
Introduction#
We’re building Dolt, the world’s first version controlled SQL database. Our customers are using Dolt in a bunch of different ways, but by far the most common one is to write a version-controlled application.
What is a version-controlled application, and why would you want one? This blog post will discuss what it means for an application to be version-controlled, and walk you through how to write one using Dolt.
What’s a version-controlled application?#
When we talk about a version-controlled application, we mean any application that supports version-control operations for the data under its management. Version control might refer to a bunch of different features, some of which you have probably already used in different applications.
Audit logging#

The application keeps a log of all changes made to the data, so a user can review them manually to see who did what. Many commercial databases such as MySQL have audit log functionality built-in or installable via plugin, and other enterprise applications that manage data tend to build this feature in as well, as it’s a common compliance requirement. The audit log is usually just for human review and can’t easily be used to show you a previous version of the data.
Time travel#

The application keeps snapshots of all changes to the data, so you can examine the data as it existed at some previous time. You can build this yourself by implementing slowly changing dimension on database tables, or you can enable automatic table versioning on many commercial databases like Postgres, usually with an extension. This will enable you to write queries against older revisions of the data.
Rollback#

The application stores a copy of every version of the data whenever a change occurs, so you can
revert to a previous version after a mistake. For example, Google Docs calls this feature “Version
History”,
and you can use it to revert to an earlier version of a file. JetBrains IDEs do something similar
using the name Local History. And of
course the git checkout and git reset commands can restore a previous version of a file in a git
repository.
Branching#
The application manages multiple “current” versions of the same data, usually each referred to as a branch. If you use Git, you probably use branches to keep your file changes isolated from the rest of the project while you work on them. Branches let you develop multiple versions of your data at the same time, iterating on each one independently. There are a number of recent database projects that support some form of branching, like PlanetScale (only for schemas) and Neon (for schemas and data). Most user applications that support branching do so by exposing files that are managed by a version-control system that supports branches, like Git.
Diffing#

The application can show you the difference (diff) between two versions of the data, usually so a
user can manually inspect it for quality or to see what changed. Some applications that support
rollback can also show you the diff between the versions to be rolled back to and the current one,
but it’s not as common. Among SQL database products, only two support diff operations. SQLite3
recently launched a tool to diff two SQLite databases, which
produces a SQL script of INSERT, UPDATE, and DELETE statements that will mutate one database
into the other. Dolt supports diff natively as well, and due to its
architecture can diff much faster than SQLite3 as the data
grows.
Merging#

If the application supports branching, it sometimes can merge the changes in a branch into another branch. Not very many applications have this capability, since it isn’t easy to implement. We know of only a handful of software tools that support the merge operation: distributed version control systems like Git or mercurial; TerminusDB, a version-controlled graph database; and Dolt, the world’s only version-controlled SQL database. Lots of database products and libraries support some form of merging for schema changes (schema migrations), but Dolt is the only SQL database that supports data merges.
Pull requests#
The application provides a workflow where users can request changes from one branch get merged into another, usually with human review that lets you examine what has changed, then apply the merge if everything looks OK. Pull requests combine the functionality of branching, diffing, and merging, and require additional UX on top of those features. The only widely used software that supports pull requests are web tools for version control, most notably GitHub (who invented the term for this feature). It’s useful to note that pull requests are not a feature of Git itself. Rather, GitHub built them on top of functionality implemented by Git. Similarly, Dolt itself doesn’t have pull requests as a feature, but DoltHub built pull requests on top of Dolt.
Why version control?#
There aren’t yet many version controlled applications that support all of these features, simply because version controlled data stores are pretty new, and the most mature ones (Git, Mercurial) are built for text files rather than data storage. But if you’ve used Git or another version control system in your software development work, you already understand how useful version control is for collaboration. It’s what makes it possible for large teams to write software together without stepping on each other’s toes. Many applications could also benefit from version control for the same reason.
Next, let’s deep-dive on how to implement these features to build a version-controlled application.
Tutorial: how to build a version-controlled application with Dolt#
For this tutorial, we’ll be building an inventory management / storefront system. This is a common use case among Dolt customers. The inventory for the storefront needs to be updated periodically by many different teams at our company, each of whom is responsible for some subset of the overall store experience. Each team wants to develop their changes to the storefront on their own schedule, and preview their changes before deploying them to production.
Our store’s data will be versioned with the use of branching and merging:
- The default branch of the database will be called
main, and will host production traffic. - Each team creates a development branch off
mainto make their changes. - Each team wants to preview how their changes will look as they make them
- Changes to the storefront are manually reviewed in two stages: incrementally as part of each
team’s development process, and then again as they’re merged back into
main(deployed to production)
To support these requirements, we need a backing store that supports these version control features. For this tutorial we’ll be using Dolt as this backing store, since it’s the world’s only version-controlled SQL database. It’s also possible to build a system that uses Git to store this data, but you would either lose the ability to use SQL, or would need to write your own SQL adaptation layer. The internet thinks using Git for this is a bad idea.
Starting a new feature#
The company is planning to launch a new line of menswear and wants to get it perfect before shipping it. Our first step is to create them a branch to use for their development. This function will be part of an internal-only application, so we don’t have to make it look fancy.

To get the list of branches that already exist, the backend that generates this page queries the
dolt_branches
table to
see what branches are available:
SELECT * FROM dolt_branches;When the user clicks the “New Branch” button, our backend application code creates it for them by connecting to the database and running some SQL commands:
CALL DOLT_CHECKOUT('menswear'); -- switch to the menswear branch,
-- since we want that to be our source branch
CALL DOLT_BRANCH('menswear/q2-update-2024'); -- create the new branchIf you’re familiar with Git, you’ll notice that the Dolt stored procedures copy the names of the equivalent Git commands for these tasks. That’s on purpose: if you know how to use Git it’s really easy to get started with Dolt.
For this workflow, we actually want to create several branches, probably at least one for each person working on this new menswear update. That way they each get their own copy of the data to work on in isolation, just like software developers writing code on a feature branch.

This will be Brandon’s branch to make his edits. Just like with GitHub, we’ll put people’s user names in the branch names as a convention to keep things organized. On the backend, the procedure calls look like this:
CALL DOLT_CHECKOUT('menswear/q2-update-2024'); -- switch to the source branch
CALL DOLT_BRANCH('menswear/q2-update-2024/brandon'); -- create the new branchConnecting to the right branch and making updates#
Now that Brandon has his branch created, he uses the internal catalog editor tool to connect to it to start making his edits. Note the URL query parameter that chooses the branch we’re working on.
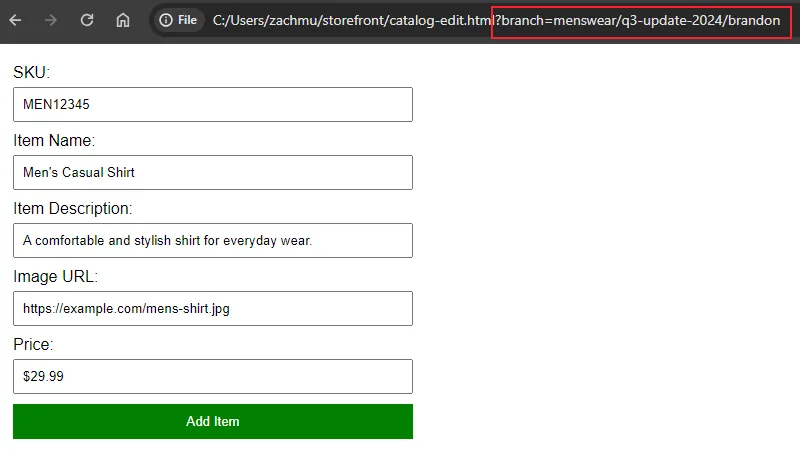
On the backend that processes this form, all we need to do is properly connect to the correct branch
when issuing any database queries or updates. Above, we used the DOLT_CHECKOUT
procedure
to switch our session to the branch we wanted, but it’s usually more convenient to just connect to
the branch you want in the first place. This involves changing the connection string to include the
branch
name. The
specifics of how to specify the name of the database in the connection string depend on the
language, but it’s usually pretty similar. If our backend is written in Go, we would change this:
db, err := sql.Open("mysql", fmt.Sprintf("%s:%s@/%s", dbUser, dbPassword, dbName))To this:
branch := getBranchFromQueryParam()
db, err := sql.Open("mysql", fmt.Sprintf("%s:%s@/%s/%s", dbUser, dbPassword, dbName, branch))Now the connection is talking to the menswear/q2-update-2024/brandon branch, and all our queries
and updates will apply to that branch.
Committing work#
Just like when you’re editing files under Git version control, Dolt has two layers of persistence:
SQL transactions and Dolt commits. Think of
a SQL transaction like saving the file being edited, whereas dolt commit creates a new snapshot
you can roll back to, merge into another branch, etc.
To create a new commit, there are two basic strategies you can use. The first strategy is to make these commits explicit, which is best if your team wants to write descriptions of their incremental changes for review later.
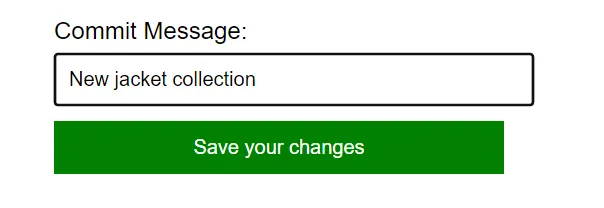
On the backend, your code connects to the proper database branch as above, then calls the stored procedure to commit changes to all tables being edited.
CALL DOLT_COMMIT('-a', '-m', 'New jacket collection');Note the use of the command line flag syntax. These flags exactly match the corresponding ones in
the git commit command:
-ameans to commit all tables that have been edited-msays to accept the provided commit message, instead of opening an editor to get one. This is required for the SQL procedure since there’s no editor available.
The other strategy for creating a commit is to automatically create one for every transaction via
the
[dolt_transaction_commit](https://dolthub.com/docs/sql-reference/version-control/dolt-sysvars#dolt_transaction_commit)
system variable:
set @@persist.dolt_transaction_commit = 1;Setting this variable to true will automatically create a new Dolt commit on every SQL COMMIT,
using an auto-generated commit message. This setting is appropriate if the volume of commits is high
and you don’t have any need to annotate them with individual commit messages.
Previewing changes#
Your teams are going to want to see the progress of their work as they continue making their changes. An internal endpoint for your site augments the customer-facing page with a branch selector, optionally also encoding this in the URL as before (note the highlighted query parameter below). Then the backend simply alters the connection string as before to choose the desired database branch to preview. Now we can see our updated catalog items as they’ll eventually appear to our users.
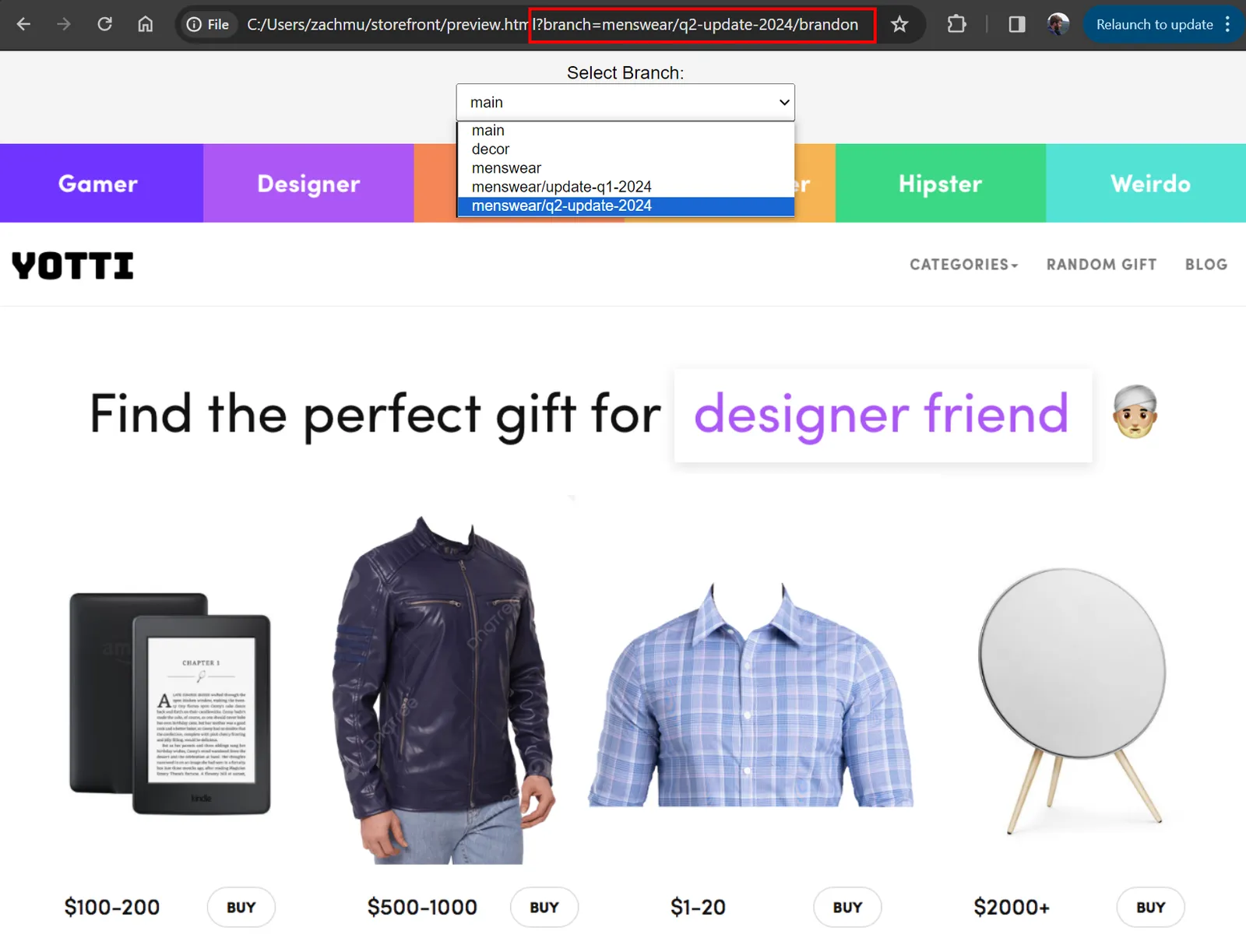
One complication is that for long development cycles, the main branch will keep getting changes as
other teams do their work. If we want to see how these changes on main will impact the branch we’re
previewing, we can merge them into the development branch. On your backend, you can merge main into
the development by connecting to that branch as above, then running the DOLT_MERGE
procedure:
CALL DOLT_MERGE('main');Doing this periodically, either with a button on the frontend, or automatically as the development
process goes on, gives you a better idea of what your changes will look like once they eventually
get merged back into main to make them visible to customers.
Seeing a diff and pull requests#
Separate from seeing a preview of work under development, sometimes it’s nice to be able to review
how the data has changed directly, row by row. In Dolt, you can compare two revisions with the
DOLT_DIFF
function,
which will return how each row has changed in the table you specified. Many Dolt customers have used
the diff capability to implement a pull request workflow, so that humans can manually review changes
before they get deployed.
This is best illustrated with examples. We’ll ask Dolt for the diff between the main branch and
the menswear/q2-update-2024/brandon branch:
> show create table men_clothing;
+--------------+------------------------------------------------------------------+
| Table | Create Table |
+--------------+------------------------------------------------------------------+
| men_clothing | CREATE TABLE `men_clothing` ( |
| | `SKU` varchar(50) NOT NULL, |
| | `product_name` varchar(100), |
| | `product_description` text, |
| | `image_url` varchar(255), |
| | `price` decimal(10,2), |
| | PRIMARY KEY (`SKU`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------------+------------------------------------------------------------------+
> select to_SKU, diff_type, to_product_name,
from_product_description, to_product_description,
from_price, to_price
from dolt_diff('main', 'menswear/q2-update-2024/brandon', 'men_clothing');
+--------+-----------+----------------------+-------------------------------------------------+-------------------------------------------------+------------+----------+
| to_SKU | diff_type | to_product_name | from_product_description | to_product_description | from_price | to_price |
+--------+-----------+----------------------+-------------------------------------------------+-------------------------------------------------+------------+----------+
| MC001 | modified | Men's Casual Shirt | A comfortable and stylish casual shirt for men. | A comfortable and stylish casual shirt for men. | 29.99 | 34.99 |
| MC004 | added | Men's Leather Jacket | NULL | A stylish leather jacket for men. | NULL | 89.99 |
| MC005 | added | Men's Chino Pants | NULL | Classic chino pants for a polished look. | NULL | 34.99 |
+--------+-----------+----------------------+-------------------------------------------------+-------------------------------------------------+------------+----------+Here you can see the MC001 SKU had a price change, while the MC004 and MC005 SKUs were
added. For every column in the table, there are from_ and to_ columns in the diff output,
showing how the value has changed between those revisions. For additions, the from_ fields will be
NULL. For deletions, the to_ fields will be NULL.
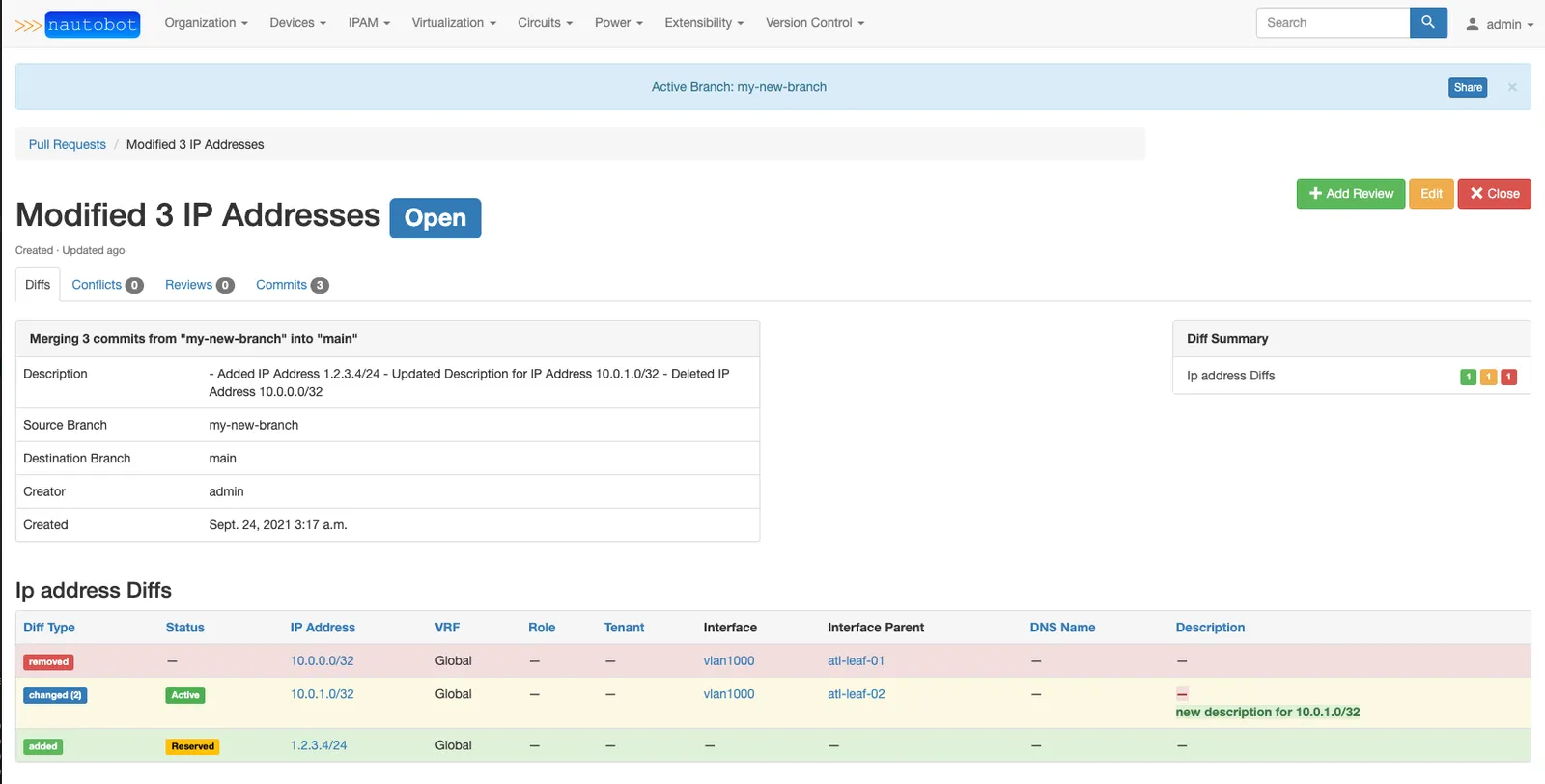
There are two basic strategies for using DOLT_DIFF results to show a diff to your users. The first
is to show the table fields more or less directly. For example, Network configuration software
Nautobot integrates with Dolt to implement pull
requests, and follows this
strategy in their UX. During the review of a pull request, this is what a user sees:
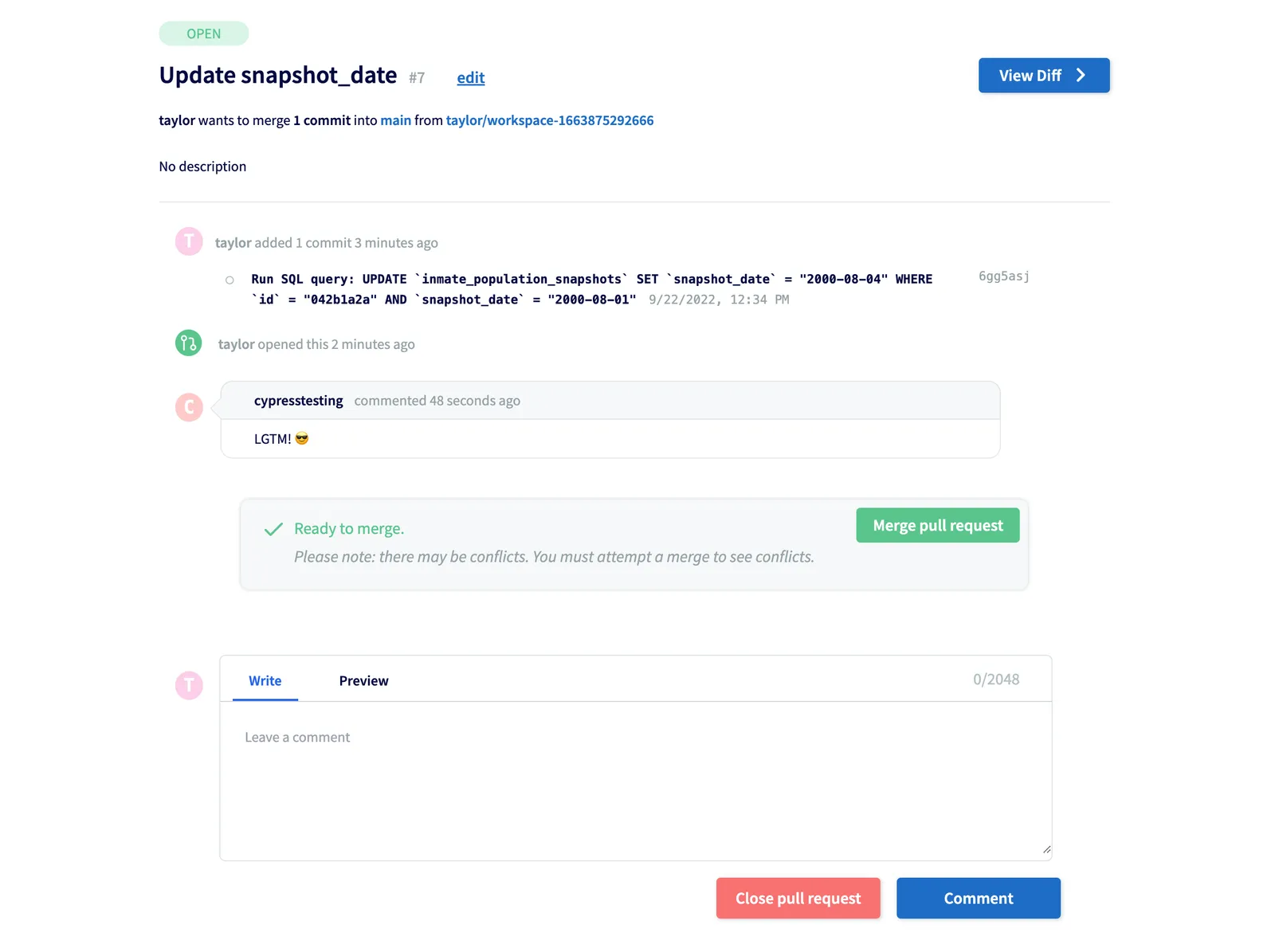
Another option is to use DoltHub or DoltLab as a remote, or to run your Dolt database on hosted Dolt. All these products implement pull requests with a clean UX that you don’t have to build yourself.
The second strategy for displaying diffs to your users is to integrate it more directly into your product’s normal customer-facing UX, e.g. showing two versions of the same page side by side, or highlighting elements of the UX which changed. This is obviously much more involved, but could be a lot nicer for users reviewing large changes.
Deploying back to production#
At the end of a development cycle, after you’ve previewed your work and gotten it reviewed by the rest of the team, then it’s finally time to deploy it to production. In Dolt, this is pretty simple: you just merge the development branch back to main. Here our internal tool presents a simple form to perform this merge, but in systems that implement pull requests, you want the merge to be the final step of that workflow.
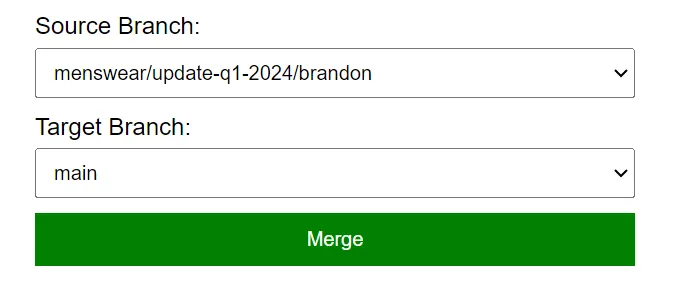
On your backend, merge is a simple stored procedure call. Connect to the target branch (main in
the above example), and issue the DOLT_MERGE
call:
CALL DOLT_MERGE('menswear/update-q1-2024/brandon');When this call succeeds, the contents of the menswear/update-q1-2024/brandon branch is merged into
main. The menswear/update-q1-2024/brandon branch can be deleted at this point, as it’s not needed
anymore. For the next round of changes, Brandon will create a new branch from the tip of main.
Depending on the size of the team and the cadence of updates, it might also make sense to merge
changes in a two-phase process. Earlier, our menswear editor Brandon created a branch called
menswear/update-q1-2024/brandon to manage his contributions to the menswear/update-q1-2024
branch. Lots of other teammates are all collaborating on the menswear/update-q1-2024, working on a
big update that’s going to get deployed back to main all at once. So instead of each teammate
merging from their personal branch to main continually, they instead merge back to a shared
development branch.
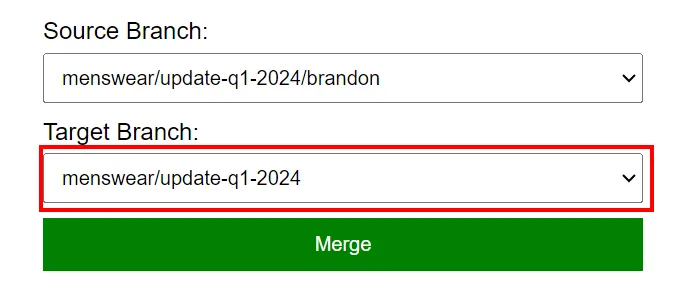
They chose a naming scheme that makes it obvious that all the personal branches are descended from the feature branch, a convention that’s also widely used in the GitHub community.
Each teammates makes incremental changes to the shared development branch on as many throw-away
personal branches as they need, and then when the entire feature is ready to deploy, we do one final
merge from menswear/update-q1-2024 back into main to deploy the feature.
Rolling back a bad change#
Deploying new changes is great, except when it breaks something. A couple years ago Atlassian had an outage that impacted a few hundred customers for over a week, caused by a bad change to production data. As we wrote at the time, the reason the outage took so long to correct for those customers came down to two problems:
- The error wasn’t immediately noticed, and updates had continued in the meantime
- No customer sharding, so it wasn’t possible to restore from backup for a single customer without impacting others
Normal database backup processes make it easy to roll back to a previous version of your data, but there’s a sacrifice involved: you lose any updates that came in after the backup snapshot. So in practice, you only do this for truly catastrophic scenarios, where losing those updates is less bad than what’s already happening. Atlassian wasn’t willing to make that sacrifice (400 customers v. tens of thousands), and who can blame them?
But if your application is version controlled, that means it’s possible to revert only particular changes without impacting updates that came after the bad change.
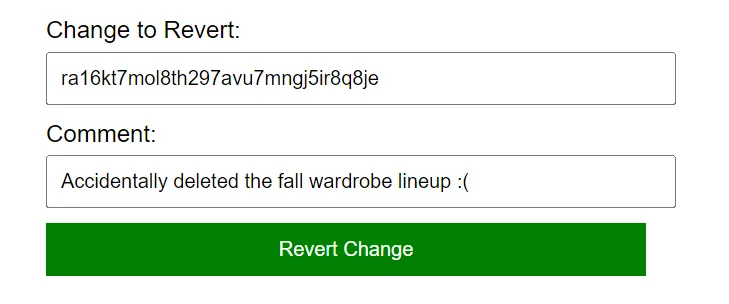
On your backend, to revert a particular commit you can use the built-in DOLT_REVERT
procedure,
which works just like git revert does on the command line: it creates a new commit that reverts
the changes made in the commits provided.
CALL DOLT_REVERT('ra16kt7mol8th297avu7mngj5ir8q8je');Of course it’s also possible to simply roll back to a previous snapshot if that’s what you want to
do. In Dolt this operation is also built-in and has zero downtime, using the DOLT_RESET
procedure:
CALL DOLT_RESET('--hard', 'HEAD~2'); -- revert the last two commitsUsing DOLT_RESET is more similar to restoring from a backup in a traditional database, in that you
“lose” updates that came after the restore point. But because Dolt is version controlled, those
updates aren’t actually gone: you can see the branch’s history with the DOLT_REFLOG
function,
and then selectively apply commits you want to keep with the dolt_cherry_pick
procedure,
or go even finer-grained with the
DOLT_PATCH
function.
Conclusion#
Version controlled applications are still uncommon, and we think this is mostly because we haven’t had the tools needed to implement them easily. Plenty of application developers have implemented soft deletes or slowly changing dimension to get some of the benefits of version control, but using traditional databases to implement features like branching and merging, or pull requests, has required really complex custom solutions that were super slow and only partially worked. The availability of Dolt and other version-controlled databases opens up a whole new set of possibilities in application design, and we’ve only just begun to see how they will be applied.
Have questions about Dolt, or building version controlled applications? Have a suggestion on how to improve this tutorial? Join us on Discord to talk to our engineering team and meet other Dolt users.