
We’re saying Good Bye to one of DoltHub’s most unique experiments, Data Bounties. DoltHub started with a data marketplace mission. Data Bounties were our best idea to bootstrap a virtuous cycle between data producers and data consumers.
Data bounties worked like this.
- Identify unique, hard to collect datasets.
- Make a schema.
- Pay contributors to source data for that schema.
- Use Dolt and DoltHub’s unique collaboration and data review features to manage the process.
- Pay contributors based on the amount of data collected, reviewed, and merged into the database.
While cool, data bounties remained very niche almost three years after launch. In the meantime, DoltHub became a database company, producing and selling the world’s first and only version controlled SQL database, Dolt.
Bounties became an expensive distraction. So, it’s time to say goodbye. We may resurrect the idea in the future but for now, we’re focused on making Dolt a great database.
This article will explain the bounties journey and dive a bit deeper into what we learned, just in case anyone else wants to try the Bounties idea again. Bounties remain a very cool Dolt use case.
A DoltHub History#
Our company started in 2018 as “Liquidata”. We wanted to “add liquidity to the data market”. The name was a bit of a mouthful but damn, I still like the logo.
![]()
Notice how the cuts in the drop form an “l” and a “d”. Chef’s kiss. 99 Designs really came through for us here. But I digress.
The problem we were (and still are) trying to solve is “Data is too hard to share”. Our hypothesis was that if we added branch/merge to data, like we had in source code, data would be easier to share. If data was easy to share, a thriving data marketplace would emerge.
So, we built Dolt, Git for data, and DoltHub, GitHub for Dolt. We launched Dolt in August 2019 and DoltHub in September 2019. We changed the name of the company to DoltHub in early 2020.
How do we get people to share data in Dolt and on DoltHub? We’ll do it! We will seed DoltHub with a bunch of open datasets. Our early blogs show off databases like Wordnet, ImageNet, and Wikipedia N-grams.
We pursued this strategy for about a year, publishing monthly dataset spotlights. We were getting a few open databases but no one was collaborating in the way we intended. Publishers were publishing but no one was making Pull Requests.
How do we get people to collaborate on DoltHub?#
We started to really lean into the idea of “crowd sourcing” data. Building databases ourselves just wasn’t cutting it. How could we build a database that required a lot of people to contribute?
First, we needed a feature on DoltHub to allow decentralized collaboration: Forks. Forks are a bit of a subtle feature. On GitHub and DoltHub, to contribute to a project you must have write permissions. This means you have to ask permission to contribute. With forks, you just fork and make your changes on your own copy, no permissions necessary. This allows for permission-less collaboration. We added Forks to DoltHub in September 2020.
Then, we tried to bootstrap a LinkedIn dataset. We built a scraper and with your login credentials, the scraper would grab all the data from your network off LinkedIn. The idea was resume data should be free and open. We thought that would motivate people to contribute. We shipped the blog but no one scraped their LinkedIn. How do we get people to care enough to contribute to an open data project?
Bounties#
Let’s pay people! We’ll put up a prize for a dataset we want to build and use Dolt and DoltHub’s unique collaboration features to manage contributions.
We built all the necessary software including a unique open source attribution system. All that was left was to pick a dataset to target. This was the height of 2020 US Presidential Election craziness so we decided on Precinct level results for the 2020 Presidential Election.
We launched the bounty on December 14, 2020 and followed up with a Bounty explainer post on December 16. We publicized both posts on r/datasets and HackerNews hoping people would show up and contribute.
A little to our surprise, people started to show up and contribute. We managed all the bounty hunters through our really active Discord. The first bounty featured six contributors, 75 pull requests, 15.5M cells edited, and 1.7GB of data collected. The top contributor made almost $11,000.

The big innovation was the scoreboard. It was extremely fun to get a PR accepted and then watch the scoreboard change to calculate your new piece of the prize money.
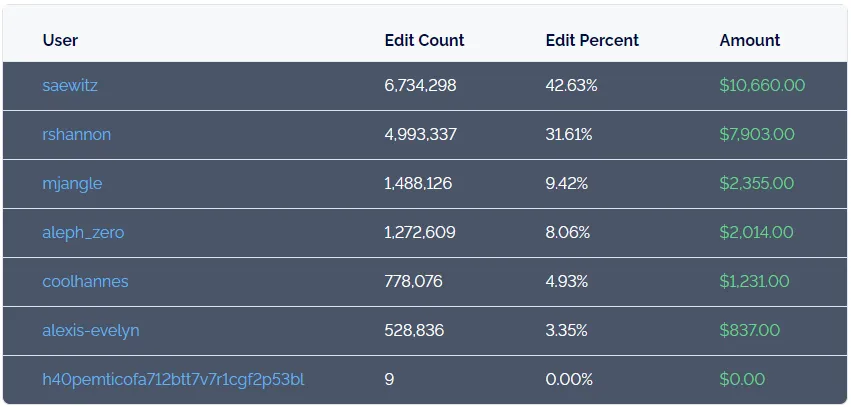
The first bounty concluded with a bit of controversy. The folks from OpenElections got a little mad at us but we worked it out.
We continued on to do dozens of bounties. We made bounty payouts to participants totalling approximately $250,000. This is not counting salaries of the bounty administrators. It was becoming an expensive experiment.

Our second data bounty was US hospital prices. The hospital price space became the focus of bounties over the past three years as we became experts in hospital price data. In what is looking like our last ever bounty, we built the best open hospital price database on the internet.
But DoltHub is a Database Company…#
In the meantime, Dolt became a credible OLTP database you can use to replace MySQL or Postgres. Customers use Dolt to serve a number of production use cases. DoltHub became a database company not a data sharing company.
Bounties generate cool, large scale data sharing and CLI use but most of our customers don’t use Dolt that way. Most of our customers use Dolt as a database to replace MySQL or Postgres. So, the feedback and bugs we get from bounties on Dolt and DoltHub is a bit tangential to where we are taking the product.
Saying Goodbye#
So with that, we’re saying goodbye to Bounties.
Thanks @spacelove (ie. Alec Stein) and all the bounty hunters who participated over the years.@spacelove started as a bounty contributor. He learned Python through data bounties. In the early days, I was teaching him how to code on weekends. With most bounties, the top contributor take about 80% of the prize and for the first year of bounties that was @spacelove. He became a guest and then DoltHub’s first fulltime bounty administrator. At DoltHub@spacelove is synonymous with Bounties.
As a thank you, I bought a few of these badges and I’m going to send them out to some of our best contributors over the years as thanks.
![]()
What we learned#
With all that said, I think there is something here if another intrepid soul wants to take the plunge. Bootstrapping a marketplace is difficult and requires focus we here at DoltHub don’t have right now. Feel free to use these lessons and take your own shot at a Bounties-like product using Dolt and DoltHub.
Bounties are very good marketing#
Long after we knew Bounties as we implemented them were not going to be a self-sustaining business, we kept doing them because they are great marketing. Data bounties are exciting and innovative. The content we generated from bounties was great. Announcing new bounties, showcasing the raw data we collected, and analyzing the data afterwards all made great blog content.
Bounties blogs have been in the top three of HackerNews multiple times. Our most successful blog about the health insurance data dump generated over 50,000 views. We even made a meme to tease @spacelove about it.

Bounties Produce Point-in-time Datasets#
Bounties databases are updated during the bounty. Once the bounty ends, the updates stop. Bounties produce point-in-time “snapshots” of data. Bounties are good at producing a prototype to see what is possible. For a small amount of investment you can get a very good prototype database and you can then decide if you want to invest further in-house resources to maintain it.
We never tested the “forever bounty” idea. The idea is to pay a certain amount for an update to data once it gets stale. For instance, we could pay $50/month/hospital price sheet to incentivize updates. The issue here is that these updates are a bit hard to review which we’ll get to next.
Data Review is hard#
Reviewing data submitted requires subject matter expertise. As we learned the hospital price space our databases became better. Towards the end, we had automated testing of Pull Requests to ensure data quality. The bounty system requires the bounty administrator and even the bounty hunters build subject matter expertise.
Paid volunteers do the least#
Due to the nature of the bounty system, bounty hunters transparently do the least amount of work possible to get their data through review. If the data is accepted, they get paid. Thus, they are willing to delegate a lot of data quality control work to the bounty administrator. We eventually adopted very strict rules like, we’re only going to review your Pull Request once, to work around this.
Moreover, there are disputes to manage. There is a lot of money on the line so passions are high. If a bounty hunter feels like he or she was treated unfairly, someone has to manage it. We often resorted to “if you don’t like it, don’t participate”. That said, most bounty hunters participated in multiple bounties so the bounty hunter pool was quite stable.
Supply/Demand Open Data Loop#
Even when we had the best open hospital price data in the world people still didn’t use it. We tried to pay bounties for data analysis blog posts but it was too manual and felt disingenuous. I think people like the idea of open data but practically, companies need data, not individuals. This made it hard to get a supply and demand loop going in the open data space. Unlike open source, building databases is tedious and not very fun. The combination of not very fun to do and only companies needing the results is not a good combination for open data.
Conclusion#
Data Bounties were a fun experiment and we may pick the idea back up of the shelf in the future. I’m hoping that some intrepid entrepreneur is thinking, “Tim is dumb. I can make this Data Bounties work.” To that I say, “Have at it!”. If you want to talk about Data Bounties or version controlled databases, I’m available on our Discord.