
This article discusses the technical details of static initialization for map data in Go binaries, and some alternative strategies for dealing with the performance impacts. It’s part of our our technical Golang blog series. We publish a new article in the series every 3 weeks.
At Dolt, we’re building a SQL database with Git-like version control features. It supports all the core Git idioms like clone, push, pull, branch, merge and diff. It’s implemented in Go and its wire protocol and SQL dialect is compatible with MySQL.
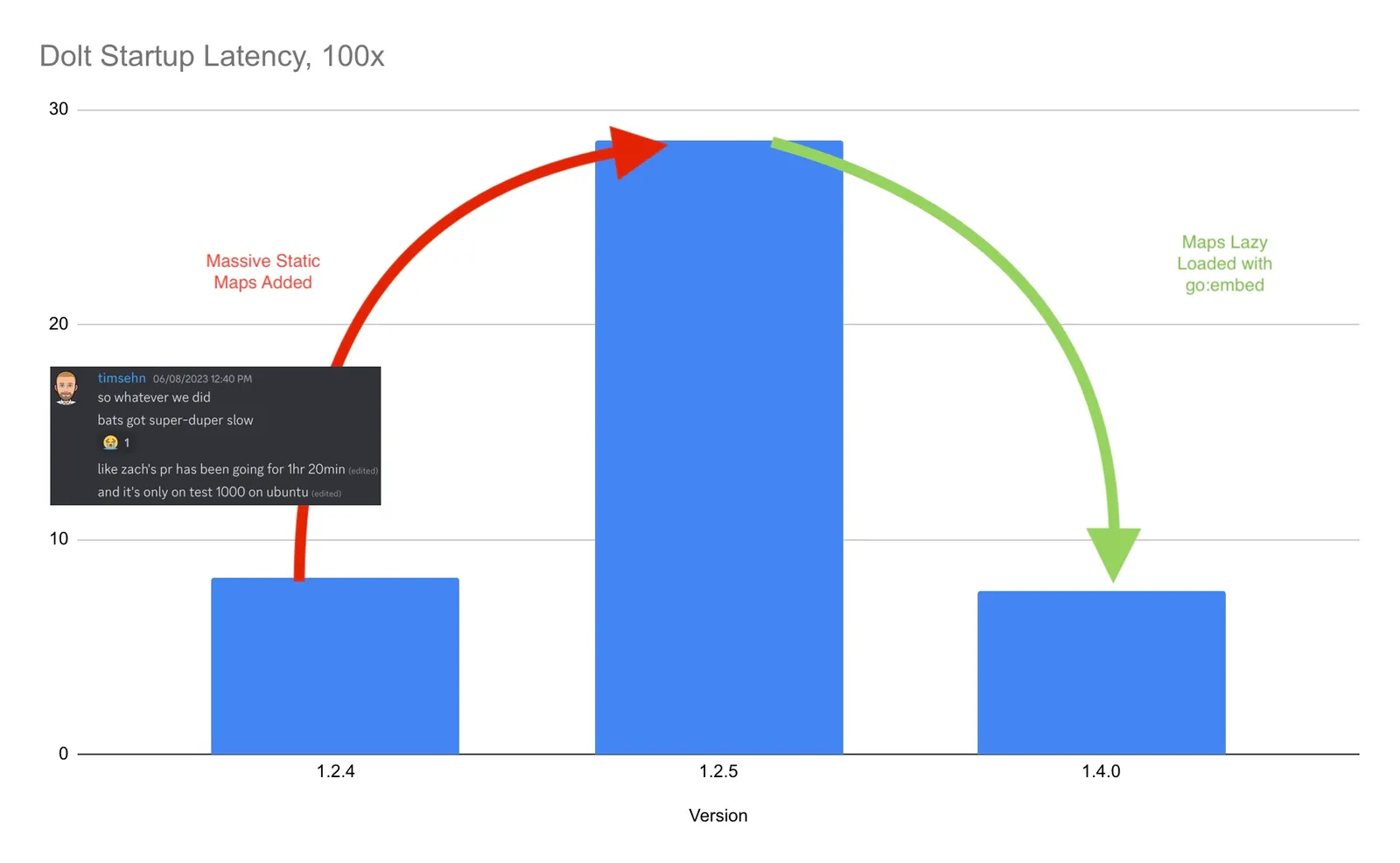
For the past few months, we have been working on improved collation and Unicode support throughout our SQL engine. One change that we made was to add a number of data tables to the Dolt distribution to better support locale-dependent sorting of strings in different Unicode locales. This involved adding a lot of static data tables to the Dolt binary. Our initial implementation was to use static maps which were compiled into the Dolt binary. Shortly after a PR landed that added a number of large static maps to Dolt, my colleagues realized that our end-to-end tests had gotten much slower. This caused us to dig into how static map initialization works in Go and to address the regression in a later release:
This blog is a short exploration of how static map initialization in the Go toolchain is implemented, what its runtime costs overhead are, and some alternative approaches to deal with it if and when it matters to you.
Background#
Dolt, like MySQL and as part of its MySQL compatibility, supports language dependent collation of strings. Language dependent collation involves comparing strings against each other and arriving at a relative ordering for the strings which a language user would expect. For most character encodings and locales, it is more involved than a simple comparison of the binary representations of the characters or code points in the strings. The reasons for this include:
-
Different representations of the same string, as a user will perceive it rendered on a screen, can have different binary representations in a given character encoding. For example, in UTF-32, the word
oùin French can be written with two code units, as:[U+006F, U+00F9], or as three code units, with a combining diacritical mark for the accent:[U+006F, U+0300, U+0075]. -
Different languages have different rules for the relative order of the same characters. For example, the list of strings
["Aa", "Od", "Öd", "Zz"]should sort in that same order for a user in a German locale, but should sort["Aa", "Od", "Zz", "Öd"]in a Swedish locale.
You can see this in action in Dolt itself:
collations> create table german (word varchar(32) primary key) collate utf8mb4_de_pb_0900_as_cs;
collations> create table swedish (word varchar(32) primary key) collate utf8mb4_sv_0900_as_cs;
collations> insert into german values ("Aa"),("Od"),("Öd"),("Zz");
Query OK, 4 rows affected (0.02 sec)
collations> insert into swedish values ("Aa"),("Od"),("Öd"),("Zz");
Query OK, 4 rows affected (0.01 sec)
collations> select * from german order by word asc;
+------+
| word |
+------+
| Aa |
| Od |
| Öd |
| Zz |
+------+
4 rows in set (0.01 sec)
collations> select * from swedish order by word asc;
+------+
| word |
+------+
| Aa |
| Od |
| Zz |
| Öd |
+------+
4 rows in set (0.00 sec)Because of complications like this, implementing locale dependent collations typically involves shipping data tables which are used by a collation algorithm to arrive at the appropriate relative ordering of strings.
Dolt itself is distributed as a statically linked binary. We really like the approachability and ease of its distribution model. You just download the OS appropriate version of Dolt and run it. Thus, we have always shipped these tables for Dolt’s supported collations within the binary itself.
The UX and resulting typical interactions with Dolt’s binary can also be quite different than a typical SQL server. In particular, Dolt users typically interact with Dolt in two different ways:
-
As a SQL server, with a long running dolt process accepting SQL connections over TCP and/or a Unix socket.
-
As a standalone binary in a Git-like workflow, frequently invoking the
doltCLI to do things like create branches, run adhoc SQL queries, view the commit log and perform a merge.
The latter case is quite distinct from typical interactions with a traditional RDBMS implementation, and it means that the user experience of using Dolt can be somewhat sensitive to the startup latency of the Dolt binary itself.
My colleague recently added over 32MB of collation data tables to the Dolt binary in order to better support many Unicode collations which are supported by MySQL. These were initially done in exactly the same way as existing collation implementations. A large portion of the data payload was implemented as a statically initialized Go map, as something like:
var utf16_spanish_ci_Weights = map[rune]int32{
9: 0,
10: 1,
11: 2,
12: 3,
13: 4,
133: 5,
8232: 6,
// ...
// ...
// ... 24000+ lines later ...
65534: 59403,
65535: 59404,
}Shortly after the PR landed, we noticed that our end-to-end tests had gotten
much slower. When we benchmarked it, dolt --help had become over 300% slower
as a result of the static maps. After realizing the runtime initialization cost
of the static maps, we were able to move them to be embedded data files which
are loaded when needed, fixing the entirety of the regression.
Let’s take a look at how Go static map initialization works and what we can expect for its runtime overhead.
Static Map Initialization#
Static map initialization occurs when a map with initial contents is created at the top-level of a Go package. Unlike with certain types of other static data—including primitive types, strings, slices, and structs of all of these things—a static map in Go is dynamically allocated and assigned at program initialization time, instead of its contents being laid out in memory and written to the data segment of the compiled binary. For something like:
package main
var mymap = map[int]int{
1: 1,
2: 2,
3: 3,
}The Go compiler will emit an init function for the package which includes
allocating the map and inserting the elements into it. The emitted code looks
almost exactly the same as for the following sequence of Go code:
mymap = make(map[int]int, 3)
mymap[1] = 1
mymap[2] = 2
mymap[3] = 3with a call to runtime.makemap_small and three calls to
runtime.mapassign_fast64.
In the current version of the golang compiler, this approach changes very
slightly as the map gets larger. The size of the emitted code is capped,
because the compiler will move the key and value data itself into a static array if
there are more than 25 entries in the
map.
The emitted init code in that case just loops over the array data and inserts
it into the dynamically allocated map.
The overall effect is that the cost of static map initialization grows approximately linearly with the size of the static maps one has in the their Go binary. In some experiments run locally, I see the following scaling behavior:
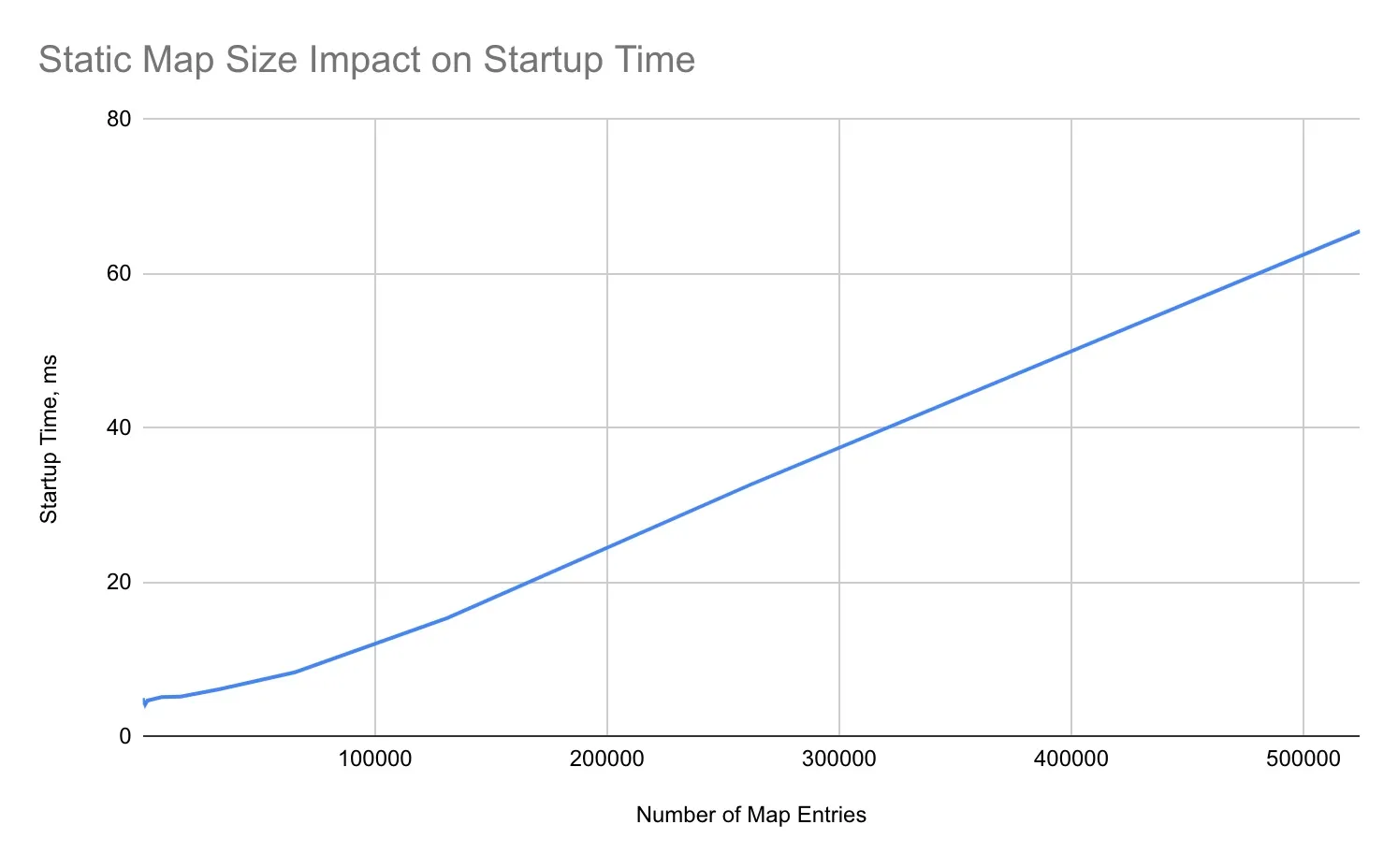
We can see that once the map initialization is expensive enough to start having an effect, its cost grows approximately linearly.
Impact on Development Workflow#
In addition to the startup cost in the resulting binary, huge code payloads in
the form of static map initialization also have an observed negative effect on
compile times and the memory overhead of operations like go vet. This is not
at all surprising, since the amount of code which needs to be compiled is much
larger. In one test program consisting of a a map with 2^20 integer entries,
making a total of 17MB of source on disk, go vet’s maximum resident heap
utilization was over 1.5GB, go build’s resident heap utilization was over
1.2GB, and a build of the package took over 12 seconds.
Some Workarounds#
Given the costs associated, there are a number of different approaches we can take to make different tradeoffs with regards to startup overhead, ease-of-use and approachability of the code, and the various features which are available in the resulting initialized data structure. Here we will talk about three compelling alternatives, with varying levels of complexity and available functionality after the transformations. Any or all of these might be appropriate depending on your use case.
Sorted Static Arrays#
If you can afford O(lg n) comparisons on the lookup path for whatever tables
you are shipping embedded in your binary, and you are mostly concerned about
the startup overhead, not necessarily with the resource overhead associated
with the large code payload, it might be an option to convert the map into a
sorted static array. With this approach, you lose:
-
Easy mutability of the data structure at runtime.
-
O(1)lookups.
You might also be trading off easy manual editing of the embedded array literal. If you take this approach, the literal needs to actually be sorted, and so you should write unit tests which assert that. As a nice to have, those same unit tests could also generate code for embedding the sorted result when they fail, so that a developer can easily copy the correct result into the code.
With this approach, the example map from above might look like:
type RuneCollationWeight struct {
R rune
W int
}
type RuneCollationWeights []RuneCollationWeight
func (w RuneCollationWeights) Len() int {
return len(w)
}
func (w RuneCollationWeights) Less(i, j int) bool {
return w[i].R < w[j].R
}
func (w RuneCollationWeights) Swap(i, j int) {
w[i], w[j] = w[j], w[i]
}
func (w RuneCollationWeights) Get(r rune) (int, bool) {
n := sort.Search(w.Len(), func(i int) bool {
return w[i].R >= r
})
entry := w[n]
if entry.R == r {
return entry.W, true
} else {
return 0, false
}
}
var utf16_spanish_ci_Weights = RuneCollationWeights{
{9, 0},
{10, 1},
{11, 2},
{12, 3},
{13, 4},
{133, 5},
{8232, 6},
// ...
// ...
// ... 24000+ lines later ...
{65534, 59403},
{65535, 59404},
}Which implements sort.Interface so that the sanity test can just be, for
example, sort.IsSorted(utf16_spanish_ci_Weights).
Reducing the Amount of Code With embed#
Depending on the circumstances, leaving the array in the Go code like that
might still have some unfortunate impact on developer ergonomics, given the
overhead on compile and go vet times, for example. Go provides a very easy
way to embed binary payloads as []bytes and even entire directory trees as
fs.FS implementations through its embed package.
Using this, it’s easy to move the large static arrays out of the Go code itself
and into an external file. When doing this, you will need to account for the
serialization of the data itself into the external files. That serialization
will need to be handled in a cross-platform way. You will also need to add
programs or build processes which are able to generate these files when you
make changes to them. For the above example, maybe you write a simple program
which just serializes the data out as big endian int32s:
func SerializeWeights(w io.Writer, weights RuneCollationWeights) error {
sort.Sort(weights)
for _, weight := range weights {
if weight.W > math.MaxInt32 {
return fmt.Errorf("cannot serialize weights: weight for %d, %d, is larger than MaxInt32", weight.R, weight.W)
}
if weight.W < math.MinInt32 {
return fmt.Errorf("cannot serialize weights: weight for %d, %d, is smaller than MinInt32", weight.R, weight.W)
}
err = binary.Write(w, binary.BigEndian, int32(weight.R))
if err != nil {
return err
}
err = binary.Write(w, binary.BigEndian, int32(weight.W))
if err != nil {
return err
}
}
return nil
}As you can see, we can choose to sort the weights as part of this build step,
which might make working with the arrays checked into the source code of these
generator programs easier. To ship these files and use them in our binary, we
can take the above approach, but this time making use of the file we have
generated using the embed package:
import _ "embed"
//go:embed utf16_spanish_ci_Weights.bin
var utf16_spanish_ci_Weights_bin []byte
type BinaryRuneCollationWeights []byte
func (w BinaryRuneCollationWeights) Len() int {
// There are two 32-bit integers per entry
return len(w) / 8
}
func (w BinaryRuneCollationWeights) Get(r rune) (int, bool) {
n := sort.Search(w.Len(), func(i int) bool {
entryR := binary.BigEndian.Uint32(w[i*8:])
return rune(entryR) >= r
})
entryR := binary.BigEndian.Uint32(w[n*8:])
if rune(entryR) == r {
return int(int32(binary.BigEndian.Uint32(w[n*8+4:]))), true
} else {
return 0, false
}
}
var utf16_spanish_ci_Weights = BinaryRuneCollationWeights(utf16_spanish_ci_Weights_bin)Lazy Loading Maps#
If you want O(1) access back, and in particular if you want runtime
mutability of the map after it is seeded with its initial contents, then lazy
loading the map at first access might be a good option. This is especially true
if not all runs of your program will need access to the map (or all maps, in
the case that you have multiple).
The simplest way to accomplish this is to move the access of the map behind a
function call, and to populate the map contents using a sync.Once invocation
within that function. Something like:
import "sync"
var utf16_spanish_ci_Weights_ map[rune]int
var utf16_spanish_ci_Weights_once sync.Once
func utf16_spanish_ci_Weights() map[rune]int {
utf16_spanish_ci_Weights_once.Do(func() {
utf16_spanish_ci_Weights_ = map[rune]int{
9: 0,
10: 1,
11: 2,
12: 3,
13: 4,
133: 5,
8232: 6,
// ...
// ...
// ... 24000+ lines later ...
65534: 59403,
65535: 59404,
}
})
return utf16_spanish_ci_Weights_
}Then every access of your map should go through utf16_spanish_ci_Weights().
This transformation is entirely sufficient if you only care about startup
initialization overhead. The func inside of utf16_spanish_ci_Weights gets
compiled into almost the same code as what would have been in the package’s
init function otherwise, and so all of that work is delayed until the weights
map is actually accessed.
If you want to get the code payload itself out of commonly compiled, tested or
depended on code paths, then you can use embed as above, and build the map up
yourself from the serialized contents within the sync.Once callback.
Something like:
func utf16_spanish_ci_Weights() map[rune]int {
utf16_spanish_ci_Weights_once.Do(func() {
bin := utf16_spanish_ci_Weights_bin
utf16_spanish_ci_Weights_ = make(map[rune]int, len(bin) / 8)
for len(bin) > 0 {
r := rune(binary.BigEndian.Uint32(bin[:]))
w := int(int32(binary.BigEndian.Uint32(bin[4:])))
utf16_spanish_ci_Weights_[r] = w
bin = bin[8:]
}
})
return utf16_spanish_ci_Weights_
}This is the solution we ended up implementing in dolt, since it was very near
at hand and had the smallest impact on the code consuming the contents of these
data tables.
Perfect Hashes#
Since solutions relying on embed need an external program processing the data
table and putting it into a format which the program can use (as opposed to
just piggybacking on the Go compiler’s ability to layout static data for the
program), we can go one step further and layout the data in a compact, hashed
way which still allows O(1) access to all the entries but does not require
building a map at runtime. The structure we want is a lookup table built on a
computed minimal perfect hash
function of the keys in
our original map. There are number of high quality minimal perfect hash
implementations in Golang.
We build and serialize a perfect hash function for the keys of the map as a separate payload from the map contents themselves. That payload is typically much smaller than the set of keys and values itself. We leave the keys and values embedded as a separate binary payload which we reference through the perfect hash indirection. Here’s what this might look for our running example, using the bbhash package:
func SerializeWeights(wWr, hWr io.Writer, weights []RuneCollationWeight) error {
keys := make([]uint64, len(weights))
for i, weight := range weights {
keys[i] = uint64(weight.R)
}
hash, err := bbhash.New(bbhash.Gamma, keys)
if err != nil {
return err
}
err = hash.MarshalBinary(hWr)
if err != nil {
return err
}
ordered := make([]RuneCollationWeight, len(weights))
for _, weight := range weights {
i := hash.Find(uint64(weight.R)) - 1
ordered[i] = weight
}
for _, weight := range ordered {
if weight.W > math.MaxInt32 {
return fmt.Errorf("cannot serialize weights: weight for %d, %d, is larger than MaxInt32", weight.R, weight.W)
}
if weight.W < math.MinInt32 {
return fmt.Errorf("cannot serialize weights: weight for %d, %d, is smaller than MinInt32", weight.R, weight.W)
}
err = binary.Write(wWr, binary.BigEndian, int32(weight.R))
if err != nil {
return err
}
err = binary.Write(wWr, binary.BigEndian, int32(weight.W))
if err != nil {
return err
}
}
return nil
}import _ "embed"
//go:embed utf16_spanish_ci_Weights.bin
var utf16_spanish_ci_Weights_bin []byte
//go:embed utf16_spanish_ci_Weights_hash.bin
var utf16_spanish_ci_Weights_hash_bin []byte
var utf16_spanish_ci_Weights_hash *bbhash.BBHash
var utf16_spanish_ci_Weights HashedRuneCollationWeights
func init() {
var err error
utf16_spanish_ci_Weights_hash, err = bbhash.UnmarshalBBHash(bytes.NewReader(utf16_spanish_ci_Weights_hash_bin))
if err != nil {
panic(err)
}
utf16_spanish_ci_Weights = HashedRuneCollationWeights{
H: utf16_spanish_ci_Weights_hash,
B: utf16_spanish_ci_Weights_bin,
}
}
type HashedRuneCollationWeights struct {
H *bbhash.BBHash
B []byte
}
func (w HashedRuneCollationWeights) Get(r rune) (int, bool) {
i := h.Find(uint64(r)) - 1
off := i * 8
if off < len(w.B) {
entryR := rune(binary.BigEndian.Uint32(w.B[off:]))
entryW := int(int32(binary.BigEndian.Uint32(w.B[off+4:])))
if entryR == r {
return entryW, true
}
}
return 0, false
}This is maybe the approach you want to take if you are trying to cut down on initialization overhead, but a large percentage of the invocations of your binary actually do need to access at least some parts of these embedded data tables. In that case, there is no way to avoid paying for the initialization, and so it would be nice if it was as cheap as possible.
A few downsides of this approach might be:
-
Regenerating the serialized data tables takes quite a bit more time, because it needs to compute the minimal perfect hash of the keyset when it does it.
-
If the data tables are being checked into source control, they are being stored in hash order, as opposed to sorted order. This will generally result in less compelling binary diffs and higher storage overhead, since changes between revisions will be larger and things like delta encoding used by the SCM will not be as effective.
-
The resulting binary is slightly larger, since it stores enough data to reconstruct the hash table mappings as well as the actual contents of the data tables.
Also worth noting is that the static initialization overhead of the
bbhash.UnmarshalBBHash call within the init function above is somewhere
between purely static data in something like a []byte and initializing a
map. It needs to parse a number of bitvectors which are in aggregate of size
O(n), typically less than five bits per key, and it passes through and
interprets most of the loaded data as little endian integers. This can all be
done very fast, much faster than building a hash map, but it’s not as cheap as
not accessing the memory at all—large static arrays written into the data
segment of a Golang binary don’t even need to be paged in from disk on startup
if they are not accessed.
If you generally like some of the properties of the perfect hash but you don’t
like that particular initialization overhead, moving the UnmarshalBBHash to
be lazy loaded works perfectly well as well.
Summary#
To recap, we looked at the following approaches to embedding large static lookup tables in your Dolt binary:
| Approach | Startup Cost | First Access Cost | Code Cost | Build Complexity | Access Asymptotics | Runtime Mutability |
|---|---|---|---|---|---|---|
| Static Map | ★☆☆☆☆ | ★★★★★ | ★☆☆☆☆ | ★★★★★ | O(1) | ✔️ |
| Lazy Map | ★★★★★ | ★☆☆☆☆ | ★☆☆☆☆ | ★★★★★ | O(1) | ✔️ |
| Lazy Map, using embed | ★★★★★ | ★☆☆☆☆ | ★★★★★ | ★★☆☆☆ | O(1) | ✔️ |
| Static Array | ★★★★★ | ★★★★★ | ★☆☆☆☆ | ★★★★★ | O(lg n) | ❌ |
| Static Array, using embed | ★★★★★ | ★★★★★ | ★★★★★ | ★★☆☆☆ | O(lg n) | ❌ |
| Perfect Hash | ★★★★☆ | ★★★★★ | ★★★★★ | ★☆☆☆☆ | O(1) | ❌ |
In Dolt itself we ended up using lazy initialized maps which we build at first access from embedded data tables. An external program writes the serialized data tables out and we check the binary payloads into source control. This works well for us since the tables are slowly changing, there are a lot of them of medium size each, and most invocations of Dolt for most of our customers access very few of them.
As you can see, the Go toolchain and ecosystem provides a multitude of near at hand approaches which can hopefully meet your distribution and developer ergonomics needs for shipping large lookup tables in a binary. If you have feedback or questions on the approaches presented or just want to talk about development with Go or about Dolt, please come and join us on our Discord.