
Introduction#
Originally, Dolt was a CLI tool focused on data sharing and collaboration. As a CLI tool, Dolt exposed commands that allowed users to import, commit, branch, and merge data. About 1.5 years ago our company decided to focus on building Dolt into a version controlled SQL database. In this blog, we’ll discuss some of the architecture challenges left as a result of the product shift and why fixing them enables a much more extensible product.
Our original architecture#
Below is a simple picture of what our architecture looked like when we only offered CLI functionality.
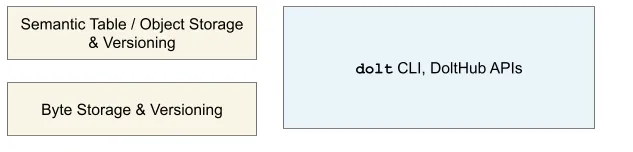
At the very bottom layer of the left side is our storage engine, built on top of Noms. It’s what reads and writes bytes to disk and memory. On top of the storage engine is our representation of a table along with its versioning primitives. On the right, we expose a command layer that allows for both data manipulations (import, add, delete) and versioning manipulations (commit, merge, branch).
Moving towards a MySQL database#
Becoming a MySQL database means that CLI tooling was simply not enough to read or write data. We had to support data reads and write in multiple ways
- CLI commands as such as import
dolt table import - CLI commands such as
dolt sql - Server commands from a mysql client
dolt sql-server
More importantly, we even had to expose versioning primitives through all of these read/write paths. This is where our Dolt SQL functions and system tables come into play. We can summarize the above by adding some more parts to our diagram.
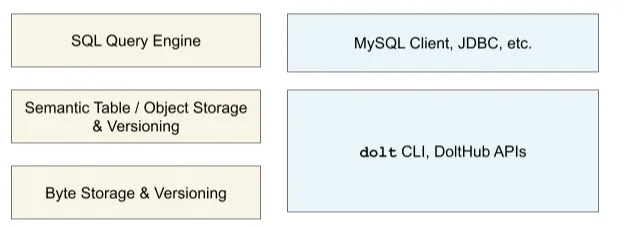
All of these additional code paths for manipulating data were becoming extremely difficult to manage. Some commands done through the CLI would leave the database in an erroneous state. We needed to do the hard work of refactoring our code base to make sure all reads and writes go through the SQL query engine.
The solution to that problem is to represent all data manipulations as SQL manipulations that can be sent to a SQL query engine.
Case Study: dolt table import#
The dolt cli had several commands that directly modified table level abstractions but did not use the SQL Engine. This could be a problem as the SQL Engine enforces operations such as check constraints, default values, and foreign keys. dolt table import was the biggest violator as it enabled you to import hundreds of thousands of rows with almost no validation! A huge problem.
Let’s break down what dolt table import does and how it can be converted into a SQL Engine Problem.
dolt table import supports three ways of manipulating data
InsertDirectly insert the data. Error on duplicateReplaceClear the table and reinsert with new data.UpdateIf the primary keys exists update its values otherwise add the new row.
dolt table import also allows users to create and drop existing tables. Previously, all of this work was done by directly manipulating our core RootValue abstraction. Now we can express each of these functions as SQL queries that go directly through the engine.
- To create a table use
CREATE TABLE - To drop a table use
DROP TABLE - To insert convert the data into an
INSERTquery - To replace first call
TRUNCATEand then convert the data into anINSERTquery - To update use an
INSERT ON DUPLICATE KEY UPDATEquery
We had to extend this type of reasoning to all sorts of commands including dolt dump, dolt table export, and soon dolt schema import.
With these clear sets of commands we could expose engine related functionality in a super simple manner: A set of queries to be parsed and executed on.
Conclusion#
Doing the work to take on this technical debt has really enabled some key benefits.
- The ability to quickly iterate on storage engine changes. When table level changes go through one code path, it becomes much easier to deploy new compression and storage techniques. More on this soon.
- An extensible SQL Engine. With all data manipulation paths going through one unified path we can add support for new protocols like PostgresSQL.
- Correctness guarantees. We know the data you are ingesting is valid as it is validated by our query planner.
If you want to learn more about the inner workings of a database join our Discord here.