
Developing machine learning infrastructure is a competitive new space. Machine learning operations (MLOps) promises to replace stodgy, manual scripts with automated and reproducible pipelines, unlocking priceless volumes of business value in the process. The following quote from a Pachyderm product blog summarizes the premise well:
Imagine a large organization with hundreds of machine learning models that need training and regular evaluation. Any small change in training datasets can significantly affect the model output. Change bounding boxes slightly or crunch down file sizes and you could get very different inference results. Scale that scenario to hundreds of models, and it quickly becomes unmanageable. Being able to systematically reproduce those experiments requires rigorous data versioning, data lineage and model lifecycle management techniques.
Big companies that offer “all in one” platforms are multiplying. If the space is so new and confusing, how can execs be expected to roll their own platform from scratch? But as the needs of businesses become more specialized, so too are the products emerging to fit those needs. A wave of narrowly focused open source products are now viable platform competitors.
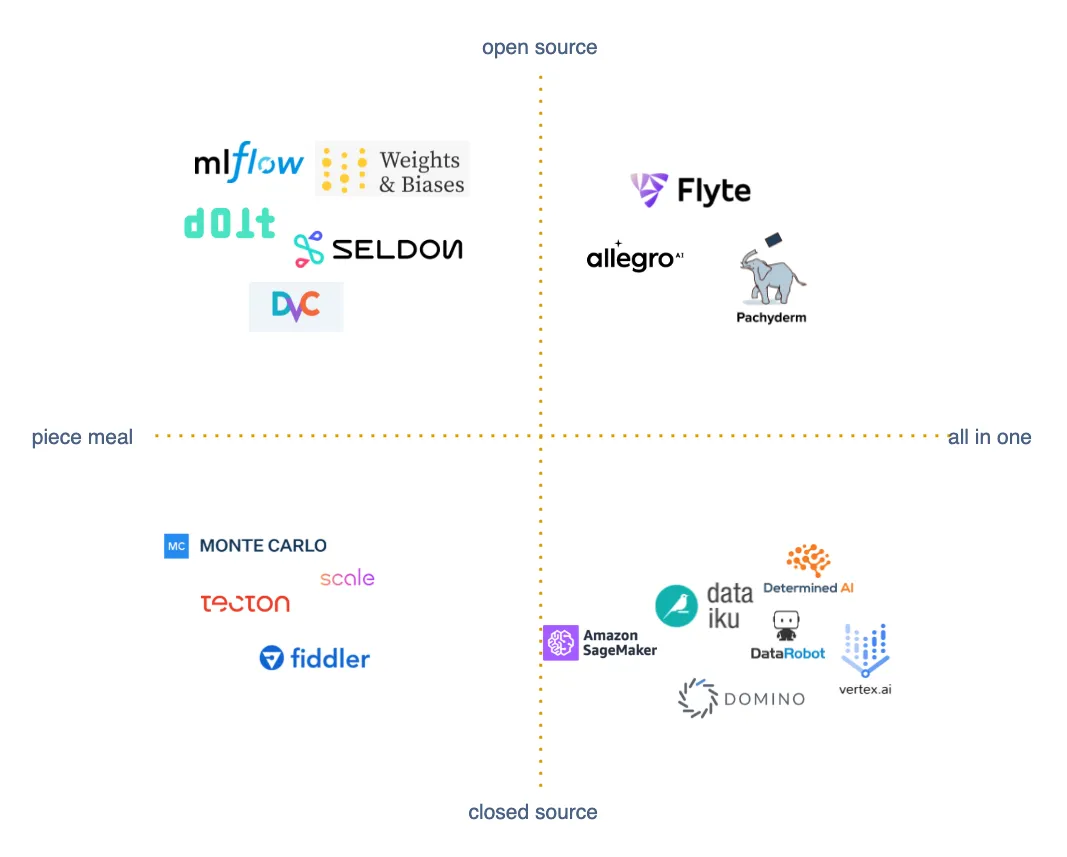
The top left quadrant are open source projects delivering focused supportive tools. In the top right, we have compute and automation systems that deliver a range of data, pipeline, and visualization tools all in one platform. The bottom right includes closed source, enterprise lock in platforms that span data science, analytics, and model serving. Lastly, the bottom left is a handful of closed source tools that outsource specific processes for enterprise customers. For a more comprehensive list of tools, refer to this infographic.
In this blog, we will discuss how we took the opposite approach of “all in one” platforms. We merged several open source tools into a coherent ML platform in three months, avoiding the pitfalls of “rolling your own.” There are benefits and tradeoffs to both approaches, but every year it becomes easier and cheaper to combine best of breed tools rather than acquiesce to enterprise lock in. You can now choose optionality without sacrificing quality. If you find that as exciting as us, read on!
Scaling an ML Team#
When a partner asked us to build a platform, our first move was documenting their existing infrastructure. At the beginning of the project they had a team of analysts, and one lone data scientist. The data scientist trained models on an on-premise GPU rack, saved results to a local MLflow instance, and used Jupyter notebooks as helper automation scripts. Analysts mostly focused on cleaning and cataloging training data in Google Sheets.
Next, we dove into the partner’s present and future ML goals. A handful of original models had ballooned to 50, on track to pass 100. Each model includes several new sources of data. Tracking data management is as important as logging model artifacts. The team is growing, and it is impractical for a single data scientist to manually track every data source and model themselves.
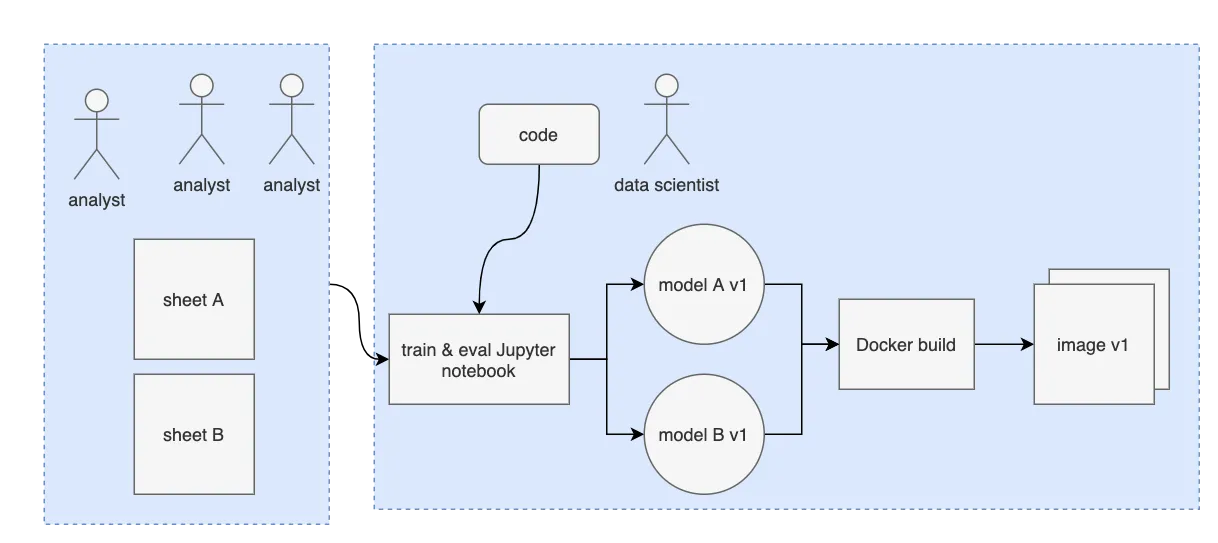
In summary, we want to automate data versioning, model training, and image building downstream of analyst data changes. The higher our workflow fanout, the more important it is to log and track the inputs and outputs of each job. The system is reminiscent of the Pachyderm mission quote, but our partner wanted a custom solution.

Piecing Together the Jigsaw#
We joined this project because Dolt is the only database that offers complete Git versioning for data. Dolt databases are MySQL compliant but can be created and edited locally, replicated to remote servers, and incrementally improved with Pull Requests. Our partner wanted to sync changes in training sheets into the database, verify those changes using diffs in DoltHub’s UI, and trigger new model builds on commit (see our Gsheets integration blog for more details).
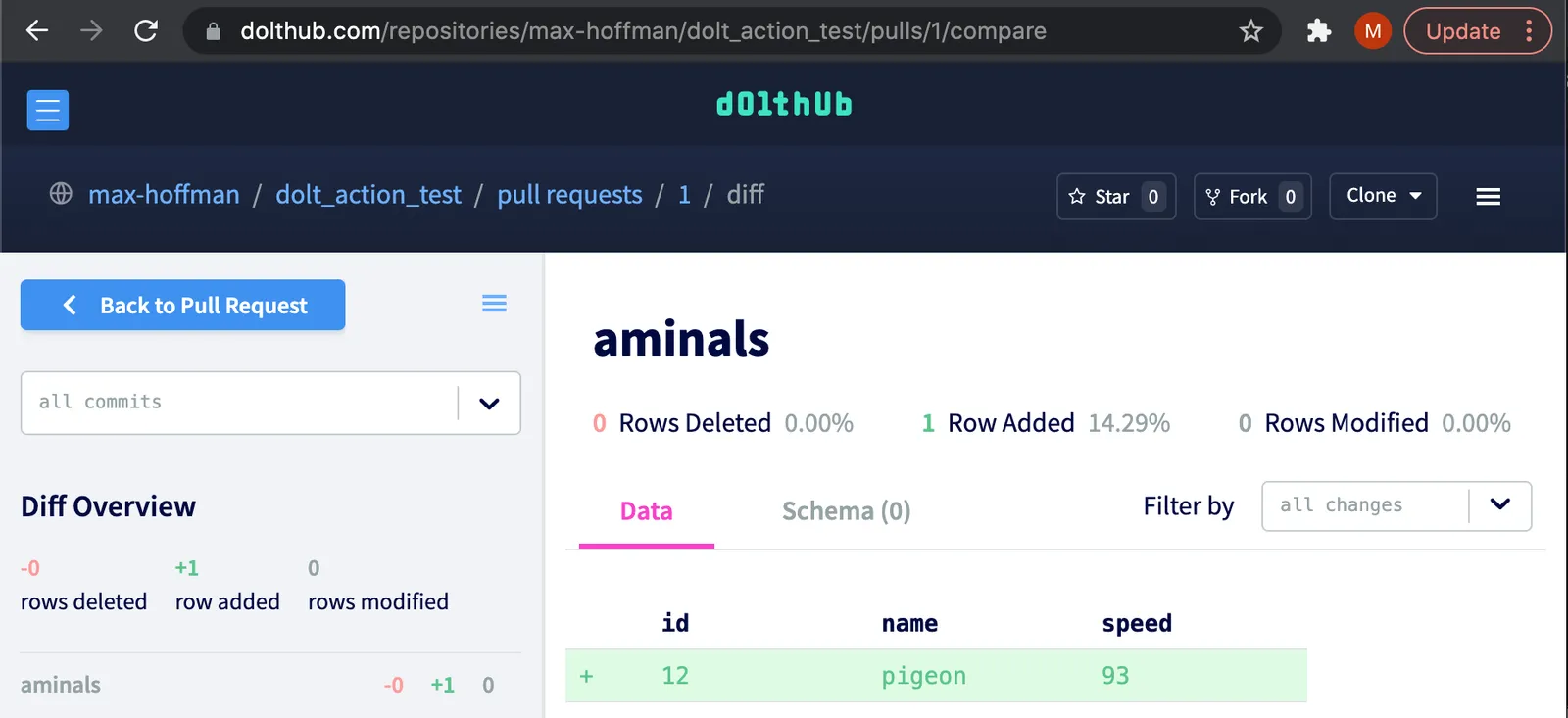
Dolt is not an aspiring ML platform. We focus exclusively on making a better SQL database. So we needed to plug gaps with complementary tools.
The “control plane” for executing jobs was the biggest initial decision. We want a continuous integration (CI) system, and decided to use GitHub Actions to schedule jobs. GitHub Actions is closed source, but also a free product offered by what has become a basic engineering utility. GitHub is unlikely to aggressively monetize Actions, and we can switch to an open source solution if something does change. The upside of bundling source control and CI is also a clear win. We can write arbitrarily complex scripts with control flow and job composition as it suits our changing needs.
Here is what is looks like to start a job:

And here is how logs are aggregated during and afterwards:
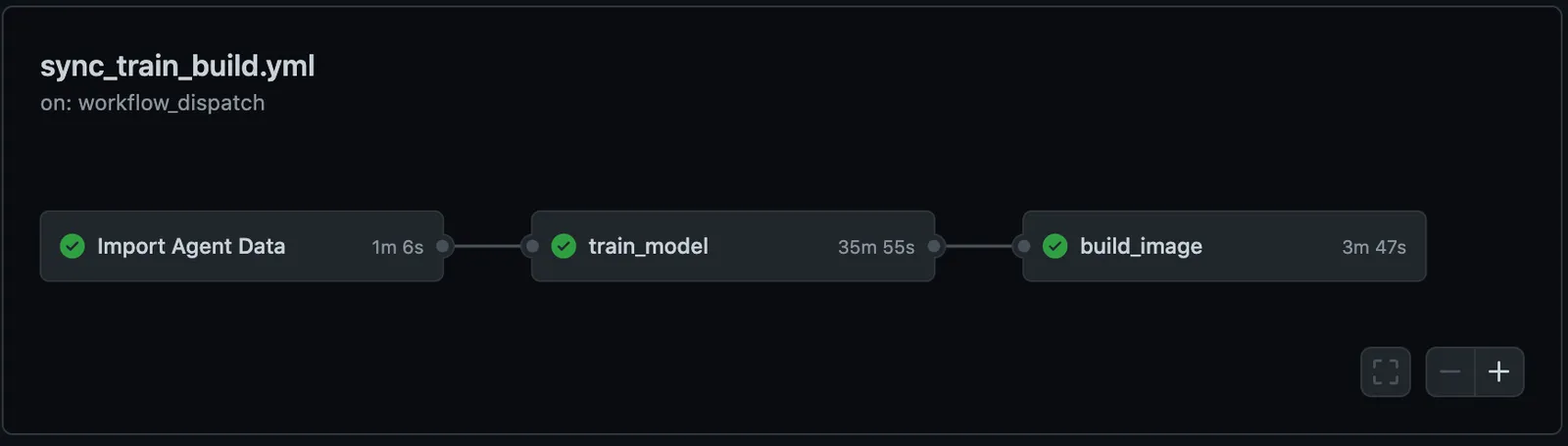
Next, we decided to continue using MLflow to store training metadata. GitHub saves versions of code, Dolt saves versions of data, and MLflow tags models with respective commits versions.
MLflow is a good choice because it is a narrowly focused, open source logging library that encompasses the training lifecycle. An experiment tracker with a better user experience can be swapped without changing other components of the system.
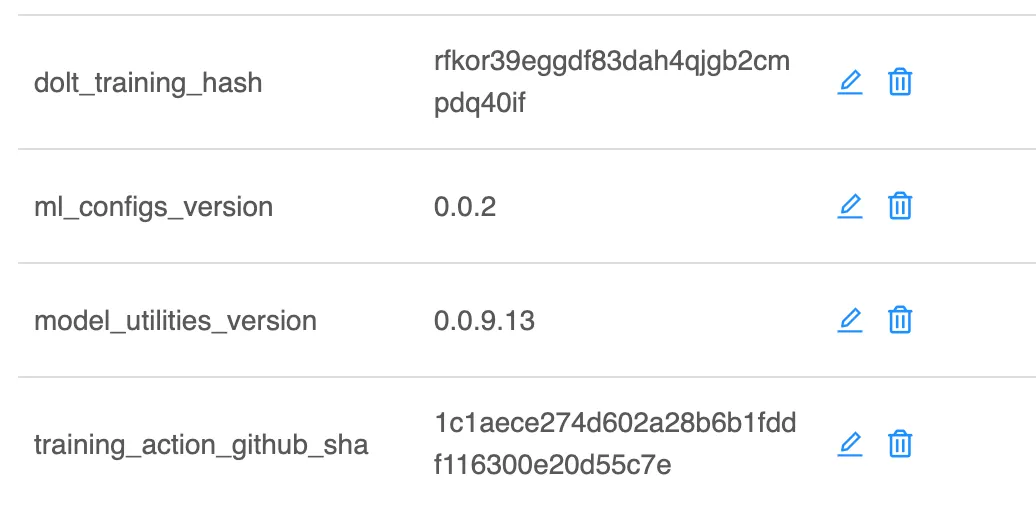
Bookkeeping production releases introduces one last problem for our partner. Production Docker images include adapter models for each of their customers. In other words, how do we track 100 adapter model versions for each release? Instead of provisioning a second database, we repurposed the MLflow backend. The model names and versions are encoded as a json string, MD5 hashed, and inserted into our backend:
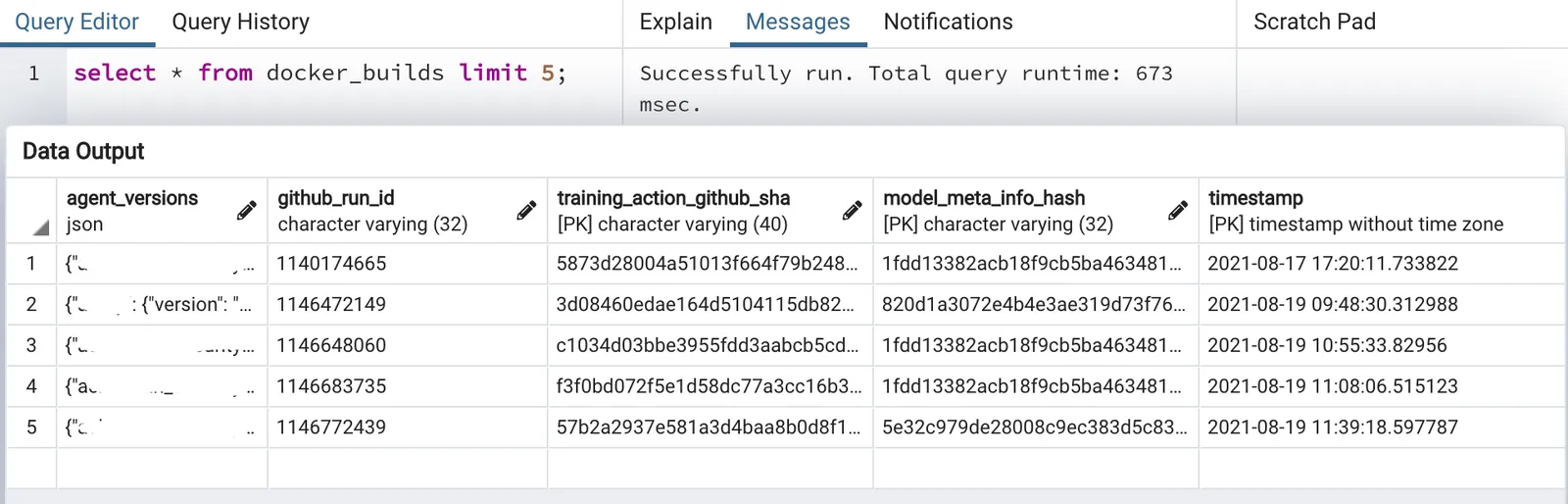
A Docker image is tagged with the accompanying model versions hash. If we wish to rollback to a previous collection of models, we can ship a previously built image. If we want to rollback a single model version, we use the MLflow API to tag the “latest production model” and build a new image.
Here is the system running at full capacity:
SaaS Pricing#
Costs depend on workload and choice of compute provider. Our partner already had purchased on-premise GPUs, a sunk cost. The closest comparable AWS instance is much more expensive per year, but does not involve maintaining hardware. The closest comparable Pachyderm instance includes a markup on each compute hour for included platform services. Pricing for another platform I looked at, DataRobot, starts around 100k a year for 6 worker instances. Here is a summary of our findings:
| compute | fixed | variable | year 1 | year 2 |
|---|---|---|---|---|
| self | 30,000 | 3600 | 33,600 | 37,200 |
| aws | 0 | 43,083 | 43,083 | 86,166 |
| pachyderm | 0 | 67,738 | 67,738 | 134,756 |
| datarobot | 0 | 98,000 | 98,000 | 196,000 |
The AWS and Pachyderm numbers can be reproduced on their respective pricing pages. We selected the most similar compute instance in each case, AWS p2.8xlarge is 8 GPU/32 CPU/488 GB, and Pachyderm 8 GPU/16 CPU/23 GB. The self hosted fixed costs is the GPUs rack, and the variable cost is a cloud hosted database (RDS/Dolt).
It is important to avoid comparing apples and oranges here. Cloud billing is usage based, and you rarely use 100% of the compute hours reserved. Likewise, office hardware does not scale the same way as cloud Kubernetes clusters. Still, cloud bills often slip beyond estimates. Fractionally used resources are billed as wholes. Re-running week long training jobs use more CPU hours than you expect. Our customers hardware was a sunk cost, and they will pay little monthly bill until either the hardware fails, or they scale 10x. Your mileage may vary.
Balancing Operational Quality of Life#
You control your own fate with open source tools. For a nontechnical team, that may be a liability. It can be reassuring to outsource infrastructure risk for something that is not a key differentiator in your business. Organizational habits accrete around enterprise software in a way that makes it difficult to change systems in the future, however.
Our partner could replace Dolt with a legacy MySQL database, or DVC if training data is unstructured, or a Delta Lake for a team with append only data. At some point they will scale, but delaying the complexity of Kubernetes lets them focus on business goals sooner.
New ML tools will exist in the future, for which abstraction patterns will inevitably converge. Alternatives, improvements, and upgrades for your business are near at hand if you plan for it.
Conclusion#
The market for ML platform is messy, changing rapidly, and fraught with hard questions. It is difficult to quantify the business value of one unit of ML infrastructure. On the bright side, it is now possible to plan for that uncertainty. Building cheaper, flexible systems that better accommodate change beats the pitfalls of enterprise SaaS lock in. We described a case study of one modular open source platform here.
Our partner uses GitHub Actions to schedule, execute, and reproduce workflows on custom hardware. They support both CPU based jobs, like syncing analyst data into a Dolt relational database, and GPU jobs, like training 100 NLP models in parallel. Metadata is tracked in two stages: once for each model, and a second time for each collection of models packaged into a production release. Each of the chosen tools can be changed over time. The system can grow to support 1000 adapter models without changing the way code, models, and data are versioned.
If you are interested in asking us about ML platforms or version controlled databases, feel free to reach out on Discord!