
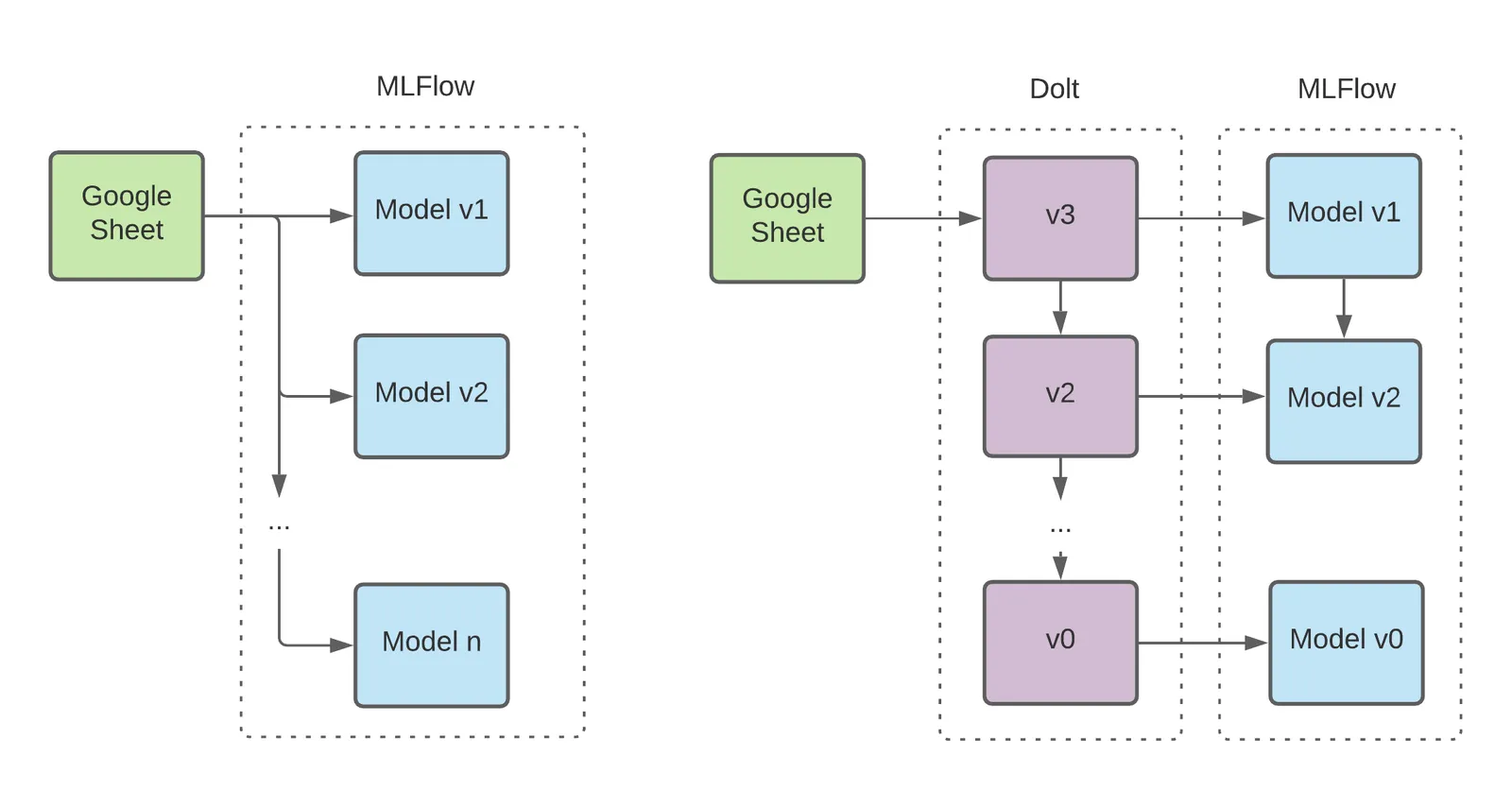
Introduction#
We will learn how to version control Google Sheets data using Dolt and GitHub Actions today. This is intended for teams who might benefit from a Pull-Request process for managing Google Sheets data changes, complete with strong typing, lineage tracing and diff management. We will touch on branch, diff, merge and rollback operations in a simple tutorial.
Background#
Google Sheets is a common format for storing all sorts of data, including data used for analysis and model training. When used in engineering workflows, Sheets are often converted into a more durable format, like an SQL database or S3 files. Moving data is a technical challenge, but also an organizational process that bridges individuals and teams.
Dolt is an SQL database with Git style versioning. The Dolt storage layer is designed to support clone, branch, diff and merge as first class citizens. At the same time, Dolt can be run as a server 99% compatible with MySQL’s features.
At Dolt, we believe data versioning as a habit allows teams to more confidently ship data products. Avoiding data duplication is helpful, but, more importantly, versioning provides a way for teams to collaboratively branch, Pull Request (PR) and merge data changes. Dolt is the only database that provides diffs, the simplest way to observe, coordinate and historically trace how data changes over time. The indispensible features that Git provides for source code, Dolt provides for data, the lifeblood of machine learning operations.
Using Dolt to version Google Sheets data introduces the best of both worlds. First, data is versioned and saved in a format more amenable to data science. Second, organizations can develop a process for coordinating the progression of data quality and rollbacks between teams.
Data Syncing#
Today we consider a use case where data management is divided between analysts and data scientists. Analysts edit data and train models with pre-set hyperparameters. Data scientists refine model architectures and track production quality. The two experts collaborate to deliver clean data and accurate models. Google Sheets is an organizational dividing line between the two camps.
This handoff creates several problems. The data is always changing because analysts are always improving, mixing and matching training rows. Understanding how data differences impact successive model versions is not feasible in the first setup. Rollbacks are limited, given the difficulty reproducing past training phases. Productionizing a model in this instance requires packing dozens of adaptor layers and one base model into a docker image. If we experience a regression, our options are to either rebuild everything with the newest data versions (assuming the offending model was fixed), or rollback to the last built image and clobber every adaptor upgrade.
The next iteration of this data process adds versioning between analysts and data scientists. If we were interested strictly in reproducibility, we could export GSheets into CSV files named by timestamp. A forced rollback would involve retraining the offending model on an old version of data and pushing the individual fix.
The organization handoff and importance of data changes increases the appeal of Git/Dolt style versioning workflows. Dolt workflows separate the “production” version of data from “development” branches. Pull requests let analysts comment on each other’s additions before they are merged to a master branch. Data diffs provide a human friendly interface to review proposed changes. And commit versioning provides release tagging, rollbacks, and point-in-time queries, all particularly helpful as the number of data and model versions in each Docker image scale.
See It In Action#
Our Github Actions workflow file (found here) includes three steps:
-
Download sheets into temporary CSV files (dolthub/gsheets-to-csv).
-
Import the CSV files into a Dolt table and push results to DoltHub (dolthub/dolt-action).
-
Log the import diff (if any) in our workflow logs.
name: Import GSheets into Dolt
on:
workflow_dispatch:
env:
id: "16iUpjhWnPYDo4OUwxv1TlF9x975iPJ2WABgmpoJJdNY"
remote: "max-hoffman/dolt_action_test"
branch: "dev"
jobs:
plugin_tests:
runs-on: ubuntu-latest
name: Test Plugin
steps:
- name: Step 1 - Download Agent Data
id: "sheet_to_csv"
uses: dolthub/gsheets-to-csv@v0.5
with:
creds: ${{ secrets.GOOGLE_CREDENTIAL }}
tempdir: ${{ github.workspace }} #/github/workspace
sheets: |
[
{ "id": "${{ env.id }}" },
{ "id": "${{ env.id }}", "title": "Sheet2", "range":
"A1:C10" }
]
- name: Step 2 - Dolt Import
uses: dolthub/dolt-action@v0.5
id: "dolt_import"
env:
FILES: ${{ steps.sheet_to_csv.outputs.results }}
with:
before: |
file_list=($FILES)
head "${file_list[1]}"
for file in "${file_list[@]}"; do
dolt table import --update-table -pk id aminals "$file"
done
remote: ${{ env.remote }}
branch: ${{ env.branch }}
commit_message: "Dolt action commit"
dolthub_credential: ${{ secrets.DOLTHUB_CREDENTIAL }}
push: true
- name: Step 3 - Table Diff
uses: dolthub/dolt-action@v0.5
id: "training_diff"
if: steps.dolt_import.outputs.commit != ''
with:
remote: ${{ env.remote }}
branch: ${{ env.branch }}
dolthub_credential: ${{ secrets.DOLTHUB_CREDENTIAL }}
before: |
dolt diff HEAD^ HEADTwo inputs are required to run this workflow: DOLTHUB_CREDENTIAL and
GSHEETS_CREDENTIAL. The DoltHub credential can be substituted for AWS
or GCP credentials to access respective database remotes. Your local
DoltHub credential can be found in ~/.dolt/creds:
$ ls ~/.dolt/creds
-rw------- 1 max-hoffman staff 175 Mar 31 15:39 7on1utvveb1uoakrc9ku9m2abotsg2q9mhph68i072un0.jwk
-rw------- 1 max-hoffman staff 175 Mar 31 15:40 jsgj5bnsu0olp8n95gom7vfmahi6h4n2eaf578kuti2aq.jwkGoogle Cloud service account credentials are currently required, even for public Google Sheets. The Google Cloud service credential can double as authorization for a GCP Dolt remote.
{
"type": "service_account",
"project_id": "dry-icicle-281492",
"private_key_id": "a3cdbe532c4ad7g6x4vv700cgge4683e131331gg",
"private_key": "-----BEGIN PRIVATE KEY-----\...n-----END PRIVATE
KEY-----\n",
"client_email": "runner@dry-icicle281492.iam.gserviceaccount.com",
"client_id": "131822607917526703563",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url":
"https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url":
"https://www.googleapis.com/robot/v1/metadata/x509/runner%40dry-icicle-281492.iam.gserviceaccount.com"
}With the proper credentials set, we can run the workflow:
Successful output logs (simplified for clarify) are detailed in the following section.
Step 1:#
Download the entire first sheet, and A1 through C10 of the sheet named Sheet2.
downloading sheet: ***'id':
'16iUpjhWnPYDo4OUwxv1TlF9x975iPJ2WABgmpoJJdNY'***
downloading sheet: ***'id':
'16iUpjhWnPYDo4OUwxv1TlF9x975iPJ2WABgmpoJJdNY', 'title': 'Sheet2',
'range': 'A1:C10'***Step 2:#
Clone the repo, head the first file, and import both files into a Dolt repository.
+ dolt clone max-hoffman/dolt_action_test -b master
+ /github/workspace/doltdb
cloning https://doltremoteapi.dolthub.com/max-hoffman/dolt_action_test
Retrieving remote information.0 of 49 chunks complete. 0 chunks being
downloaded currently.0 of 49 chunks complete. 1 chunks being downloaded
currently.1 of 49 chunks complete. 0 chunks being downloaded currently.1
of 49 chunks complete. 4 chunks being downloaded currently.1 of 49
chunks complete. 6 chunks being downloaded currently.5 of 49 chunks
complete. 2 chunks being downloaded currently.7 of 49 chunks complete. 0
chunks being downloaded currently.7 of 49 chunks complete. 1 chunks
being downloaded currently.8 of 49 chunks complete. 0 chunks being
downloaded currently.8 of 49 chunks complete. 2 chunks being downloaded
currently.10 of 49 chunks complete. 0 chunks being downloaded
currently.10 of 49 chunks complete. 6 chunks being downloaded
currently.10 of 49 chunks complete. 14 chunks being downloaded
currently.16 of 49 chunks complete. 8 chunks being downloaded currently.
24 of 49 chunks complete. 0 chunks being downloaded currently.24 of 49
chunks complete. 4 chunks being downloaded currently.28 of 49 chunks
complete. 0 chunks being downloaded currently.28 of 49 chunks complete.
4 chunks being downloaded currently.28 of 49 chunks complete. 7 chunks
being downloaded currently.28 of 49 chunks complete. 10 chunks being
downloaded currently.31 of 49 chunks complete. 7 chunks being downloaded
currently. 34 of 49 chunks complete. 4 chunks being downloaded
currently.38 of 49 chunks complete. 0 chunks being downloaded
currently.38 of 49 chunks complete. 4 chunks being downloaded
currently.38 of 49 chunks complete. 8 chunks being downloaded
currently.42 of 49 chunks complete. 4 chunks being downloaded
currently.46 of 49 chunks complete. 0 chunks being downloaded
currently.46 of 49 chunks complete. 3 chunks being downloaded
currently.49 of 49 chunks complete. 0 chunks being downloaded currently.
+ head /github/workspace/tmp1.csv
id,name,speed
11,crocodile,20
12,pigeon,93
+ dolt table import --update-table -pk id aminals
+ /github/workspace/tmp0.csv
Import completed successfully.
Rows Processed: 6, Additions: 0, Modifications: 0, Had No Effect: 6
+ dolt table import --update-table -pk id aminals
+ /github/workspace/tmp1.csv
Import completed successfully.
Rows Processed: 1, Additions: 1, Modifications: 0, Had No Effect: 0
+ dolt commit -m 'Dolt action commit'
commit hph1gdos395fnfkrenfts9q8hd6r2qam
Author: GitHub Actions <actions@github.com>
Date: Tue Jun 15 21:33:44 +0000 2021
Dolt action commit
+ dolt push origin master
Tree Level: 7 has 6 new chunks. Determining how many are needed.Tree
Level: 7 has 6 new chunks of which 5 already exist in the database.
Buffering 1 chunks.
Tree Level: 7. 100.00% of new chunks buffered.
Tree Level: 1 has 3 new chunks. Determining how many are needed.Tree
Level: 1 has 3 new chunks of which 2 already exist in the database.
Buffering 1 chunks.
Tree Level: 1. 100.00% of new chunks buffered.Step 3:#
Log the difference between the last two commits if we added data during the import step.
+ dolt diff 'HEAD^' HEAD
diff --dolt a/aminals b/aminals
--- a/aminals @ lr8e0ubininvlj936vfvsp23ctvklaoo
+++ b/aminals @ 0988hnjk7jftb9h30sfau81g7b8k7b3n
+-----+----+--------+-------+
| | id | name | speed |
+-----+----+--------+-------+
| + | 12 | pigeon | 93 |
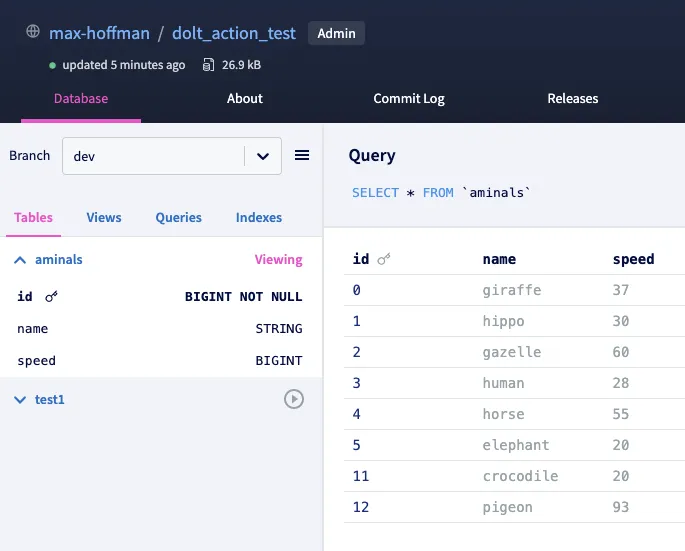
+-----+----+--------+-------+Afterwards, we verify our workflow completed successfully:

And observe our updates in DoltHub:
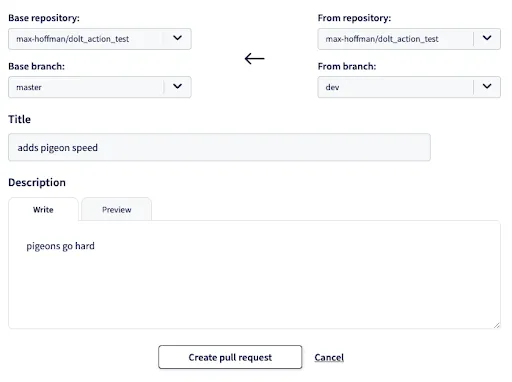
We pushed data to the dev branch. We can create a Pull Request to
apply these changes to master:
And view the diff in DoltHub before merging to master:
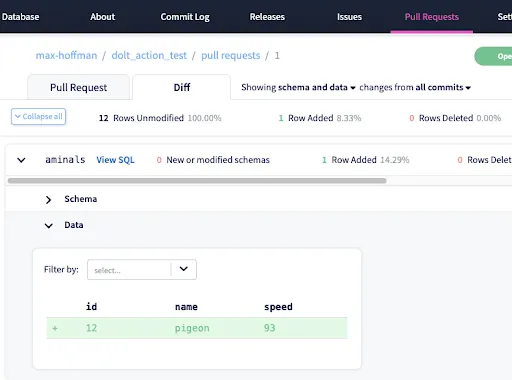
Future Work#
As mentioned previously, Google service account credentials are required, even for public data. We should make this config field optional in the future.
Database caching between steps is another potential improvement. Databases currently self-delete at the conclusion of a workflow step. Two sequential steps, like importing into a database followed by printing a diff log in the event of a commit, require two full clones. The complexity of GitHub actions working directories between steps make this feature a bit more difficult to implement, but more valuable for large workflows.
Summary#
We have discussed how to sync Google Sheets data into Dolt with GitHub Actions. This integration was motivated by a customer whose analytics and model management responsibilities are divided between teams who stand to benefit from data versioning, a branch and merge PR process to standardize data handoff, and diffs/rollbacks for responding to production regressions.
Bringing order to data management is essential for improving organizational data quality, and by extension model and pipeline quality. A Pull Request process bring data diffs and lineage front and center, making it easier to understand how data is changing and collaborate on QA between versions.
If you are interested in trying these plugins yourself, you can find dolthub/gsheets-to-csv and dolthub/dolt-actions on GitHub. If you are interested in asking the Dolt team questions about your data infrastructure, feel free to reach out to us on Discord.