
Dolt, the world’s first SQL database with Version Control capabilities in its bones, has some new tricks! We’ve been discussing Automatic Garbage Collection and the Archive storage format for some time now. With the release of Dolt 1.75, we’ve taken the leap and made both of these behaviors enabled by default.
Today we’ll discuss a little about the advantages of these two features. Then we’ll talk a lot about how to disable them if you run into trouble. These changes are all deep in the layers where we store and manage raw data, and we have taken every measure we can think of to verify they are production-ready. Nevertheless, there are legitimate reasons to disable these features and we’ll cover them.
New Behaviors in a Nutshell#
Dolt stores all of its data in chunks. These are similar to blobs in Git - they are binary data blocks which are keyed by their content using their cryptographic checksum. chunks are immutable, by virtue of the fact that you can’t change the content of a chunk without also changing its key. If the concept of content-addressed storage is new to you, read this.
When Dolt is doing its work storing your data, it needs to create temporary chunks. When you commit, the chunks which make up that commit are required to be saved for the entire life of the database. To put a finer point on this, if you perform two insert operations on your database, you’ve created garbage. This is because after the first insert, you’ve created a database state which is surpassed by your second insert. The second state of the database is recorded forever in a commit, so the data that makes it up will never be garbage.
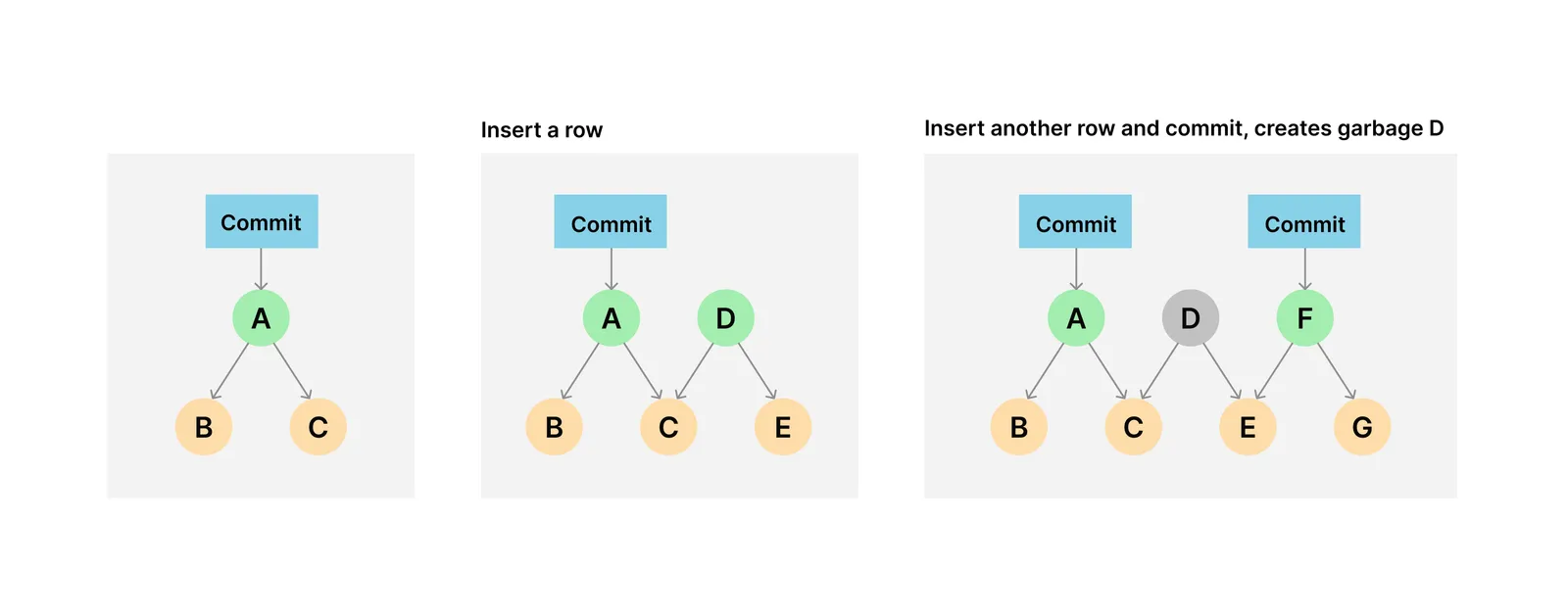
If you have a dolt sql-server running for weeks or months, every time a person or process modifies data without committing it, there is garbage. You could enable commit on transaction, which would simply create a commit for every update - but that isn’t necessarily what you want either because you end up with a bunch of commits you never care about.
Dolt’s creation of garbage is an unavoidable fact. This is why we’ve enabled garbage collection by default.
How about Archives? The Archive file format was developed primarily to reduce the amount of space used by the chunks the garbage collection process determines are necessary to keep forever. First, we use zStd compression, which gives us about 30% compression improvement right out of the gate. Second, zStd compression enables us to use dictionary compression so we can pack groups of highly similar chunks together on disk. This is similar to delta encoding performed in Git, but more appropriate for binary data while Git’s approach shines with text. We haven’t enabled the ability to group chunks by default yet, as that can produce a lot of load on your server. The ability to do it is enabled by the format, which is why we’re making it the default. It’s a better format for where we are heading long term.
In a nutshell, these two features are about reducing the amount of disk space needed by your Dolt database. AutoGC will keep your garbage to a minimum without you needing to care, and we’ll compress the critical chunks more than before thanks to Archives.
Tricky Details#
We built these features and labeled them as “experimental” while we gained confidence in them. AutoGC is tricky because, in a transactional multi-user database, there are many cases where the garbage collector needs to be session-aware to ensure that no critical chunks are erroneously deleted in the middle of a transaction.
Archives have a different problem: Dolt is a replicated database, and the format of bytes on disk bleeds out from your local instance. For example, there is a database on Dolthub.com that two people, Adam and Eve, have cloned. If Adam decided to compress his database using the dolt archive command, when he pushes changes to Dolthub.com, the format will affect Eve when she pulls changes from Dolthub.com. She’ll first need a version of Dolt which understands the new format, or she’ll need to convert the chunks into the legacy format when she pulls changes.
Due to this distributed data problem, even though the Archive format has existed for more than a year, every time you push and pull your data, we convert it into the legacy format. Switching to Archives by default means that Archives become the format you push and pull with. We built awareness of Archives into versions of Dolt more than a year ago, so if you are using a client which doesn’t work fully with the new format you will get a sensible message that you need to upgrade your Dolt version. That said, the ideal situation would be that all users of a given database upgrade to Dolt 1.75 proactively. Otherwise, there will be a period of time where unnecessary computation is required to convert chunks into the preferred format of the client you are using.
I have to mention that Git has this problem too. If they did develop a new storage format, then users of Git would be forced to be aware of what format was used for a given repository. Amazingly, they have never once updated their storage format, which I consider remarkable:
$ git config get core.repositoryformatversion
0Disabling#
Now that you are aware of why these changes are coming to a database near you, let’s discuss why you might want to disable these features and how.
AutoGC#
AutoGC is hopefully a feature you have no reason to turn off. I believe there is no application logic reason to disable it unless you suspect it is causing adverse side effects. This might look like excessive CPU utilization or delayed queries. Please contact us if you believe you are having trouble with this feature.
AutoGC shows up in two contexts:
- A running
dolt sql-server - Using
dolt sqlwhen no sql-server is running.
dolt sql-server configuration files are used to encode your server’s configuration. It’s possible to run a server without this file, but you must have one to disable AutoGC. If you are used to running a sql-server without a configuration file, you will find an autogenerated config.yaml file which contains all of the defaults. If you already have a config.yaml file, obviously update your existing configuration. You’ll make similar changes to the following:
- # behavior:
+ behavior:
# read_only: false
# autocommit: true
# disable_client_multi_statements: false
# dolt_transaction_commit: false
# event_scheduler: "OFF"
- # auto_gc_behavior:
- # enable: true
+ auto_gc_behavior:
+ enable: false
# archive_level: 1By setting the behavior.auto_gc_behavior.enable to false, when you start your server now AutoGC will never run:
$ dolt sql-server --config config.yamlThe second place AutoGC comes up is when you are running dolt sql. Specifically, when you are running dolt sql and it is not connected to a server but directly modifying your local dolt database. Since these sessions can last a long time and you can generate plenty of garbage. AutoGC will run in the background to keep garbage to a minimum. If you determine that is slowing you down, you can disable it with the following flag:
$ dolt sql --disable-auto-gcThere you go. Garbage collection will only happen when you specifically invoke the stored procedure:
mydb/main> call dolt_gc();Archives#
The reason for disabling Archives would primarily be to avoid forcing all people/processes which push to the database from upgrading. If there are bugs or performance issues that prompt you to disable them, please contact us.
Disabling the use of Archives comes up in two contexts:
- When you are performing garbage collection
- When you are pushing and pulling to another Dolt database.
Disabling Archives during garbage collection will depend on if you are using AutoGC or not. If you are sticking with the defaults and AutoGC is good, but you don’t want Archives, then you need to update your server configuration file. The configuration field of interest is behavior.auto_gc_behavior.archive_level, and if you set it to 0, then when AutoGC runs it will produce the legacy storage format artifacts.
Changes to your server’s config.yaml file would look like this assuming you had the default file to begin with:
- # behavior:
+ behavior:
# read_only: false
# autocommit: true
# disable_client_multi_statements: false
# dolt_transaction_commit: false
# event_scheduler: "OFF"
- # auto_gc_behavior:
- # enable: true
- # archive_level: 1
+ auto_gc_behavior:
+ enable: true
+ archive_level: 0Whenever you update your config.yaml file, you need to restart your dolt sql-server:
$ dolt sql-server --config config.yamlIf you have disabled AutoGC (see above), then when you manually perform call dolt_gc() Archive formatted files will be generated. To ensure that you don’t get Archive files, you need to specify the Archive level as 0 by doing the following:
mydb/main> call dolt_gc('--archive-level', '0');Or on the CLI:
$ dolt gc --archive-level 0In the second case, where you are pushing and pulling to another database, we use an environment variable to change the default behavior. To disable pushing and pulling with the Archive format, the DOLT_ARCHIVE_PULL_STREAMER variable must be set to 0:
$ DOLT_ARCHIVE_PULL_STREAMER=0 dolt push origin main:main
[snip]Similarly you could export this value in a .zsh.rc file or in your terminal session:
$ export DOLT_ARCHIVE_PULL_STREAMER=0
$ dolt fetch origin
[snip]
$ dolt push origin main:main
[snip]With that environment variable set, when you push or pull changes to your database, the over-the-wire format will be in the legacy format. Be aware that if you are pulling Archive artifacts and have Archives disabled, you will need to decompress and recompress every chunk as you receive it, so it can be prohibitively slow.
Finally, if you want to convert all local Archive storage files back into the legacy format, you can run the following command:
$ dolt archive --revertConclusion#
Hopefully none of this is necessary and you all are delighted with the new default behavior of Automatic Garbage Collection and the Archive storage format. If you are not fully delighted, or you discover a regression which we need to address, please hop on our Discord server or file a ticket. We love hearing from our users!