
Dolt is the world’s first and only version controlled SQL database. That makes Dolt the only database with true branch and merge. The reason there are no other version controlled databases is that version control is a hard problem at scale.
One of the first questions we get these days is, how does Dolt scale? Interested engineers are worried about three dimensions:
- Versions
- Branches
- Rows
Dolt can scale to millions of all three. This article explains how.
How Git Scales#
Dolt is inspired by Git. Git scales to millions of versions and branches. To understand how Dolt scales, it is useful to first understand how Git scales.
Requirements#
This may seem obvious to some but if you want to scale to millions of something, that thing needs to be as lightweight as possible. In Git, the thing you want to scale to millions of is versions. As you’ll see later, branches in Git are named, moving pointers to a version. Versions in Git must use the least storage possible in order to store millions of them. Common actions like reading values in a version and comparing versions must use as little compute as possible.
Git makes versions lightweight by satisfying three basic requirements:
- Structural Sharing
- History Independence
- Fast Diff
Structural Sharing#
Structural sharing means portions of a version that are the same in multiple versions must share storage. In other words, portions of a version that are the same in any version are only stored once. Structural sharing is often mistaken for “only storing the deltas”. Only storing deltas is one method to achieve structural sharing. As you’ll see later, chunking and content addressing is the Git method of structural sharing.
History Independence#
History independence means that no matter how you make a version, it looks the same in storage. Order of creation does not matter. If you create files a, then b, then c, this looks the same in your version as if you created file c, then b, then a. History independence is critical for structural sharing and fast diff across branches and clones because the same object, no matter how it is created, must get the same content address to be efficiently stored and diffed.
Fast Diff#
Comparing two versions and producing the differences (ie. diff) must be fast, and thus, computationally light weight. In version control systems, comparing versions is a very common operation. Diff is the basis of merge algorithms, a must for managing branches.
Content Addressing#
Content addressing is the core technology that delivers structural sharing, history independence, and fast diff in Git.
Git uses the content of the objects it is versioning to generate a deterministic address for that object. Content addresses are generated using a hashing function, in Git’s case SHA-1, upgrading to SHA-256 at some later date. A content address is that random 40 character number you see in your Git log.
Here is the last content address I have pulled for Dolt as I write this.
$ git log -n 1
commit b56618ee55e483f5c5587f0cd455f89437bc7528 (HEAD -> main, tag: v1.53.2, origin/main, origin/HEAD)
Author: coffeegoddd <coffeegoddd@users.noreply.github.com>
Date: Tue May 13 00:07:26 2025 +0000
[ga-bump-release] Update Dolt version to 1.53.2 and release v1.53.2In Git, each individual file gets a content address. Each content address of the files in a directory (and any directories) are hashed together to form the content address of the directory. This happens recursively up to the root of your Git repository.
This picture is cribbed directly from the Git documentation. If you’ve read, Dolt documentation on Prolly Trees, it may look familiar.
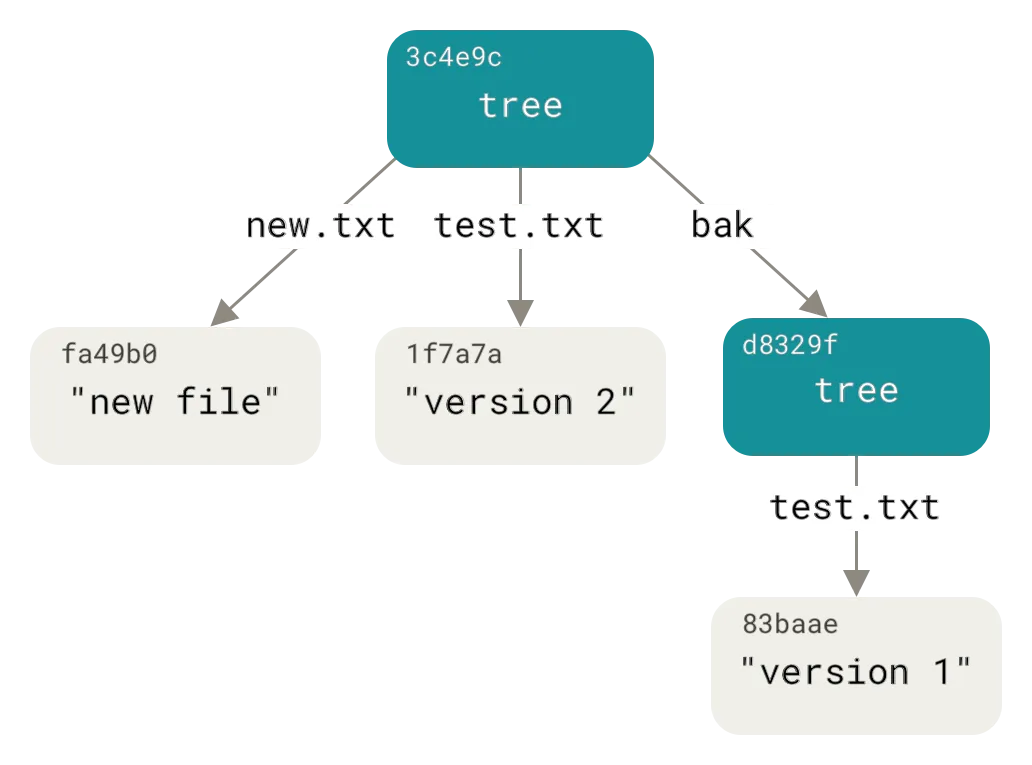
Here is Dolt’s tree as of the commit above.
$ git ls-tree b56618ee55e483f5c5587f0cd455f89437bc7528
040000 tree 5ce904af15db40d8f0a303f685ba21c169dab2c8 .github
100644 blob 7a69e78ddc1ce0548b5ea5bd0f465aafef8c981f .gitignore
100644 blob b1778fa9985eec3b7fdf83eb0b93a5ca676fb14a .gitmodules
100644 blob 5361be842ca8bad6ac534b468b2ec40653a1ebff CODEOWNERS
100644 blob d645695673349e3947e8e5ae42332d0ac3164cd7 LICENSE
100644 blob 94c4cc3c61c4c3372012e3dcff73d2de41c8310e README.md
100644 blob cfe387285367dfb2c890249feca96d76d8f4ed18 SECURITY.md
040000 tree 8458bf271e653ed40e538430b8d8a7cdc803186f docker
100644 blob b974596ca9dd638e5a9b37d16d9afa9ebe2f3712 dolt.plugin.zsh
040000 tree 795a40c894c780803d45bdf60ba509820c66c797 go
040000 tree aef130fc090afeba17c822746b5814dca91b7d60 images
040000 tree 59c28cbf8233bfe8b37964ff01467a5515d349ff integration-tests
040000 tree 8f3cfec86f9dd751944493298c9e994a8e52ae24 protoThe root content address of your Git repository is called the “root”. The most important thing in the root content address is the tree of content addresses of the objects in your Git repository.
But other important metadata is included in the root. Commit metadata like date, message, and author are in the root. This means that if two people create the exact same files and directories in a Git repository but commit it separately, the root content address will be different but the content address of the tree will be the same. The tree itself is history independent.
Git also stores one important additional piece of metadata in the root, the parent or parents of the current commit. Merge commits have multiple parents. This means, your Git repository is a directed acyclic graph (DAG) of roots. This graph is often referred to as the “commit graph” and it’s used to provide all the versioning functionality in Git.
Intuitively, you may be able to see how Git provided computationally lightweight diff using content addressing. If the content address of any sub-tree is the same, that tree is the same and can be ignored for the purpose of diff.
As you can see, Git’s content addressing provides structural sharing, history independence, and fast diff, the three requirements for scaling to millions of versions.
Branches#
Branches in Git are very lightweight as well. Branches are named pointers to roots that update when a commit is made on a branch. When you create a new branch, you create a new pointer, a small amount of metadata. Effectively, a branch is creating a new path in the commit graph.
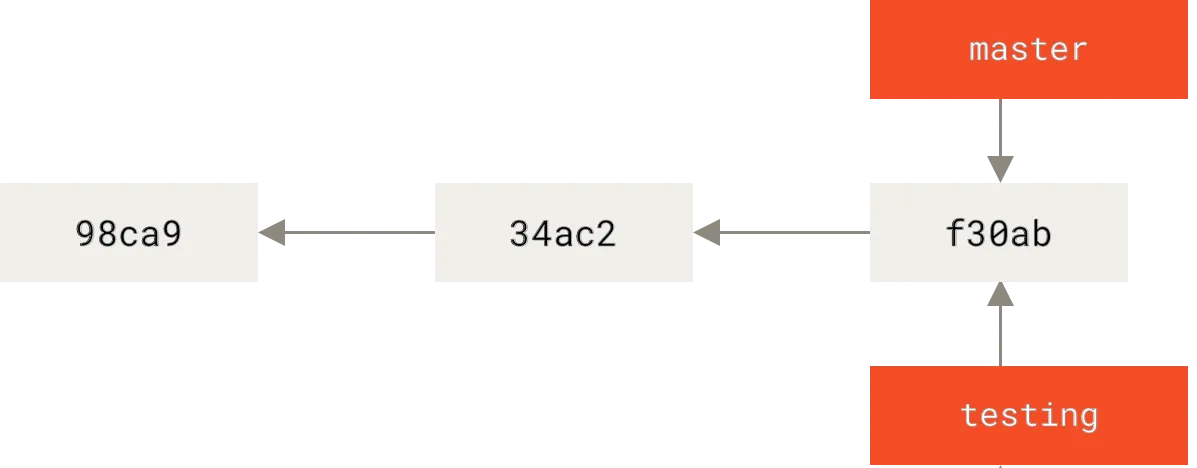
There is no additional object storage required unless a change is made on a branch. When a change is made, the unchanged portions of the tree are only stored once, using the magic of content addressing.
Branches do not need to know about other branches except for in diff and merge operations. Because diff is fast and merge is based on diff, branch operations are not computationally intensive. Branch diff and merge do not scale with the number of branches.
Thus, Git can scale to millions of branches.
How SQL Databases Scale#
After reading the above, and thinking about Dolt, you may be thinking:
So, Dolt puts CSV files in Git. Cool technology bro.
People have tried variants of this approach. The problem is databases also require fast select, insert, update, and delete on tables with millions of rows. Databases are built to scale query latency logarithmically (ie. log(n)) with the number of rows in a table. A humble CSV does not meet this requirement.
Yes, databases are backed by files on disk. These files represent data structures that allow for fast querying. If you versioned, say, the data storage directory of a MySQL database, the results would look like gibberish to Git. You would get no structural sharing of your commits. Your diffs would be of binary files. This approach would not scale.
B-trees#
Most modern databases are built on variants of B-trees. A B-tree is data structure that maps keys to values. A B-tree stores key-value pairs in leaf nodes in sorted order. Internal nodes of a B-tree store pointers to children nodes and key delimiters. Everything reachable from a pointer to a child node falls within a range of key values corresponding to the key delimiters before and after that pointer within the internal node.
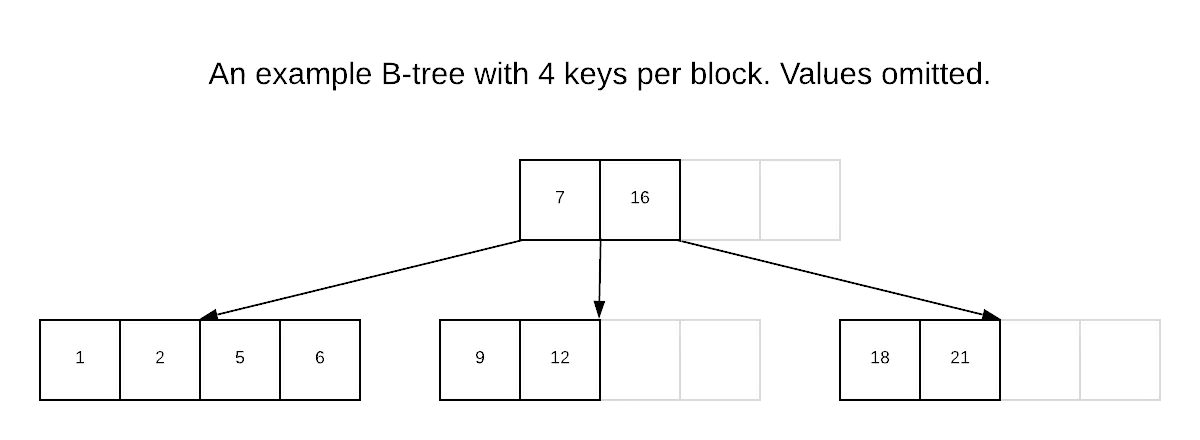
Databases store their tables and indexes in B-trees. In row major databases like MySQL and Postgres, the primary key of your table is the key and the values of each column are the value. Your rows live in the leaf nodes of the B-tree and the internal nodes are used to find rows quickly.
For the purposes of version control, B-trees are not history independent and thus portions of the tree cannot be structurally shared. If you insert row a, then b, then c, you may get a different tree than if you insert row c, then row b, then row a. B-trees offer no facility for fast comparison. Comparison complexity scales with the size of the tree. You walk both trees in sorted order, noting the differences.
B-tree do not provide structural sharing, history independence, and fast diff, the three requirements for scaling to millions of versions but they do scale to millions of rows.
Dolt has Content Addressed B-Trees#
Git’s content addressed storage scales to millions of versions via content addressing. B-trees scale to millions of rows. I wonder if one could make a content-addressed B-tree?
To do that, the B-tree would first need to be history independent, meaning no matter how you created the tree it looked the same in storage. Then, you could chunk that tree up into pieces and give each piece a content address. Any piece that was shared would only be stored once giving you structural sharing. Then, just like the Git tree, intermediate nodes in your content addressed B-tree would be hashed from the content addresses of their children, all the way up to the root of the B-tree. We didn’t invent them, the good folks that built Noms did, but these content-addressed B-trees exist. They are called Prolly Trees, short for probabilistic B-tree.
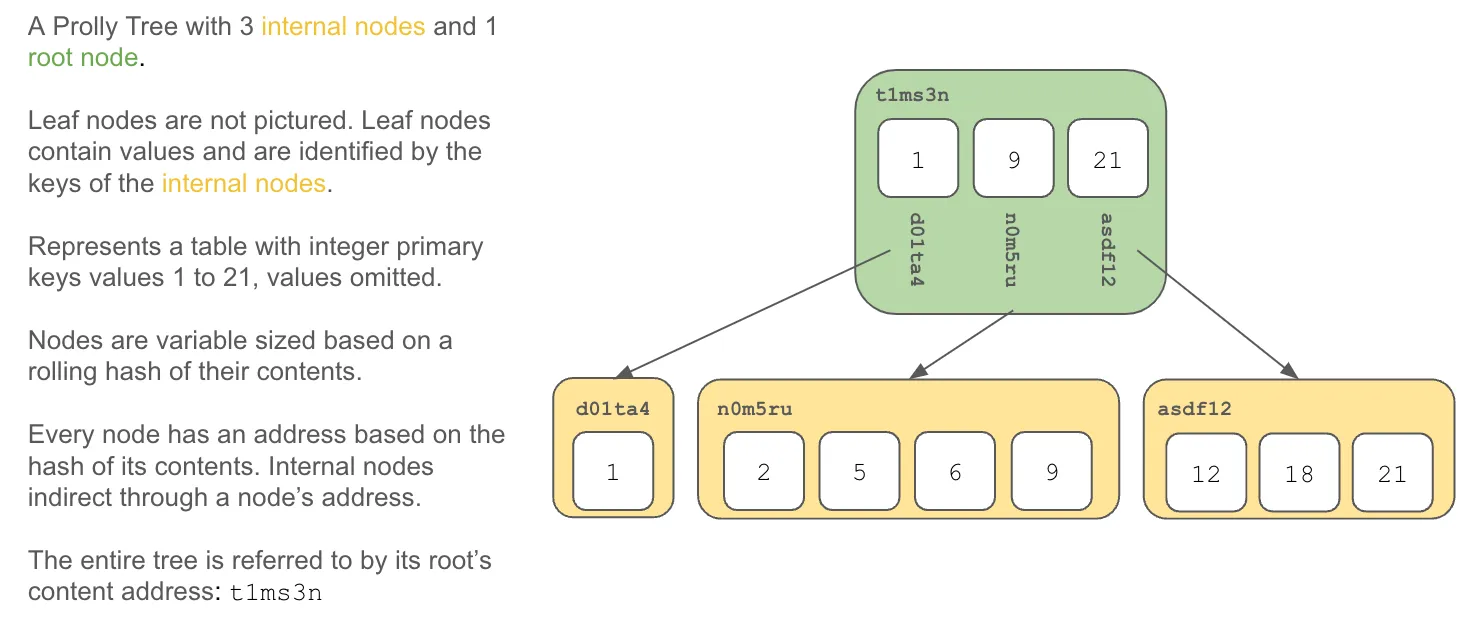
Almost everything in Dolt is a Prolly Tree: tables, schemas, indexes.
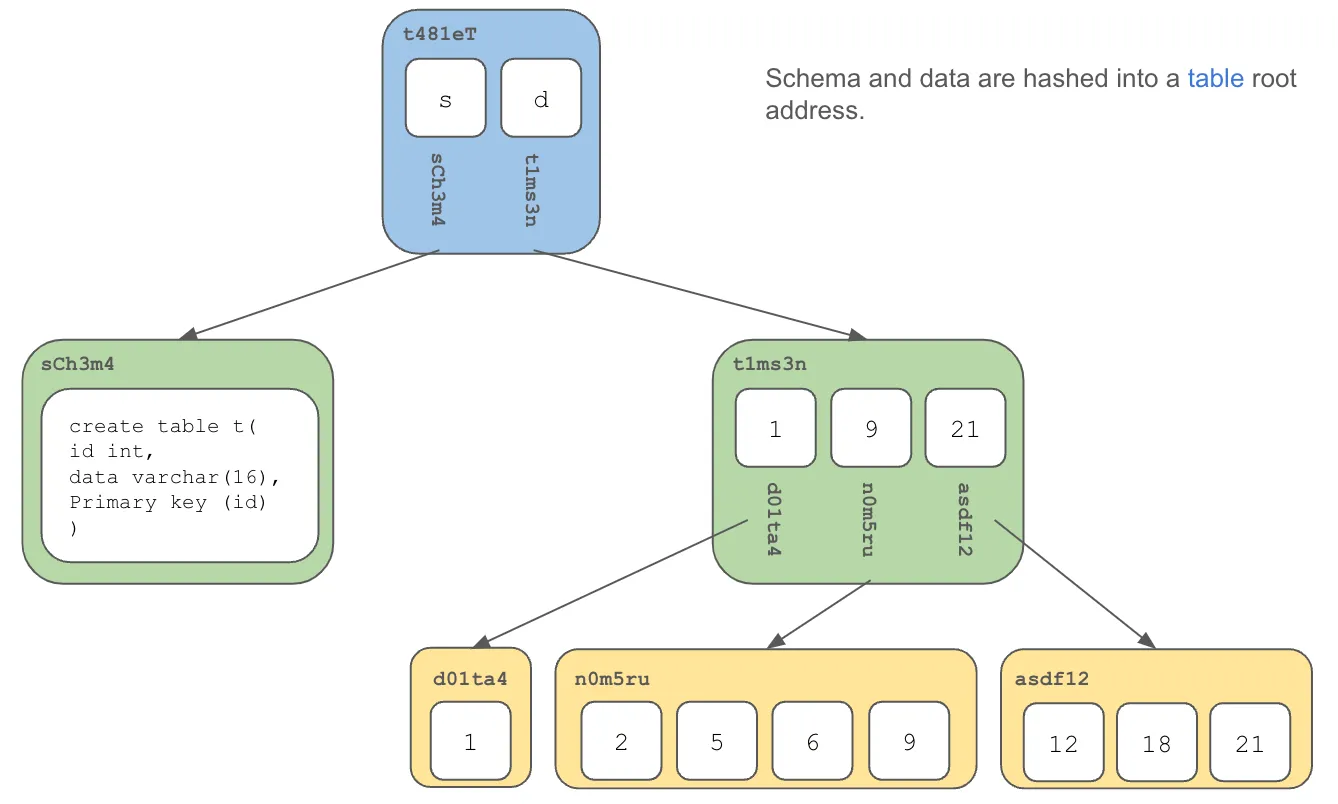
This allows your database to be summarized into a root content address, just like a Git repository.
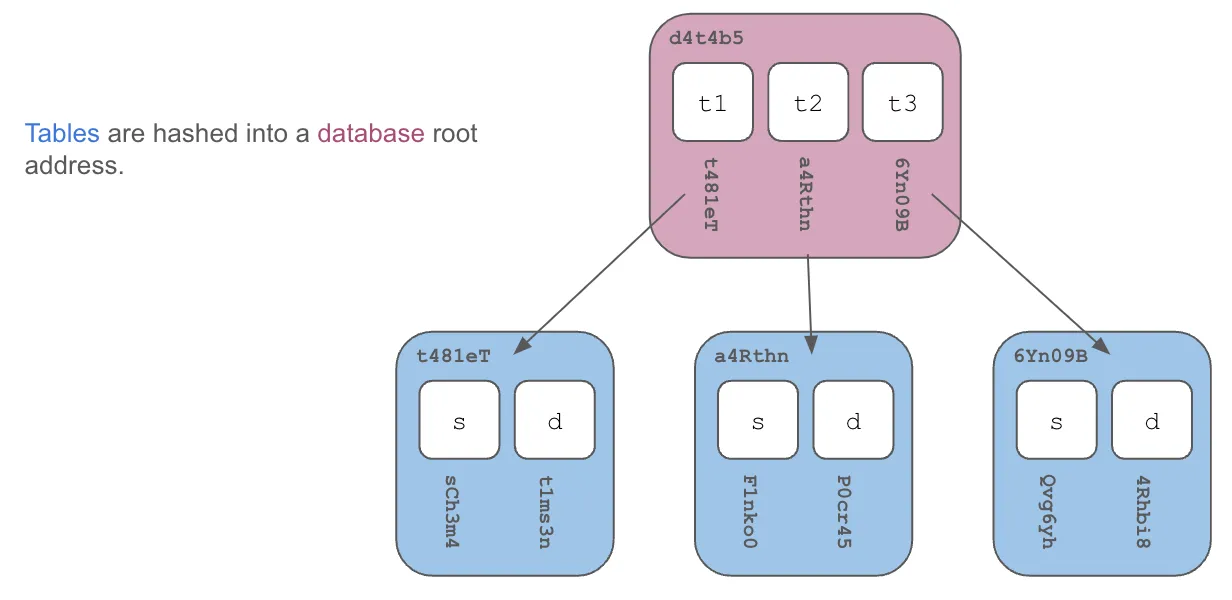
Just like Git, this database root content address is hashed together with commit metadata and parent commits to form a Git-style commit graph. This means the pointer-style branching approach works in Dolt as well, making it the first and only SQL database with branches. Just like Git, Dolt can have millions of branches.
Prolly trees can be diffed using computation proportional to the size of the differences by comparing content addresses of portions of the tree. This fast diff forms the basis of most Dolt version control operations.
Prolly trees allow for all the scaling properties of Git when it comes to versioning. Prolly trees allow for the scaling properties of B-trees when it comes to table rows. Prolly Trees allow Dolt to scale to millions of versions, branches, and rows.
Read More#
This article scratches the surface on a number of topics we’ve written more deeply about in the past. If you’re curious to learn more, check out:
Conclusion#
Prolly Trees in a Git-style commit graph allow Dolt to scale to millions of versions, branches, and rows. Dolt is the world’s first and only version controlled SQL database and the only SQL databases with branches. Curious to learn more? Come by our Discord and chat with the team, including me.