
A few weeks ago, we announced the availability of automatic garbage collection in Dolt sql-server. This blog post is a quick follow up outlining some of the implementation challenges in automatic GC and how the collection and reference tracking itself works.
Garbage Collection Overview#
As a quick overview, let’s review what garbage collection in Dolt is and why it exists. Dolt is a SQL database that stores all database data in a Merkle-DAG, which enables it to support lots of unique functionality, including Git-like functionality on the database itself, supporting branch, diff, and merge, as well as remotes functionality including push, pull and clone. In order to support this functionality, table data is stored in a unique, content-addressed sorted index data structure which we call a Prolly Tree. For a given database value, there is a prolly tree per table and per index. Writes to a Dolt database create copy-on-write materializations of these prolly trees into an append-only ChunkStore which stores the serialized chunks.
Over time, chunks in the ChunkStore may become unreferenced. Unreferenced data is any data which is not reachable from a current branch, tag or remote reference in a Dolt database. Data can become unreferenced when a particular Dolt database value receives a new write before creating a Dolt commit or when a branch gets deleted, for example. Dolt itself also flushes buffered writes to materialized prolly trees and can create unreferenced data even within the execution of a single SQL statement.
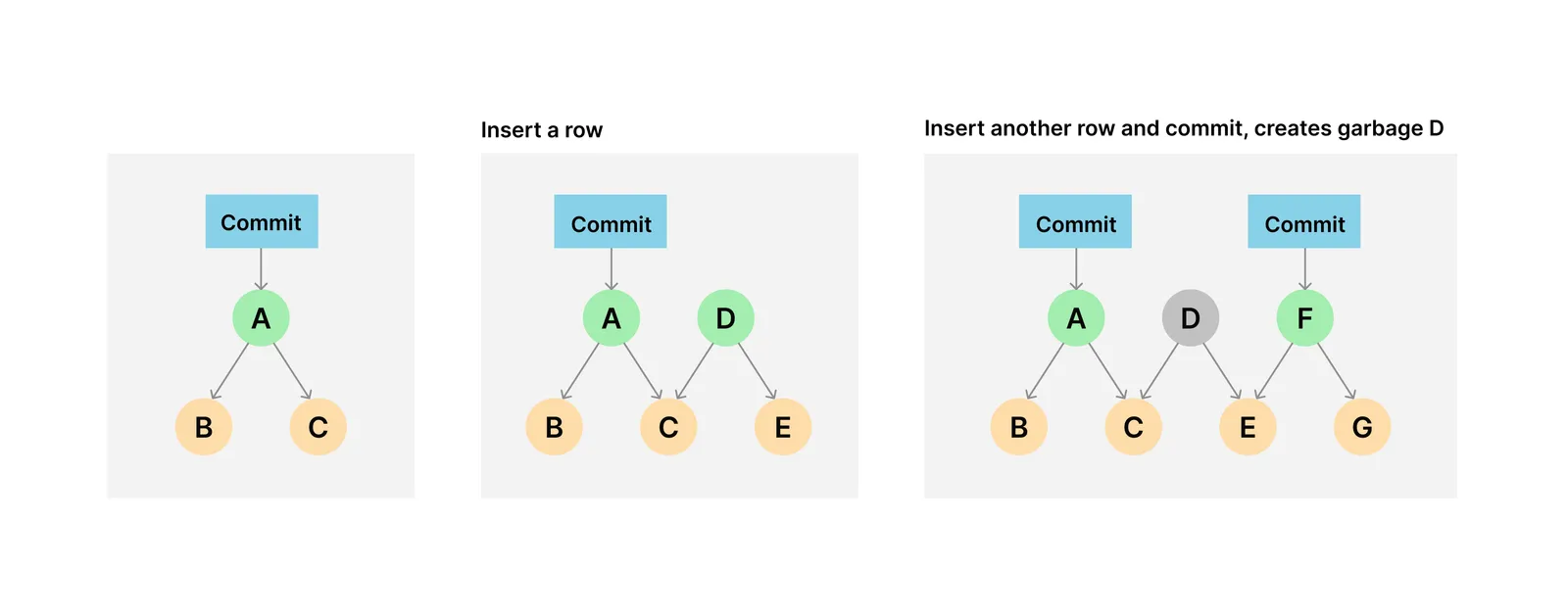
For these reasons, it can be important to periodically garbage collect your Dolt database. Keeping the amount of unreferenced data to a minimum helps with disk utilization and, in extreme cases, can also help with performance by reducing the memory and CPU overhead associated with storage metadata bookkeeping.
Previous Behavior#
Dolt garbage collection is the only process in Dolt which can remove data from the ChunkStore. It requires careful consideration to ensure that it never removes anything that might actually be needed. When we first implemented garbage collection, we implemented it as an offline process that needed to be performed while the server was not running. It was easy to ensure that garbage collection was safe because there were no concurrent writes to the database at the time. The garbage collection process simply walked all the reachable chunks from the current branch roots and ensured they made it into the new storage files.
Of course, we knew that dolt gc needed to be available on a running server as well, since taking down time of your server just to keep your disk utilization in check is not reasonable for many use cases. And so we implemented the dolt_gc stored procedure. But since there were now potentially concurrent writes in progress, we needed to take steps to ensure that everything was still safe.
Our first approach was very heavy handed — when the dolt_gc() stored procedure ran, it would kill all in-flight SQL connections. To see why this is helpful, you need to understand a useful ChunkStore invariant. Chunks in a ChunkStore are part of the Merkle-DAG creating the database value for a Dolt database. As a consequence, they can reference each other by their content-addressed chunk hash. A ChunkStore should never contain a chunk if it doesn’t also contain all of the chunks that that chunk references. Because of this invariant, all writes to a Dolt database happen bottom up. This is also the natural write order for most kinds of writes to the store, because inserting a new chunk which points to other data requires serializing the chunk contents which will contain with the addresses of the chunks to which it refers.
Since writes are occurring bottom up, a prolly tree mutation will start at the leaves, inserting the new chunks, and work its way up the internal nodes, inserting new internal nodes. Eventually it will reach the root node of the prolly tree, and then update further chunks, like the tables map which stores the roots of all the prolly trees implementing all the table data in the database. Suffice it to say, once garbage collection is involved, we could encounter the following problem:
-
A prolly tree write starts before a garbage collection and inserts some leaf chunks, for example.
-
Garbage collection starts. It is walking the known roots of the store. Nothing in the store currently refers to the leaf chunks which were just inserted in step 1.
-
The garbage collection ends. The store now contains only what was reachable from the roots of the store when the garbage collection started.
-
The prolly tree write continues, attempting to insert internal nodes of the mutated prolly tree which reference the previously inserted leaf chunks.
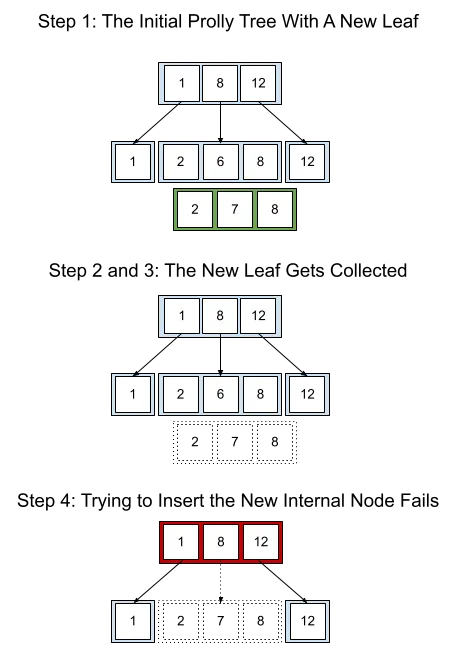
Obviously the prolly tree write in #4 can not be allowed to continue since its data dependencies didn’t make it into garbage collection results.
By disrupting all SQL connections which existed while the GC was in progress, the engine could disrupt any in-progress writes and thus ensure that they didn’t attempt to take invalid data dependencies.
Write Buffering and Cascading Failures#
There’s another subtlety here that needs to be understood to understand this tradeoff associated with terminating all in-flight connections. Because the chunk reference invariant is a safety property, it is enforced at write time by the ChunkStore. Any time a chunk gets written to the store, its dependencies are checked against the store contents and if they do not exist, the write itself fails. On the surface, it seems like that property would be enough to allow for online GC to proceed without proactively terminating all in-flight SQL connections. It would still be disruptive to terminate the ones whose in-flight data dependencies got collected, but at least read-only queries could proceed without issue, for example.
This didn’t work for Dolt, however, because the ChunkStore needs to batch writes and write reference sanity checks in order to achieve high throughput. That batching is most effective and efficient when it coalesces the writes from multiple connections. The simplest and safest implementation was to cause a sanity check failure to throw out all the chunks in the write batch, and to signal the failure to the caller who happened to be flushing the write batch. Some of those chunks which got thrown were possibly dependencies of other in-progress writes which were now operating with invalid assumptions about what was in the store, exactly like they would have been if they had occurred across a garbage collection.
As a consequence, running dolt_gc without terminating in-flight SQL connections had the potential to result in a series of cascading failures, without any bound on when they would stop, since some of the chunks which get thrown away on every sanity check failure might also be dependencies of in-flight writes that other connections are in the process of making. Those connections could in turn populate the write buffer with chunks which attempt to take further invalid dependencies. Depending on the workload, the process can repeat indefinitely, with no writes succeeding.
Breaking the SQL connections allowed us to avoid the cascading failures, but it meant that every connection would experience a failure instead. Applications could work around this with a typical strategy of writing idempotent SQL transactions and retrying, and that’s what our users did for the time being.
In-Memory Chunk Dependencies#
There’s yet another reason that terminating all in-flight connections made the implementation of dolt_gc easier. Dolt GC’s job is to copy all reachable data into the storage files which will make up the new store before deleting the old storage files. So it needs to be able to find all “referenced and reachable” data. In the offline use case, the answer to that question was simple, because we defined it to just be everything that was reachable from the root of the Merkle-DAG that made up the value of the database, including all its branches, working sets, remotes branches, etc. For an online SQL server, that definition is not sufficient. In-flight SQL sessions can have in-memory references to written data that they are using to service client requests but which they have not yet published to the Merkle-DAG root or to other sessions. A long running SQL transaction will accumulate new root values for the branch it is running against without publishing those anywhere until it is committed.
To the storage layer, in almost all ways, this problem looks the same as the problem outlined in the four step example above — there are references to chunks floating around in memory, which the storage layer does not know about, and they are going to cause writes against the storage layer to break in the future after the garbage collection completes. To the application layer, these two cases might look a little different, because it’s easier to collect GC roots at known quiesced points, such as after a SQL statement completes, than it is to instrument the application to make all in-memory chunk references available at any given time.
Session-Aware Garbage Collection#
In order to implement automatic garbage collection, we needed to get away from breaking every in-flight SQL connection every time dolt_gc was run. The actual implementation required changes in a lot of places, but the behavior is conceptually quite simple.
As it was implemented, garbage collection started by walking and copying all the data in the store reachable from the root. At some point, before the garbage collection could be finalized, it needed to establish a safepoint, which was a point beyond which it was certain that no in-flight work which started before the garbage collection started was still in flight. The original online dolt_gc implementation implemented that safepoint by terminating all in-flight SQL connections at that point, including coordinating with the SQL engine to ensure that all in-flight work was cleaned up before declaring the safepoint established.
However, terminating these connections is a stronger guarantee than we need. These connections may have been completely idle, for example. To truly establish the safepoint we are looking for two conditions:
-
any work that started before our garbage collection started is finished before our garbage collection finishes,
-
any in memory GC roots associated with the session are seen by our garbage collection process before garbage collection finishes.
The safepoint controller in the original dolt_gc implementation was not session aware, and so it took the heavy-handed approach of terminating all SQL connections instead. With a session-aware garbage collection safepoint, we can get the behavior we want. We simply inspect the set of all sessions shortly after garbage collection starts. For the sessions which are quiesced, we register their roots for marking before we allow them to do any further work. For sessions which are currently doing work, we register them to mark their own roots with the GC process after they have completed their current work. As garbage collection is getting close to completing, we come back and we block its completion on any in-progress work. This ensures that all in-flight work whose roots we have not yet gotten a chance to visit will be visited before finalizing the garbage collection.
A rough sequence diagram of the session-aware safepoint controller looks like this.
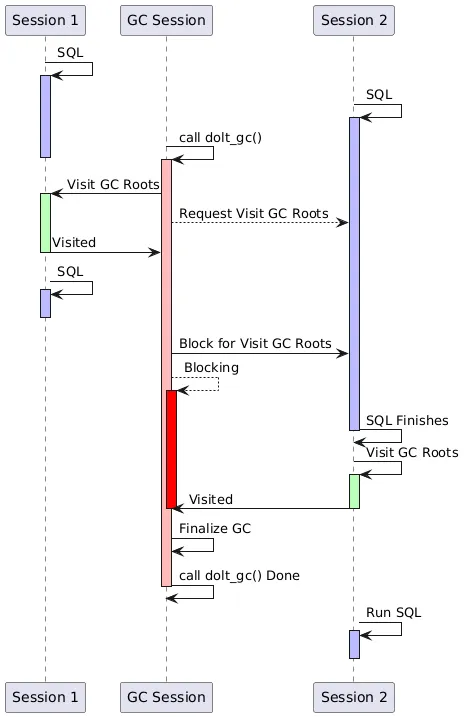
In the example, Session 1 and Session 2 were running SQL before the GC started. Session 1 was quiesced by the time GC started, and so it immediately visits its root and then can run SQL as before. Session 2 was actively running a SQL statement when the GC process first visited active sessions, and so it was required to visit its roots after that statement is done. By the time the GC is nearing completion, Session 2 still hasn’t visited its roots. So the GC process blocks on the completion of the SQL statement in Session 2 and waits for it to visit its roots. After Session 2 finishes visiting its roots, the GC process can continue with finalization, while Session 2 is allowed to continue running further SQL statements.
Session Details#
To get this right, the storage layer needs visibility into when a particular unit of “work” starts and when it ends. So Dolt’s SQL engine, and some other points of contact with the storage engine across Dolt, had to be instrumented with indications of when they started accessing the storage layer in a way that could create new data dependencies and when they stopped. The application itself can choose its unit of work, but if a unit of work stays open for a long period of time, it may prevent a dolt_gc invocation from completing a timely manner.
For now, Dolt implements its safepoint-relevant unit of work as a SQL statement. That means a long running SQL statement can keep a dolt_gc from completing until it itself completes. This is the simplest approach, but it could be improved, especially in the case of SQL statements which are expected to take longer, like call dolt_backup or call dolt_clone.
Sessions are also responsible for making their GC roots available to the garbage collection process. A session’s GC roots are basically any in-memory references to chunks that it has. It’s possible to make session safepoints finer grained, but as you do so the bookkeeping and logic associated with surfacing the session’s GC roots typically becomes heavier. For example, a different tradeoff would be for Dolt to allow safepoint establishment in between prolly tree edit flushes, with the GC roots being extended to include the roots of all prolly tree editors that the session had open.
Future Improvements#
In the current Dolt release, dolt_gc still kills all in-flight connections when it is run. Only when automatic GC is on does it assume the new behavior where connections are left in place. We hope to enable the new dolt_gc behavior by default in the near future, and we will continue to improve on the performance and behavior of dolt_gc going forward. Automatic GC will continue to get ergonomic improvements to its scheduling heuristics and should be on by default soon too.
Do you have a use case for a version-controlled SQL database? Stop by our discord or reach out to us.