
One of the most important concepts in SQL is the primary key. This tutorial will teach you what a primary key is, how to use it, and what it’s good for.
What’s a primary key?#
A primary key is a way to identify exactly one record in a SQL table. Every row in that table will have a different primary key that uniquely identifies it and no other row. This is easiest to see with an example.
First, we’ll make a table without a primary key. Here’s an example table that records employees at a company.
CREATE TABLE employees (
first_name varchar(100),
last_name varchar(100),
title varchar(80)
);We can insert some rows in the table like this:
INSERT INTO employees VALUES
('Tim', 'Sehn', 'CEO'),
('Brian', 'Hendricks', 'Software Engineer'),
('Brian', 'Fitzgerald', 'Salesman');And get them back like this:
SELECT * FROM employees;
+------------+------------+-------------------+
| first_name | last_name | title |
+------------+------------+-------------------+
| Brian | Hendricks | Software Engineer |
| Tim | Sehn | CEO |
| Brian | Fitzgerald | Salesman |
+------------+------------+-------------------+
3 rows in set (0.01 sec)Now let’s create the same table, but give it a primary key. We will use the combination of
first_name and last_name as the key.
CREATE TABLE employees (
first_name varchar(100),
last_name varchar(100),
title varchar(80),
PRIMARY KEY (first_name, last_name)
);We can insert the same rows and get them back as before. But something has changed. What happens if we try to hire a second Brian Fitzgerald?
INSERT INTO employees VALUE ('Brian', 'Fitzgerald', 'Window washer');
ERROR: duplicate primary key given: [Brian,Fitzgerald]Our primary key on (first_name, last_name) means that every combination of those values in the
table has to be unique. The database will ensure that there is only one row for each combination, so
trying to insert a second Brian Fitzgerald is an error.
Natural versus synthetic primary keys#
There’s an obvious objection to the key we chose above: what if I want to hire a second Brian Fitzgerald? My database schema should allow that! Most database systems that deal with people’s names use synthetic keys for this reason. A synthetic key is one that has nothing to do with the data itself. It’s metadata chosen purely to uniquely identify a single row.
Here’s our employees table with a new synthetic key that we’ll call employee_id.
CREATE TABLE employees (
employee_id bigint,
first_name varchar(100),
last_name varchar(100),
title varchar(80),
PRIMARY KEY (employee_id)
);Now our insert statements look like this instead:
INSERT INTO employees VALUES
(1, 'Tim', 'Sehn', 'CEO'),
(2, 'Brian', 'Hendricks', 'Software Engineer'),
(3, 'Brian', 'Fitzgerald', 'Salesman');And our data looks like this:
SELECT * FROM employees;
+-------------+------------+------------+-------------------+
| employee_id | first_name | last_name | title |
+-------------+------------+------------+-------------------+
| 1 | Tim | Sehn | CEO |
| 2 | Brian | Hendricks | Software Engineer |
| 3 | Brian | Fitzgerald | Salesman |
+-------------+------------+------------+-------------------+
3 rows in set (0.01 sec)Now we can insert our second Brian Fitzgerald, as long as he has his own ID.
INSERT INTO employees VALUES (4, 'Brian', 'Fitzgerald', 'Window washer');The way we tell these two Brian Fitzgeralds apart is their employee ID. As we continue to build the rest of our system, other tables should always refer to an employee by their employee ID, not their name, so we always know which Brian Fitzgerald we are talking about. For example, here’s how we would record employee salaries:
CREATE TABLE salaries (
employee_id bigint,
salary numeric
);
INSERT INTO salaries VALUES
(1, 56000),
(2, 100000),
(3, 80000),
(4, 36000);To find the salary of every employee, we would use a JOIN between the two tables:
SELECT * FROM employees JOIN salaries ON employees.employee_id = salaries.employee_id;
+-------------+------------+------------+-------------------+-------------+--------+
| employee_id | first_name | last_name | title | employee_id | salary |
+-------------+------------+------------+-------------------+-------------+--------+
| 2 | Brian | Hendricks | Software Engineer | 2 | 100000 |
| 3 | Brian | Fitzgerald | Salesman | 3 | 80000 |
| 1 | Tim | Sehn | CEO | 1 | 56000 |
| 4 | Brian | Fitzgerald | Window washer | 4 | 36000 |
+-------------+------------+------------+-------------------+-------------+--------+(Note that we didn’t specify an ORDER BY clause, so the employee results aren’t necessarily
returned in the order we might expect).
Generating synthetic keys automatically#
In the example above, we defined our synthetic key manually, so that we choose its value for every
row. It’s more common to let the database generate synthetic keys for you instead. The most common
way to do this in MySQL is to use the AUTO_INCREMENT keyword in your table definition.
CREATE TABLE employees (
employee_id bigint AUTO_INCREMENT,
first_name varchar(100),
last_name varchar(100),
title varchar(80),
PRIMARY KEY (employee_id)
);Now when we insert our employees, we let the database choose the employee ID for us. It will automatically choose new numbers so that every employee has their own unique ID.
INSERT INTO employees (first_name, last_name, title) VALUES
('Tim', 'Sehn', 'CEO'),
('Brian', 'Hendricks', 'Software Engineer'),
('Brian', 'Fitzgerald', 'Salesman');Note that because we are not choosing a value for the employee_id column, we now have to tell the
INSERT statement which columns we’re inserting into.
The resulting data is the same as when we chose employee IDs manually, but now the database does it for us.
SELECT * FROM employees;
+-------------+------------+------------+-------------------+
| employee_id | first_name | last_name | title |
+-------------+------------+------------+-------------------+
| 1 | Tim | Sehn | CEO |
| 2 | Brian | Hendricks | Software Engineer |
| 3 | Brian | Fitzgerald | Salesman |
+-------------+------------+------------+-------------------+MySQL has a special function LAST_INSERT_ID() that will tell you the ID it chose for you, if you
need to record it for additional inserts into other tables.
INSERT INTO employees (first_name, last_name, title) VALUES
('Brian', 'Fitzgerald', 'Window washer');
Query OK, 1 row affected (0.01 sec)
SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 4 |
+------------------+
1 row in set (0.00 sec)Natural keys#
Choosing some combination of columns in the table’s data as the key is called a table’s natural key, since it comes from the data itself, not metadata chosen by the programmer or assigned by the database. This is harder to get right.
Most database tables in the real world use synthetic keys for the same reason we saw above. At first it seems reasonable to choose values of the table you think should be unique. In our example, we chose an employee’s name. But with a little bit of thought, we should have realized that two employees can have the same name, so this won’t work as the key. In practice, it’s hard to absolutely guarantee that over time combinations of values you think should be unique actually will be.
For example, consider a table that stores information about cities. You might think that the combination of city and state would be a reasonable natural key, and write your table like this.
CREATE TABLE cities (
city varchar(255),
state_id varchar(2),
zip_code varchar(5),
PRIMARY KEY (city, state_id)
);But unfortunately, you would be wrong. There are dozens of American cities that share a state with a city of the same name.
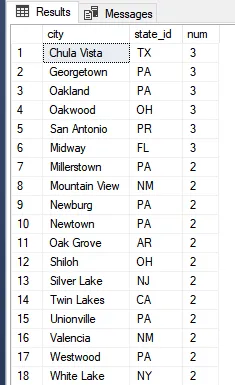
But, in some special cases, you can convince yourself that the data in some combination of columns will absolutely be unique and use that as the key. In the real world, it’s common for a natural key to be another system’s synthetic key: for example, identifying people by their social security number. Someone else (the Social Security Administration) has already made a guarantee of uniqueness.
And sometimes you can make your guarantee of uniqueness true by adding additional information to a natural key. In the cities example, we could use a city’s ZIP code to disambiguate two cities with the same name in the same state.
CREATE TABLE cities (
city varchar(255),
state_id varchar(2),
zip_code varchar(5),
PRIMARY KEY (city, state_id, zip_code)
);But you should always be careful about doing this. You inevitably make assumptions about the future that may turn out to be wrong. Are you willing to bet that the US Postal Service will never assign two cities with the same name in the same state the same ZIP code?
Primary key syntax#
We’ve already seen several examples of the PRIMARY KEY clause of the CREATE TABLE
statement. It looks like this:
CREATE TABLE cities (
city varchar(255),
state_id varchar(2),
zip_code varchar(5),
PRIMARY KEY (city, state_id)
);After defining columns, you add a PRIMARY KEY clause with the columns you want to use as the
primary key. This is the normal way of defining a primary key.
But there’s a simpler syntax for tables that have a single column as their primary key.
CREATE TABLE employees (
employee_id bigint PRIMARY KEY,
first_name varchar(100),
last_name varchar(100),
title varchar(80)
);Here we just add the PRIMARY KEY keywords after the single column we want to use as the key. It
can also be combined with the AUTO_INCREMENT keyword, since this is such a common use case.
CREATE TABLE employees (
employee_id bigint PRIMARY KEY AUTO_INCREMENT,
first_name varchar(100),
last_name varchar(100),
title varchar(80)
);Adding a primary key to an existing table#
If you have a table without a primary key and want to add one, use this ALTER TABLE
syntax:
ALTER TABLE employees ADD PRIMARY KEY (employee_id);You can also drop a primary key from a table that has one.
ALTER TABLE employees DROP PRIMARY KEY;The only time you would want to do this in practice would be when you need to change the primary key of a table. There’s no way to do this other than to drop the primary key and create a new one.
What are they good for?#
Now that we understand the basics of primary keys in MySQL, let’s talk about why you would want to use one.
Ensuring data uniqueness#
Primary keys are unique, which means the database will not allow you to have two rows with the same key. This constraint lets you reason about your data and make guarantees about its correctness. Let’s look at an example.
Above, we defined an employees and a salaries table. Here they are for reference, with a primary
key added.
CREATE TABLE employees (
employee_id bigint PRIMARY KEY AUTO_INCREMENT,
first_name varchar(100),
last_name varchar(100),
title varchar(80)
);
CREATE TABLE salaries (
employee_id bigint PRIMARY KEY,
salary numeric
);To retrieve the salary of an employee, I would write a query like this:
SELECT salary FROM salaries WHERE employee_id = 4;But how can I be sure that there’s exactly one row in this result? What if someone at the company fills out a form twice for the same employee and they get two salaries in this table?
Adding the primary key definition fixes this issue:
employee_id bigint PRIMARY KEY,Now I know that every employee_id will have only one entry in this table, so my result from the
SELECT statement above will be authoritative.
In the real world, we would probably also want to add a FOREIGN KEY constraint to this column, so
that it’s impossible to have any employee_id entries that don’t have a corresponding row in the
employees table. The full CREATE TABLE statement to do both those things looks like this:
CREATE TABLE salaries (
employee_id bigint PRIMARY KEY,
salary numeric,
FOREIGN KEY (employee_id)
REFERENCES employees (employee_id)
);Fast lookups#
Databases are very good at retrieving records via their primary key, which means queries that specify a primary key will be much faster than ones that don’t. This can matter a lot when the table has many rows.
Without a primary key, to find the row you want, the database has to look at every row in the table
to see if it matches the WHERE clause. This is called a full table scan. You can see that’s
what’s happening if you run an EXPLAIN on your query, like this:
EXPLAIN SELECT * FROM employees WHERE employee_id = 1;
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)This is what you see when you’re using a primary key in your WHERE clause. Without the key, you
see something like this:
mysql> explain select * from employees where employee_id = 1;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)You can see from the rows column that the table with a primary key examines only 1 row. Without,
it examines every row in the table (only 3 in this case, but for a big table this query would
destroy performance for this query and every other running at the time).
Fast sorting#
For analytical queries (ones where you expect to return lots of rows), you will often add an ORDER BY clause to make it easier to understand the results. This is especially important when you have a
lot of rows and want to process them in batches using a LIMIT clause, like this.
SELECT * from EMPLOYEES ORDER BY employee_id LIMIT 1000 OFFSET 2000;In this scenario, I’m writing a batch job that processes employees 1000 at a time. As the batch job
runs, I update the OFFSET as I go to get the first batch of 1000, the second batch, and so on.
Without a primary key, the database gets all the rows in the table, and then sorts them using a merge sort on disk.
EXPLAIN SELECT * from EMPLOYEES ORDER BY employee_id LIMIT 1000 OFFSET 2000;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | EMPLOYEES | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)The Using filesort is the indicator that this is happening.
But if you have a primary key you’re sorting by, the database can much more efficiently fetch your rows. Here’s the same query with a primary key.
EXPLAIN SELECT * from EMPLOYEES ORDER BY employee_id LIMIT 1000 OFFSET 2000;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | EMPLOYEES | NULL | index | NULL | PRIMARY | 8 | NULL | 3 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)On the first batch and on every subsequent batch, the database uses the primary key as a natural sorting mechanism and just fetches that many records directly without doing an expensive disk-based sort operation. It can very efficiently calculate how many records it needs to skip, then just read the next 1000 in order. Much, much faster!
Joins#
Finally, any time you’re joining two or more tables together, primary keys are absolutely essential to getting good performance. All the performance problems you run into without primary keys on a single table are multiplied by the number of rows in each table.
To drive this home, let’s look at a join of three tables defined like this:
create table states (name varchar(100), population int unsigned);
create table cities (name varchar(100), state varchar(100) not null, population int unsigned);
create table people (name varchar(100), city varchar(100) not null);Let’s say that we want a list of people named “John Smith” along with names and populations of the cities and states they live in. We would write a query like this:
select * from people p
join cities c on p.city = c.name
join states s on s.name = c.state
where p.name = "John Smith";Using some real numbers: let’s use the US and say that there are 330,000,000 people rows, 20,000
cities rows, and 52 states rows (we didn’t forget you, DC and Puerto Rico). There are about
48,000 people named John
Smith
in the US. So with no primary keys, the database query planner will generate a query execution plan
that starts by finding every “John Smith” row in the people table. Then for every one, it will
look at every row in the the cities table for a match. Then for every one of those rows, it will
look at every row in the states table for a match. This means we end up examining 330,000,000 + (48,000 * 20,000 * 50) rows, or about 48.3 billion rows.
In case it wasn’t obvious, this is bad. This query isn’t returning.
Every modern database will use primary key information to make this join more intelligent, meaning
it examines fewer rows. To be specific: if every table above has a PRIMARY KEY on its name
column, the database will examine only the 48,000 “John Smith” rows to begin with. Then for each
one, it will examine only a single row in the cities table, then only a single row in the states
table. This comes out to 48,000 * 3 rows, or around 144,000 of them. This is 10 million times
faster performance.
In short: primary keys are the difference between your JOIN queries working, or not.
Other kinds of keys#
Astute readers might note that all of the benefits of primary keys above also apply to non-primary keys, often called indexes. This is true! In future blog posts we’ll talk about other kinds of keys and their uses.
Conclusion#
This tutorial should get you on your way using primary keys in MySQL. They are essential to writing a production database schema that is easy to use and performs well.
Before you go, did we mention that we built a MySQL-compatible database with built-in version
control called Dolt? Dolt is a great way to experiment with databases, because
you have the safety of version control to fall back on — if you mess up, you can always dolt reset --hard to roll back to a previous revision. Dolt also lets you diff two revisions of your database,
so you can see what you changed whenever you run a command.
Dolt is free and open source, so go check it out! All of the examples in this tutorial work in Dolt’s built-in SQL shell, so you can use it to follow along at home.
Have questions about Dolt or MySQL primary keys? Join us on Discord to talk to our engineering team and meet other Dolt users.