
DoltDB is the first version-controlled relational database that scales to thousands of concurrent branches.
We spent the last year building a subsystem of table statistics to improve query performance, but so far that system only supports a handful of branches.
Here we will describe how we are bridging that gap. The second version of statistics is still in preview but scales as gracefully as our content-addressed storage.
Background#
All modern databases use data shape as part of query planning. Does table_A have 1000 entries or a billion? Is a column full of NULLs or fully populated? Table statistics can change a join’s runtime from days to milliseconds. While not strictly necessary, most production systems will hit performance bottlenecks in their absence.
We’ve upgraded from manually collected statistics with ANALYZE to automatic background collection recently. With automatic collection, everyone’s servers silently function a little bit better.
The main problem is that it only works automatically for one branch. Many of our customers use a “branch-per-user” model that can include thousands of branches.
The previous architecture scaled using one thread/histogram per branch and quickly eats CPU and memory resources. The “thread-per-branch” left-half of the plot below shows how current statistics defy data sharing, one of the main features of using Dolt!
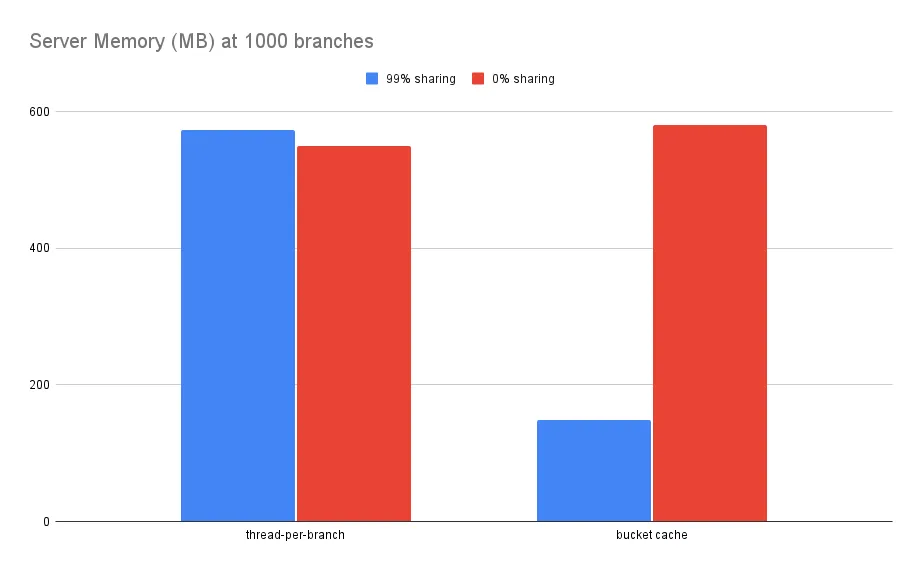
1000 branches that share data should use much less memory, 75% in this case. The prototype is still in preview, but we will describe how we can use the same content-addressing as Dolt’s storage layer to reduce statistics overhead. We expect the official release to come by the end of February.
Statistics V1#
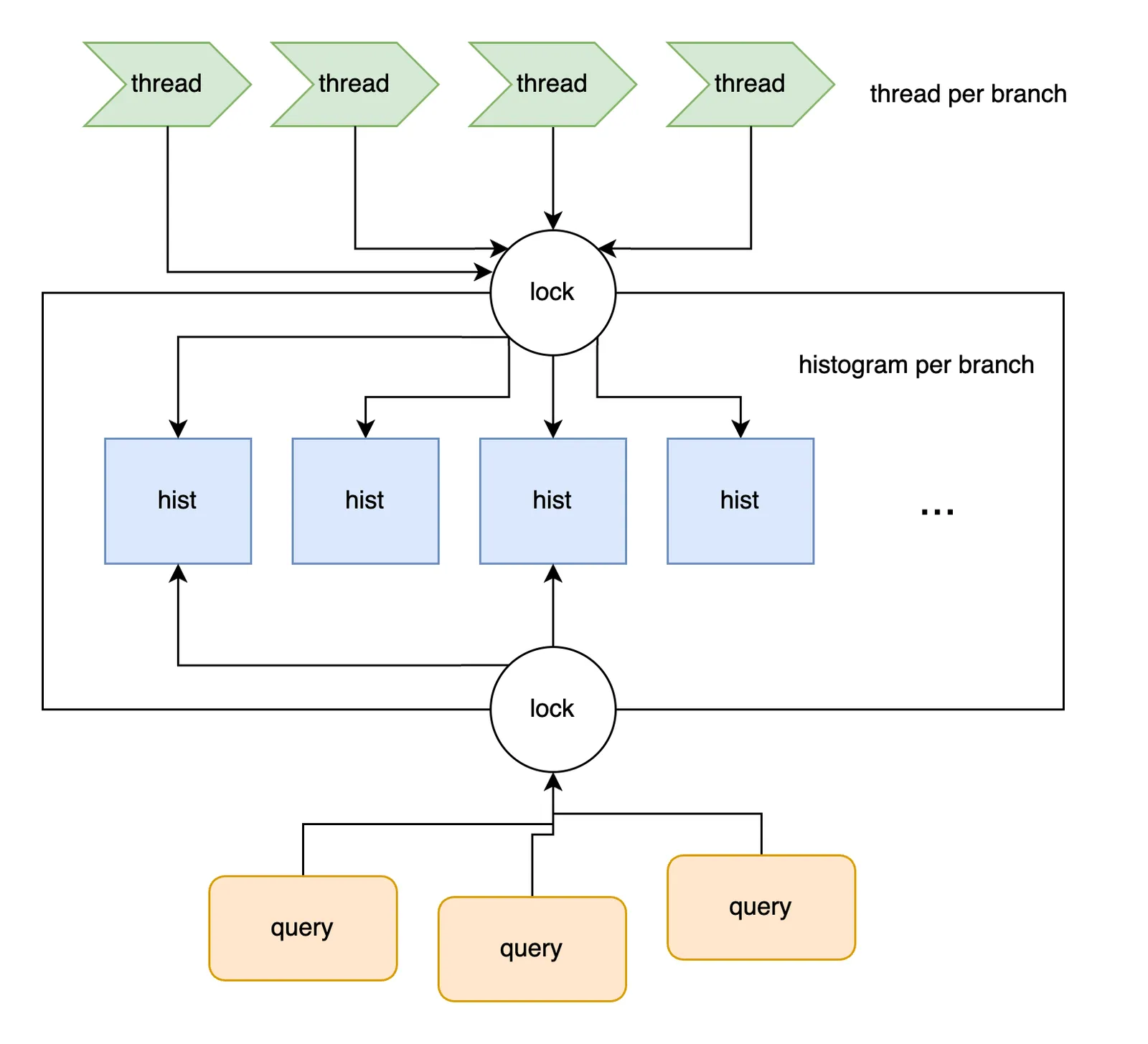
We incrementally built statistic support over 2024. First stats lived in memory, then we persisted to storage to survive server restarts, and finally added multiple branch and database support. Each database and branch added processing overhead proportional to the number of histograms required to track its indexes. Additionally, the thread volume caused lock contention issues The organization of the in-memory statistics was also optimized for ease of update at the expense of runtime read access. Lastly, the old design made coherence assumptions that were hard to repair. For example, the table schema and branch list were expected to be consistent with on-disk storage. We have added many fixes for these kinds of inconsistencies. But “the data is behind” is usually the safest assumption.
Below shows a diagram of what this looks like: a thread per branch and a histogram per thread, all sitting in a common statistics store.
Statistics V2#
The new architecture tries to address these deficiencies.
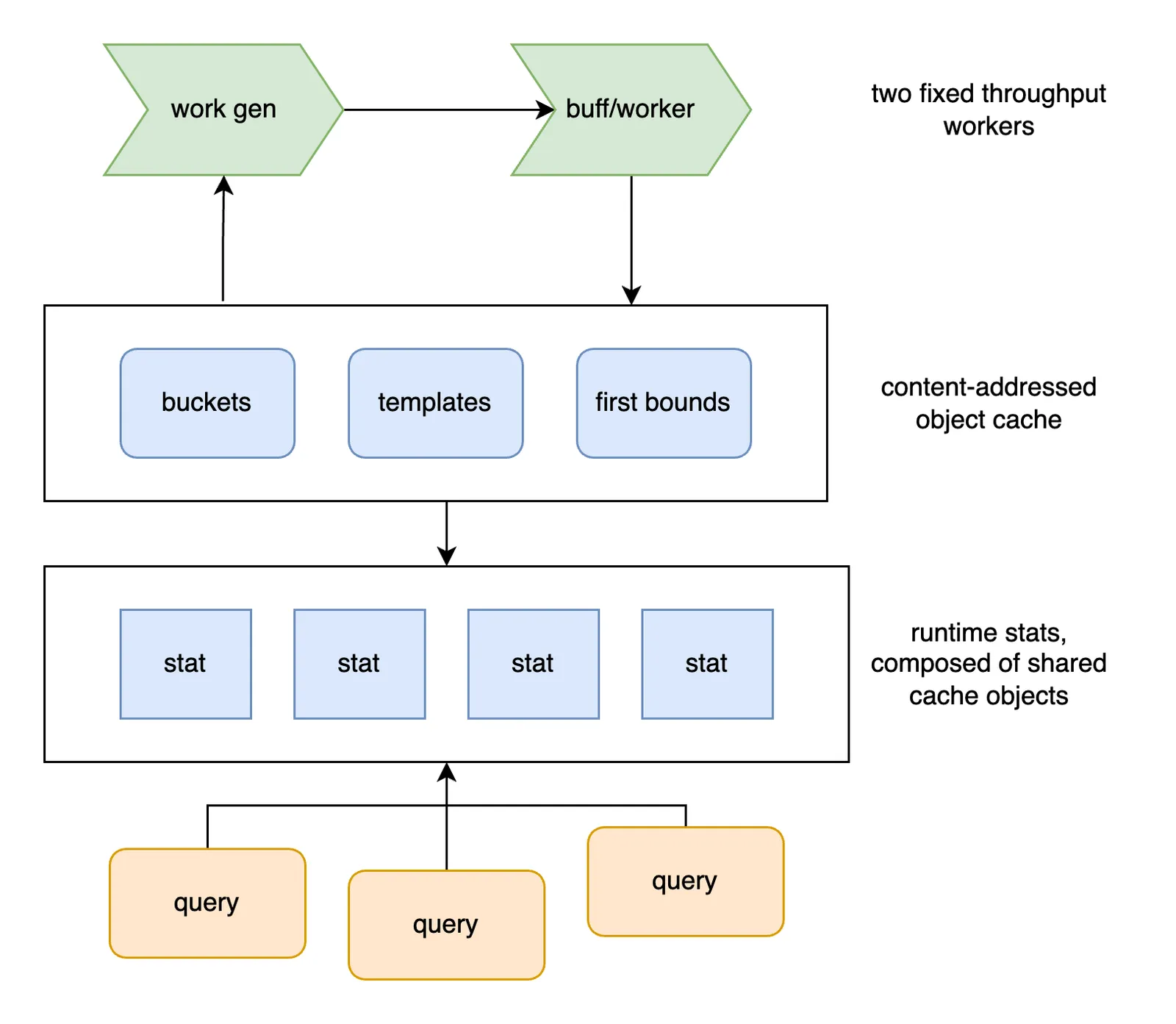
As before, worker threads are responsible for reconciling drift between database root values and recorded statistics.
Updates are performed by a fixed number of threads now. It takes longer to work through a full refresh cycle as the branch count scales up. The processing rate is the main lever for toggling the background thread’s CPU usage and time to reconcile.
All stats are synthesized from shared cache objects. Schema templates, histogram buckets, and lower bounds are content addressed and are reused between branches, databases, and tables. Specifically, templates are indexed by the index schema hash, and buckets/lower bounds are indexed by the corresponding node’s schema hash.
This system has a few notable advantages:
-
Stats resource usage is fixed and easily tunable.
-
Stats memory scales with the amount of data on disk, not the branch count.
-
Queries access stats faster. The stats organization, interface deduplication, and lower thread contention reduce access overhead.
-
Database, branch, and table DDL (add/drop/modify) are now explicitly tested.
-
Inconsistencies self-correct more smoothly, both between storage and memory, and spurious worker inconsistencies within the queue.
The tradeoff is more moving parts:
-
Queueing concurrency is subject to all the regular deadlock/back-pressure/consistency issues inherent in replication and distributed systems.
-
The bucket cache has to be GC’d periodically to clean up unreferenced objects.
We think the new design is simpler. Assuming we are always behind, throttling the queue work, and sharing data when appropriate should be helpful choices moving forward.
In Progress#
Statistics does a lot, but it is important that users don’t notice. Our prototype has negligible overhead in our TPC-C benchmarks, but some things like server startup and GC are still unacceptably slow. The 1000 branch database from before takes almost 10 minutes to load and GC:
db/main> call dolt_stats_gc();
+---------+
| message |
+---------+
| Ok |
+---------+
1 row in set (513.59 sec)
db/main> call dolt_stats_info();
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| message |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| {"dbCnt":1001,"readCnt":0,"active":true,"dbSeedCnt":1001,"storageBucketCnt":136783,"cachedBucketCnt":136783,"cachedBoundCnt":10001,"cachedTemplateCnt":15,"statCnt":5000,"gcCounter":1,"syncCounter":0} |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+We will improve startup and GC before officially releasing. But the cache reorganization alone might not be enough for customers with many branches. Most databases have somewhere between 0% and 99% sharing. Doubling the memory overhead for 50% sharing is still a lot. We have improved the asymptotics, but probably need to figure out how to bring down statistic memory usage across the board in the future.
Summary#
We are in the process of rewriting statistics to scale to the branch-per-user model many of our customers use. In the current format, histogram statistics can start dominating server memory in the range of 100’s of branches. We would like all branches to benefit from statistics, but with a more reasonable memory overhead. We sketched out the prototype here, which we plan on improving and releasing soon!
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!