
In databases, the new hot hotness is vector indexes. Here at DoltHub, we’re not immune to the hype. We released support for vector indexes a couple weeks ago.
But what are vectors and vector indexes? Why put them in databases? Before I wrote this article I had no idea. This blog will answer those questions and show you how to get started using vector indexes in Dolt, the world’s first and only version controlled database. It will also show you how you can use Dolt’s unique version control features to be more productive when working with vector indexes.
What are Vectors?#
Vectors are an array of numbers just like you learned in your first algebra class. [0, 0, 0] and [5, 4, 3, 2, 1] are vectors. For the purposes of this article, usually the operation you perform on vectors is “calculate the distance between them”. Is vector A closer to vector B or vector C?
Vectors have become popular in computer science lately due to the rise of machine learning models that can distill (the proper jargon is “embed”) a block of text, audio, images, or videos into a vector called an “embedding”. This embedding represents the semantic meaning of that object to a human observer. Thus, when you calculate the distance between an input embedding and other embeddings, the embeddings closest in distance to the input embedding represent an object that will seem similar to a human observer. Thus, vectors combined with machine learning models can be used to power similarity search on text, audio, images, or videos.
Here’s a simple fictional example to represent the point. Let’s say I have four sentences:
- Apples are red.
- Oranges are orange.
- Bananas are yellow.
- This is a really weird sentence bro.
These sentences might be embedded into a two dimensional space by a model like so:
[1, 1][1.1, 1.1][0.9, 0.9][10, 10]
As you can see, the embeddings show that sentences one through three are similar while sentence four is weird.
How these machine learning models are trained and work is a very large topic that I can’t hope to cover in this article. But the fact they work so well is one of the miracles of the last decade of computing.
Retrieval Augmented Generation (RAG)#
In the last two years, the big breakthrough in artificial intelligence was generative models. We now have machine learning models that can generate novel objects: text, audio, images or video, from a simple text prompt. The most popular of these is ChatGPT built by OpenAI. Here’s how it explains retrieval augmented generation:

So, retrieval augmented generation can be used to make answers from generative models better. It does this by augmenting the prompt sent to the model with objects retrieved using similarity search to the entered prompt. The initial training run may not have had access to these objects or even if it had access to them, the objects are especially relevant to this particular prompt. Because the prompt now contains additional information, the generative model can create a more specific, better answer.
As we saw above similarity search is powered by vectors. Thus, vectors have a major use case in generative artificial intelligence, a very hot field of investment.
Why put Vectors in a Database?#
Databases act as data persistence for most online applications. There are a number of frameworks that integrate with databases that make building applications much easier. If you’re building an application that needs similarity search at sufficient scale, a database backend that supports similarity search is an ideal persistence layer. Vectors power similarity search.
A few years ago, you needed a specialized database for vectors. Now, most of the databases you know and love support vectors including those of the SQL variety.
Practically, in most databases, vectors are stored as an array of numbers, either as a custom type or as a JSON array. In SQL databases, you make a column to store vectors. You generate vectors outside the database and then populate the database with them. Then, you create a special type of index called a vector index on the vector column. This index makes calculating the distance between vectors faster. Finally, there is a function you can use in standard queries to calculate the distance between two vectors using the index. You can sort by the distance to find similar objects. Interestingly, the function that calculates distance between vectors using this method is a “fuzzy match” algorithm meaning you are not guaranteed to get the correct result. The longer you run the algorithm for the greater precision you get on the results.
Dolt supports Vectors#
Other SQL databases support vectors with the most popular being the Postgres extension pgvector.
Dolt recently announced vector support. Dolt vector support is differentiated because you get Dolt’s historical query and branch capabilities on top of vectors. Last week’s data and embeddings work better? Instantly roll back on another branch and begin your debugging process on the current branch.
We are biased but we think version control of vectors is a natural fit in this space where your data looks more like code than traditional facts.
Example#
Let’s walk through an illustrative example. We are going to rely on Hugging Face, a collaborative machine learning platform that shares DoltHub’s mission. Whereas DoltHub makes sharing databases easier, Hugging Face makes sharing data and machine learning models trained on that data easier. We will use Hugging Face twice in this demo. First, we will get our data from Hugging Face and later we will download models used by Pytorch from Hugging Face.
In this example we will:
- Grab an open dataset from Hugging Face
- Import it into Dolt
- Add an embedding column on main
- Populate embeddings from different models on branches
- Compare similarity results from different models
- Remove some data and embeddings
- Roll back to the previous version
- Create a pull request on DoltHub with the embeddings we like best
Install Dolt#
We first need to install Dolt if we don’t have it yet. Dolt is a single ~103 megabyte program.
dolt $ du -h /Users/timsehn/go/bin/dolt
103M /Users/timsehn/go/bin/doltIt’s really easy to install. Download it and put it on your PATH. We have a bunch of ways to make this even easier for most platforms.
Download a Dataset#
You can see a list of datasets on Hugging Face on the Datasets page. I chose Yelp Reviews because it seemed like a meaningful yet manageable size for this demo. I downloaded the parquet version specifically.
Import to Dolt#
First, I must create a new Dolt database. To make a new database through the Dolt CLI, I use dolt init.
$ cd vector_example
$ dolt init
Successfully initialized dolt data repository.Now that I have a database, I need to create a schema. I can run SQL on the command line using dolt sql -q. I create a table called yelp with a label column and a text column. This matches the schema of the parquet file I downloaded.
$ dolt sql -q "create table yelp (label int, \`text\` text)"Then I use dolt table import to import the data from the parquet file I downloaded to Dolt.
$ dolt table import -u yelp train-00000-of-00001.parquet
Rows Processed: 650,000, Additions: 650,000, Modifications: 0, Had No Effect: 0
Import completed successfully.Now, I create a primary key column for diffs. I also rename the text column reviews for clarity. I do this with standard SQL alter statements.
$ dolt sql -q "alter table yelp add column id int primary key auto_increment"
$ dolt sql -q "alter table yelp rename column \`text\` to review"I then create an embeddings column which I will populate later. Embeddings are stored as a json array so I make the embeddings column json type.
$ dolt sql -q "alter table yelp add column embeddings json"
$ dolt sql -q "describe yelp"
+------------+------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------+------+-----+---------+----------------+
| label | int | YES | | NULL | |
| review | text | YES | | NULL | |
| id | int | NO | PRI | NULL | auto_increment |
| embeddings | json | YES | | NULL | |
+------------+------+------+-----+---------+----------------+Finally, I make a Dolt commit so I can always return to this point later.
$ dolt commit -Am "Set up main branch with schema and data. No embeddings."
commit f4e5ondvtptp6rpprmu9oa886fi8od33 (HEAD -> main)
Author: timsehn <tim@dolthub.com>
Date: Tue Jan 28 14:19:10 -0800 2025
Set up main branch with schema and data. No embeddings.
Insert embeddings on branches#
We’re going to use Python to create our embeddings. So, first, we must set up our Python environment. I used the Python package sentence-transformer which relies on Pytorch for running models. After a few pip installs, I was ready to go.
I then wrote the following Python script to read the data in from the database, cycle through each row, create vector embeddings for each review, transform those to a json array, and then insert that json array into the database.
import mysql.connector
import json
from sentence_transformers import SentenceTransformer
# configuration to connect to Dolt server
config = {
'user': 'root',
'password': '',
'host': '127.0.0.1',
'port': 3600,
'database': 'vector_example',
}
def main():
try:
read_cnx = mysql.connector.connect(**config)
except mysql.connector.Error as err:
print(err)
try:
write_cnx = mysql.connector.connect(**config)
except mysql.connector.Error as err:
print(err)
read_cursor = read_cnx.cursor()
read_cursor.execute("SELECT id, review FROM yelp")
model = SentenceTransformer("all-MiniLM-L6-v2")
# model = SentenceTransformer("BAAI/bge-m3")
write_cursor = write_cnx.cursor()
while row := read_cursor.fetchone():
id = row[0]
review = row[1]
embeddings = model.encode(review)
json_embeddings = json.dumps(embeddings.tolist())
sql = "update yelp set embeddings=%s where id = %s"
val = (json_embeddings, id)
write_cursor.execute(sql, val)
write_cnx.commit()
read_cursor.close()
write_cursor.close()
main()I make a new branch named after the model I am using to make the embeddings.
$ dolt checkout -b all-MiniLM-L6-v2
Switched to branch 'all-MiniLM-L6-v2'To run the script I first start a Dolt SQL Server.
$ dolt sql-server
Starting server with Config HP="localhost:3600"|T="28800000"|R="false"|L="info"|S="/tmp/mysql.sock"I leave that program running in a terminal and run my script named vectorize.py in another shell. It takes about 12 hours on my Mac without a GPU. I think making processes like this faster is why GPUs are in high demand.
Then I create a vector index on that branch which also takes a while, another 12 hours or so on my Mac. I can’t blame this on a lack of GPU. This is just Dolt being slow. We will optimize this process over time. I could have created the vector index before I inserted the embeddings but incremental builds of the vector index is slower than building it all at once after a batch insert.
dolt sql -q "create vector index vidx ON yelp(embeddings);After I’m finished I have the embeddings in an index on the all-MiniLM-L6-v2 branch.
I then repeat the process for the bge-m3 model. I chose these two models because they had the most likes on Hugging Face.
State of the World Now#
After I’m done, I have three branches. main has an empty embeddings column. The two other branches, all-MiniLM-L6-v2 and bge-m3 have the embeddings column populated with embeddings generated with the model corresponding to the branch name. On the two branches non-main branches I also have vector indexes on the embeddings column. You can inspect the database on DoltHub. It’s called vector_example.
$ dolt branch
all-MiniLM-L6-v2
bge-m3
* mainYou can use as of syntax to inspect the embeddings on each branch. For instance, let’s check out the sizes.
$ dolt sql -q "select json_length(embeddings) from yelp as of 'bge-m3' limit 1"
+-------------------------+
| json_length(embeddings) |
+-------------------------+
| 1024 |
+-------------------------+
$ dolt sql -q "select json_length(embeddings) from yelp as of 'all-MiniLM-L6-v2' limit 1"
+-------------------------+
| json_length(embeddings) |
+-------------------------+
| 384 |
+-------------------------+It looks like the bge-m3 model produces much larger embeddings than all-MiniLM-L6-v2.
Compare Results#
Let’s find similar reviews to the first review in the set. The review is:
I went here before a night out on the strip to celebrate my birthday and was absolutely impressed. the food was delicious, and we were able to get so much food, and their wonderful sangria, for an incredible price. this was my first tapas experience and I am hooked. I still get cravings for their delicious truffle fries!!
Let’s start with the bge-m3 model.
Note, Dolt will only use the vector index if the input vector is a constant in every vec_distance function call. Even naming the results (ie. as distance) and referring to that name in the order by (ie .order by distance) messes up Dolt’s analyzer. We will improve this.
$ dolt checkout bge-m3
Switched to branch 'bge-m3'
$ dolt sql -q "set @query = (select embeddings from yelp where id = 1); select id, review, vec_distance(embeddings, @query) as distance from yelp order by vec_distance(embeddings, @query) limit 3;"
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+
| id | review | distance |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+
| 1 | I went here before a night out on the strip to celebrate my birthday and was absolutely impressed.\n\nthe food was delicious, and we were able to get so much food, and their wonderful sangria, for an incredible price.\n\nthis was my first tapas experience and I am hooked. I still get cravings for their delicious truffle fries!! | 0 |
| 517988 | I love this place for group outings. It can get kind of loud so if you're looking for a nice, quite restaurant on a Friday night...not here.\nThe prices are extremely reasonable and the Tapas are really good. I have been satisfied every time I've gone.....\n\nGet the Sangria. Try the mushroom tart and the mac & cheese.\n\nHighly recommended! | 0.42744792676641 |
| 79194 | Fantastic......... \nThe two of us went there on a Saturday @ 6pm withought booking, which wasn't a problem, they gave us two hrs which was fine, we had 5 tapas to start and the paella for 2 which was great with 2 Btls wine \u00a367. staff are very friendly and nothings to much bother, a great atmosphere too. \n\nEnjoy. | 0.42908953699554725 |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+This model seems to key on tapas as the defining characteristic of the first review. There’s nothing about birthdays in the similar reviews. I’m not all that impressed with this model’s results.
So, we’ll switch branches and try the all-MiniLM-L6-v2 model to see if it gives better results.
$ dolt checkout all-MiniLM-L6-v2
Switched to branch 'all-MiniLM-L6-v2'
$ dolt sql -q "set @query = (select embeddings from yelp where id = 1); select id, review, vec_distance(embeddings, @query) as distance from yelp order by vec_distance(embeddings, @query) limit 3;"
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| id | review | distance |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 1 | I went here before a night out on the strip to celebrate my birthday and was absolutely impressed.\n\nthe food was delicious, and we were able to get so much food, and their wonderful sangria, for an incredible price.\n\nthis was my first tapas experience and I am hooked. I still get cravings for their delicious truffle fries!! | 0 |
| 237494 | We went here with 20 relatives for my father's birthday. It was quite good. I had a filet and sampled many other entrees and appetizers. The drinks were good. Like most restaurants on the Strip, the waitstaff was very mechanical and unenthusiastic, but they were very efficient. My niece (and I) enjoyed running out to see the water show every 30 minutes. They sang and brought out a piece of cake. | 0.4680939563569547 |
| 323515 | We went last Thursday for my boyfriend's mother's birthday. The decor was fun and so were the staff's uniforms. The had live music and dancing, which was fun. The service was pretty good but the iced tea didnt need to take 40 mins. The food was great, the sangria was so so but overall I think its a great place for Tapas. I recommend it | 0.496545577096497 |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
This model seems to key on birthday as being the defining characteristic of the first review, Then, it finds some similarities like “sangria” and “the strip”. Moreover since the embeddings are much smaller the queries are much faster. This all-MiniLM-L6-v2 model seems to perform better than the bge-m3 model for this query based on simple human inspection.
Time Travel#
Now, let’s imagine the data changes out from under you. In this contrived example, I will delete my two top results from the bge=m3 branch.
$ dolt sql -q "delete from yelp where id=237494 or id=323515"
Query OK, 2 rows affected (0.24 sec)Now, I run the similarity query above. Oh no, my results have changed.
$ dolt sql -q "set @query = (select embeddings from yelp where id = 1); select id, review, vec_distance(embeddings, @query) as distance from yelp order by vec_distance(embeddings, @query) limit 3;"
+--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| id | review | distance |
+--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 1 | I went here before a night out on the strip to celebrate my birthday and was absolutely impressed.\n\nthe food was delicious, and we were able to get so much food, and their wonderful sangria, for an incredible price.\n\nthis was my first tapas experience and I am hooked. I still get cravings for their delicious truffle fries!! | 0 |
| 457982 | First time here. Did not have tapas, but the Cubano sandwich for lunch. It was good, not great. Sweet tater fries were good. Didn't love the yogurt dip that accopmanies them. Service was good and the decor was...unique. Kinda of like The Office (former tenant of this space) but dressed up for a night out. The Cubano won't bring me back, but I'll go again to give the tapas a shot. | 0.5354190047122163 |
| 210613 | Went here for a bday party. All of the food was amazing! We had six different Tapas and a huge pan of Paella and loved every bite! They also had music and a flamenco dancing to add to the fun! | 0.5606543013652906 |
+--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+In other databases, you would need to restore from a backup but in Dolt, you have a number of rollback options. I’ll just dolt reset --hard to the HEAD commit.
$ dolt reset --hardAnd my results are back.
$ dolt sql -q "set @query = (select embeddings from yelp where id = 1); select id, review, vec_distance(embeddings, @query) as distance from yelp order by vec_distance(embeddings, @query) limit 3;"
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| id | review | distance |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 1 | I went here before a night out on the strip to celebrate my birthday and was absolutely impressed.\n\nthe food was delicious, and we were able to get so much food, and their wonderful sangria, for an incredible price.\n\nthis was my first tapas experience and I am hooked. I still get cravings for their delicious truffle fries!! | 0 |
| 237494 | We went here with 20 relatives for my father's birthday. It was quite good. I had a filet and sampled many other entrees and appetizers. The drinks were good. Like most restaurants on the Strip, the waitstaff was very mechanical and unenthusiastic, but they were very efficient. My niece (and I) enjoyed running out to see the water show every 30 minutes. They sang and brought out a piece of cake. | 0.4680939563569547 |
| 323515 | We went last Thursday for my boyfriend's mother's birthday. The decor was fun and so were the staff's uniforms. The had live music and dancing, which was fun. The service was pretty good but the iced tea didnt need to take 40 mins. The food was great, the sangria was so so but overall I think its a great place for Tapas. I recommend it | 0.496545577096497 |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+Pull Requests#
Now, I want to show what I’ve made to my teammates to get some feedback. I’m going to propose we use the all-MiniLM-L6-v2 in production by merging it into main.
First, I create a database on DoltHub named vector_example. Then I set that database up as a remote and push my local database.
$ dolt remote add origin timsehn/vector_example
$ dolt push --all origin
| Uploading...
/ Uploading...
- Uploading...
To https://doltremoteapi.dolthub.com/timsehn/vector_example
* [new branch] all-MiniLM-L6-v2 -> all-MiniLM-L6-v2
* [new branch] bge-m3 -> bge-m3
* [new branch] main -> mainNow, my state is synced to DoltHub. Let’s create a Pull Request to merge the all-MiniLM-L6-v2 branch into the main branch.
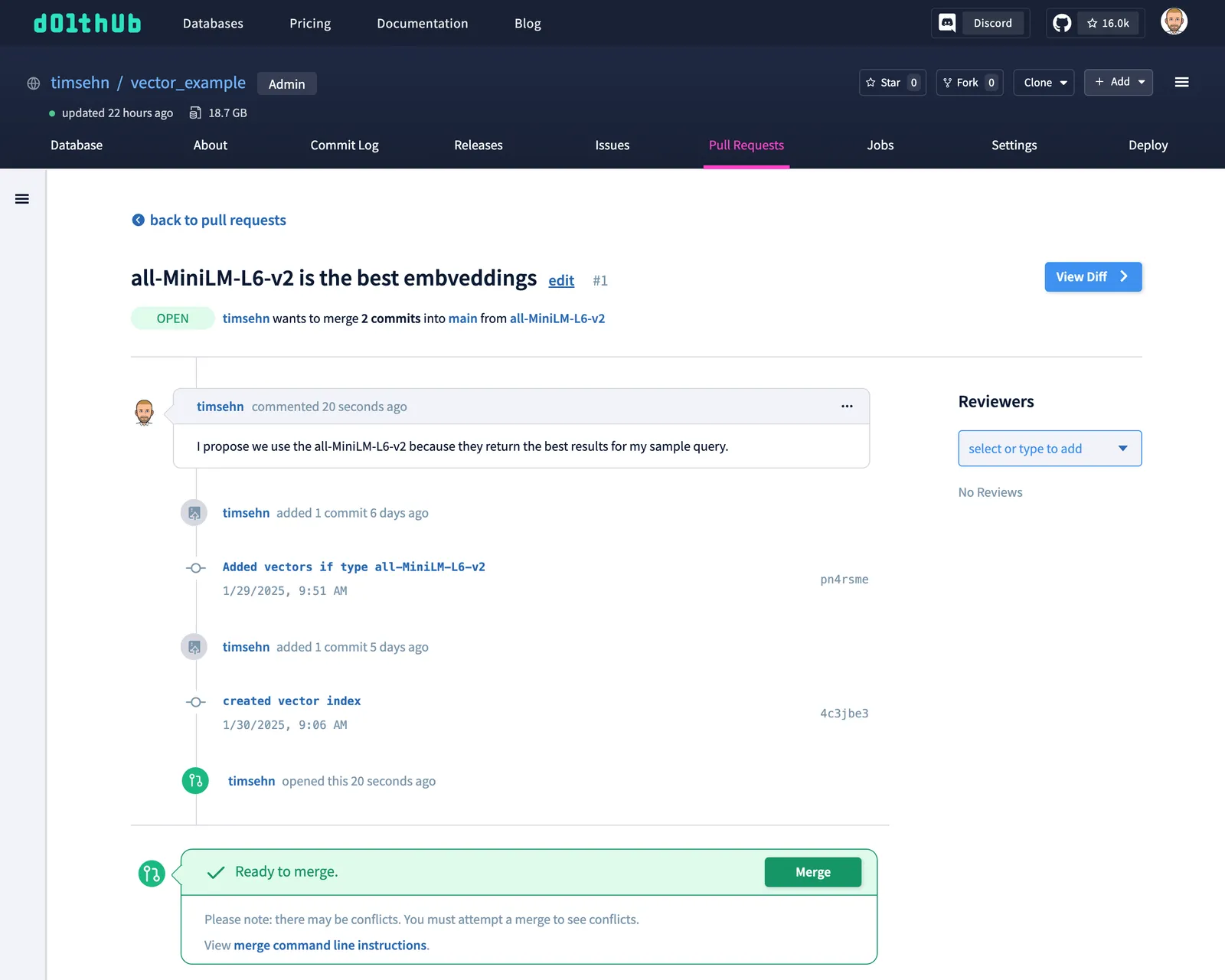
My teammates can now review my change. Maybe they will suggest a more robust testing method? DoltHub gives you the full power of integrated human review on vector changes.
Conclusion#
Dolt’s versioning features are useful and novel in the vector database space. This article walks you through a practical example to show Dolt’s vector functionality and uses of Dolt’s versioning features for vectors. Interested in being an early version controlled vector customer? Come by our Discord and let’s discuss if Dolt is a good fit for your use case.