
One of the coolest things about Dolt is DoltHub. DoltHub is the place on the internet to find, share, and collaborate on Dolt databases. If you find a cool database on DoltHub you want to play with, a good option is to copy it, or clone it in Git lingo, to your local machine.
A clone is a full working copy of the Dolt database when it arrives on your machine, no importing or special set up required. Just clone it and run SQL. Dolt is a database that is meant to be shared.
This article is part of the Dolt for Beginners series.

Find a Database#
DoltHub is Dolt’s GitHub. DoltHub hosts public data for free. You can find a sorted list of public databases on the Discover page.
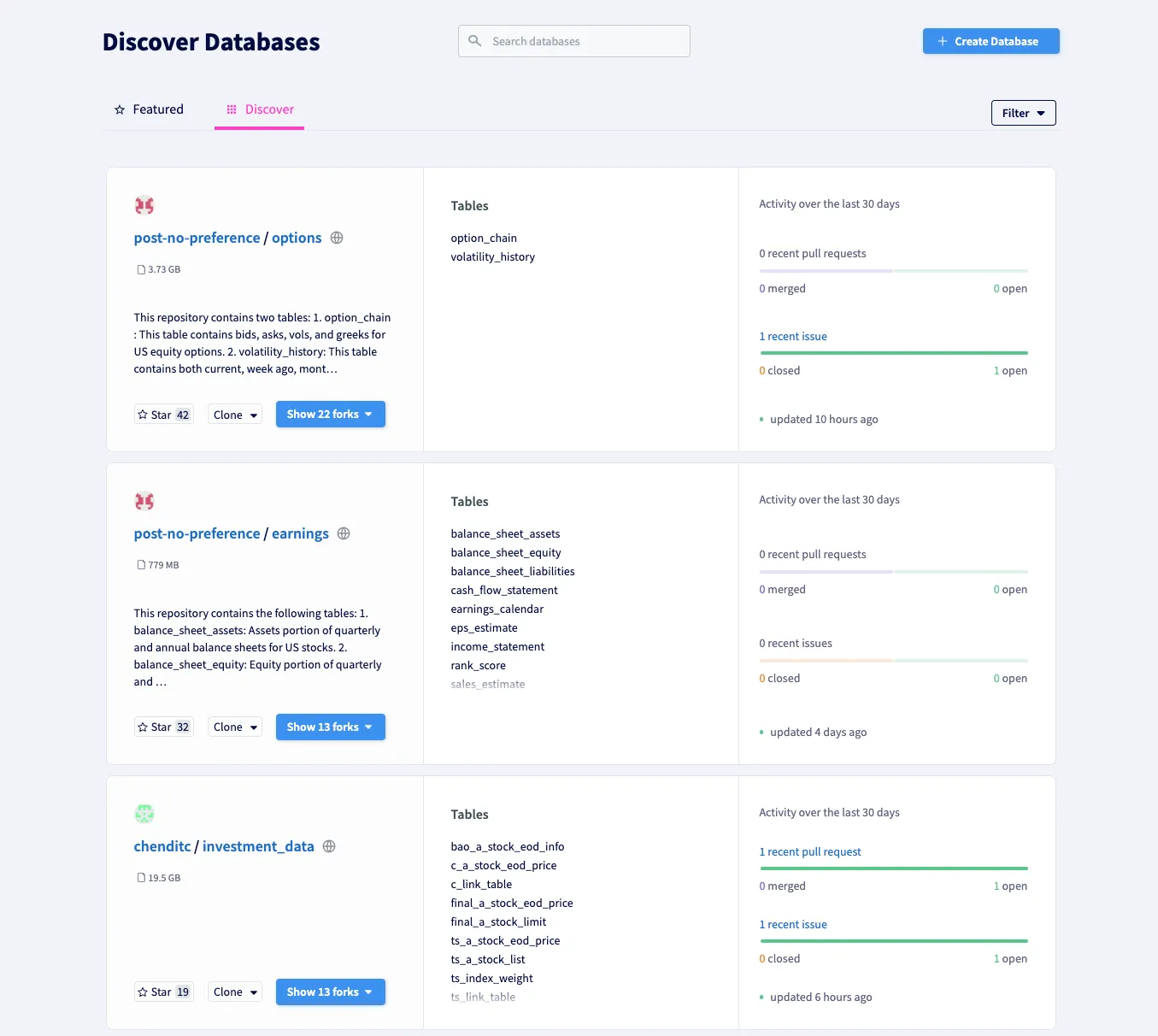
Once you find a database you are interested in, you can learn about it if it has a README. You can also use DoltHub’s SQL console to “try before you buy”. You can see the last time it was updated in it’s commit log. DoltHub is built for data sharing.
Our most popular databases by far are US financial market data maintained by post-no-preference but we have a number of different databases for many different interests. For this article, I’m going to pretend I’m interested in the transparency-in-pricing database which I recently discussed. It’s a database of US hospital prices that we collected with our now defunct data bounty program.
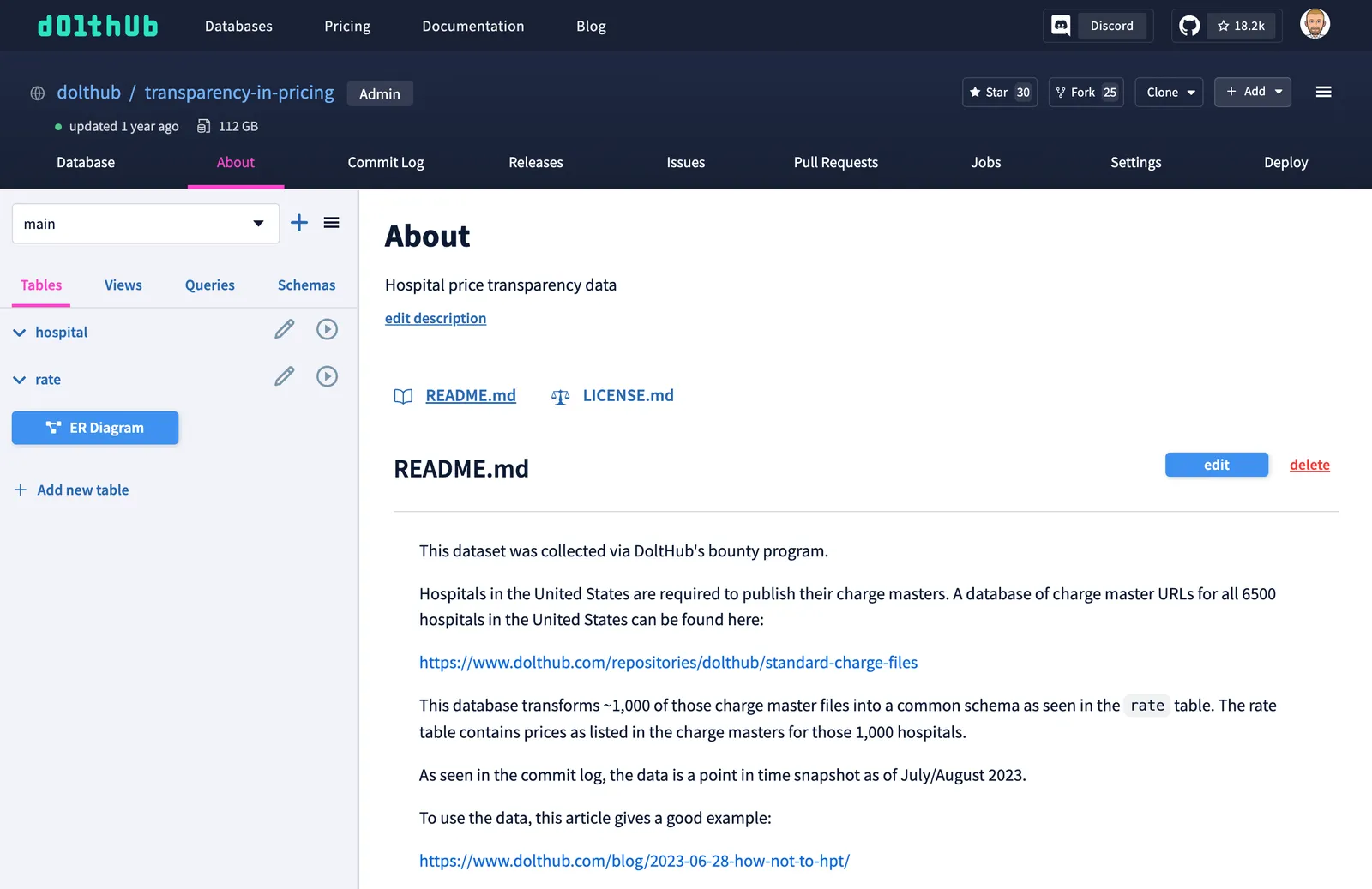
After I navigate to the transparency-in-pricing database page, I am greeted with a README that tells me what I’m looking at. This README lets me know that I’m looking at hospital price data collected in 2023.
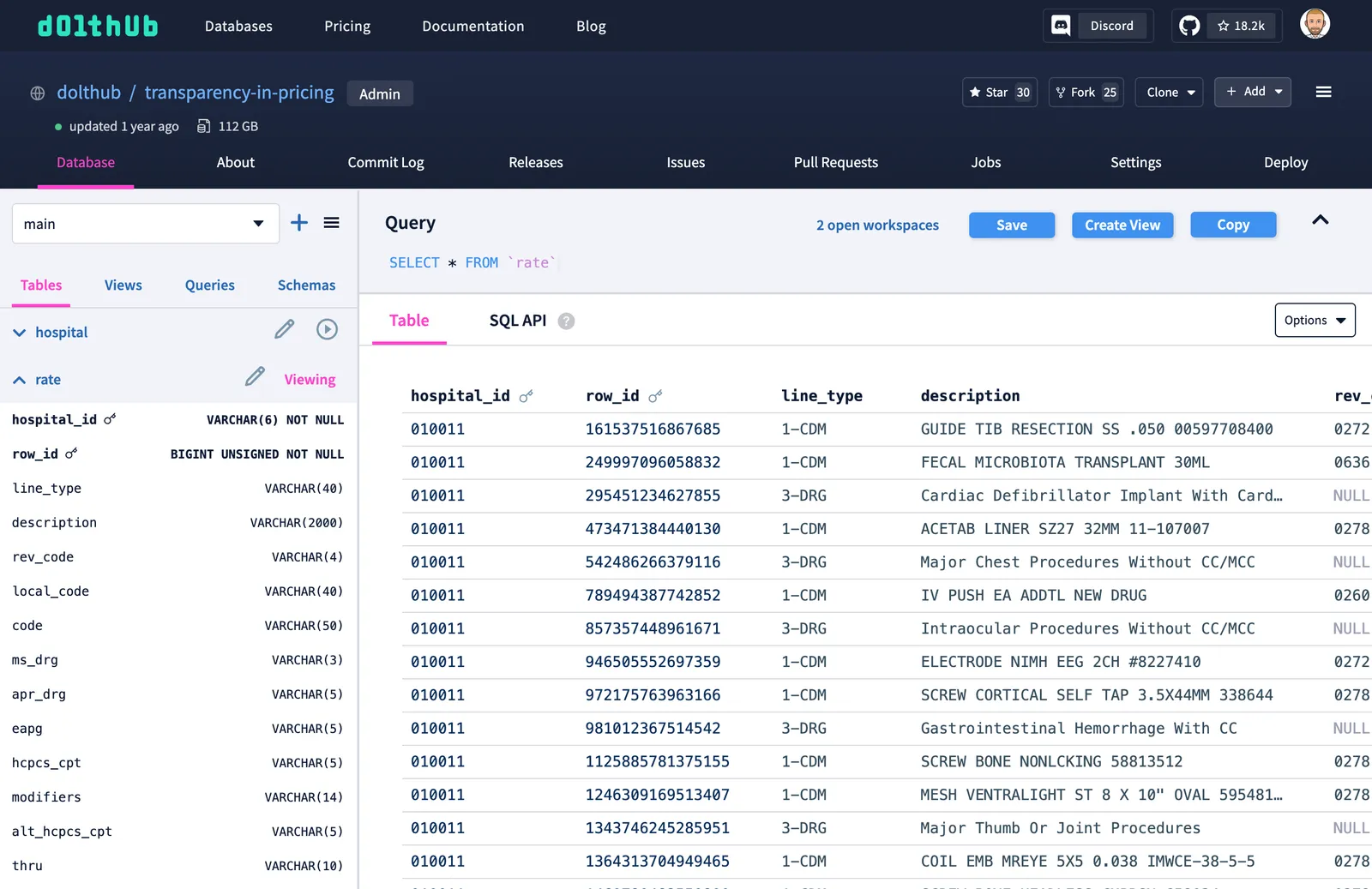
Let’s run a SQL query to see how many prices are in this database. To do that I navigate to the Database tab. This interface should remind you of a standard SQL Workbench like Datagrip or Tableplus. From the README, I know that prices are stored in the rate table so I click the play button beside the rate table in the left column. This displays a sample of the data in the rate table.
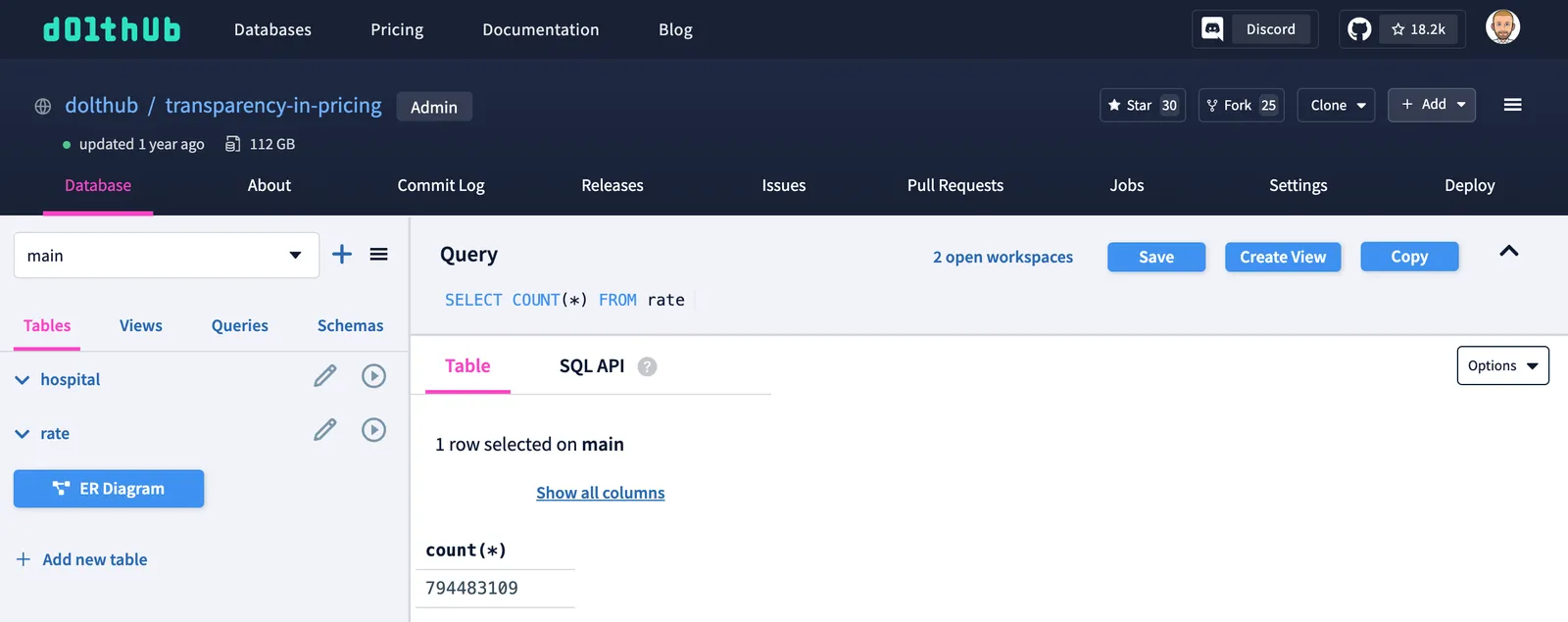
This looks like a pretty thorough collection of data. How many prices are we talking about here? I can run a select count(*) from rate to glean this information. There is a query box at the top of the page that currently has SELECT * FROM rate. I replace that with select count(*) from rate and click the play button to run the query. It looks like there are over 794 million prices in this database.
Finally, I’ll look at the commit log to confirm this data was last updated in 2023 like the README says. Trust but verify. Every Dolt database comes with a log of changes, including diffs, since the database was created.
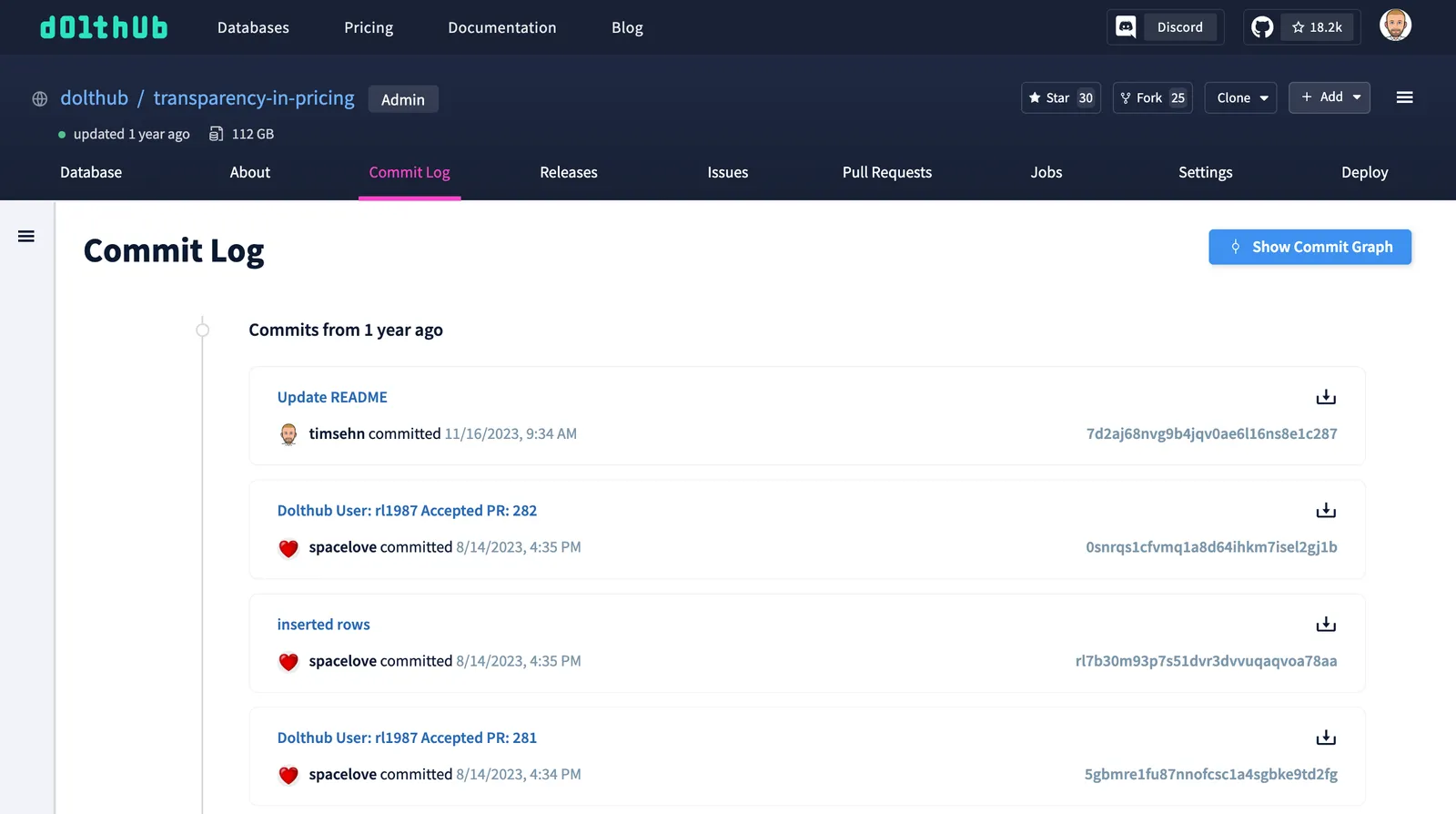
This database seems legit. Let’s get it locally so I can query it more deeply.
Install Dolt#
Once you’ve found a database you like, you need to install Dolt on your local machine. Dolt is not complicated software. There is no complicated install process. You don’t need a Docker container or multiple dependencies installed. You download the single Dolt program and run it.
We have even more convenient ways to install Dolt for every platform.
Once you have Dolt installed, you need to open a terminal like “Terminal” on Mac or Powershell on Windows. Make sure Dolt is on your PATH by typing dolt. If everything is working you’ll be greeted by a help message with all the valid Dolt commands. For those familiar with the Git command line, Dolt should look pretty similar.
$ dolt
Valid commands for dolt are
init - Create an empty Dolt data repository.
status - Show the working tree status.
add - Add table changes to the list of staged table changes.
diff - Diff a table.
... <trimmed for length>
... <trimmed for length>
... <trimmed for length>
reflog - Show history of named refs.
rebase - Reapplies commits on top of another base tip
ci - Commands for working with Dolt continuous integration configuration.Clone#
Now, it’s time to clone the database you like. Open a terminal navigate to the directory you want your database stored in. I usually put mine in a dolt directory in my home directory.
$ cd doltA DoltHub account is not required to clone public data. You only need an account when making writes to DoltHub or reading private databases. So, we’re good to just run the clone command.
$ dolt clone dolthub/transparency-in-pricingThis database is over 100GB so it will take a while to clone. It took about 20 minutes on my work laptop. After it is complete you will have a transparency-in-pricing directory. This is where your new Dolt database is stored. Let’s cd into that directory and make sure the Dolt command line works.
$ dolt ls
Tables in working set:
completed_hospitals
hospital
known_system_hospitals
largest_systems
rateYou may be wondering where completed_hospitals, known_system_hospitals, and largest_systems came from. Those are SQL views.
Run SQL#
Now let’s explore the data more deeply with SQL. You can run individual SQL queries on the command line using dolt sql -q. If you prefer a SQL shell, just leave off the -q.
Note, most queries on the rates table are going to take a long time on account of the 794 million rows and no indexes. I wanted to count the number of prices for ultrasounds (CPT code 76700) and it took about an hour.
$ time dolt sql -q "select count(*) from rate where hcpcs_cpt=76700"
+----------+
| count(*) |
+----------+
| 48195 |
+----------+
dolt sql -q "select count(*) from rate where hcpcs_cpt=76700" 3460.95s user 948.27s system 102% cpu 1:11:29.22 totalFeel free to add indexes to speed up the queries you want to run. The database is now yours. I’ll add an index on the hcpcs_cpt column and run the same query.
$ time dolt sql -q "create index cpt_idx on rate(hcpcs_cpt)"
dolt sql -q "create index cpt_idx on rate(hcpcs_cpt)" 5159.61s user 1130.51s system 55% cpu 3:09:51.05 total
$ time dolt sql -q "select count(*) from rate where hcpcs_cpt=76700"
+----------+
| count(*) |
+----------+
| 48195 |
+----------+
dolt sql -q "select count(*) from rate where hcpcs_cpt=76700" 1.55s user 2.40s system 135% cpu 2.905 totalMuch better. Now, the query that took an hour took only 1.5s after three hours of index creation. CPT code 76700 is an abdominal ultrasound, commonly performed on pregnant women. I can now build a histogram of the prices fairly quickly.
$ dolt sql -q "SELECT
floor(standard_charge / 1000) * 1000 as price_range_floor,
count(*) as frequency
FROM rate
WHERE hcpcs_cpt=76700
GROUP BY price_range_floor
ORDER BY price_range_floor;"
+-------------------+-----------+
| price_range_floor | frequency |
+-------------------+-----------+
| NULL | 585 |
| 0 | 38345 |
| 1000 | 7991 |
| 2000 | 838 |
| 3000 | 281 |
| 4000 | 48 |
| 5000 | 8 |
| 6000 | 7 |
| 7000 | 2 |
| 9000 | 3 |
| 23000 | 6 |
| 24000 | 7 |
| 26000 | 4 |
| 27000 | 16 |
| 28000 | 13 |
| 29000 | 4 |
| 32000 | 2 |
| 35000 | 3 |
| 37000 | 4 |
| 41000 | 4 |
| 56000 | 2 |
| 58000 | 1 |
| 67000 | 14 |
| 77000 | 3 |
| 134000 | 4 |
+-------------------+-----------+What’s up with these hospitals charging greater than $100,000 for an ultrasound?
dolt sql -q "select name, standard_charge from rate join hospital on rate.hospital_id=hospital.id where hcpcs_cpt='76700' and standard_charge > 100000"
+---------------------------------+-----------------+
| name | standard_charge |
+---------------------------------+-----------------+
| PRISMA HEALTH RICHLAND HOSPITAL | 134807.75 |
| PRISMA HEALTH RICHLAND HOSPITAL | 134807.75 |
| PRISMA HEALTH BAPTIST PARKRIDGE | 134807.75 |
| PRISMA HEALTH BAPTIST PARKRIDGE | 134807.75 |
+---------------------------------+-----------------+
Is this a mistake or is this for real? This is the type of question you can take to Prisma Health.
From this quick example, I’m sure you can see the power of Dolt clone. You get your own SQL databases you can do whatever you want to in a few commands.
Conclusion#
As you can see Dolt is the database built for sharing. Find a database you like on DoltHub and clone it locally to run complex SQL queries. No imports or set up required. Questions? Stop by our Discord and just ask. We love helping beginners get started with Dolt.