Workbenches are Better with a Version Controlled Database

The Dolt Workbench is a modern, open-source SQL workbench that works with any MySQL and PostgreSQL compatible database, including version controlled databases like Dolt and DoltgreSQL. We think that the workbench experience is vastly improved with version control, and we're going to show you how through a side-by-side comparison of the same the workflow in a Postgres and Doltgres database.

Getting started
We're going to use the Dolt getting started guide as an example workflow. This workflow assumes you have both Postgres and Doltgres installed. If you need help getting set up with the Dolt Workbench, start here.
1. Create a schema
Postgres
First we add the schema of our tables to our getting_started Postgres database.
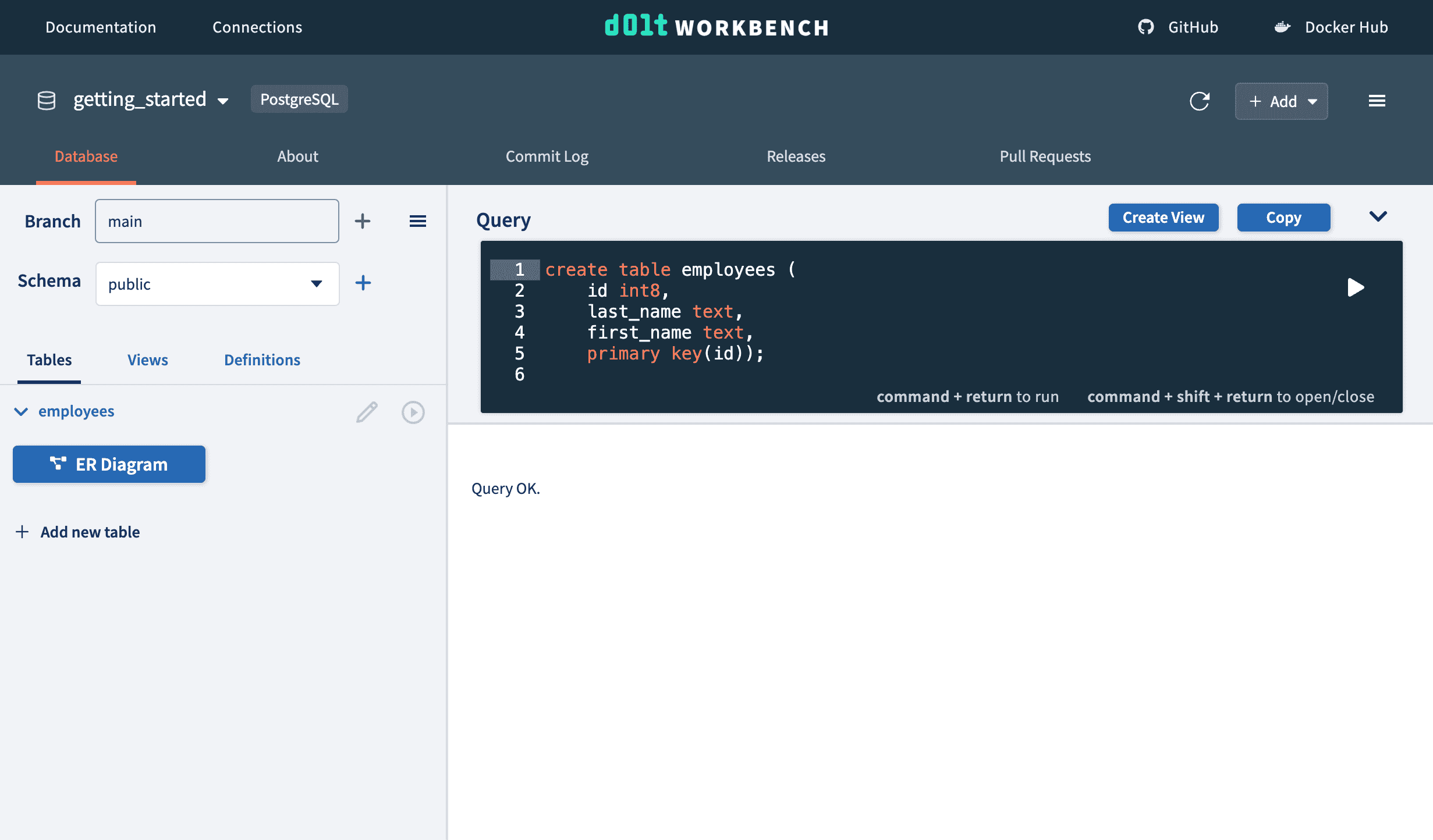
As we create our employees tables, you can see the table names and their columns being added to the left table list.
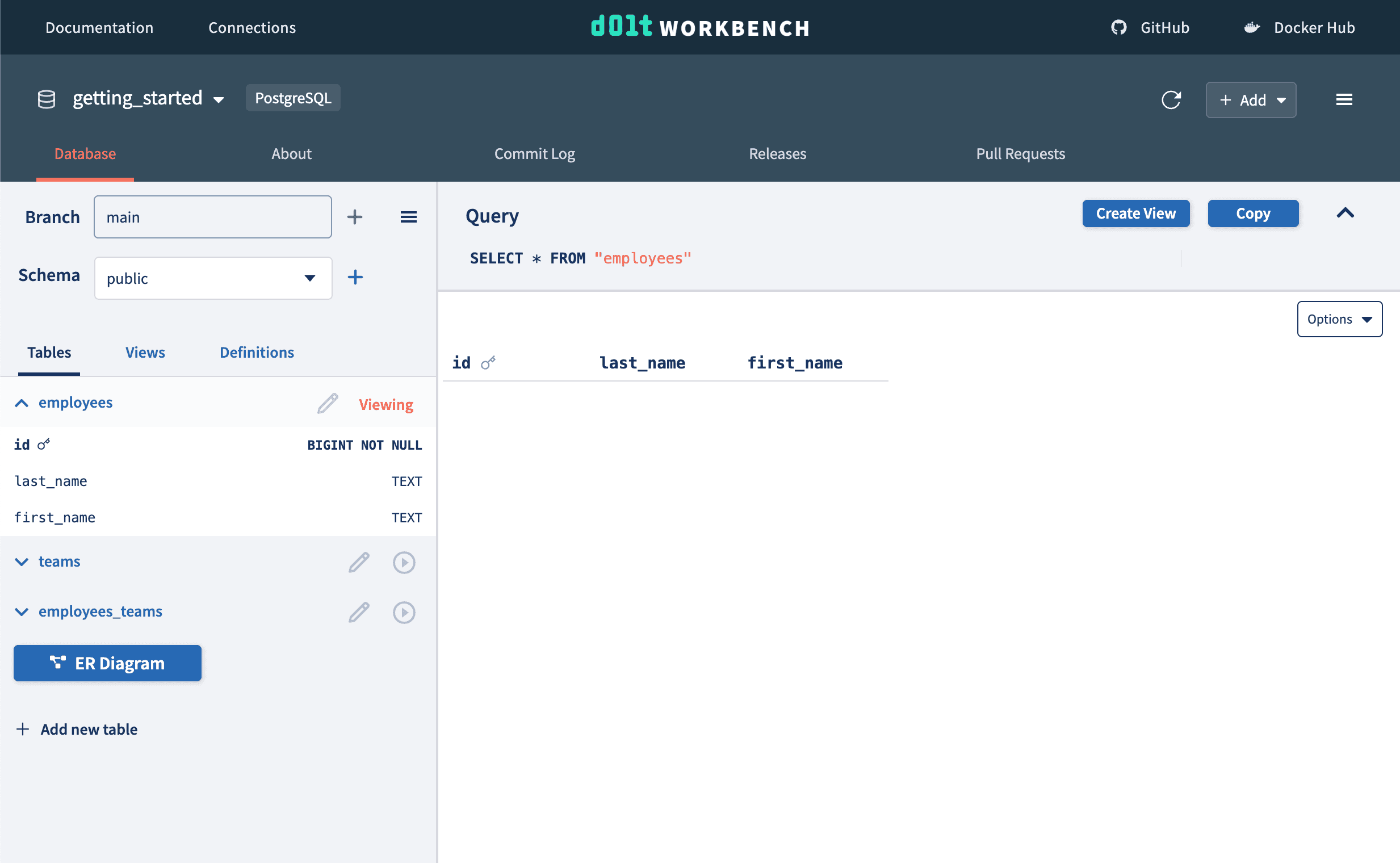
Doltgres
First we add the schema of our tables to our getting_started Doltgres database. You'll notice with Doltgres every time you run a write query you get a diff of the working changes.
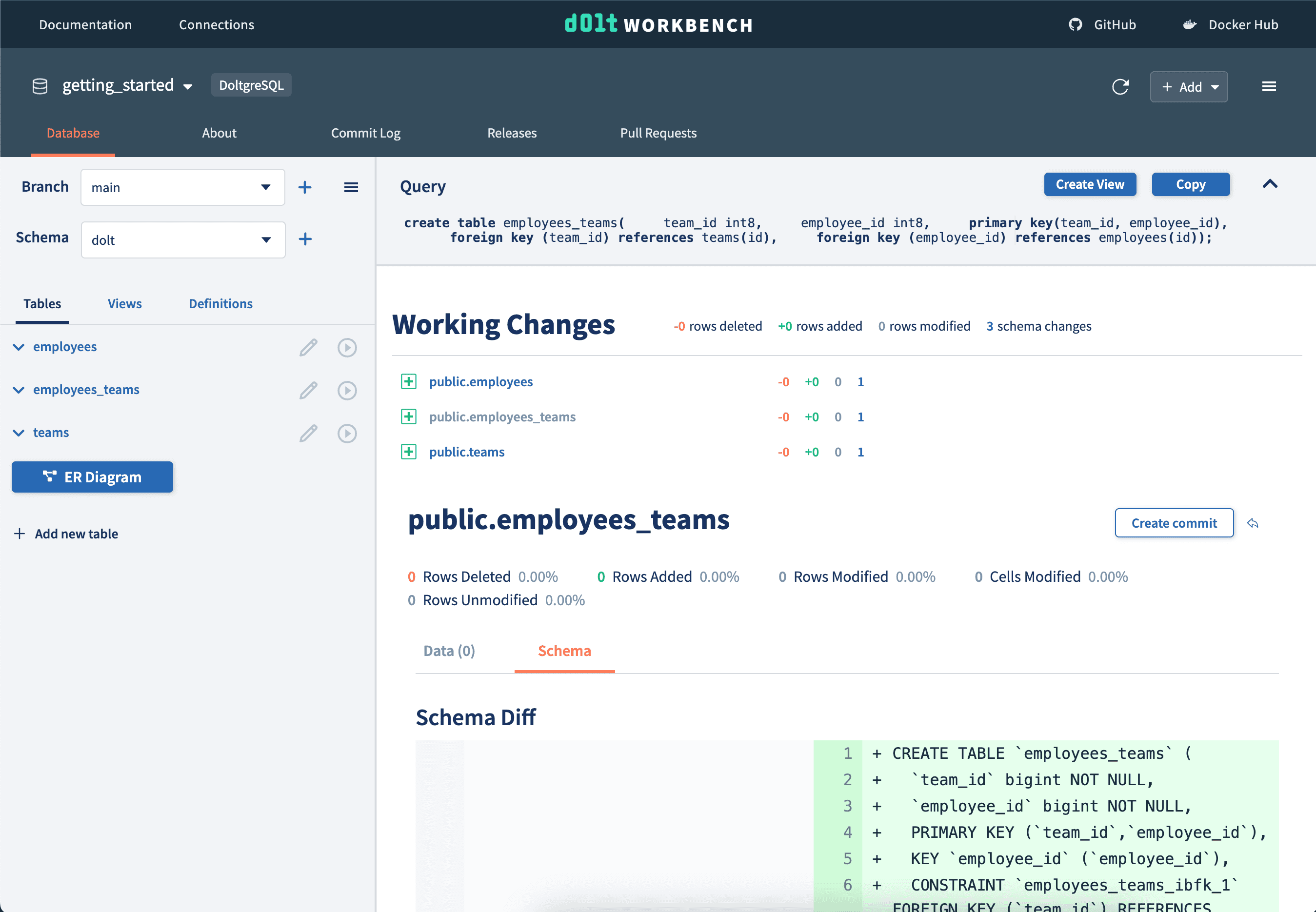
We can see the tables and their columns being added to the left table list.
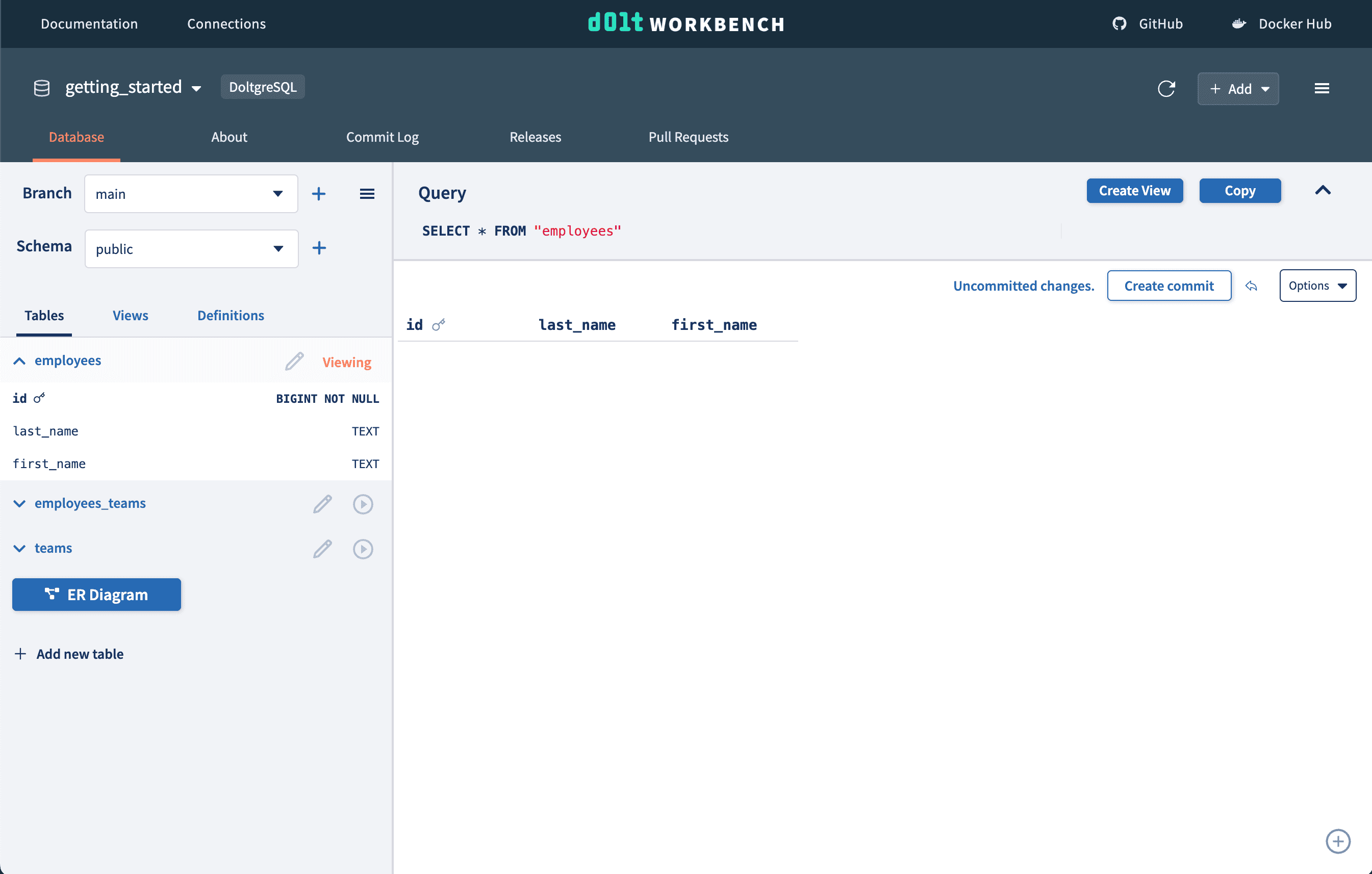
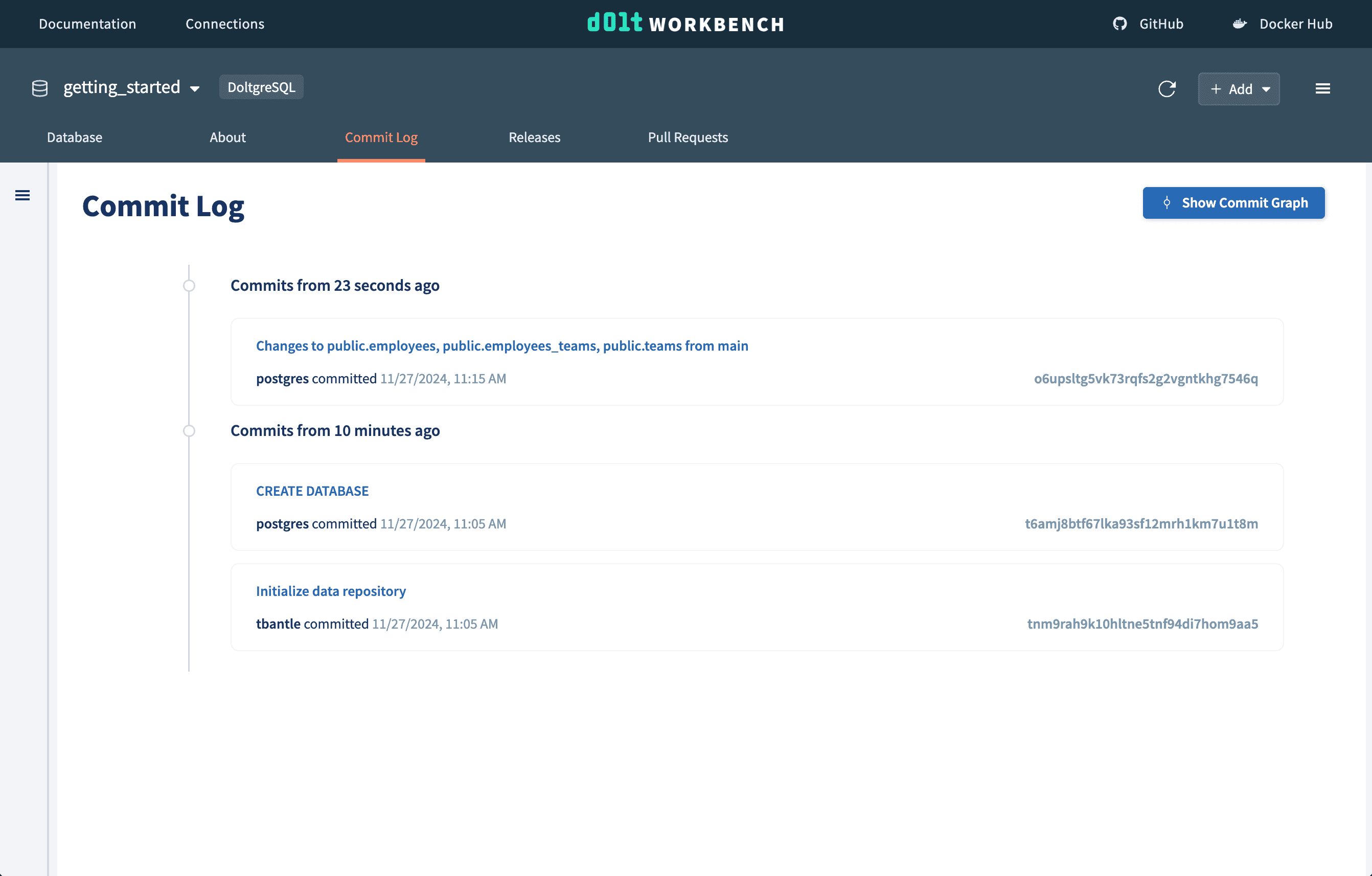
We can then commit our new schemas using the "Create commit" button, which will create a log in the commit log. We can come back to this version of the database at any point.
2. Insert some data
Postgres
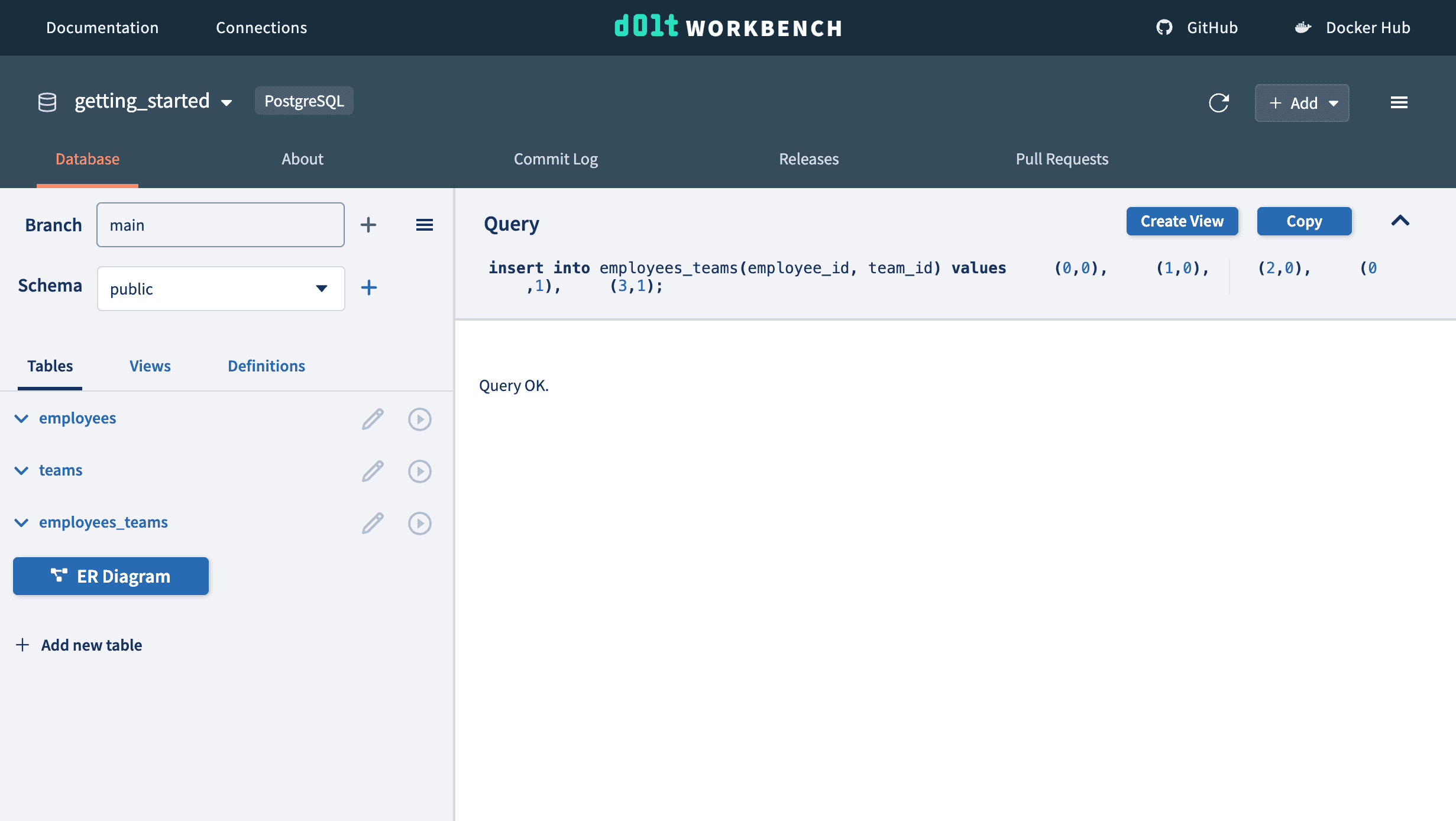
Now, we want to populate our database with some employees here at DoltHub and assign them to teams.
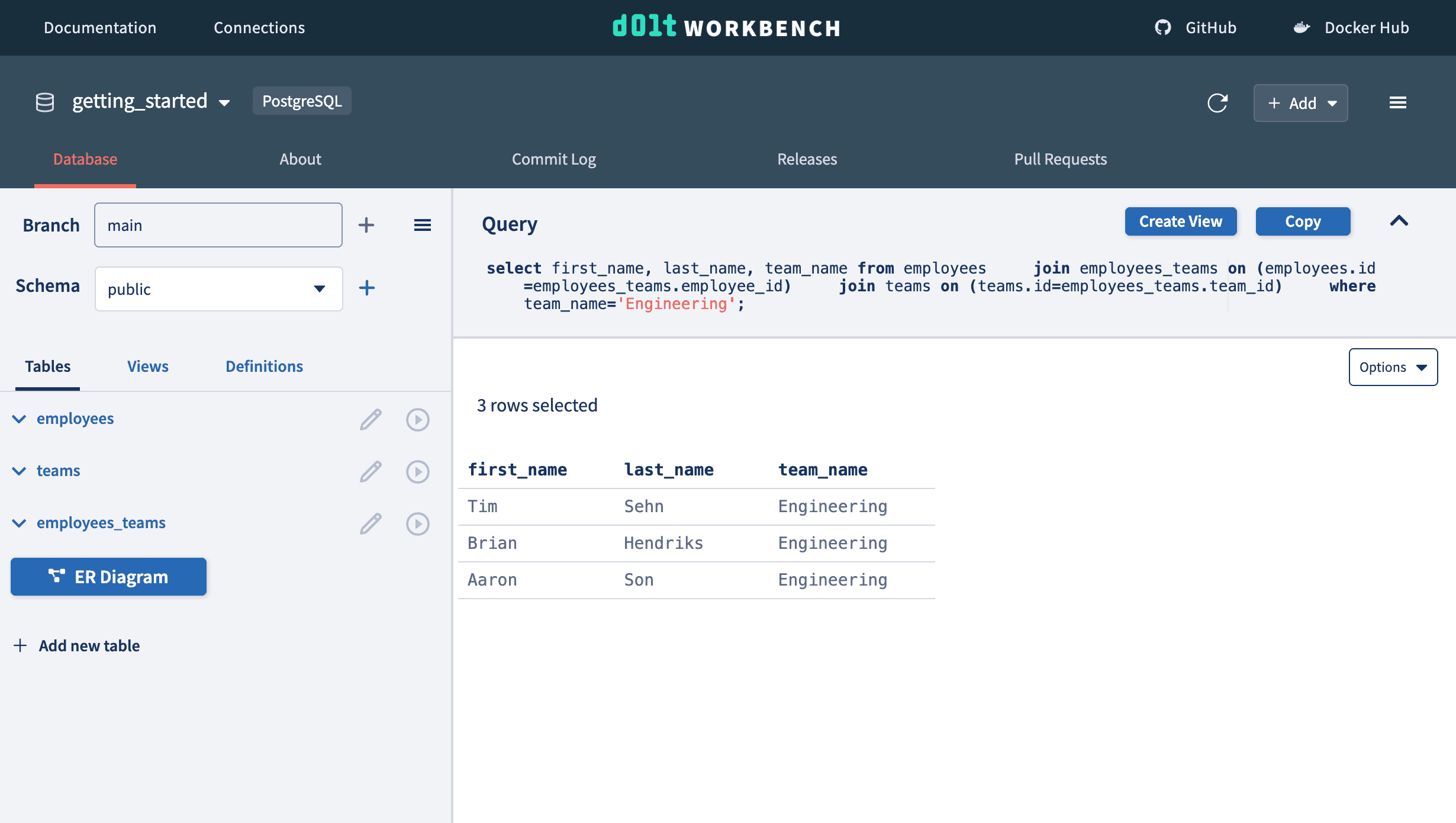
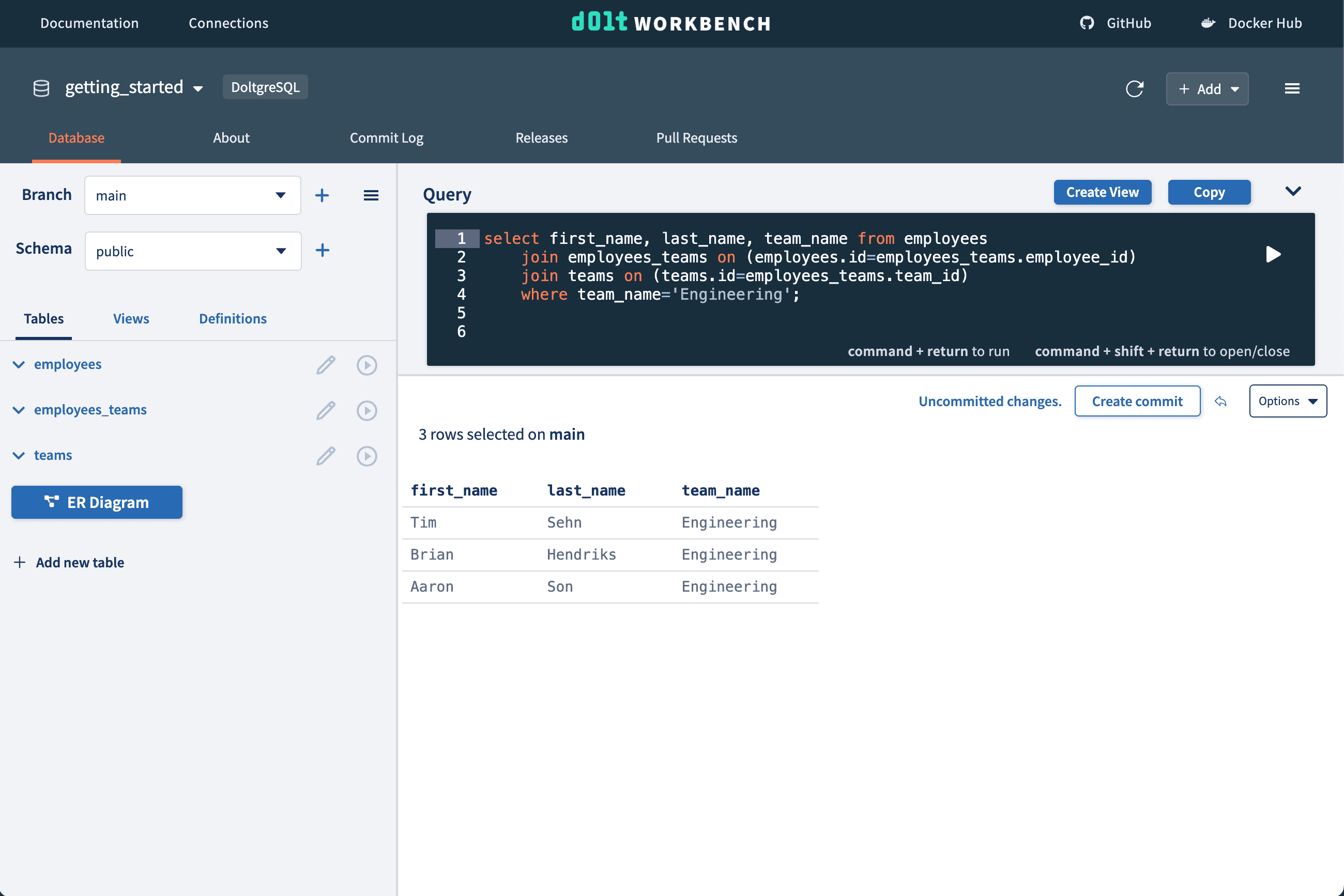
We can list members of the engineering team using a three table JOIN.
Doltgres
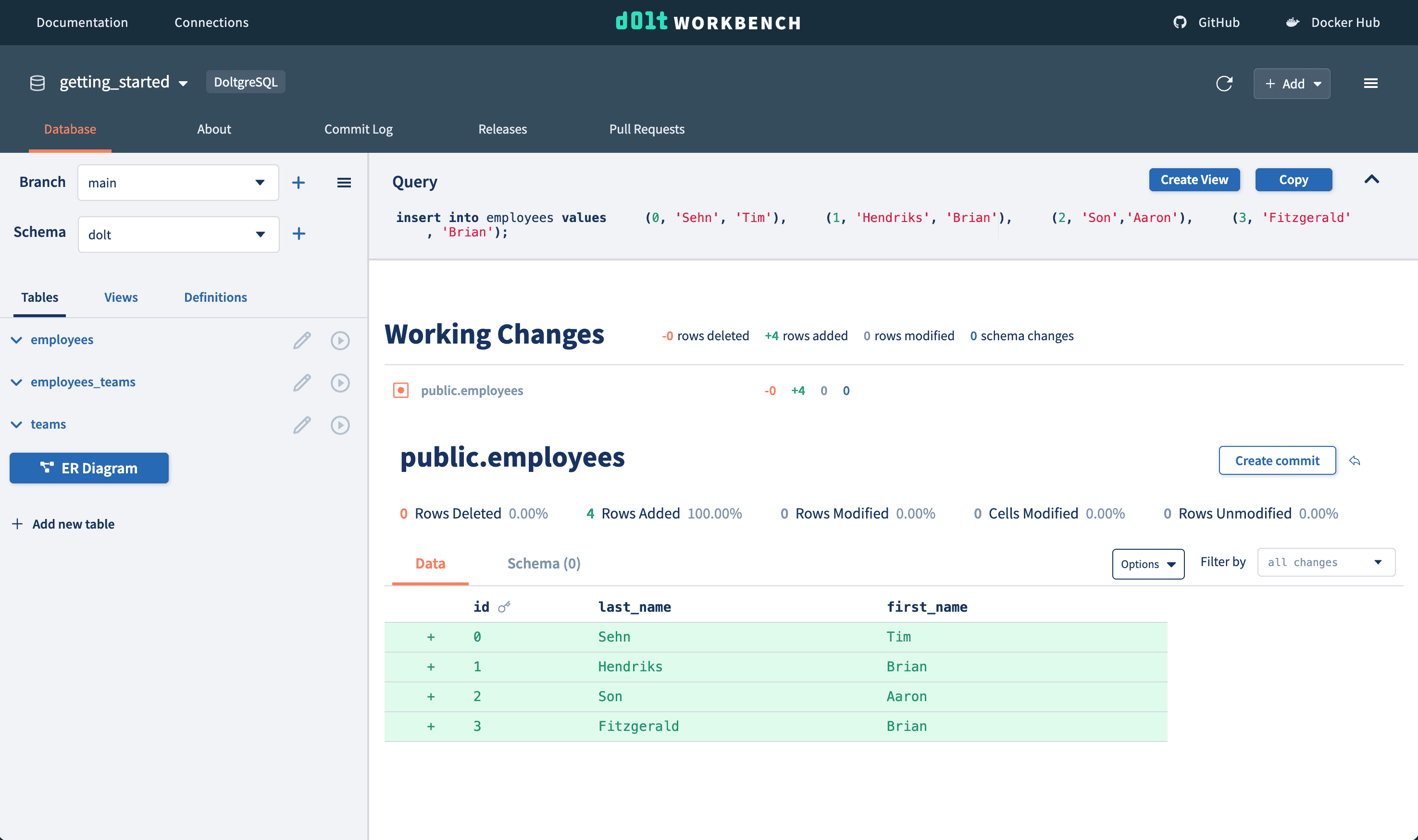
We will populate our Doltgres database with the same employees. Notice again that we always get a working diff as we execute write queries from the workbench.
We can list members of the engineering team using a three table JOIN. Doltgres comes with the full power of a modern SQL relational database.
Since we're using a version controlled database, we can examine the diff of our working changes to make sure they look correct before moving on. You can see the added rows to each table, as well as cell and row diff stats.
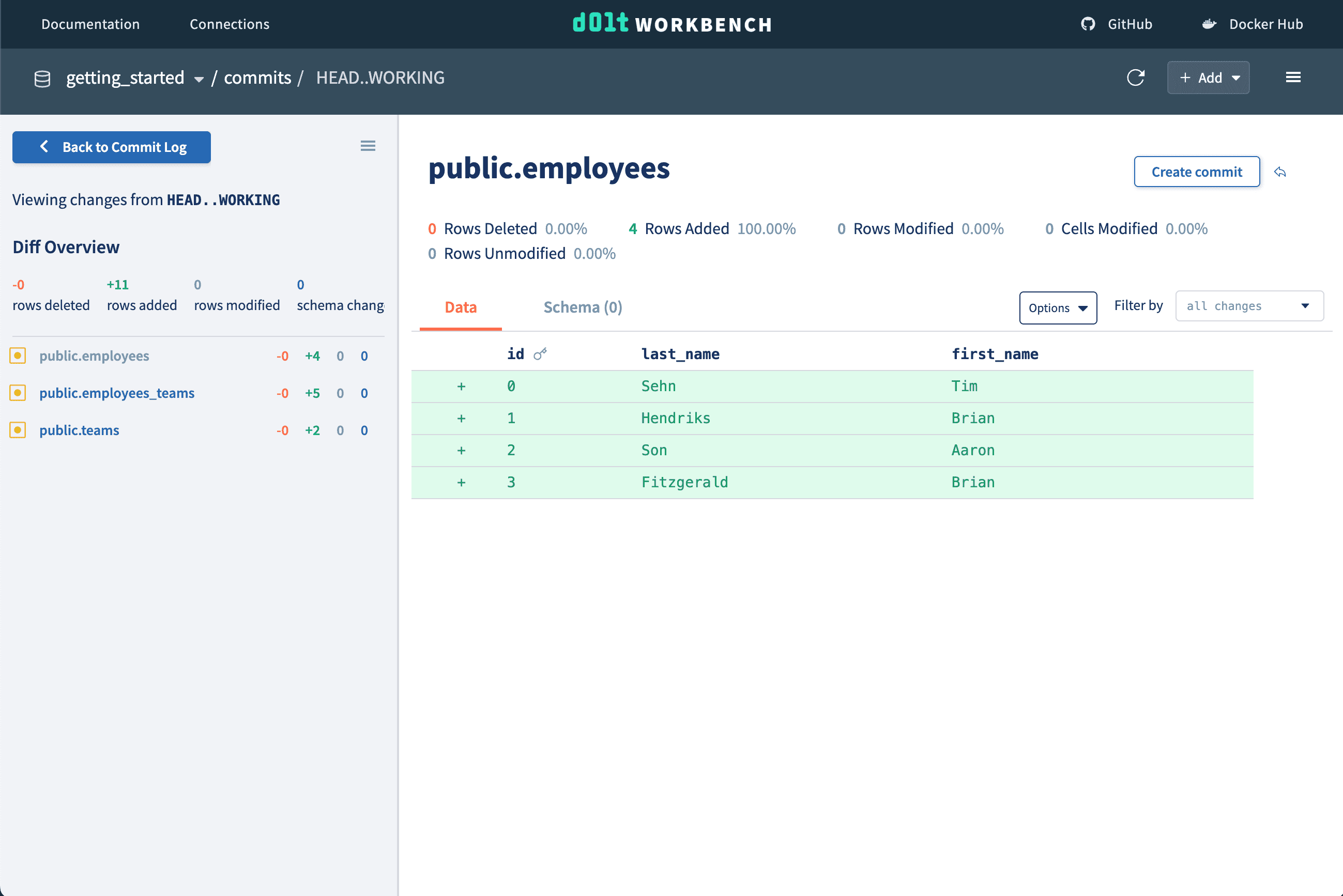
Now that we've reviewed our changes and have asserted the added data is correct, we create a commit, which we can see in the commit log if we want to know exactly what changed at this point.
3. Oh no! A mistake
Postgres
You accidentally drop the employees_teams table! Oops! It happens to the best of us.
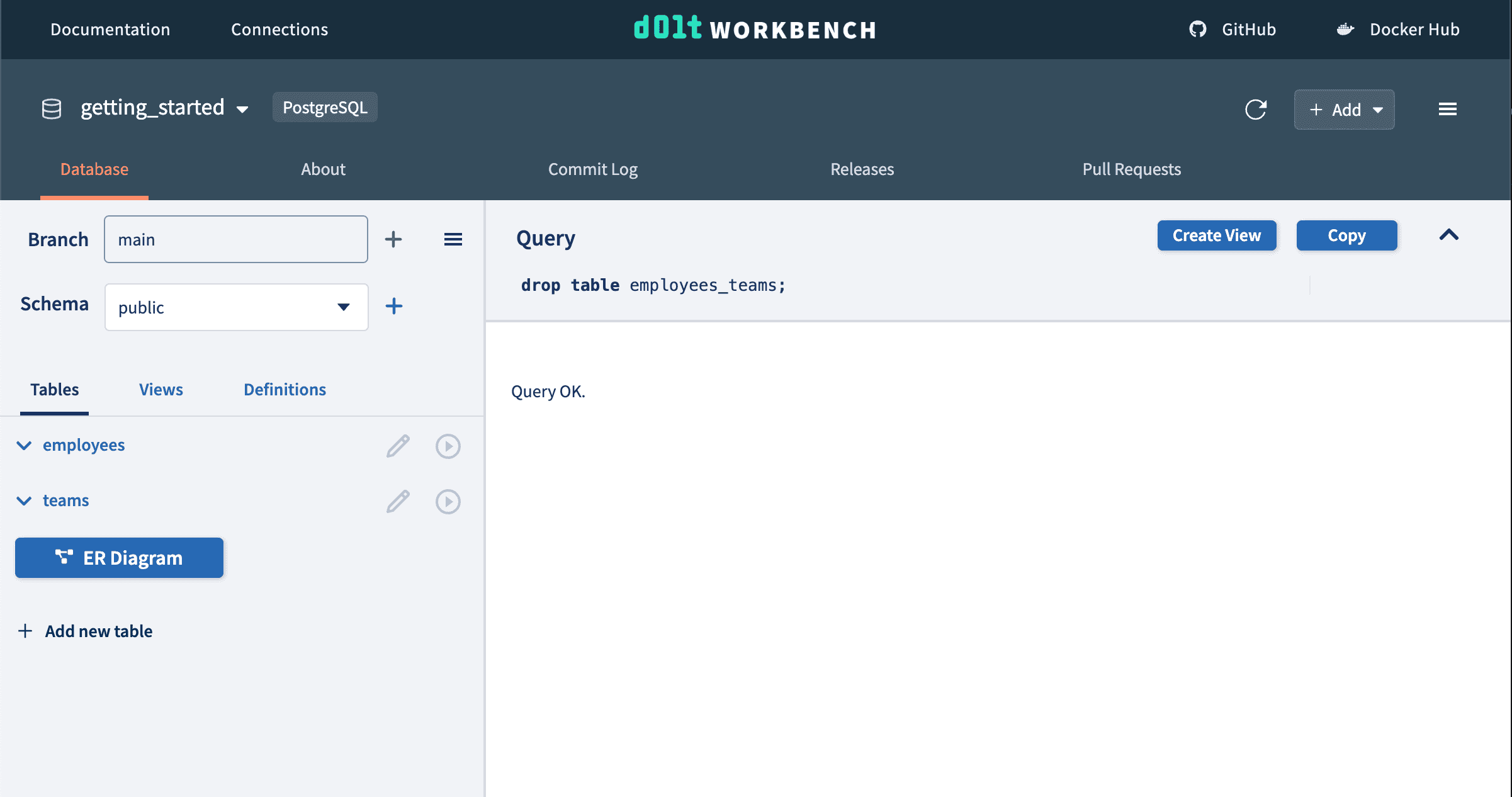
We...don't have a lot of options here unless we have a backup, which we don't. Sad day for us ☹️. Luckily, our table was small and we have access to the data we added to it. Manually recreating the employees_teams table is our only option.
Doltgres
You dropped the employees_teams table on both databases?? Rough day.
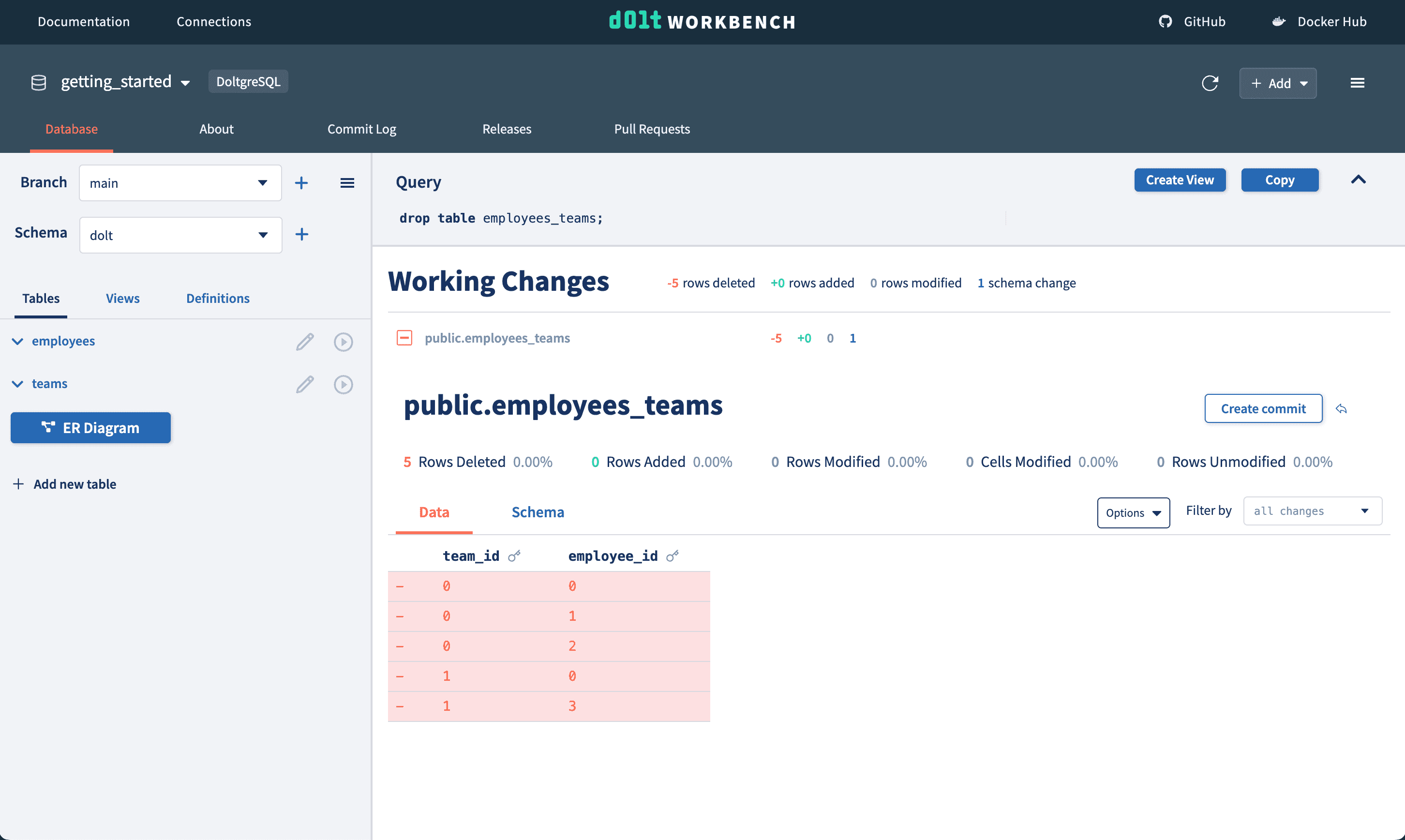
Luckily, with version controlled databases all changes are tracked and you can revert the drop with the click of a button 🙂.
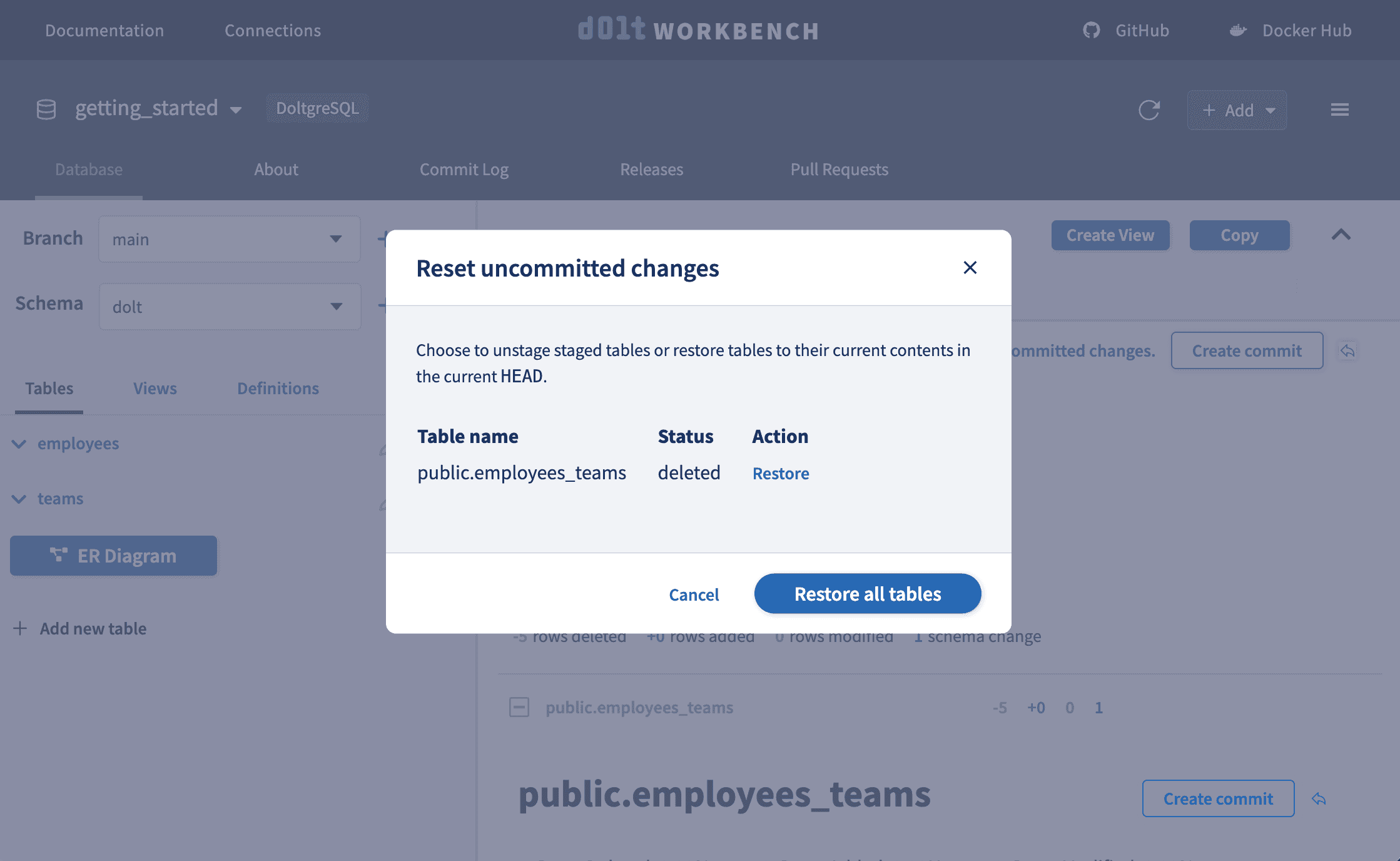
We're back in business with minimal downtime and no data loss. Version control FTW!
4. Modifying data
Postgres
While it's relatively easy to view added rows to a table, reviewing modifications to rows without version control is less obvious. We make a few updates, inserts, and deletes. Can you tell from a quick glance what changed here from above?
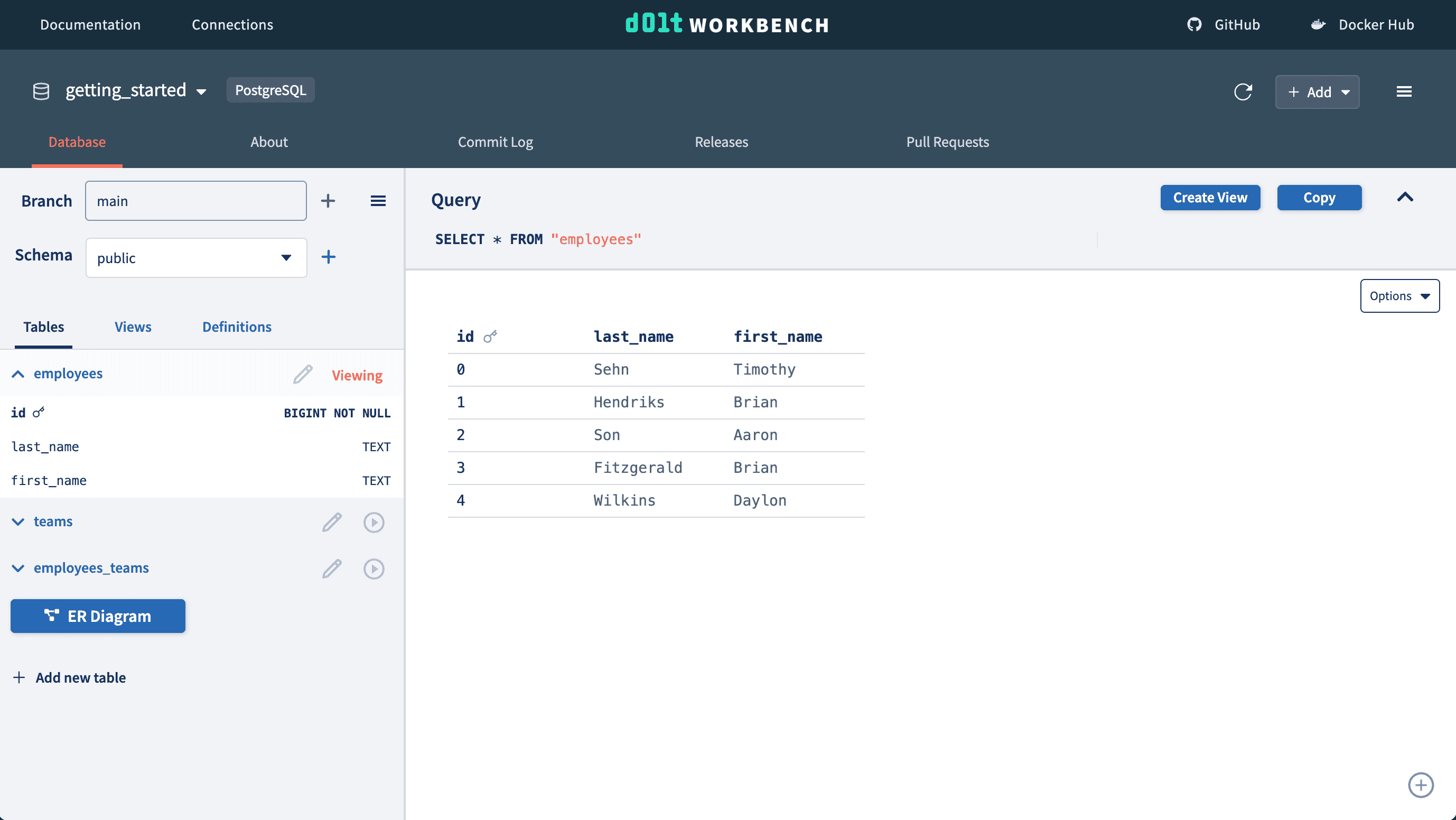
Doltgres
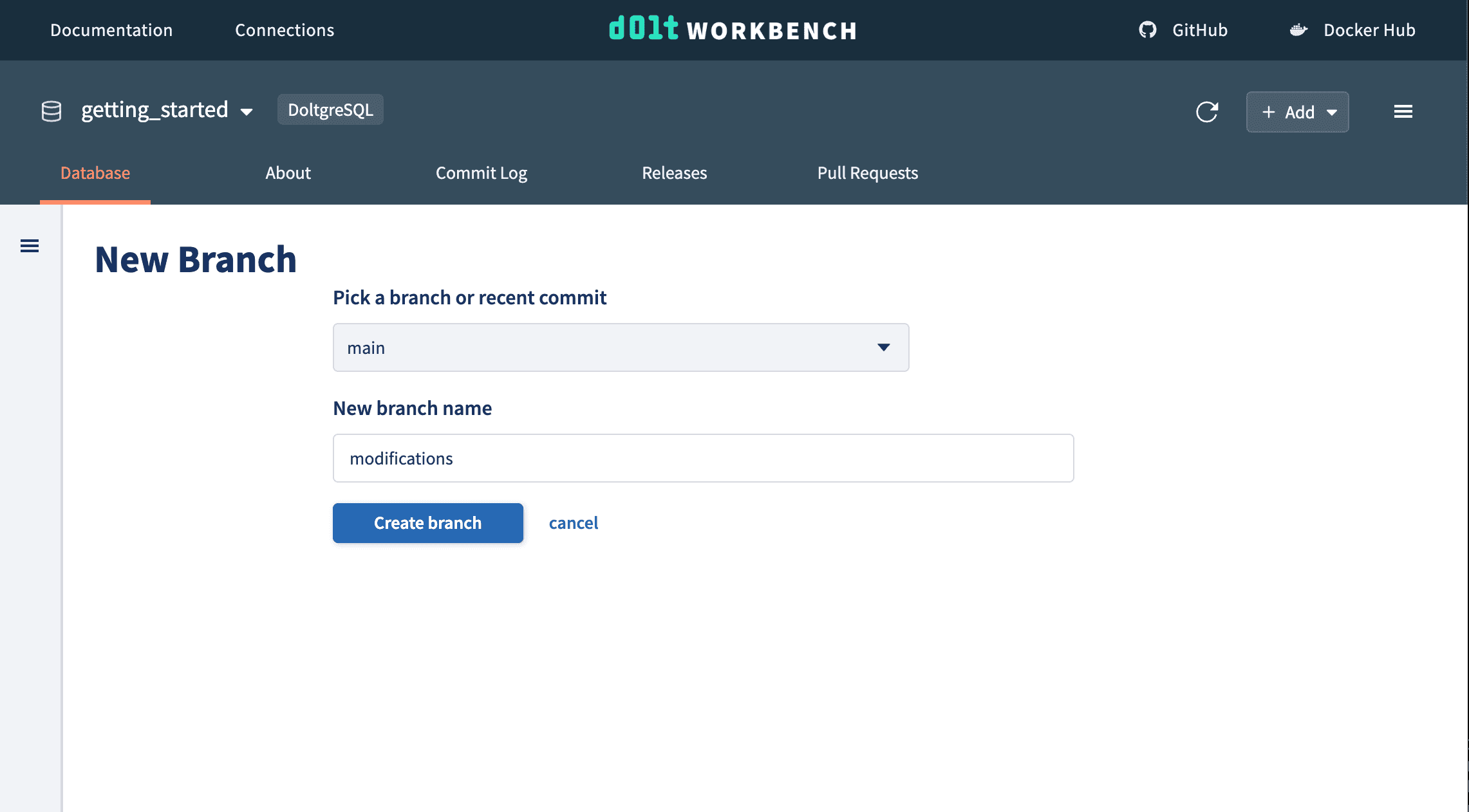
Using a version controlled database, we can test data or schema changes in isolation without affecting the "main" database using branches. We create a modifications branch to make the same data changes as above.
Every time we run a write query we see exactly what changed in the working set.
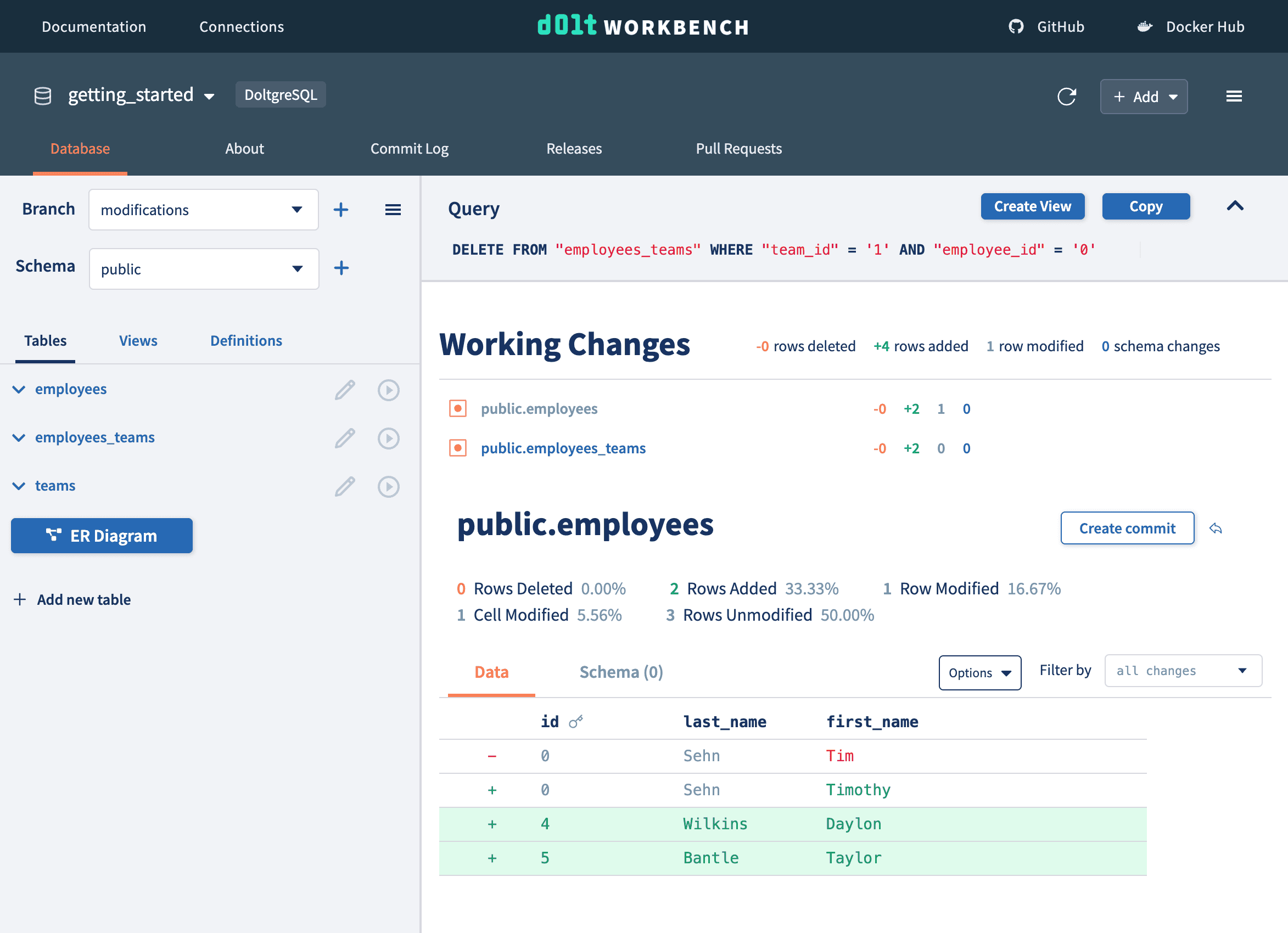
Once we're done making changes, we create a commit. Our main branch has not changed. We can view a pull request between these branches.
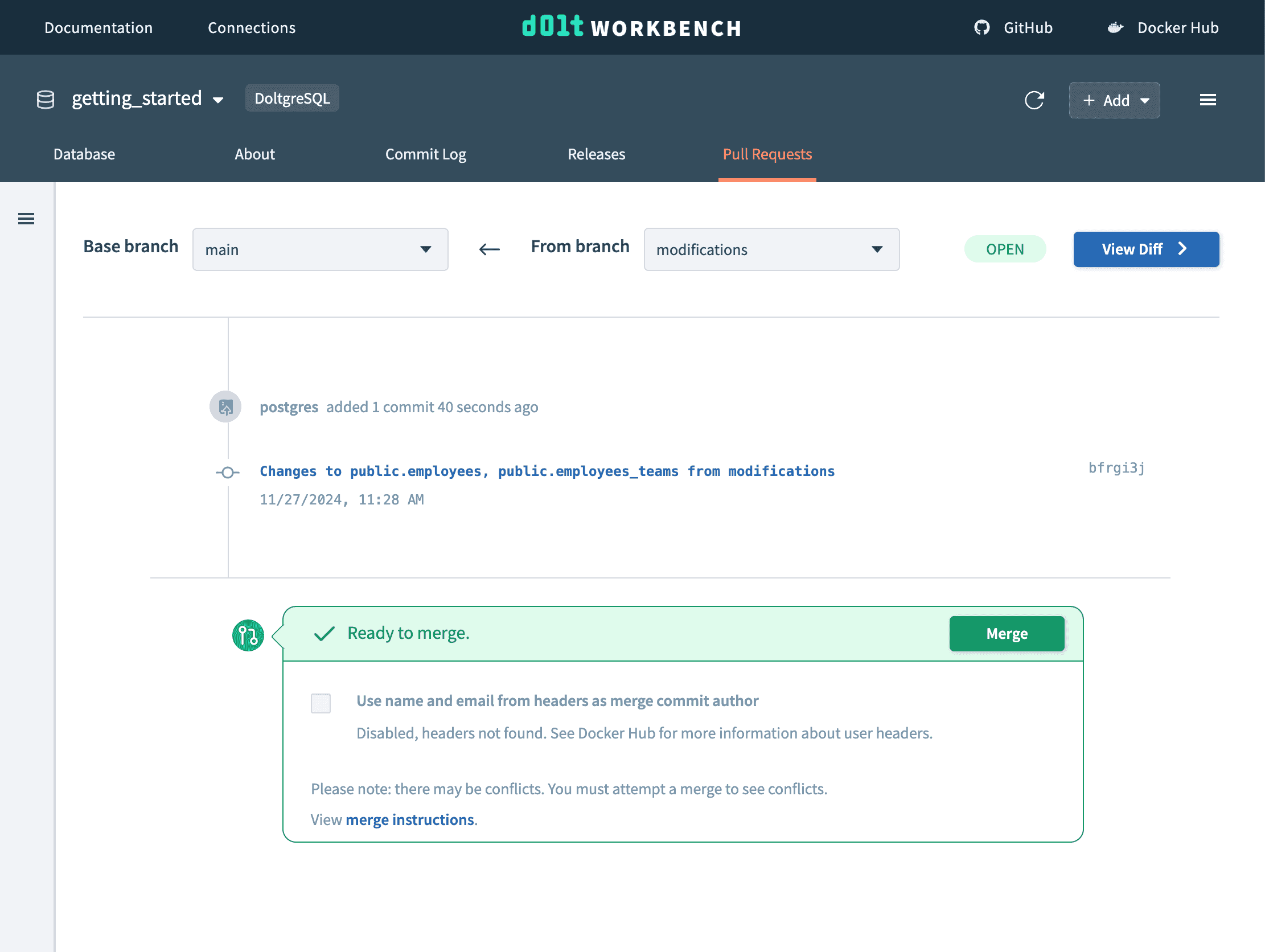
And view the diff to review the changes made on this branch. We can merge the pull request at any point.
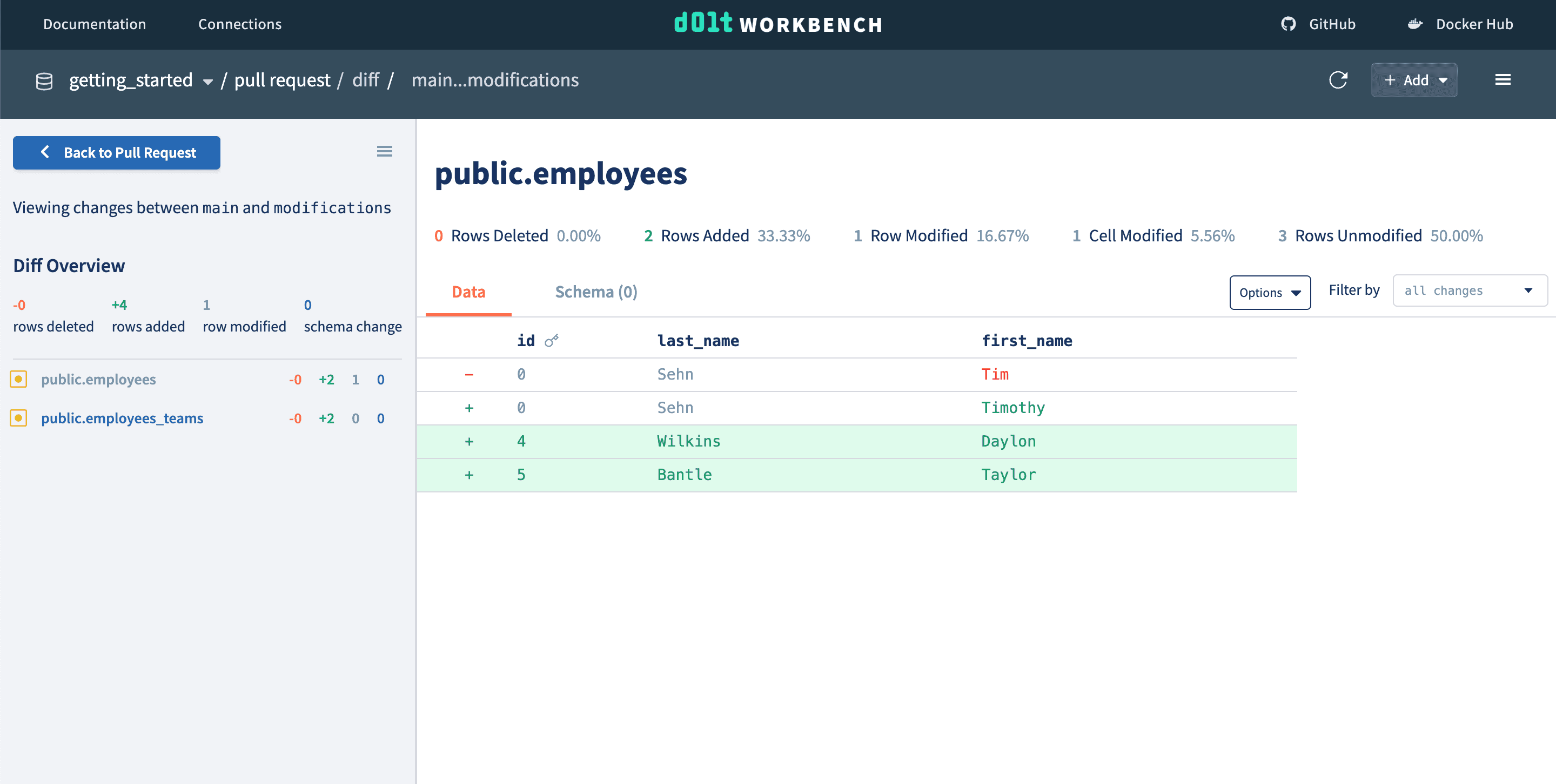
5. Modifying schema
Postgres
We want to add a new start_date column to our employees table and populate it. We run the necessary queries and they update our database immediately with the changes.
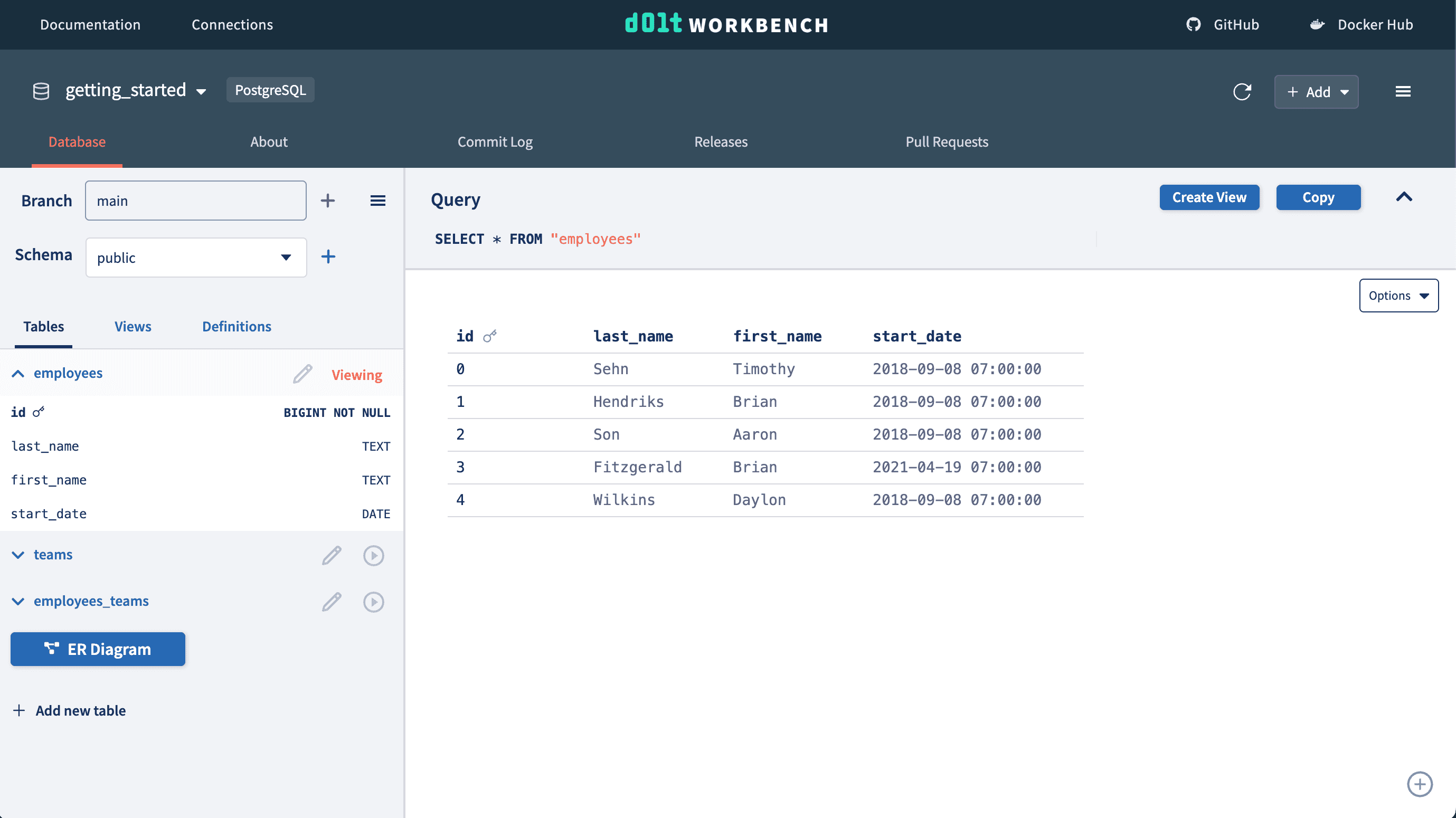
If we make a mistake with our schema change it is reflected in our database.
Doltgres
Similar to our data modifications, we want to test our schema change in isolation. So we create a new branch.
When we run queries to add the column and populate them, we get both a data AND schema diff.
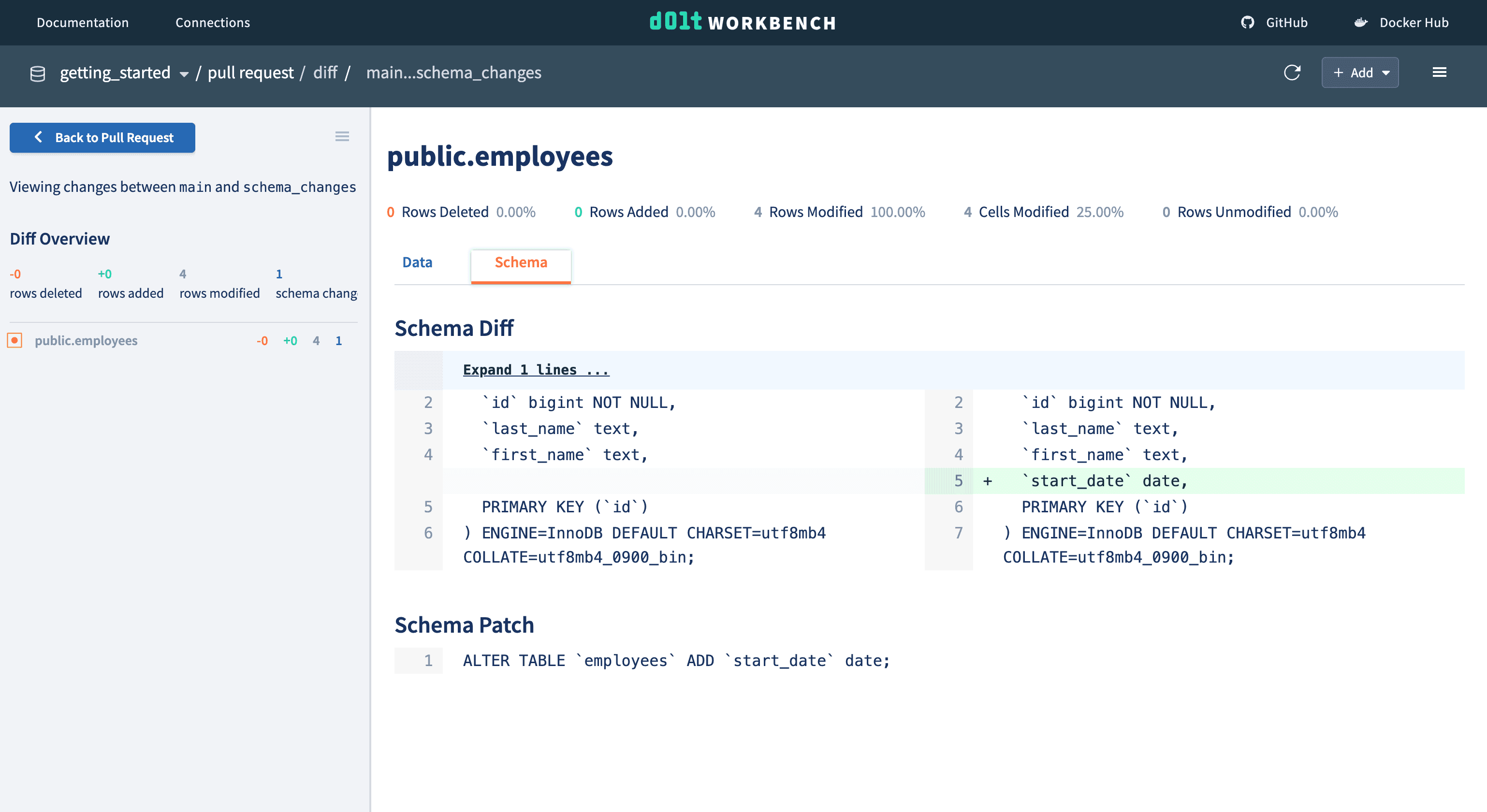
This makes it very easy to see how the schema changed and when. We can test our schema change in isolation without affecting our main database.
6. Merge
Postgres
Not applicable ☹️.
Doltgres
Now that we have some data and schema modifications on branches and have reviewed these changes, we can merge them all together. Merging a pull request using the Dolt Workbench works the same way as merging a pull request for code on GitHub.
First we merge our schema branch. When we go to the main branch, we see our new column.
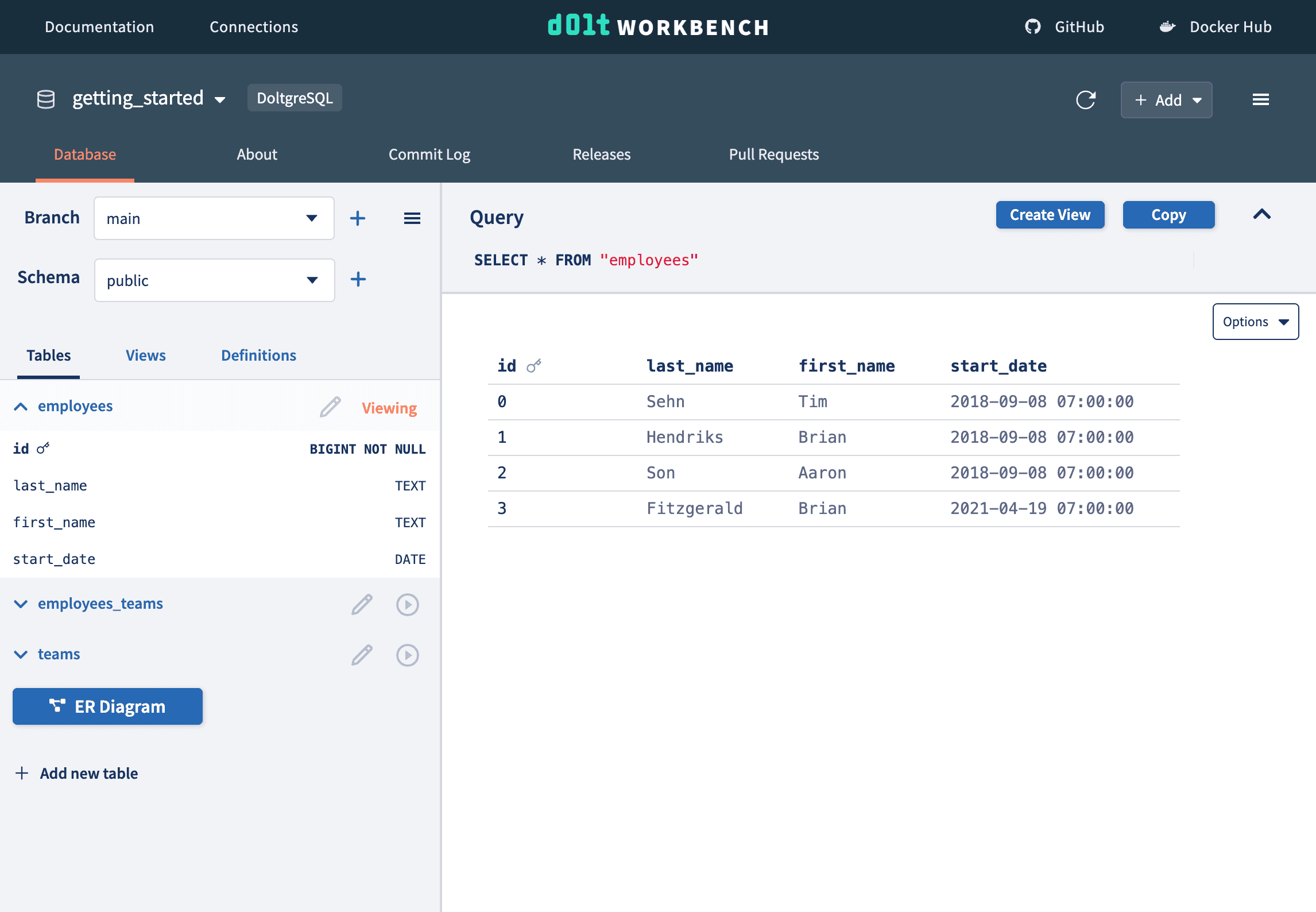
Next, we merge our data modifications branch. When we go to the main branch, we see our data changes. Notice that even though the start_date column didn't exist when we created our modifications branch, it doesn't affect the merge or existing data.
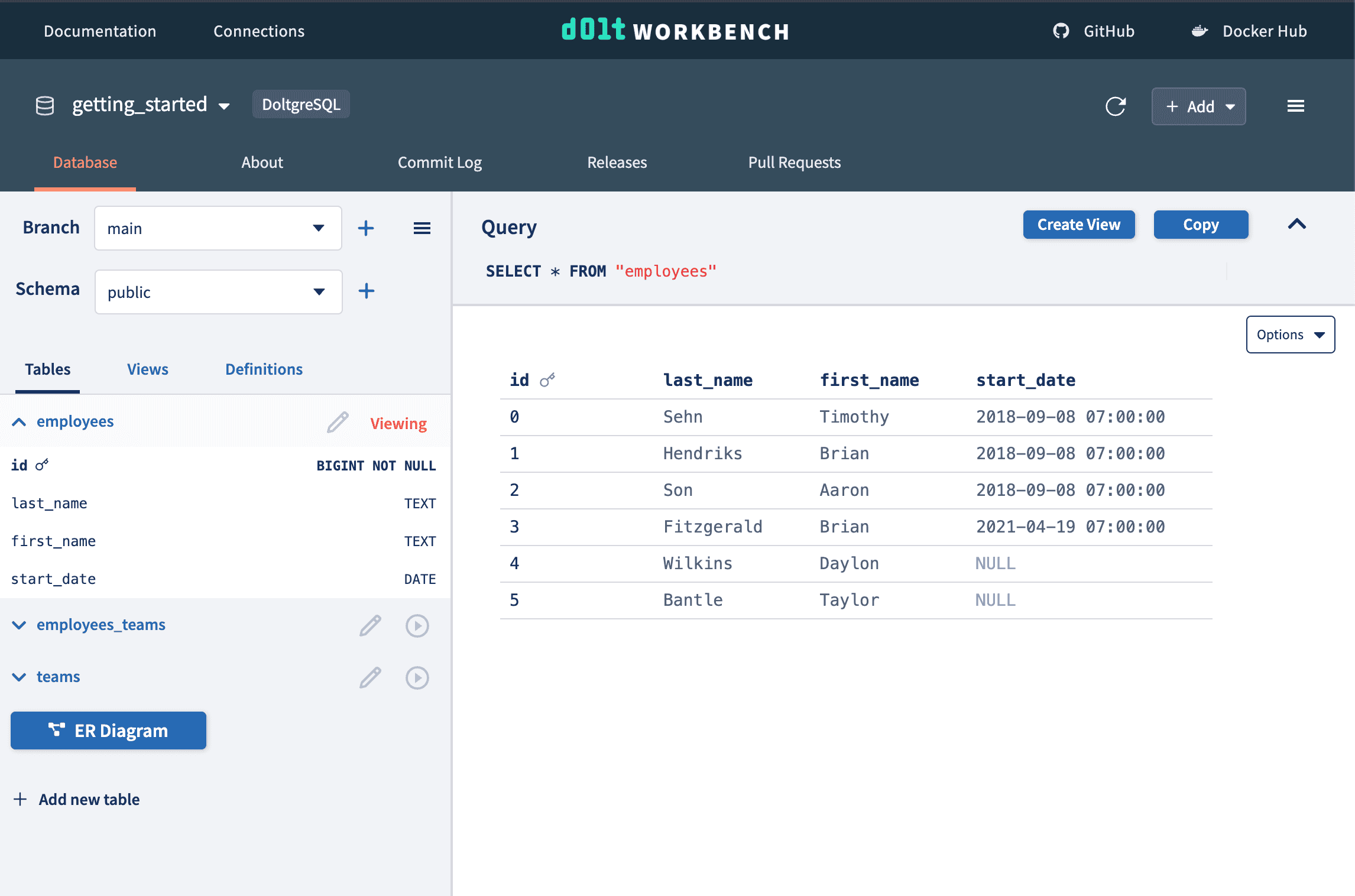
This is due to cell-level three-way merge. Even if there is more than one change to a row, merging changes is successful. If there are two changes to the same cell, this will create a conflict that can be resolved before completing the merge.
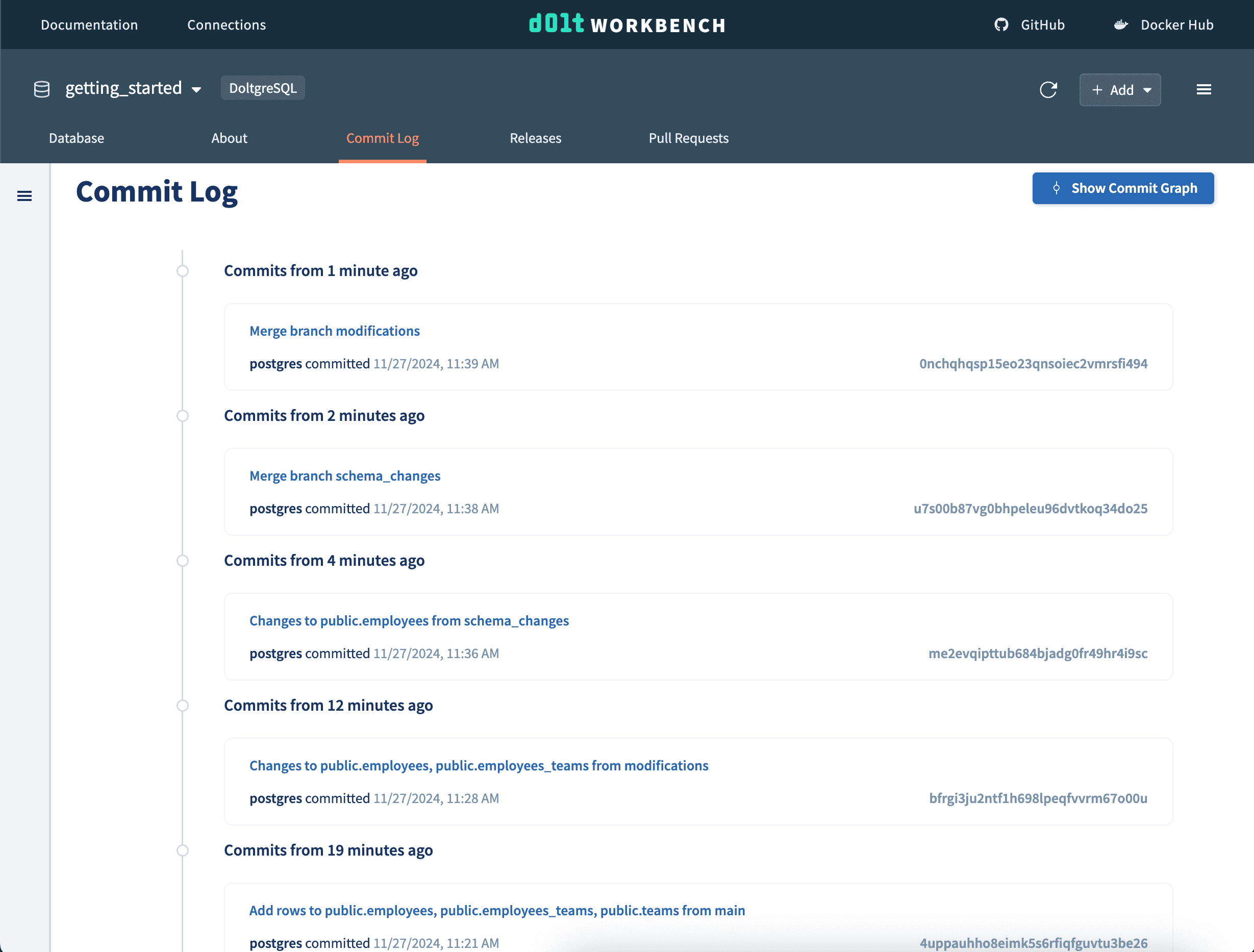
We can see the commits made on both of these branches in the commit log on the main branch, as well as the merge commits.
7. Data auditing
Postgres
Not applicable ☹️.
Doltgres
With a version controlled database, you have lineage for every cell in your database. Use the cell dropdown on any cell to see the history of how every row or cell changed and when.
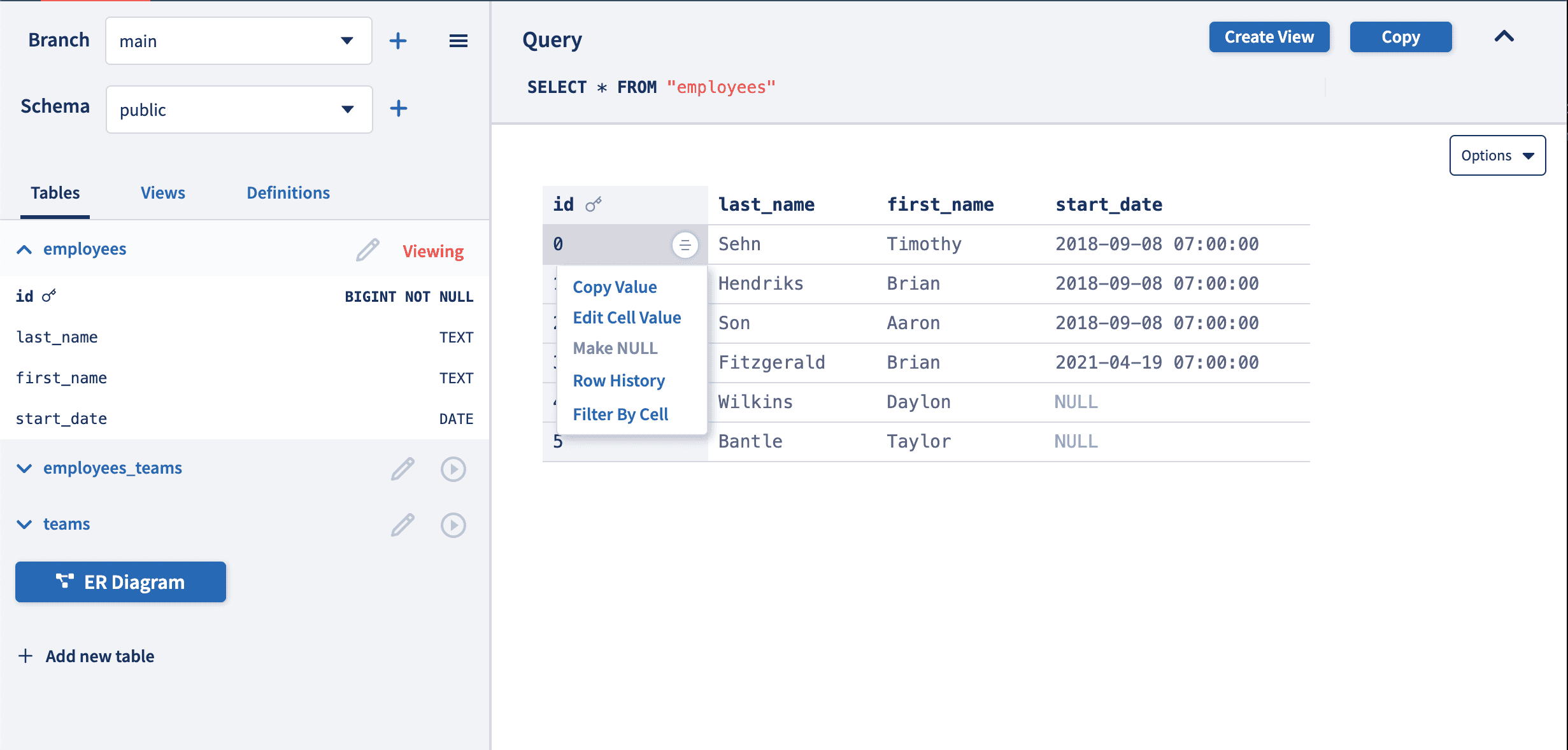
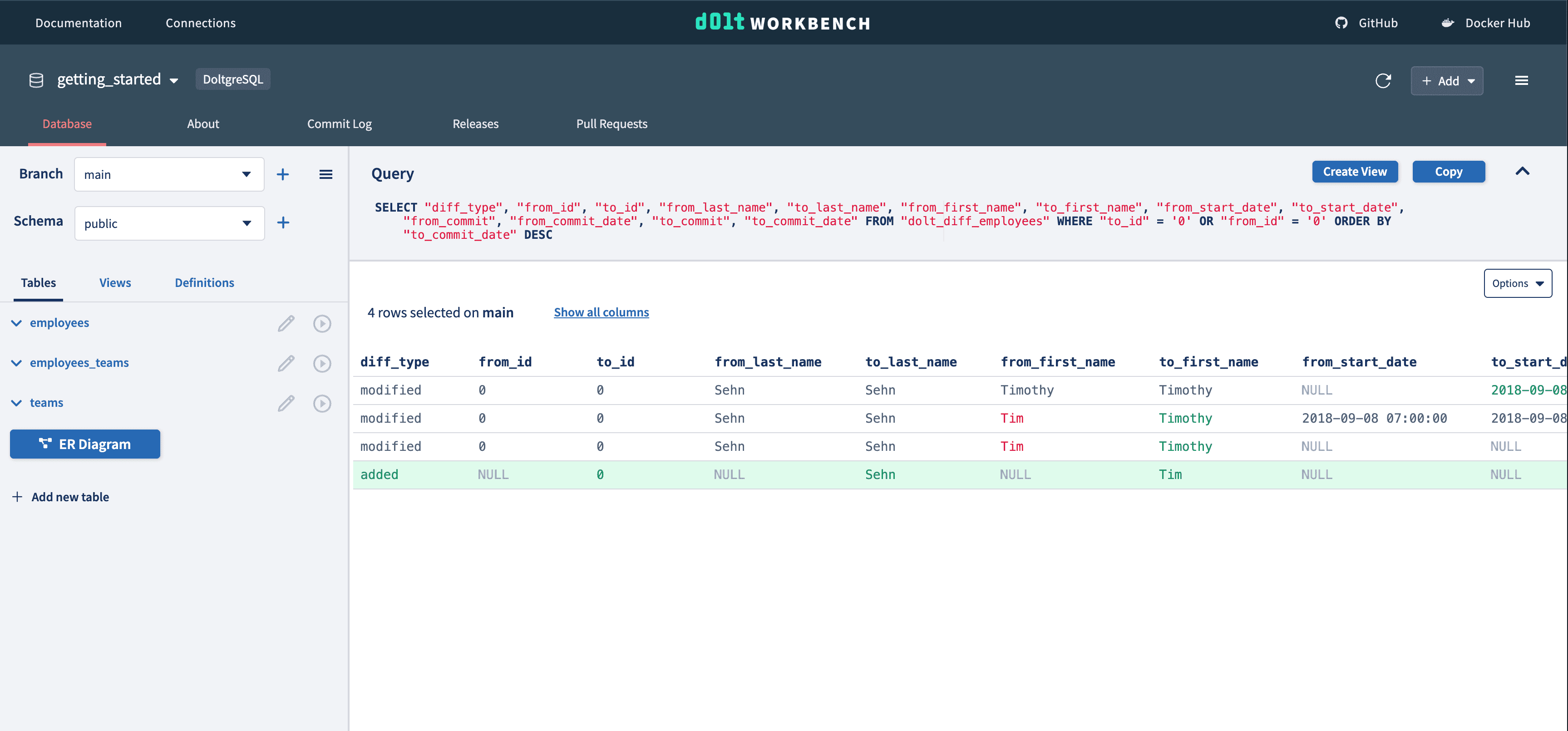
As well as a history of who changed that row at each commit.
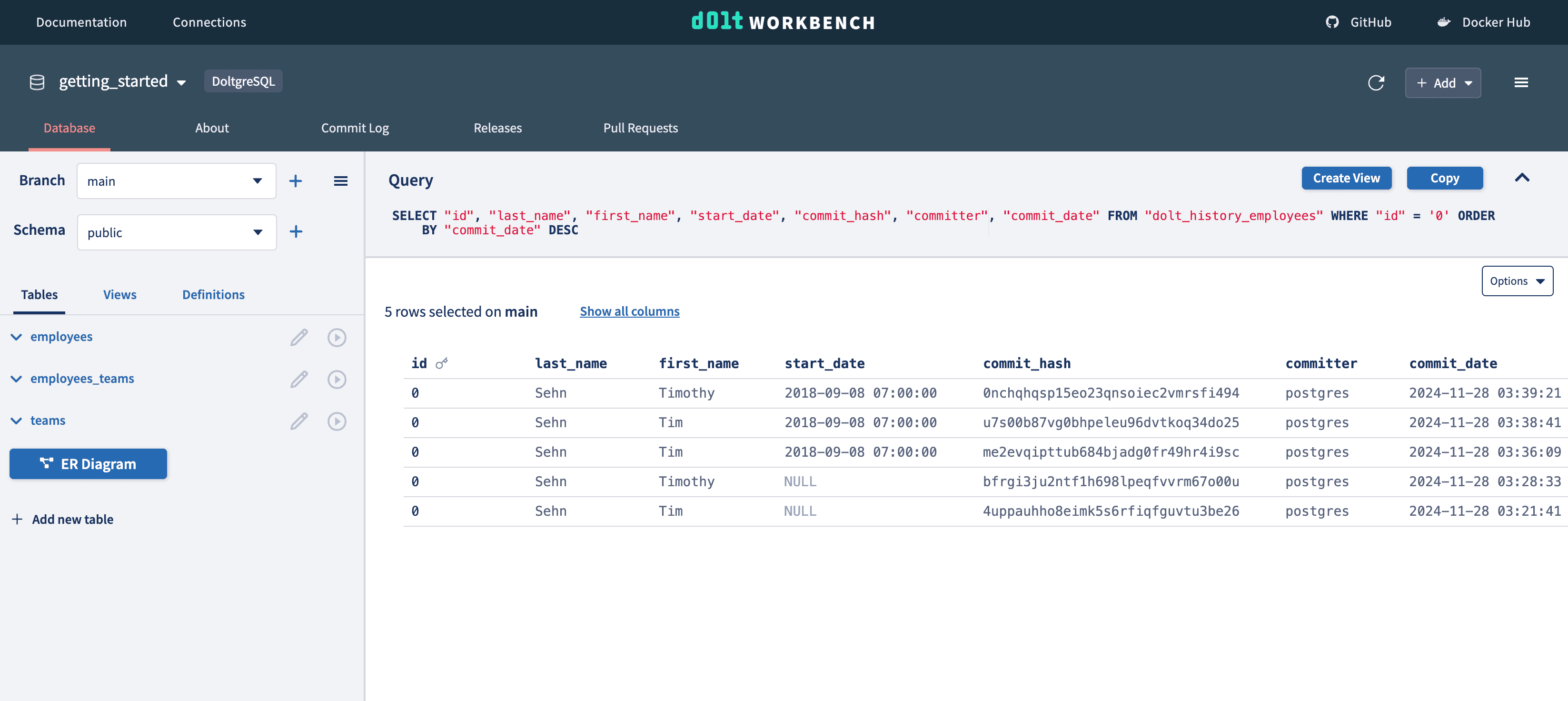
Version controlled databases provide powerful data audit capabilities down to individual cells. When, how, and why has each cell in your database changed over time?
Conclusion
We may be biased, but hopefully we have convinced you that using a SQL workbench and operating a database in general is better when the database supports versioning. Have questions or need more convincing? Join our Discord and ask away.