
Dolt is the world’s first and only version-controlled SQL database. It’s a SQL database that you can fork, clone, branch, merge, push and pull just like a Git repository. Like files in Git, tables and other data in Dolt are content-addressed by a cryptographic hash of their contents.
In this blog, we’ll discuss an important design goal we discovered when iterating on Dolt’s capabilities in the early days of product development: history independence.
What’s history independence?#
Dolt stores its data internally in a data structure called a prolly tree, which is like a cousin to the B-tree used in most traditional databases. Prolly trees are content-addressed, and each child pointer is the cryptographic hash of the contents of the child element.

These data structures are what make diffing and merging efficient. To determine what’s different between two trees, you start at the top and walk all the child pointers. If you ever encounter two child pointers that have the same hash, you can skip that entire subtree, because you know it has the same contents. This is the magic of Dolt’s efficient diff and merge operations, which scale with the size of the diff, rather than the size of the table.
You can read more about how Dolt’s prolly trees work in our documentation.
There’s nothing inevitable about this property of prolly trees. You can imagine many different ways of building two trees that, despite having identical data, nevertheless are represented by different trees. For Dolt, that’s very bad. Not only does it make our basic diff and merge operations inefficient, it leads to wasted space as revisions of the database that should share storage chunks cannot.
This leads us to our definition of history independence.
History independence is the property that no matter what set of statements produced a table with a particular schema and rows, it has the same binary representation and therefore the same hash.
Let’s look at an example. We’ll create two tables on two different Dolt databases. The tables will have the same schema and the same rows, but we’ll create them with very different sets of statements.
First a table on db1:
db1/main> create table t1 (a int primary key, b int, c varchar(10));
db1/main*> insert into t1 values (1, 2, "three");
Query OK, 1 row affected (0.01 sec)
db1/main*> insert into t1 values (4, 5, "six");
Query OK, 1 row affected (0.00 sec)
db1/main*> insert into t1 values (7, 8, "nine");
Query OK, 1 row affected (0.00 sec)
db1/main*> select * from t1;
+---+---+-------+
| a | b | c |
+---+---+-------+
| 1 | 2 | three |
| 4 | 5 | six |
| 7 | 8 | nine |
+---+---+-------+
3 rows in set (0.00 sec)
db1/main*> select dolt_hashof_table('t1');
+----------------------------------+
| dolt_hashof_table('t1') |
+----------------------------------+
| sbb055umg89qqiq9upb1omkpug5bboqm |
+----------------------------------+
1 row in set (0.00 sec)Now let’s create the same table on db2, but with a different sequence of statements.
db2/main> create table t1 (a int primary key, b int);
db2/main*> insert into t1 values (10, 100);
Query OK, 1 row affected (0.00 sec)
db2/main*> insert into t1 values (40, 1);
Query OK, 1 row affected (0.00 sec)
db2/main*> insert into t1 values (70, 55);
Query OK, 1 row affected (0.00 sec)
db2/main*> alter table t1 add column c varchar(10);
db2/main*> update t1 set a = a / 10;
Query OK, 3 rows affected (0.01 sec)
Rows matched: 3 Changed: 3 Warnings: 0
db2/main*> update t1 set c = "three" where a = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
db2/main*> update t1 set c = "six" where a = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
db2/main*> update t1 set c = "nine" where a = 7;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
db2/main*> update t1 set b = a+1;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
db2/main*> select * from t1;
+---+---+-------+
| a | b | c |
+---+---+-------+
| 1 | 2 | three |
| 4 | 5 | six |
| 7 | 8 | nine |
+---+---+-------+
3 rows in set (0.00 sec)
db2/main*> select dolt_hashof_table('t1');
+----------------------------------+
| dolt_hashof_table('t1') |
+----------------------------------+
| sbb055umg89qqiq9upb1omkpug5bboqm |
+----------------------------------+
1 row in set (0.00 sec)So here are two tables, on two databases, that were created with different sequences of statements,
including some ALTER TABLE statements. But they end up with the same schema and data, so they end
up with the same binary representation and therefore the same internal hash,
sbb055umg89qqiq9upb1omkpug5bboqm. This means that Dolt can trivially determine that these two
tables are the same during a diff or merge operation.
Why does history independence matter?#
Like Git, Dolt has clones, forks, and remotes. This means that it has to natively support
distributed workflows, taking place across multiple machines, where different users are all
modifying the data at the same time. At any point, one of those distributed users could push their
changes to a remote (or another running database server), and their changes have to be merged with
what’s already there. In the distributed use case, it’s important at large scale that two people who
create the same data can merge it together efficiently.
For several years we ran a data bounties program that used this distributed workflow. Each bounty hunter would create a fork of the main database, import some data they found online, and open a pull request to merge their additions (or corrections) back in.
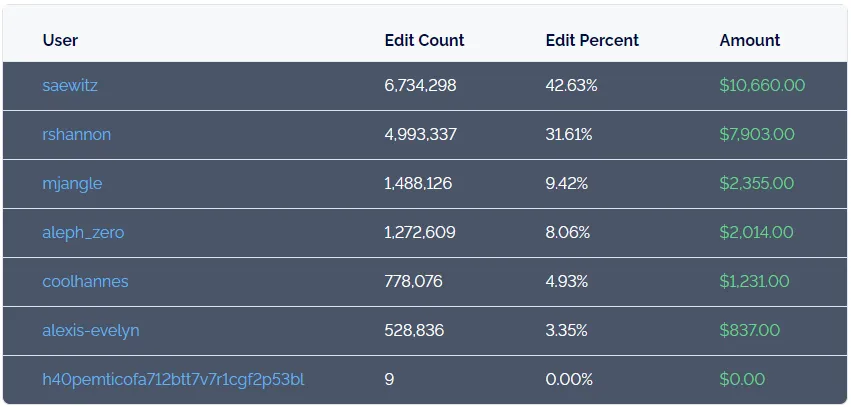
If two people find slightly different government csv files when scraping the web for data, when
they import them they should get very similar tables. And if they make manual edits to the data (a
very common part of data import workflows), we should be able to efficiently find where they are
different so we can merge them back together and credit the right person.
A lot of Dolt customers have the same need: multiple people work on local clones of a database, they import a bunch of data from elsewhere using a variety of tools, and they want it to come out the same in the end. History independence is the guarantee that makes that possible.
History independence in Doltgres#
We are hard at work building Doltgres, the Postgres-compatible version of Dolt. Doltgres has a storage format that diverges slightly from Dolt’s in order to support Postgres features that MySQL doesn’t have, things like sequences and schemas. As we build out these features the topic of history independence has come up repeatedly.
For example, Postgres has identifiers called
OIDs that are used extensively
throughout the internal tables, including in the
pg_catalog tables. This matters for
Doltgres because it needs to return correct information from these pg_catalog tables for tool
compatibility, which means having consistent and meaningful OIDs.
One easy option to implement OIDs would have been to write them into the serialized schemas of tables and other database objects. But a little discussion revealed why this would be a bad idea: it breaks history independence if we do it in a serial fashion (tables would have different OIDs if two users created them in a different order), and if we calculated them deterministically with a hash function, the relatively small key space (just 31 bits) would lead to a 1% collision rate after around 6500 schema elements, which was much too low to use as a production solution.
So instead, we calculate OIDs on the fly as needed. This comes with its own set of challenges, but it’s the better solution for the time being.
Conclusion#
We’ve been building Dolt for over 5 years, and a lot of careful design has gone into it. History independence is one of the guiding principles we use when thinking about how we should design new features, and it’s been very useful when weighing the tradeoffs of different proposals. And we think sticking to this principle has paid off in making the product work the way our customers expect, with fewer surprised and edge cases.
Questions, comments? Want to try out a version-controlled MySQL or Postgres server? Join our Discord server to talk our engineers in real time. We hope to hear from you!