
We recently announced support for continuous integration (CI) testing on DoltHub. This is a feature we’re excited about since it allows our users to programmatically test changes on their data, instead of relying solely on human review.
For those who aren’t familiar, Dolt is a version controlled database with Git semantics that supports branching, diffing, and merging as first-class features. DoltHub, like GitHub, is used to host Dolt databases, and it supports a pull-request style workflow. This means proposed changes on a DoltHub database can be reviewed and checked before they’re accepted into the database’s main branch.
With the addition of CI testing on DoltHub, users can make sure all automated tests pass before any changes are accepted into their main branch—a much needed feature for making data reviews more practical. Of course, human readable diffs will always be supported in Dolt and DoltHub. But since data changes can be so extensive and dense, programmatic review and automated testing is a true prerequisite for making the branching and merging of data an industry best practice.
As mentioned in our announcement post, CI on DoltHub is still in alpha, but we’re making quick progress and improvements everyday. Currently only CI on pushes are supported, but we are adding support for CI testing on pull requests next.
There’s quite a lot to discuss regarding DoltHub’s newest feature, both design and implementation-wise—far too much for a single post. Today, I’ll discuss how we came up with the design of CI on DoltHub, and in a later post, dive into the implementation details.
The Design for Dolt#
When architecting the design of CI on DoltHub, our guiding principle was to further expand the DoltHub as GitHub analogy by aiming to build a DoltHub version of GitHub’s CI platform, GitHub Actions. This would enable powerful CI tools and workflows to run on users’ databases, providing them the same countless benefits of running CI on data that they’ve experienced by running CI on source code.
With this principle top-of-mind, we committed early on in the design process to making sure CI configuration would be versioned and persisted in each Dolt database. This would mirror how GitHub Actions configuration is persisted in each Git repository, although, storing configuration in tables is different than storing it in static files.
On GitHub, yaml files defining CI configuration are stored in a Git repository’s .github/workflows directory. For DoltHub, we wanted something similar, so we opted for adding internal, CI-related SQL tables to version and persist its CI configuration.
In fact, this decision raised an interesting design challenge.
Unlike Git, Dolt versions table data, not static files. But static files are a really good interface for writing CI configuration. Raw SQL tables are a miserable interface for writing CI configuration. So, we needed a painless way for end-users to write their configuration to Dolt’s internal CI tables without requiring them to manually make inserts.
So once again, we decided to match GitHub as much as possible.
We decided DoltHub’s CI interface, like GitHub’s, would be yaml files. But, instead of storing these static files in Dolt, users would “import” them into their database. “Import” here means that Dolt would parse the yaml files and write its contents to the relevant, internal CI tables automatically.
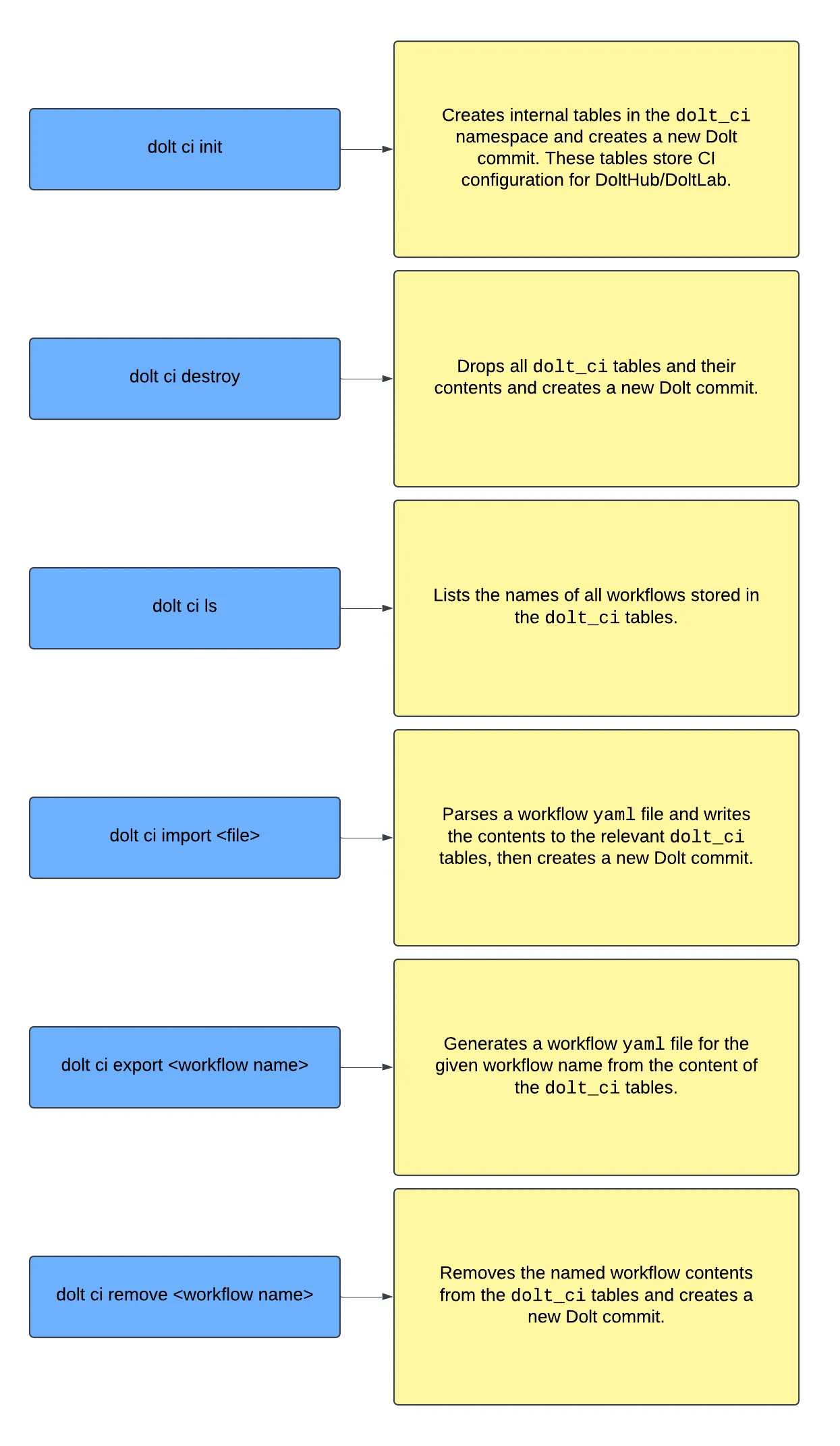
This is how we came up with the dolt ci import <file> command added to Dolt v1.43.14. This command takes a CI yaml file, stores its contents in internal dolt_ci_* tables, and automatically creates a new Dolt commit. The changes just need to be pushed to DoltHub to take effect.
This also led us to the design for the rest of the dolt ci command, which needed to include other practical subcommands as depicted in the diagram below.
The Design for DoltHub#
Once we settled on making each Dolt database on DoltHub responsible for storing its own CI configuration, we needed a plan for how DoltHub would use the data from those tables to actually run CI tests. Fortunately, this part of the design was fairly straightforward since we could leverage DoltHub’s existing Jobs feature to support CI runs.
Jobs were added to DoltHub and DoltLab some time ago. They allow users to kick-off asynchronous, time and resource intensive work and monitor the work’s progress until it is completed.
Originally, Jobs provided relief to DoltHub’s resource starved API, which performed grueling read and write tasks by itself. Once we added DoltHub Jobs, though, we could move this intensive work out of the API process and onto separate hosts with dedicated resources.
As a result, DoltHub now uses Jobs to import large data files, merge large pull requests, and run large SQL queries on its databases. Our plan for DoltHub CI was in part to update Jobs to support the running of arbitrary CI tasks.
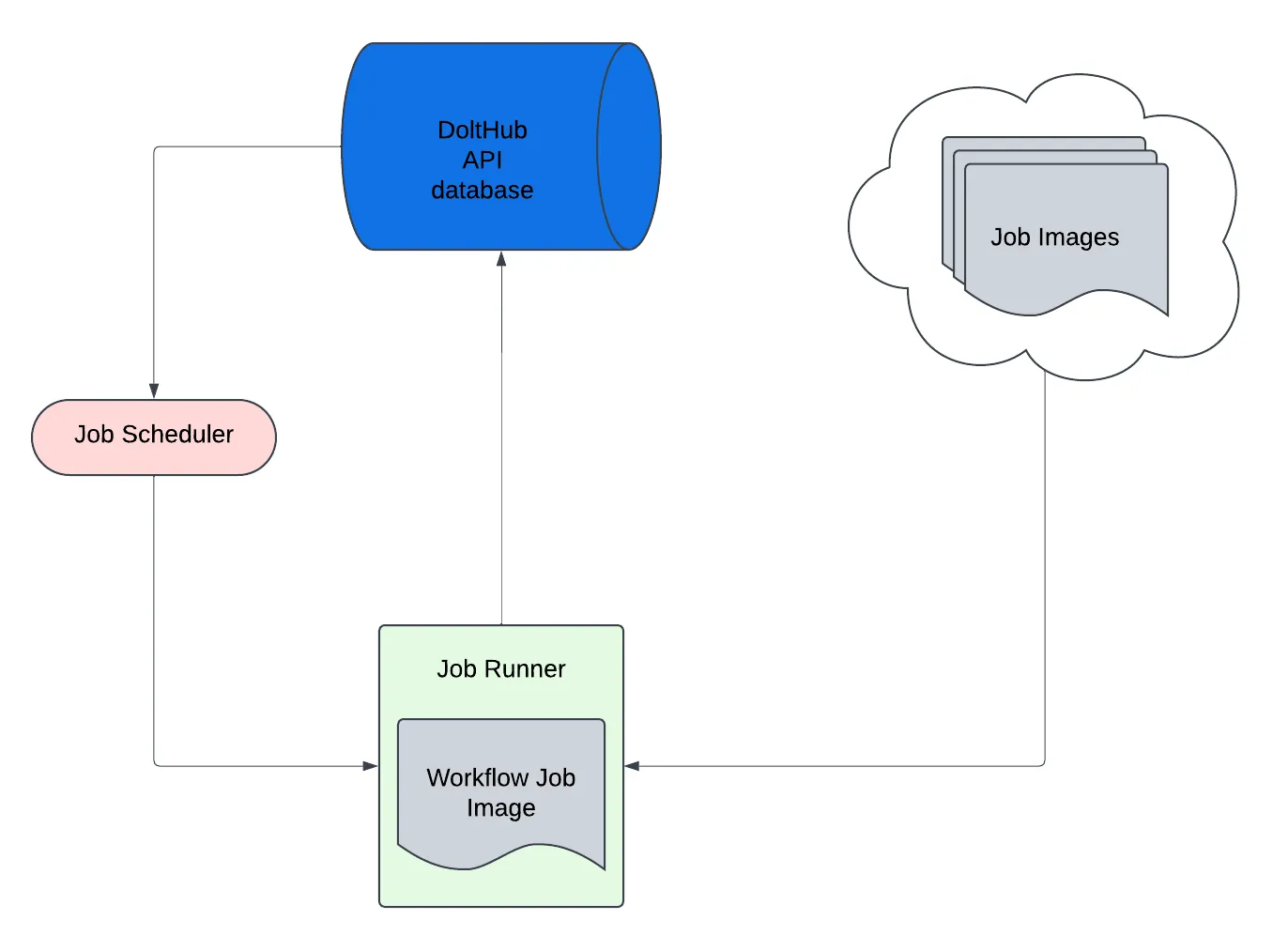
The diagram above depicts how DoltHub’s API models Jobs for performing out-of-band, resource intensive work. In simplified terms, whenever DoltHub needs to run a Job, it queues a “pending” Job for deployment. This is done by performing a write to DoltHub API’s application database. The database, the blue cylinder at the top of the image, manages the Job queue.
Next, DoltHub’s API runs an internal agent called the Job scheduler that checks the database for queued Jobs and deploys any it finds. The scheduler is represented by the pink oval. A Job is deployed to a Job runner or host, which is external to the DoltHub API process. The runner pulls the relevant Job image from DoltHub’s cloud image repository and runs it.
The diagram above shows multiple existing Job images in the cloud, which represent the various images used for different types of DoltHub Jobs. As mentioned before, these are file imports Jobs, pull request merges, and large SQL read queries.
As shown by the “Workflow Job Image” on the Job runner, our plan is to create a new Job image designed to perform CI tasks. This would allow us to simply leverage our existing Jobs infrastructure to add this important new feature.
But even with the plan to update Jobs in place, there was yet another part of DoltHub’s CI design to reason about—defining the life-cycle of a CI run.
Of course, as mentioned above, CI configuration would be stored in each Dolt database hosted on DoltHub, and the existence of configuration in a DoltHub database is the technical start of the DoltHub CI life-cycle. But what does the rest of the life-cycle look like?
To answer this question we came up with the following life-cycle model.
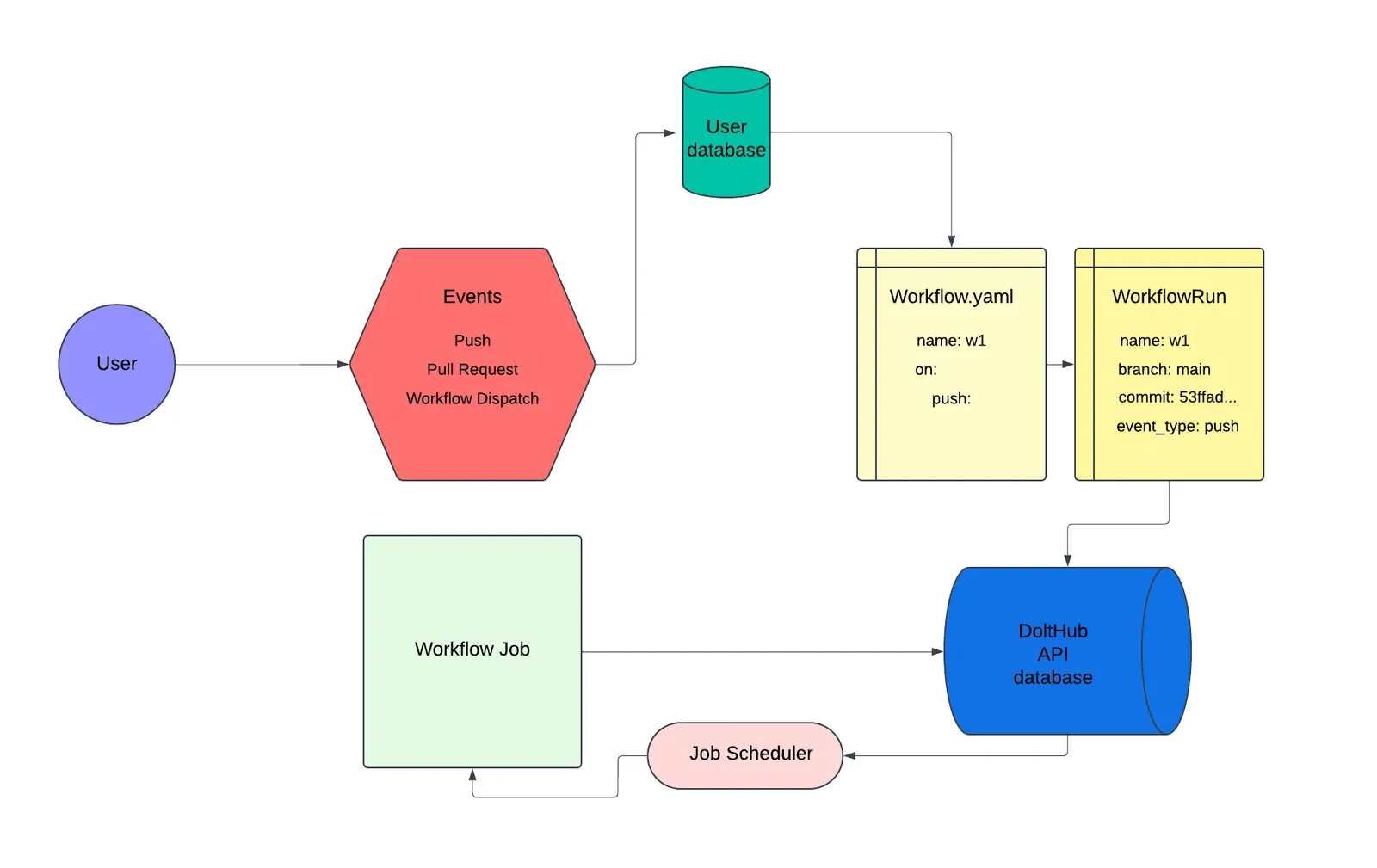
As shown in the diagram above, a CI run starts with a user. Here, the user is represented by the purple circle on the left side of the image. A DoltHub user who has added CI configuration to their database starts the CI lifecycle by performing some action on their database, called an “event”. These events are things like pushing changes, which is a push event, opening a pull request, a pull_request event, or manually creating an event with the click of a button, called a workflow_dispatch event.
Whenever one of these user-initiated events occurs on a DoltHub database, represented by the red hexagon in the diagram, DoltHub’s main API will read the CI tables of the user’s database to determine if a CI run should occur.
The arrow from the red hexagon to the user’s green Dolt database represents this process of reading the CI tables. Obviously, if the user’s database does not have CI tables, the life-cycle ends here, as there’s no work to be done.
But, if CI configuration is found, and should be run, represented by the yellow “Workflow.yaml” file in the image, DoltHub API creates and stores a point-in-time snapshot of the configuration. This snapshot is called a WorkflowRun.
This WorkflowRun is not a true one-to-one copy of the Dolt configuration, but it does store all important information and metadata needed to track the history and statuses of all CI Jobs executed on a DoltHub database. For example, the diagram shows the WorkflowRun, which represents the point-in-time snapshot of the “Workflow.yaml”, also stores the branch name and commit hash at the time the WorkflowRun was created.
The WorkflowRun is then written to DoltHub API’s application database, represented by the dark blue cylinder in the image. Simultaneously, when the WorkflowRun is persisted, a new Workflow Job is automatically queued for deployment.
The pink oval represents DoltHub’s internal Job scheduler, responsible for deploying queued Jobs. The scheduler deploys the corresponding Workflow Job for the WorkflowRun created in the previous step.
The Workflow Job is then deployed to a separate host where it performs all the CI tests against the target database. When the Job finishes, it updates the WorkflowRun in DoltHub API’s database with the results.
It is at this point that the life-cycle of a CI run is over, and the WorkflowRun is the only artifact DoltHub retains.
Conclusion#
Using the design plan for both Dolt and DoltHub that I’ve laid out above, we were able to bring the alpha version of CI on databases to life. Stay tuned in the coming weeks for more improvements and features, as we want all of our users to feel confident running CI on their database as soon as possible.
If you’d like to discuss any particular use-cases you have for CI on your Dolt databases, or want to request a feature or two, we’d love to hear from you, so swing by our Discord.
Thanks for reading and don’t forget to check out each of our cool products below:
- Dolt—it’s Git for data.
- Doltgres—it’s Dolt + PostgreSQL.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.
- Dolt Workbench—it’s a SQL workbench for Dolt databases.