
Relational databases are an organizational step change improvement over flat files like Excel or JSON. Strict typing improves data quality and maintainability over time. Schema mutations, data versioning, lineage are tracked. And you get all of the tooling and accessibility benefits from 50 years of relational database development.
Data transformations and the various ETL shapes are the next concern after the 0-to-1 of data collection. Flat files can be copied and rewritten in different forms. But we usually want cleaning stages to have more a meaningful organization than a sequence of folders with dates and version numbers.
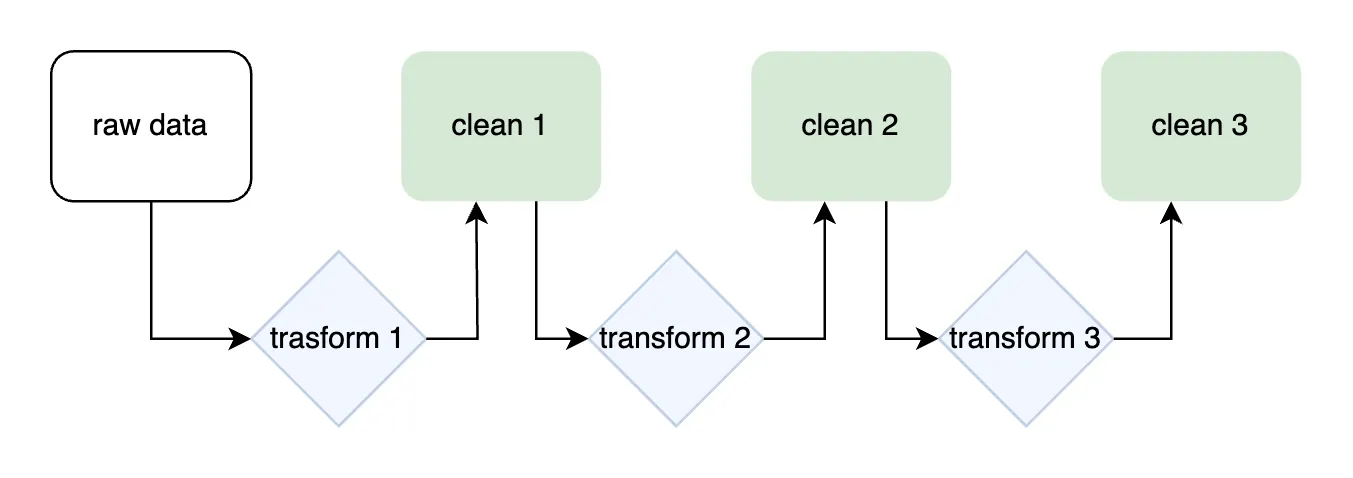
DBT (data build tool) is a common wrapper for organizing data pipelines as SQL transformations. In DBT, SQL views in Git are the source of truth for a web of transformations generating a catalog of tables/columns. A distinct execution runtime is responsible for compiling and executing the ETL pipeline.
Versioned ETL is also easy to do inside of a database. We will discuss how to do all of this in a Dolt DB.
Background#
We will look at multiple ways to build ETL pipelines represented by views. Our inputs are source tables, and our outputs are synthesized columns.
The main levers to consider are :
-
What data should be colocated for speed?
-
When do we execute transformations?
-
How do we version changes?
We will look at the data considerations first.
View Organization#
Here is the base schema:
create table rawdata (
id int primary key,
name varchar(10),
metadata varchar(10),
statistical enum('yes','no','uncertain'),
robustness enum('yes','no','uncertain')
)The robustness column will have “historical” and “cleaned” versions for every row in the table.
In either storage case, the fastest way to provide application level flexibility are views that defer execution until access time:
create view data as
select id, name, metadata,
CASE
WHEN statistical = 'yes' THEN robustness
ELSE NULL
END as robustness
from rawdata;Dolt does not materialize views by default, and so queries using the data view above are resistant to column pruning and join planning. This breaks index filtering and join planning, which for application databases is a deal breaker.
data-cleaning/default-view*> explain select * from data d1 join data d2 on d1.id = d2.id;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| plan |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Project |
| ├─ columns: [d1.id, d1.name, d1.metadata, d1.robustness, d2.id, d2.name, d2.metadata, d2.robustness] |
| └─ InnerJoin |
| ├─ (d1.id = d2.id) |
| ├─ SubqueryAlias |
| │ ├─ name: d2 |
| │ ├─ outerVisibility: false |
| │ ├─ isLateral: false |
| │ ├─ cacheable: true |
| │ └─ Project |
| │ ├─ columns: [rawdata.id, rawdata.name, rawdata.metadata, CASE WHEN (rawdata.statistical = 'yes') THEN rawdata.robustness ELSE NULL END as robustness] |
| │ └─ Table |
| │ ├─ name: rawdata |
| │ └─ columns: [id name metadata statistical robustness] |
| └─ SubqueryAlias |
| ├─ name: d1 |
| ├─ outerVisibility: false |
| ├─ isLateral: false |
| ├─ cacheable: true |
| └─ Project |
| ├─ columns: [rawdata.id, rawdata.name, rawdata.metadata, CASE WHEN (rawdata.statistical = 'yes') THEN rawdata.robustness ELSE NULL END as robustness] |
| └─ Table |
| ├─ name: rawdata |
| └─ columns: [id name metadata statistical robustness] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+It is possible to fully materialize this view ahead of time with a couple lines of SQL:
CREATE TABLE data
SELECT
id, name, metadata,
CASE
WHEN statistical = 'yes' THEN robustness
ELSE NULL
END as robustness
from rawdata;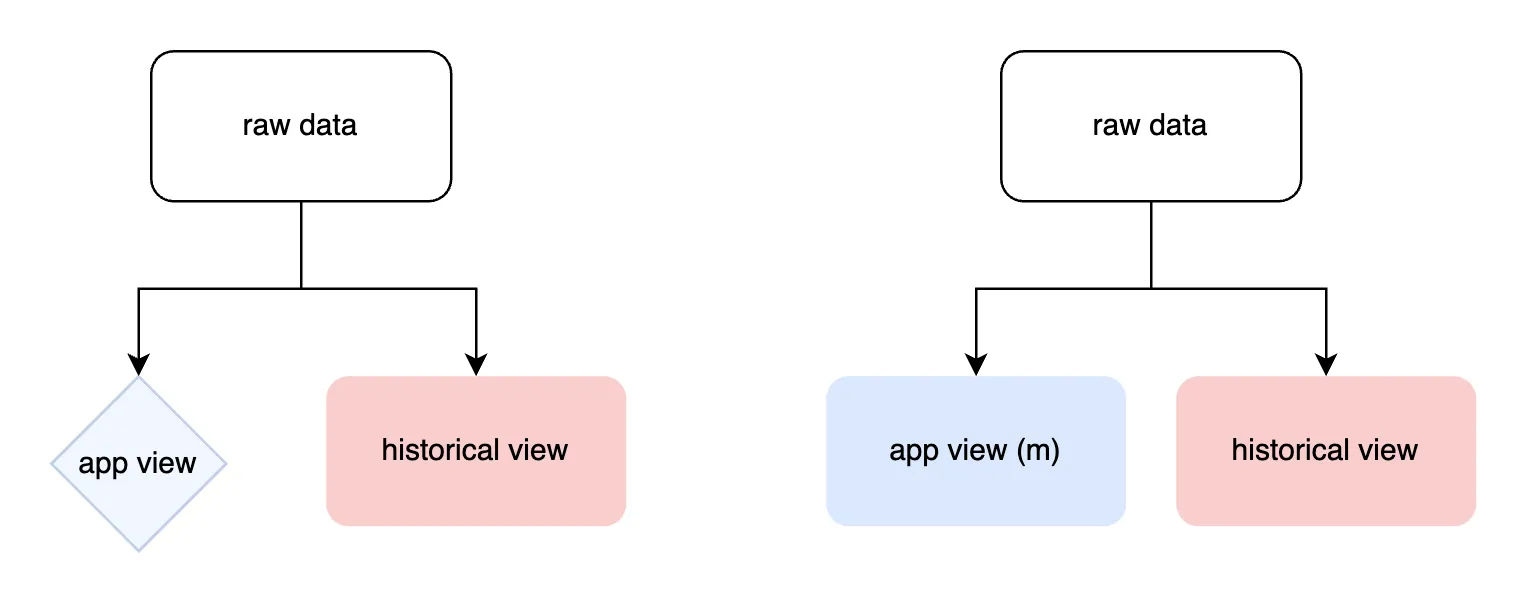
Which is now subject to join planning:
data-cleaning/materialized-view*> explain select * from data d1 join data d2 on d1.id = d2.id;
+--------------------------------------------------------+
| plan |
+--------------------------------------------------------+
| HashJoin |
| ├─ (d1.id = d2.id) |
| ├─ TableAlias(d1) |
| │ └─ Table |
| │ ├─ name: data |
| │ └─ columns: [id name metadata robustness] |
| └─ HashLookup |
| ├─ left-key: (d1.id) |
| ├─ right-key: (d2.id) |
| └─ TableAlias(d2) |
| └─ Table |
| ├─ name: data |
| └─ columns: [id name metadata robustness] |
+--------------------------------------------------------+Lastly, we would often add triggers to keep new inserts up-to-date (we can do the same thing for UPDATE and DELETE edits):
CREATE TRIGGER copy_raw
BEFORE INSERT ON rawdata
FOR EACH ROW
INSERT INTO data values (
id,
name,
metadata,
CASE
WHEN statistical = 'yes' THEN robustness1
ELSE NULL
END
);Every insert performs two writes: to rawdata and data. This can be extended for multiple computed values or a sequence of transformations as tables.
But there are also interesting ways to achieve the same result with less write amplification.
Virtual columns#
We can use virtual columns to store sanitized values in the same table as the raw data. One way to do this is to duplicate a column that we are going to sanitize:
Create table rawdata (
id int primary key,
name varchar(10),
metadata varchar(10),
statistical enum('yes','no','uncertain'),
robustness1 enum('yes','no','uncertain'),
robustness2 enum('yes','no','uncertain') as (
CASE
WHEN statistical = 'yes' THEN robustness1
ELSE NULL
END
) VIRTUAL
);
The robustness1 and robustness2 columns are colocated. We can decide whether to materialize or defer robustness2 generation by toggling the VIRTUAL/STORED qualifier.
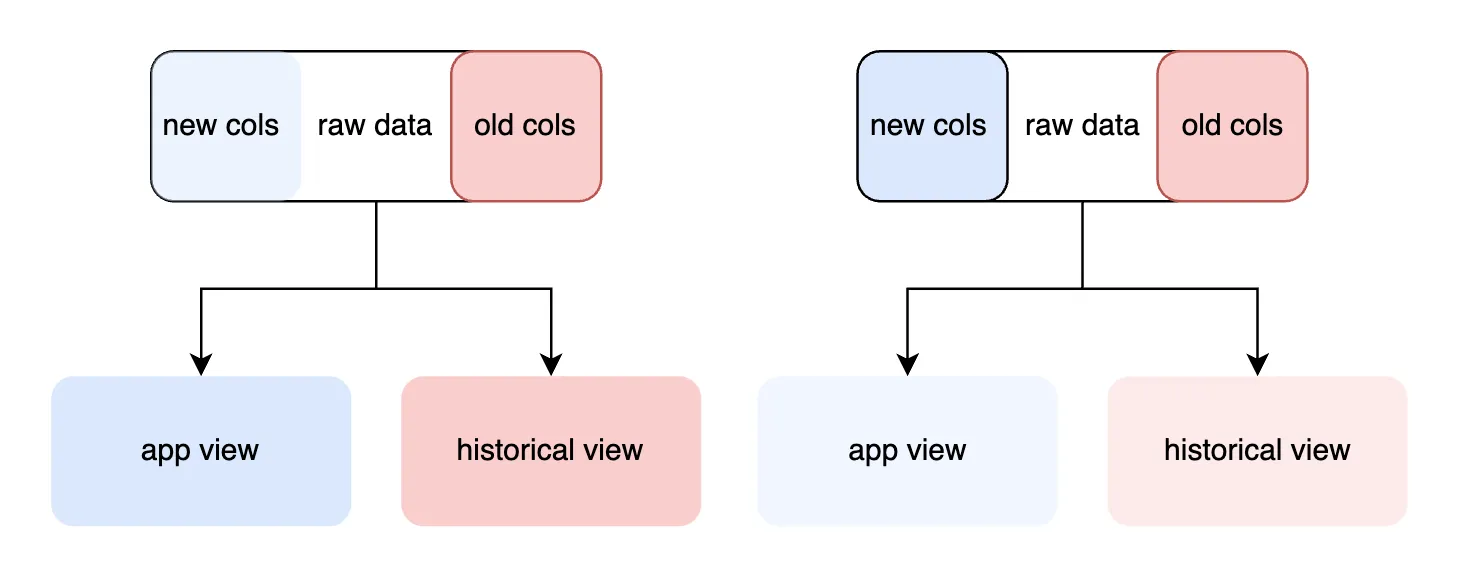
The view below hides the robustness1/2 duplication from the application code:
create view data_read as
select
id,
name,
metadata,
statistical,
robustness2 as robustness
from rawdata;This strategy reduces write duplication (amplification). We can choose between materializing or deferring synthesized column production until runtime.
The main trade-off is that our one table’s schema quickly becomes complex.
Separate The New#
We can place sanitized columns in a new table separate from the original data:
create table data_nullable_read (
id int primary key,
robustness enum('yes','no','uncertain'),
statistical enum('yes','no','uncertain')
);
When rows are inserted into the main table, we can have a trigger sequence (1) populate the new table and (2) mutate the rows inserted into the new table:
CREATE TRIGGER copy_raw
BEFORE INSERT ON rawdata
FOR EACH ROW
INSERT INTO data_nullable_read values (id, robustness, statistical);
DELIMITER //
CREATE TRIGGER santize_raw
BEFORE INSERT ON data_nullable_read
FOR EACH ROW
BEGIN
IF statistical <> 'yes' THEN
SET NEW.robustness = NULL;
END IF;
END//
DELIMITER ;(We could also combine the two into a single more complicated trigger. The separation makes it easier to add piecewise logic.)
Because data is now partitioned between two tables, the view we expose to our application now performs a join:
CREATE VIEW data as
SELECT rawdata.id, rawdata.name, rawdata.metadata, data_nullable_read.robustness
FROM rawdata
JOIN data_nullable_read
ON rawdata.id = data_nullable_read.id;Separate The Old#
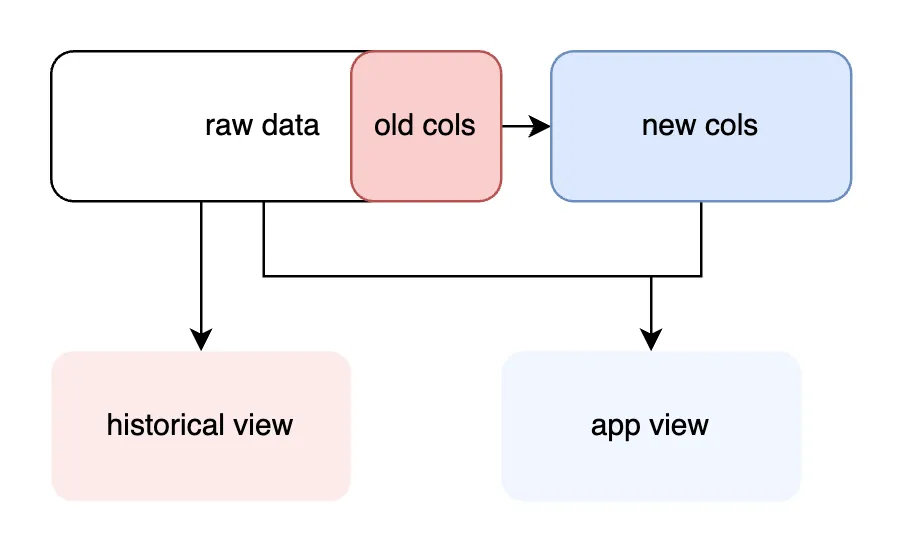
If we frequently read the sanitized values and rarely read historical data, separating the new values might not be the right performance tradeoff. Instead we can place the old values in a new table, preserving historical access but optimizing for more common application reads:
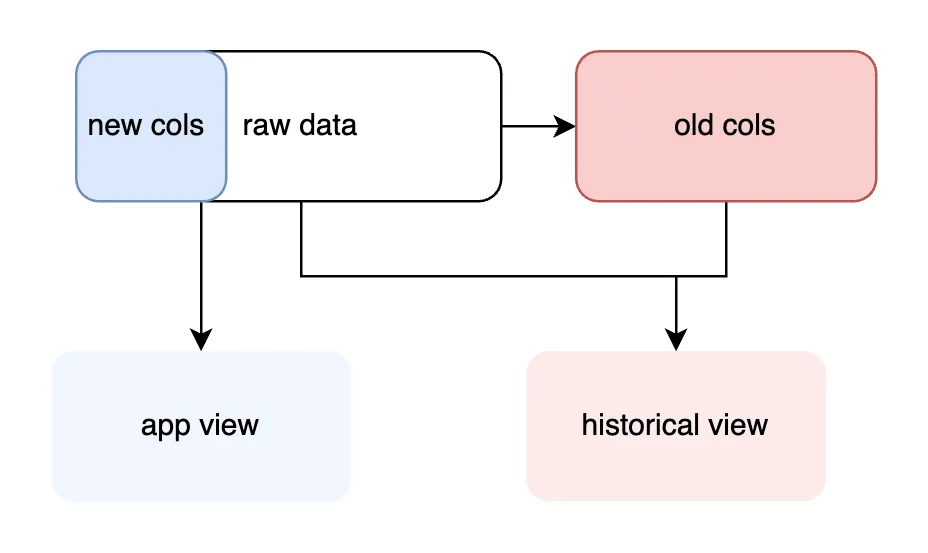
The triggers below (1) copy the old data and then (2) sanitize the columns going into our primary table:
CREATE TRIGGER copy_raw
BEFORE INSERT ON rawdata
FOR EACH ROW
INSERT INTO data_nullable_raw values (new.id, robustness);
DELIMITER //
CREATE TRIGGER santize_raw
BEFORE INSERT ON rawdata
FOR EACH ROW FOLLOWS copy_raw
BEGIN
IF statistical <> 'yes' THEN
SET NEW.robustness = NULL;
END IF;
END//
DELIMITER;The result is that we can read directly from the base table from our application, and only use a slower view join for accessing historical data:
CREATE VIEW data as
SELECT rawdata.id, rawdata.name, rawdata.metadata, data_nullable_raw.robustness
FROM rawdata
JOIN data_nullable_raw
ON rawdata.id = data_nullable_raw.id;The two options that segment raw and sanitized columns avoid storage duplication, and in the second case do so with the same performance as a materialized view.
Versioning#
Regardless of how we decide to run and store data, process versioning is a key feature of modern analytics workflows.
DBT versions transform queries as source code in Git. The static DAG in source code is then translated into execution machinery on a cluster.
Dolt versions pipeline operators inside the database the same way
Git tracks code. Below is the diff of the first
transform we looked at above. The diff describes 1) adding a materialized view data, 2) seeding
it from rawdata, and 3) adding triggers so that data continues to
track rawdata moving forward:
~/D/d/d/tmp> dolt diff
diff --dolt a/data b/data
added table
+CREATE TABLE `data` (
+ `id` int NOT NULL,
+ `name` varchar(10),
+ `metadata` varchar(10),
+ `robustness` enum('yes','no','uncertain')
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
+---+----+------+----------+------------+
| | id | name | metadata | robustness |
+---+----+------+----------+------------+
| + | 1 | name | meta | no |
+---+----+------+----------+------------+
+CREATE TRIGGER copy_raw
+BEFORE INSERT ON rawdata
+FOR EACH ROW
+INSERT INTO data values (
+ id,
+ name,
+ metadata,
+ CASE
+ WHEN statistical = 'yes' THEN robustness
+ ELSE NULL
+ END
+);The code and data source of truth are the same. There are no default intermediate steps between defining and executing transforms.
Zooming out a level, individual diffs are commits managed via
branch pointers. Features branches orbit a
main branch whose relationships are tracked in a commit graph. As with GitHub, PR workflows on DoltHub
allows branches to be tested, reviewed, and edited before merging back
into the main branch.
We add more separation by adding more steps. One option is
to separate a dev branch from main.
The two share a commit graph and schema, but dev has less data. The
smaller dev database is quicker to rewrite, run ALTER experiments on,
and make mistakes without rewriting all of main. But they are really the
same logical database and share an underlying commit graph. The shared
ancestry lets us directly forward schema patches from dev->main.
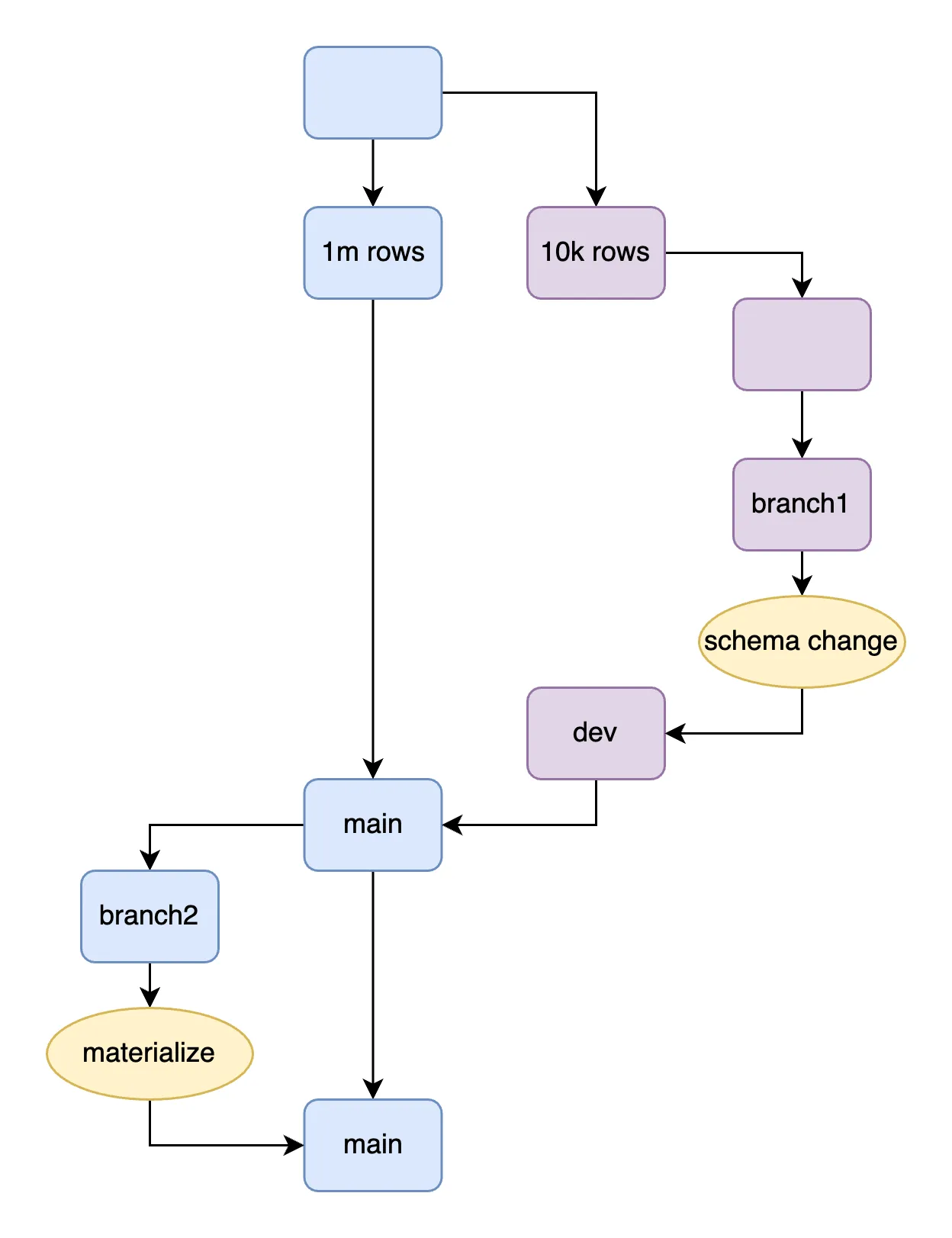
We forward schema patches with the
dolt_schema_diff()
function (equivalent to
dolt_patch(--schema)).
Porting new tables back to main is slightly more difficult because we
manually materialized data with a SELECT statement that is
not schema resident:
CREATE TABLE data SELECT <columns>. One
thing we could do is 1) document the statement in a view CREATE data_def as SELECT <columns>, which will seamlessly schema-merge:
> dolt diff --schema
+CREATE VIEW data_def as SELECT
+id, name, metadata,
+ CASE
+ WHEN statistical = 'yes' THEN robustness
+ ELSE NULL
+ END as robustness
+ FROM rawdata;and then 2) automate a second feature branch that boilerplate materializes
the statement CREATE TABLE data SELECT * from data_def off main’s
data. We would use something like the query below to identify
discrepancies between on the main branch:
SELECT table_schema, table_name
FROM information_schema.tables views
WHERE
views.table_type like 'view' and
NOT EXISTS (
SELECT 1 from information_schema.tables
WHERE
table_name = SUBSTRING(views.table_name, 1, length(views.table_name)-length('_def')) and
table_schema = views. table_schema and
table_type like 'base table'
);
+--------------+------------+
| TABLE_SCHEMA | TABLE_NAME |
+--------------+------------+
| tmp | data_def |
+--------------+------------+Soon DoltHub will have CI hooks, which would let a merge hook script
true-up the desired materialized view state on a new PR branch into main.
Summary#
We’ve looked at SQL primitives that let us version and run ETL pipeline like DBT: views, synthetic columns, versioning schema changes, patching schema changes between databases. There is a lot of flexibility! As with any organizational process, the key is picking the right set of tradeoffs to support the changeset size and workflow shape. The same is true for using tools like DBT! Either way it is always helpful to understand how things work under the hood.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!