
When you are using Dolt, you’ll come across a lot of 32 character random strings like k0j5gejn5ebnoqa3jr4pdkb6etbbrfri. For instance, each entry in your Dolt log has one.
$ dolt log -n 3
commit o9vdhp8fj78nhoa2ul9fm5s7nkks5ovv (HEAD -> main)
Author: timsehn <tim@dolthub.com>
Date: Mon Nov 04 12:13:32 -0800 2024
6,361,700 pages imported
commit aa25mg0hju30rnrvddjk9irguhnkpsbc
Author: timsehn <tim@dolthub.com>
Date: Fri Nov 01 09:33:33 -0700 2024
6,247,100 pages imported
commit 8115ehta5kovgqvvnhp1mmkr5uu67vsr
Author: timsehn <tim@dolthub.com>
Date: Thu Oct 31 09:57:15 -0700 2024
6,210,500 pages imported
These strings are hashes. These hashes are computed using different algorithms on certain objects in your Dolt database. What do these hashes mean? How are they generated? How can I access and use them? This article will explain.
Content Addresses#
These hashes are content addresses of various objects in your database. A content address is an immutable value that is computed based on the content to which it refers. The same content should generate the same content address regardless of how that content was generated.
Dolt is the only content addressed SQL database. This is a minor feat of engineering. Dolt uses specific algorithms to generate immutable content addresses for most internal objects in your database. The content addresses of multiple objects are hashed together to form a tree of content addresses. The content addresses you see in the dolt log are the root of tree.
Structuring a database this way is what enables the version control features of Dolt. Specifically, a database structured this way can share objects that have the same content address across versions, called structural sharing. Version control systems become unwieldy in storage if they cannot share storage across versions. Also, a database with a tree of content addresses can be compared to other versions of the same database quickly. If the root content address is the same, the database is the same. If not, go to the next level of the tree and compare the content addresses. Fast diff as this is called enables merge functionality, another core feature of version control.
All the way down…#
Let’s start at the bottom, at an individual table, and work our way up to the top, a Dolt commit.
Table data is broken down into a novel data structure called a Prolly Tree. We here at Dolt did not invent the Prolly Tree, the good folks who built Noms did, but we did productionize Prolly Trees. Dolt is the only database built on Prolly Trees. All Prolly Tree nodes have content addresses. The root of the Prolly Tree also gets a content address by hashing the internal nodes. Thus, all table data is content addressed by the Prolly Tree data structure.
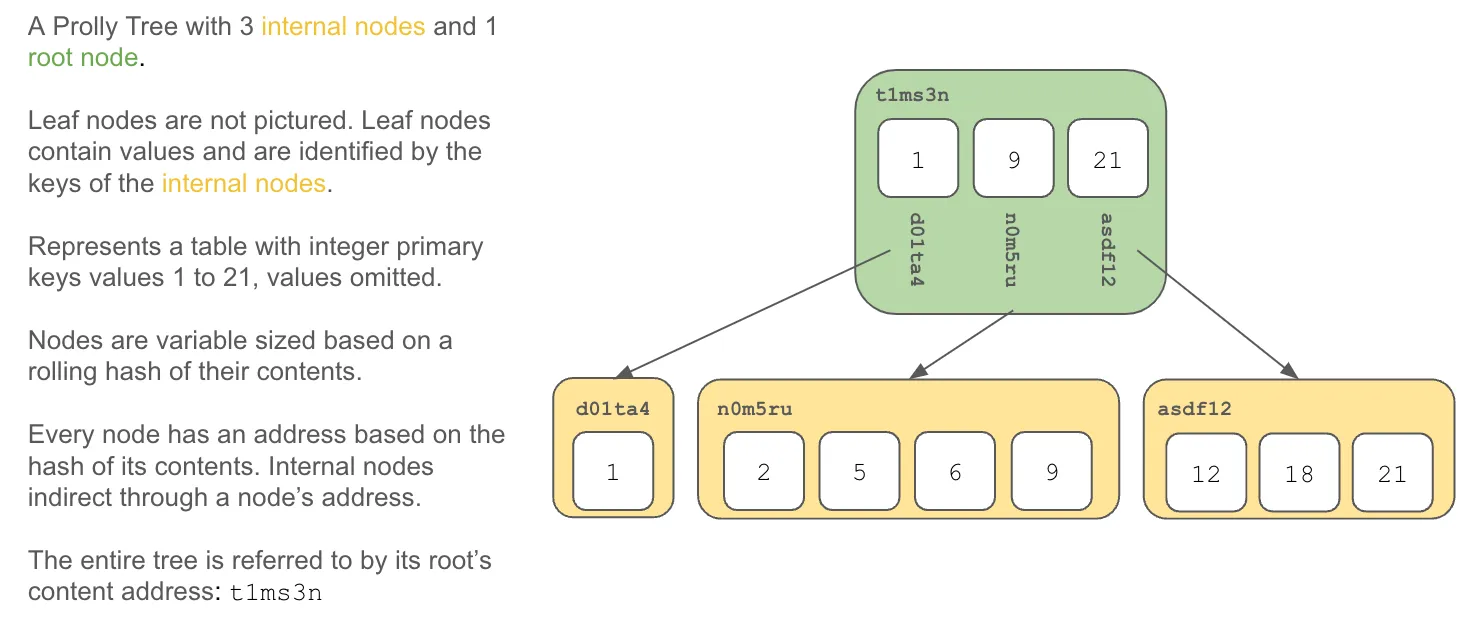
Table schema also is stored in a much simpler Prolly Tree. This also gets a content address. Hash the content addresses of these two trees and you get a content address for the table.
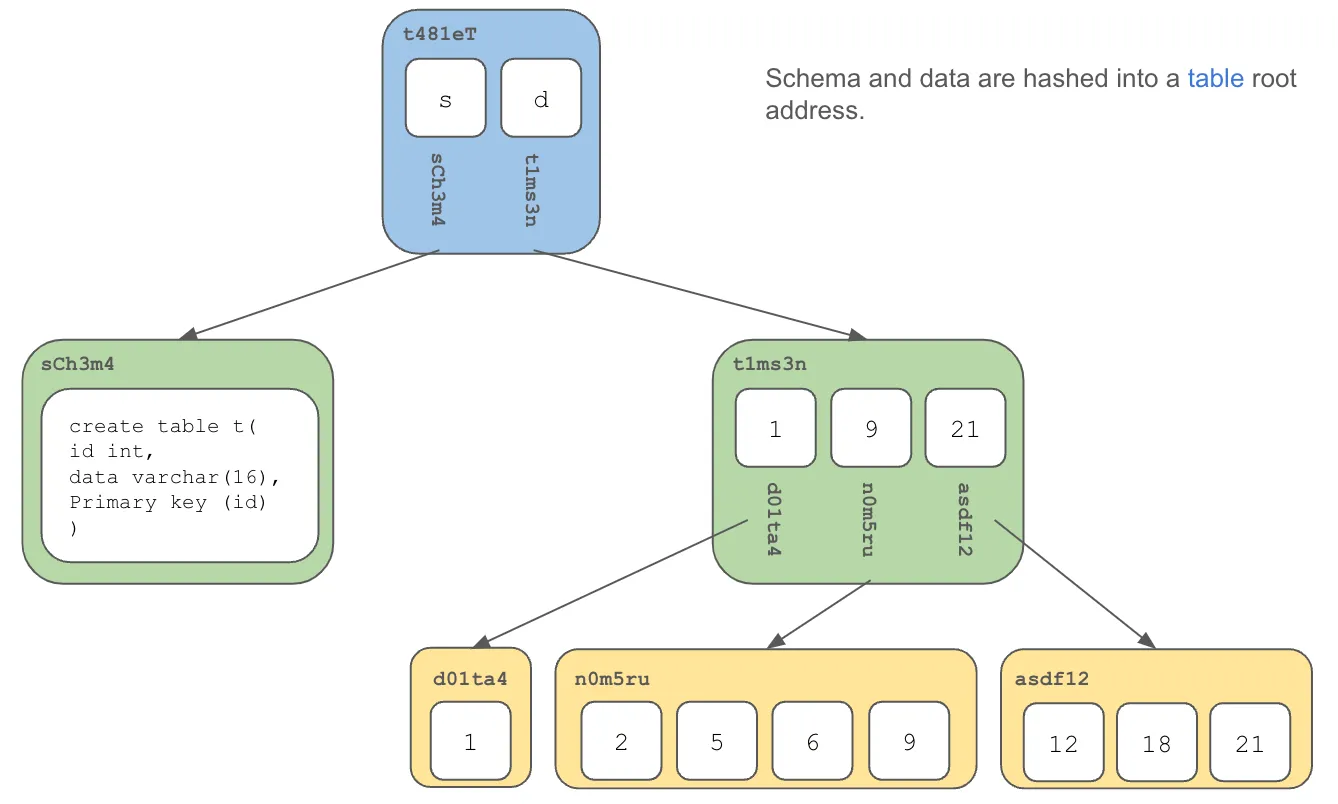
Table content addresses are hashed together and you get a content address for the database. We call this the “database root”.
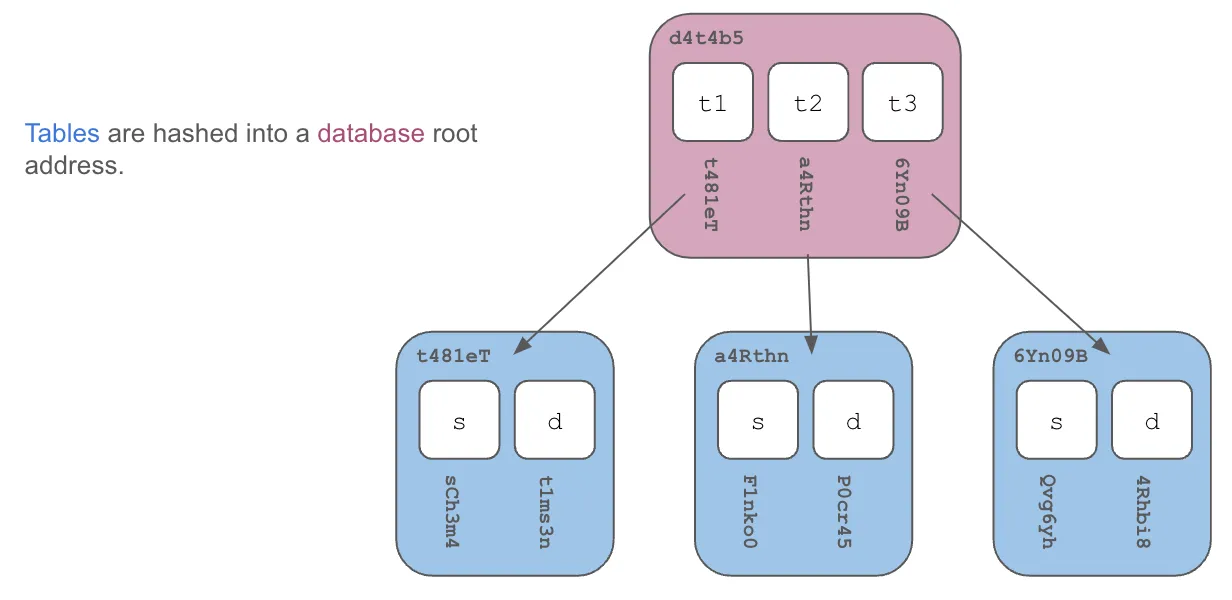
Some Dolt objects not pictured which are also included in the database root content address are views, procedures, events, the dolt ignore table, and saved queries.
Anything that should not be versioned exists outside the database root content address. Some objects notably absent from the root content address are anything to do with permissions: branch permissions and users/grants. Also, most configuration related values like persisted system variables are absent from the root content address.
When you make a Dolt commit, commit metadata is hashed with the content address of the database, meaning the same database committed at two different times will have different commit hashes, even though the diff is empty.

In this way, you can see that Dolt is content addressed all the way down.
Accessing Content Addresses#
Though considered “internal details”, it is sometimes useful to access content addresses for certain use cases. The dolt_log system table is akin to the dolt log or git log commands, providing the history of content addresses going back to the inception of your database, but in tabular form. Dolt also provides three SQL functions that return content address information.
dolt_log#
The dolt_log system table walks the commit graph from your current branch head in topologically sorted order back to the initial commit in your database and displays the commit information in tabular form. The commit_hash field is the content address of the commit and can be used to access other information about that point in history.
dolt_hashof()#
dolt_hashof() returns the content address of a named reference. A named reference is a branch or tag name, like main or feature, or special names like HEAD, WORKING, or STAGED. This is more of a convenience function for say, filtering the dolt_log system table. It does not give you access to any internal content addresses.
dolt_hashof_db()#
dolt_hashof_db() returns the hash of a database root, ignoring commit metadata. This can be used to make sure database versions are the same on two different clones without having to pull either version locally to run dolt_diff(). This is often used in the decentralized Dolt use case where writers are building a database on different geographically distributed machines.
dolt_hashof_table()#
dolt_hashof_table() returns the hash of a table. This can be used as a cache key. If the hash of a table has changed, you can trigger a cache rebuild.
Example#
To show off these internal hashes I created a simple single table database on DoltHub. For this example I will clone it to two different locations on my laptop, make the same modifications but in a different order and show you how the internal content addresses change. In the end, we will have the same table and database content addresses but a different commit content address.
First, I will create a directory tree to house my example.
$ mkdir hashes
$ cd hashes
$ mkdir clone1
$ mkdir clone2
$ ls
clone1 clone2Now I clone the hashes database to both the clone1 and clone2 directories.
$ cd clone1
$ dolt clone timsehn/hashes
cloning https://doltremoteapi.dolthub.com/timsehn/hashes
$ cd ../clone2/
$ dolt clone timsehn/hashes
cloning https://doltremoteapi.dolthub.com/timsehn/hashesNow, on clone1, I will insert a row identified by key 1 and 2 in that order showing the table and database hash after each insert.
$ cd ../clone1/hashes
$ dolt sql -q "insert into t values (1, 'Inserted row 1')"
Query OK, 1 row affected (0.01 sec)
$ dolt sql -q "select dolt_hashof_table('t')"
+----------------------------------+
| dolt_hashof_table('t') |
+----------------------------------+
| 72d6iki03nt6qqrih9fd37hhfs0juill |
+----------------------------------+
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| 0h2rmjt56gm3lh2l2ce8njd6overknfn |
+----------------------------------+
$ dolt sql -q "insert into t values (2, 'Inserted row 2')"
Query OK, 1 row affected (0.01 sec)
$ dolt sql -q "select dolt_hashof_table('t')"
+----------------------------------+
| dolt_hashof_table('t') |
+----------------------------------+
| 5dapu4felj75a3dga9f83quv42ck16pc |
+----------------------------------+
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| 6r90bdujrt4jeghbg9s533mhkpnbhelr |
+----------------------------------+Now in clone 2, I’ll insert in the reverse order expecting the final table and database content addresses to be the same.
$ cd ../../clone2/hashes
$ dolt sql -q "insert into t values (2, 'Inserted row 2')"
Query OK, 1 row affected (0.01 sec)
$ dolt sql -q "select dolt_hashof_table('t')"
+----------------------------------+
| dolt_hashof_table('t') |
+----------------------------------+
| sklapeh9i108sh8o265gq8g0t6uapk3t |
+----------------------------------+
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| mn339kldhmkp5jh97d7siogv27sa8812 |
+----------------------------------+
$ dolt sql -q "insert into t values (1, 'Inserted row 1')"
Query OK, 1 row affected (0.00 sec)
$ dolt sql -q "select dolt_hashof_table('t')"
+----------------------------------+
| dolt_hashof_table('t') |
+----------------------------------+
| 5dapu4felj75a3dga9f83quv42ck16pc |
+----------------------------------+
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| 6r90bdujrt4jeghbg9s533mhkpnbhelr |
+----------------------------------+And voila! The intermediate content addresses of the table and database are different, reflecting different content, but the final content addresses are the same because the table and database are the same.
Now, if we make a Dolt commit for each database, we will get a different commit hash because the metadata will be different but the database content address will be the same.
$ cd ../../clone1/hashes
$ dolt commit -am "Committed to clone1"
commit puh4121qm5bmuohratit01qlmnrva5ft (HEAD -> main)
Author: timsehn <tim@dolthub.com>
Date: Tue Nov 05 13:13:03 -0800 2024
Committed to clone1
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| 6r90bdujrt4jeghbg9s533mhkpnbhelr |
+----------------------------------+
$ cd ../../clone2/hashes
$ dolt commit -am "Committed to clone2"
commit 2b2o96897rpr4pjqi1pbo7pnbp7ue2pt (HEAD -> main)
Author: timsehn <tim@dolthub.com>
Date: Tue Nov 05 13:13:26 -0800 2024
Committed to clone2
$ dolt sql -q "select dolt_hashof_db()"
+----------------------------------+
| dolt_hashof_db() |
+----------------------------------+
| 6r90bdujrt4jeghbg9s533mhkpnbhelr |
+----------------------------------+
Use Cases#
In normal operation of Dolt, internal content addresses are best ignored. However, we’ve run into a couple use cases where accessing these internal content addresses can be helpful.
Decentralized#
Some users adopt Dolt as a storage layer for a decentralized use case like a blockchain. In the blockchain case, users do not want a full clone locally of another user’s database, they just want to know whether they have the same database as another user. We received many requests from this community for the dolt_hashof_db() function before we finally implemented it.
Caching#
The dolt_hashof_table() function was initially implemented to support our Endless Sky demo, showing how Dolt could be used to house video game configuration. In this use case, the game has to hot reload and cache configuration from Dolt whenever it changes. The dolt_hashof_table() function is used as a cache key. If the result has changed, it signals to the game to reload and cache the new configuration.
Conclusion#
So, now you know what all those random 32 character strings in Dolt are, how they’re built, and how to use them if you need them. Any other questions about Dolt internals we can answer? Come by our Discord and ask. We may just feature the answer in our next blog article.