
A couple weeks ago, I discussed how Amazon was migrated to Git, and I mentioned the Brazil build system briefly. Brazil is a specialized version control system, which, in the past, was built on top of a SQL database.
Today I’ll talk a little bit more about Brazil, and delve a bit into the awkward requirements which pop out when you build a version control system on top of flat tables.
What Brazil Does#
Brazil is a multi-repository build system. Developers tend to get worked up about such things, and I argue that multi-repo is better; but it requires a lot of infrastructure to make it work.
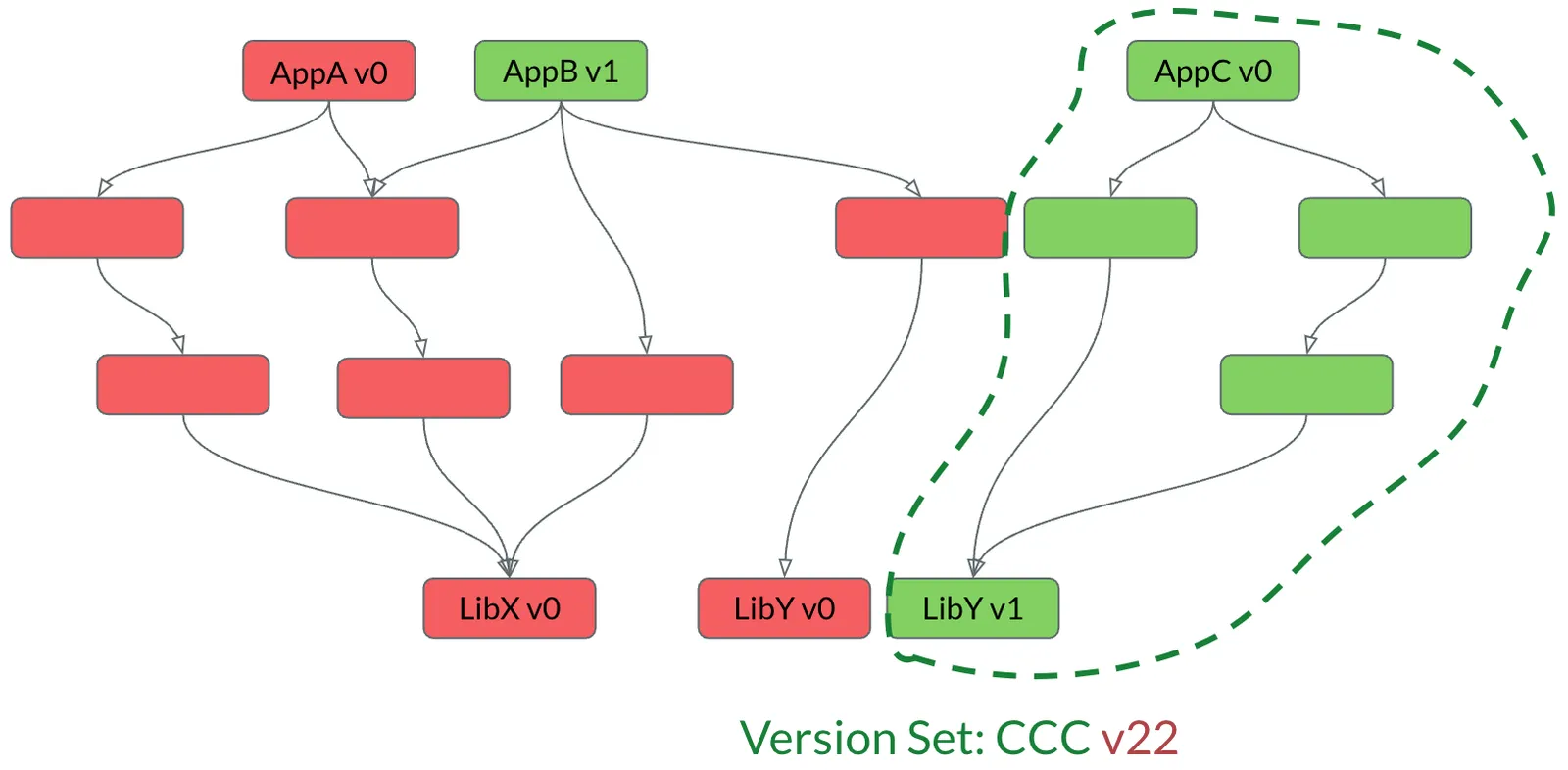
Amazon’s infrastructure to manage this problem was Brazil, which worked by tracking sets of packages to be grouped together as “Version Sets.” Each package can depend on others, and cycles in the dependency tree are forbidden.
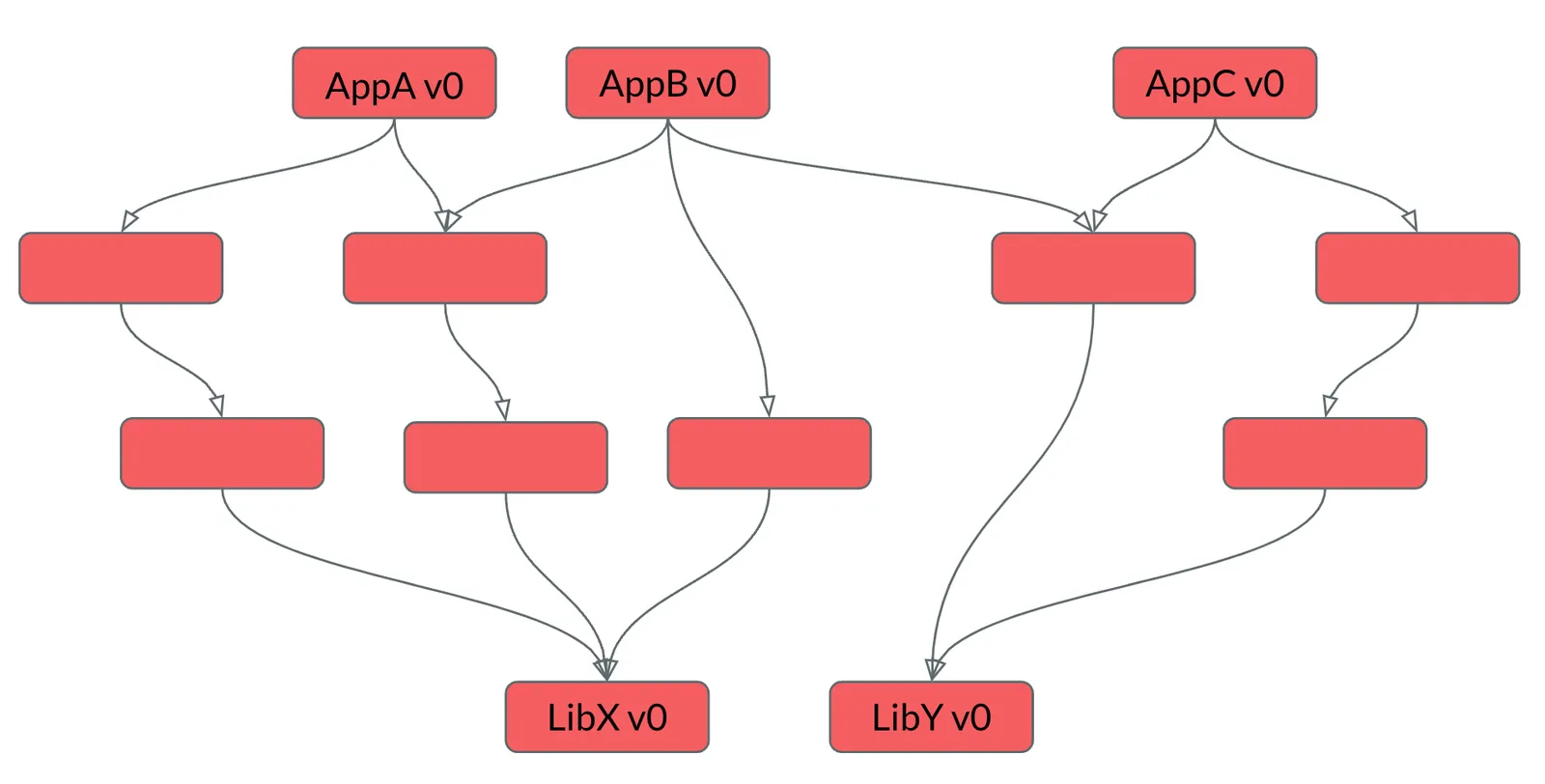
Each box in the picture is a built package. Packages at the top (leaves) depend on the packages below them. The packages without names we’ll ignore, but you can see that transitive dependencies are possible. The version identifiers here (v0) refer to the source branch and revision id. There are three Version Sets here, corresponding to the three unique application packages. BBB will be the Version Set containing the AppB package.
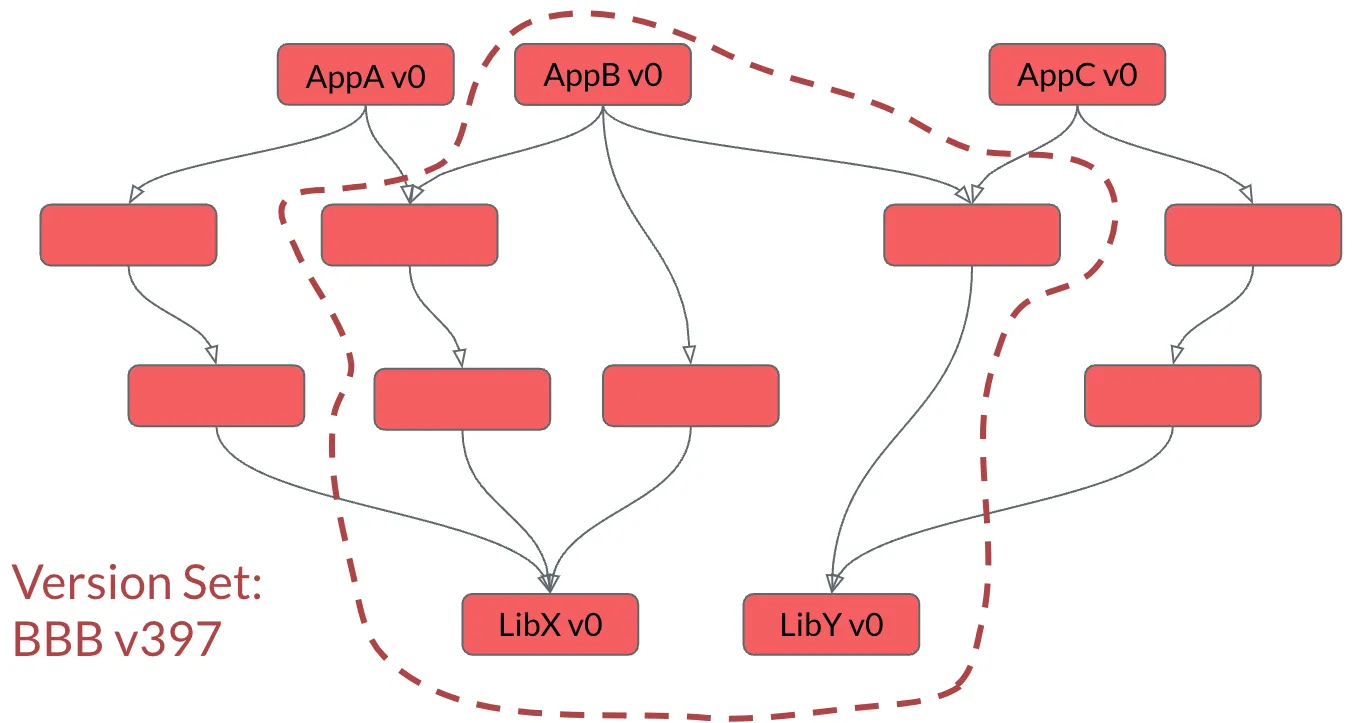
When a change is added to AppB, it stands to reason that only one package needs to be rebuilt. This is because no cycles are allowed in the dependency tree.
The important take away is that the leaf node update results in a new revision of the Version Set.
If a package lower in the dependency graph is updated, this requires the packages which depend on it to be rebuilt. The CCC Version Set contains all the packages that AppC depends on.
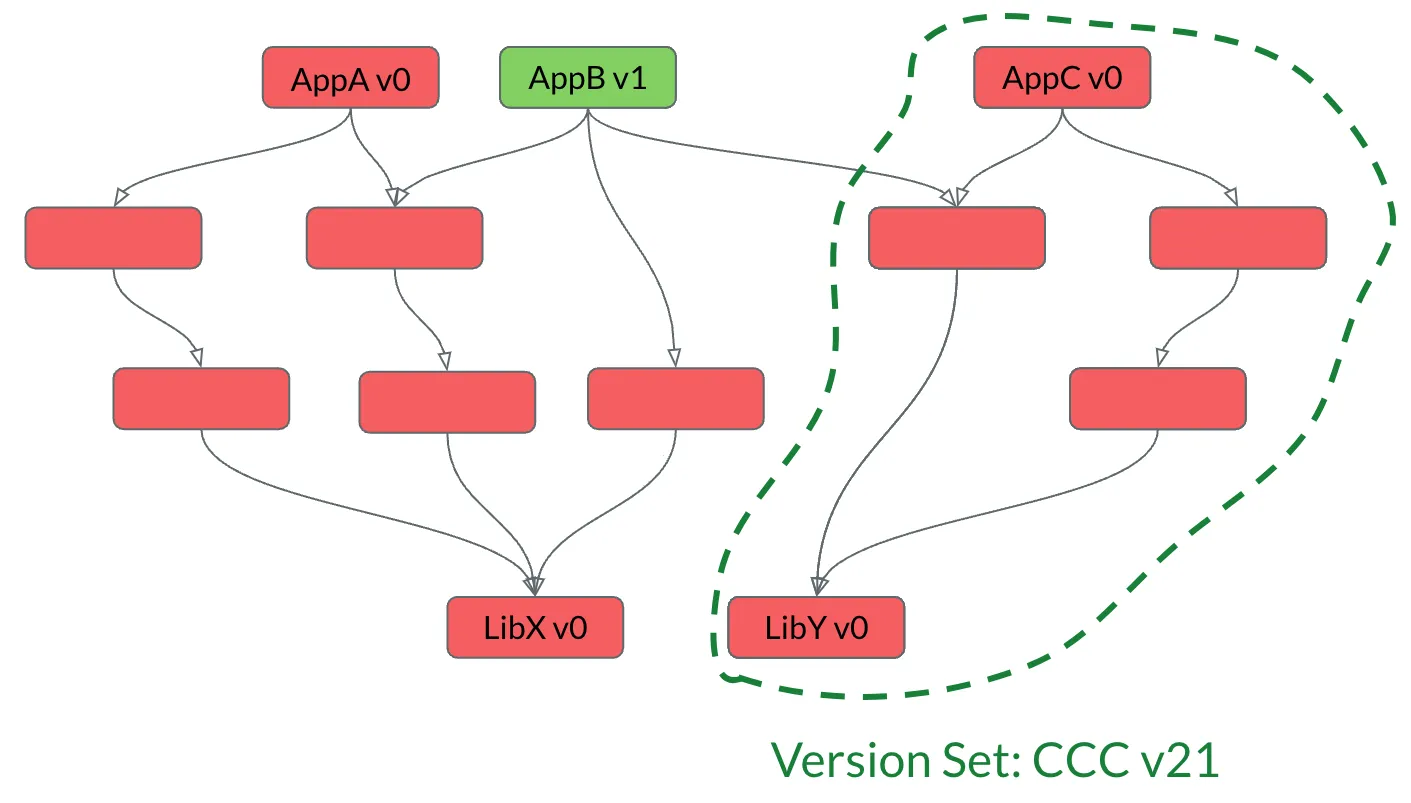
When a lower level package is updated, then all packages which depend on it must be rebuilt. For example, if LibY is updated all packages which depend on it need to be rebuilt, eventually. We’ll start with updating one of the Version Sets that we think it low risk, or CCC in this case.
This is a critical piece that made Brazil so powerful. It was possible to check in code to a low level library that everyone depended on and have confidence that it wouldn’t break everyone else’s build. Version Set isolation offered for a very fine grained ability of teams to manage their applications at Amazon.
But it’s not a Version Control System if you can’t merge…
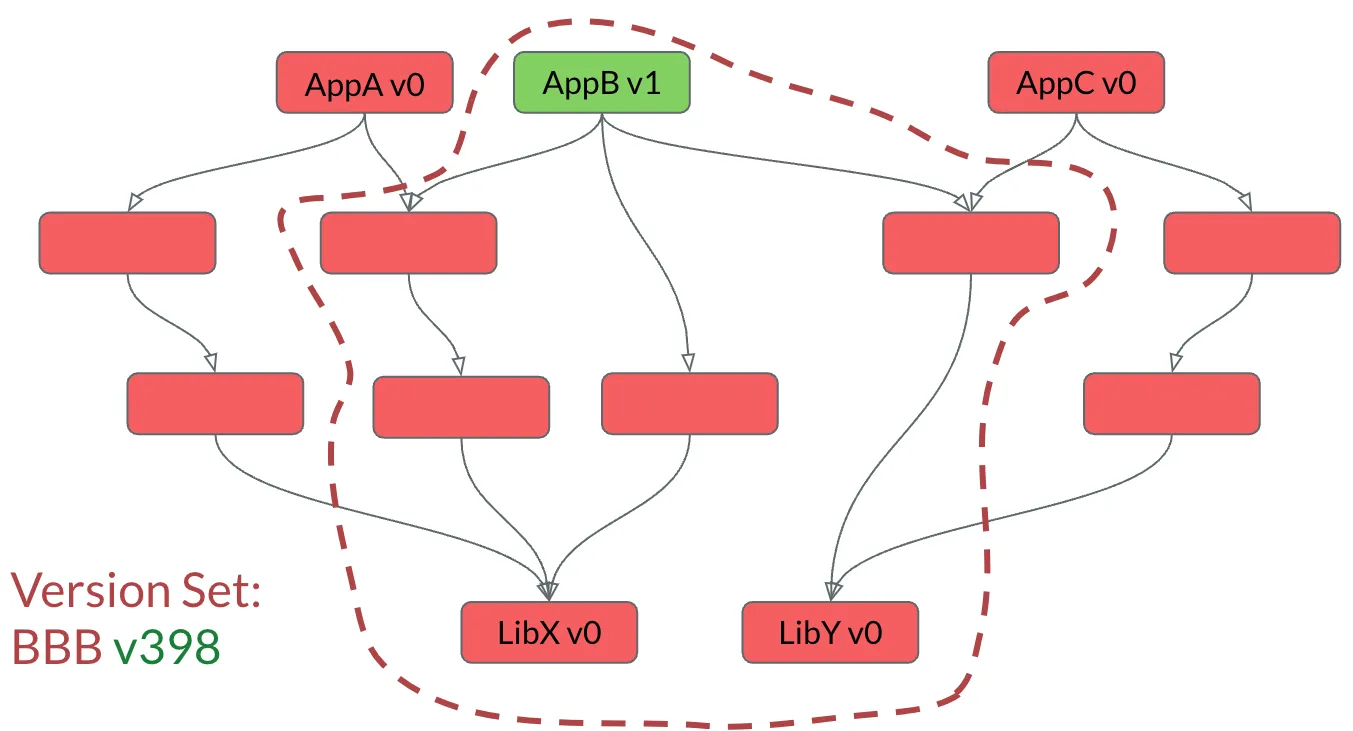
The Version Set merge operation would merge package versions from the experimental set into the first set. Note that the build package for LibY v1 stays intact. With some inspection we can see that all is required to update AppB with the latest version of LibY is to build one package.
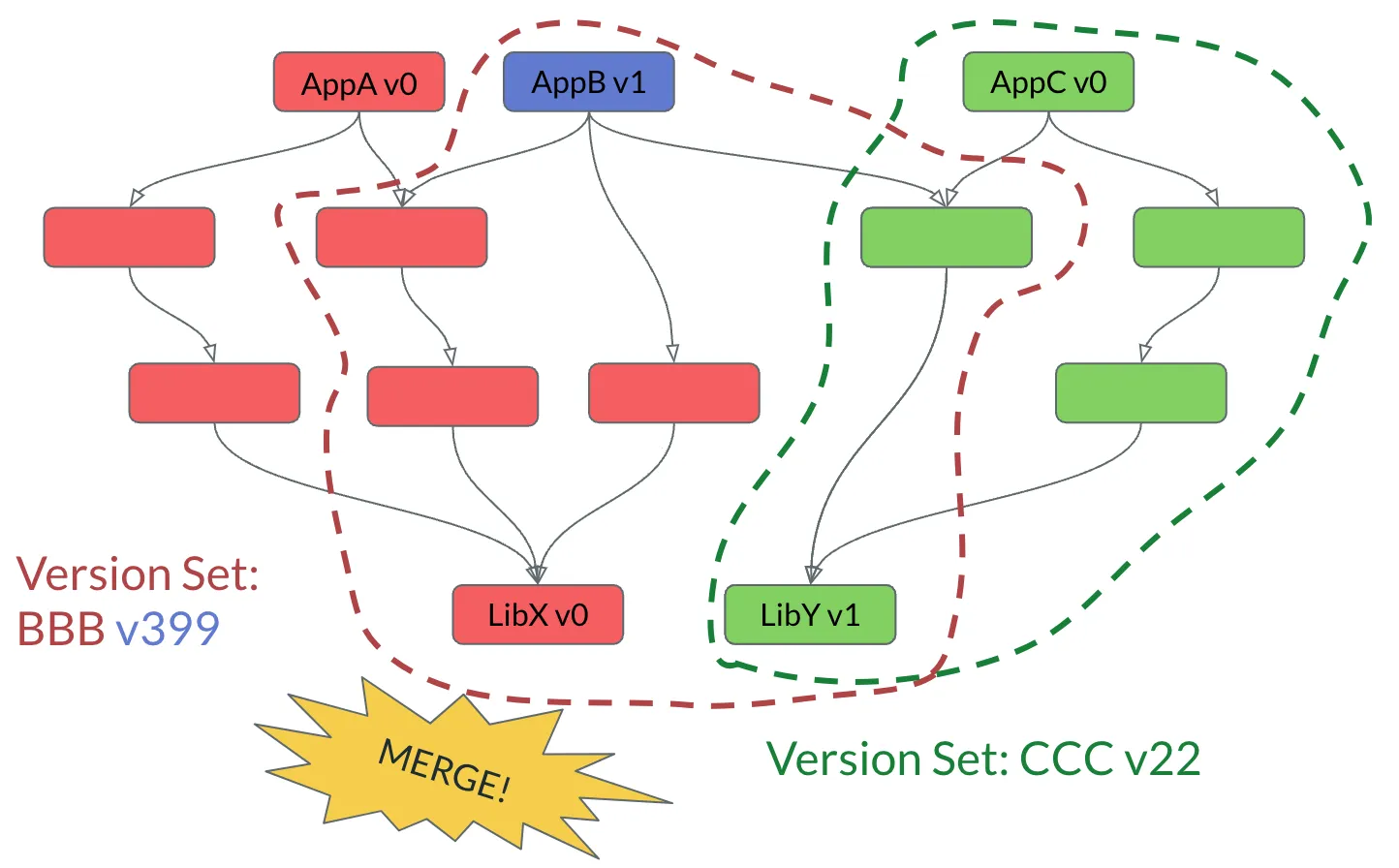
The overlap in the two Version Sets is where the merge happens. Brazil Version Sets are effectively serially versioned entities which allow for branching and merging. It’s a special purpose version control system, complete with a merge conflict workflow and rollbacks.
Anyone familiar with NPM Lock files, Go’s go.mod file, or other such solutions to codify the closure of package versions understands the value pinning down your versions. Brazil is a service to enable that, and thereby it could upgrade large swaths of the code base in automated ways. If it’s not clear, the vX in the picture above is the source code version number. IE, when AppB v1 went from Green to Blue, they are both v1 - in source control. Brazil has a separate version number for the package’s build, but that’s an internal detail.
This differs from systems you may be familiar with in that your application code needs to specify a specific version in the source code for the package. By constructing Version Sets in a service mass upgrades become much easier. There were other tools for upgrades where interfaces changed, but the vast majority of builds did not require that. Brazil could perform widespread software upgrades automatically and allow Amazon to move faster as a result.
Simple Brazil#
Modeling directed acyclic graphs in a SQL database is very awkward, and Brazil’s SQL model reflected that fact. Here is one way would could model Version Set revisions in a SQL database:
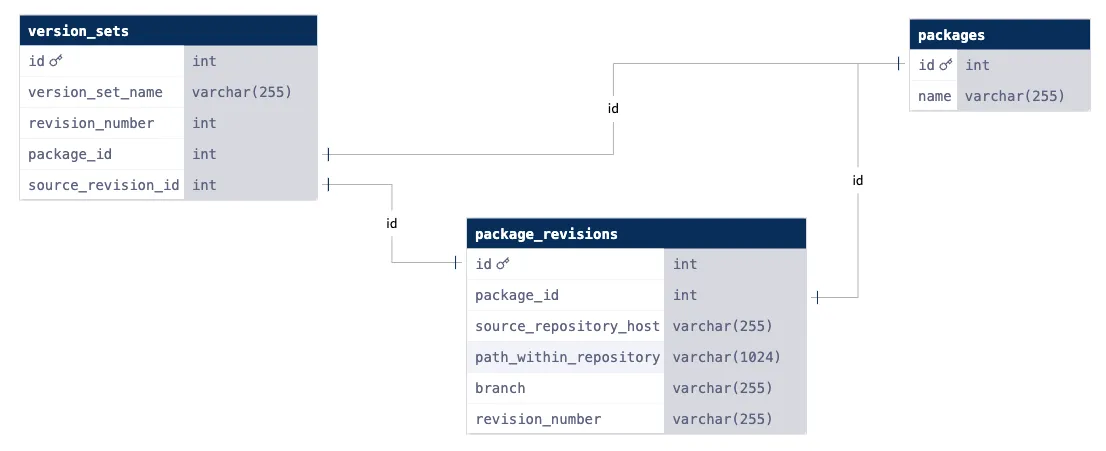
simple_brazil.sql (see constraints)
CREATE TABLE packages (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) UNIQUE
) AUTO_INCREMENT = 100;
CREATE TABLE package_revisions (
id INT AUTO_INCREMENT PRIMARY KEY,
package_id INT NOT NULL,
source_repository_host VARCHAR(255),
path_within_repository VARCHAR(1024),
branch VARCHAR(255),
revision_number VARCHAR(255),
FOREIGN KEY (package_id) REFERENCES packages(id)
) AUTO_INCREMENT = 500;
CREATE TABLE version_sets (
id INT AUTO_INCREMENT PRIMARY KEY,
version_set_name VARCHAR(255) NOT NULL,
revision_number INT NOT NULL,
package_id INT NOT NULL,
source_revision_id INT NOT NULL,
FOREIGN KEY (package_id) REFERENCES packages(id),
FOREIGN KEY (source_revision_id) REFERENCES package_revisions(id),
UNIQUE (version_set_name, revision_number, package_id)
) AUTO_INCREMENT = 900;I seeded the tables with some packages and changes:
mydb/main> select * from packages;
+-----+------+
| id | name |
+-----+------+
| 100 | AppA |
| 101 | AppB |
| 102 | AppC |
| 103 | LibX |
| 104 | LibY |
+-----+------+
mydb/main> select * from package_revisions;
+-----+------------+------------------------+------------------------+---------+-----------------+
| id | package_id | source_repository_host | path_within_repository | branch | revision_number |
+-----+------------+------------------------+------------------------+---------+-----------------+
| 500 | 100 | github.com | /repo/AppA | main | v0 |
| 501 | 101 | gitlab.com | /repo/AppB | main | v0 |
| 502 | 102 | bitbucket.org | /repo/AppC | release | v0 |
| 503 | 103 | sourceforge.net | /repo/LibX | main | v0 |
| 504 | 104 | example.com | /repo/LibY | main | v0 |
+-----+------------+------------------------+------------------------+---------+-----------------+
mydb/main> select * from version_sets order by version_set_name;
+-----+------------------+-----------------+------------+--------------------+
| id | version_set_name | revision_number | package_id | source_revision_id |
+-----+------------------+-----------------+------------+--------------------+
| 900 | AAA | 42 | 100 | 500 |
| 903 | AAA | 42 | 103 | 503 |
| 901 | BBB | 397 | 101 | 501 |
| 904 | BBB | 397 | 103 | 503 |
| 905 | BBB | 397 | 104 | 504 |
| 902 | CCC | 21 | 102 | 502 |
| 906 | CCC | 21 | 104 | 504 |
+-----+------------------+-----------------+------------+--------------------+One of the basic requirements for the application is to get source revision numbers for a given version set. Like so:
mydb/main> SELECT
vs.version_set_name,
vs.revision_number,
p.name AS package_name,
pr.revision_number AS package_revision_number
FROM
version_sets vs
JOIN
package_revisions pr ON vs.source_revision_id = pr.id
JOIN
packages p ON pr.package_id = p.id
WHERE
vs.version_set_name = 'BBB'
AND vs.revision_number = 397;
+------------------+-----------------+--------------+-------------------------+
| version_set_name | revision_number | package_name | package_revision_number |
+------------------+-----------------+--------------+-------------------------+
| BBB | 397 | AppB | v0 |
| BBB | 397 | LibX | v0 |
| BBB | 397 | LibY | v0 |
+------------------+-----------------+--------------+-------------------------+Those v0 values would be commit ids typically, but these match the figure
When we add the new change for AppB v1, the single package update will require inserting a new row for each version set.
main> select * from source_revision where package = 'AppB';
+----+---------+------------------------+------------------------+--------+-----------------+
| id | package | source_repository_host | path_within_repository | branch | revision_number |
+----+---------+------------------------+------------------------+--------+-----------------+
| 12 | AppB | gitlab.com | /repo/AppB | main | v0 |
| 16 | AppB | gitlab.com | /repo/AppB | main | v1 |
+----+---------+------------------------+------------------------+--------+-----------------+
mydb/main> SELECT
vs.version_set_name,
vs.revision_number,
p.name AS package_name,
pr.revision_number AS package_revision_number
FROM version_sets vs
JOIN package_revisions pr
ON vs.source_revision_id = pr.id
JOIN packages p
ON pr.package_id = p.id
WHERE vs.version_set_name = 'BBB'
AND vs.revision_number = 398;
+------------------+-----------------+--------------+-------------------------+
| version_set_name | revision_number | package_name | package_revision_number |
+------------------+-----------------+--------------+-------------------------+
| BBB | 398 | AppB | v1 |
| BBB | 398 | LibX | v0 |
| BBB | 398 | LibY | v0 |
+------------------+-----------------+--------------+-------------------------+For the purposes of performing builds and so forth, a query is necessary to find the difference between two sets. Which you could solve like this:
SELECT
p1.name AS package_name,
vs1.version_set_name AS version_set_from,
vs1.revision_number AS revision_number_from,
pr1.revision_number AS package_revision_from,
vs2.version_set_name AS version_set_to,
vs2.revision_number AS revision_number_to,
pr2.revision_number AS package_revision_to
FROM
version_sets vs1
LEFT JOIN
version_sets vs2
ON vs1.package_id = vs2.package_id
AND vs2.version_set_name = 'BBB' -- TO Version Set and Revision
AND vs2.revision_number = 398
JOIN
package_revisions pr1 ON vs1.source_revision_id = pr1.id
LEFT JOIN
package_revisions pr2 ON vs2.source_revision_id = pr2.id
JOIN
packages p1 ON vs1.package_id = p1.id
WHERE
vs1.version_set_name = 'BBB' -- FROM Version Set and Revision
AND vs1.revision_number = 397
AND (pr1.revision_number != pr2.revision_number
OR pr2.revision_number IS NULL
OR pr1.revision_number IS NULL)
ORDER BY
p1.name;
+--------------+------------------+----------------------+-----------------------+----------------+--------------------+---------------------+
| package_name | version_set_from | revision_number_from | package_revision_from | version_set_to | revision_number_to | package_revision_to |
+--------------+------------------+----------------------+-----------------------+----------------+--------------------+---------------------+
| AppB | BBB | 397 | v0 | BBB | 398 | v1 |
+--------------+------------------+----------------------+-----------------------+----------------+--------------------+---------------------+As I said, this would be the simplistic way to implement Brazil with SQL tables. Brazil didn’t go that route because the inserting of all those rows would be prohibitive. The work around for this was to use add_event and delete_event columns, and then the package version would be in a version set until it was taken out. So having a NULL delete_event column meant that it was still in the version set.
I’m not going to walk through the steps of that as a real life example because I’d argue that the query given above, to find the difference between two sets, is unreasonably hard. Using a flat table space to represent the complexities of entities changing over time is awkward. You end up needing to know which filters get you what you want so that you can answer simple questions about how information changed over time. Representing change overtime with a DAG has become commonplace, and it’s virtually impossible to do in vanilla SQL.
How about Dolt?#
When you have Version Control at your finger tips, you no longer need to encode many common patterns you are probably familiar with. Take for example our habit of having a deleted_date column which leaves the row in place for historical purposes. In a version controlled database, you just drop the row and trust that the database has you covered.
But what if you go all in? Dolt or Death?!? You could build your application on the primitives Dolt provides and keep you application logic more. You can branch, merge, log, rollback, and all the other things you would expect from a version control system. If you ever what to run a query on data from the past, use an AS OF query. You could build a Choose Your Own Adventure game with commits for each choice the user makes. You could build a chat application with threaded conversations based on Dolt commits. You could encode package Version Sets as their own branches in Brazil.
If I built Brazil on Dolt, I’d simplify it down to one table, and use the branch names as version set ids. It unconventional, when coming from another database, but this isn’t your mother’s database. Depending on Dolt as an API you can depend on forever is not crazy. You have the source code!
Your SQL application of the future can have Version Control at it’s disposal. Tell us what you are going to build on our Discord!