
Recently, users running SQL queries against their databases hosted on DoltHub has led us to uncovering some really interesting bugs in Dolt itself. In today’s post, I’ll take you on a journey as I recount our investigation of these bugs, and leverage the power of Dolt to make our investigative process much easier.
Our story begins a few weeks back when we noticed the main API of DoltHub, called dolthubapi, reporting CPU pegged at 100%. This was happening at random times every few days, and it wasn’t immediately clear what was causing this CPU leak.
The case of the CPU leak#

dolthubapi is a gRPC service written in Go, that is, at times, responsible for processing large amounts of work. Under normal conditions, it does not process any work that exhausts CPU or memory of the server container. By design, to prevent resource exhaustion for intensive workloads, dolthubapi schedules work to be processed out-of-band, on separate, dedicated hosts and additionally, automatically times-out gRPC requests that take longer than 15 seconds to complete.
For this reason, even if a request to dolthubapi had pegged CPU at 100%, we’d expect to only see this for 15 seconds until the request timed out. We would then expect to see the CPU released immediately after. But, this is not what we were observing in this instance.
Instead, we saw the CPU climb quickly to 100% and then stay there for a long time.
Aaron investigated this bug at the time, and found that it resulted from a user of DoltHub running a SQL query against a database.
On DoltHub, users can do this by using a web-based SQL console, or by using DoltHub’s user facing API.
Specifically, the DoltHub database involved was the dolthub/transparency-in-pricing, and the query causing the pegged CPU was:
SELECT r.description, r.standard_charge, h.name
FROM rate r
JOIN hospital h ON r.hospital_id = h.id
WHERE h.city = 'Chicago'
AND r.description LIKE '%Spinal%' LIMIT 1;When the user executed this query on DoltHub, a gRPC request to dolthubapi was made, calling the SqlReadQuery method. This method executes the query against the database, and returns the result only if the Dolt can return the result in under 15 seconds. If it takes Dolt longer than 15 seconds to process, then the execution of the query is canceled and SqlReadQuery returns a timeout error.
During Aaron’s investigation, he found that when this query was being executed in Dolt by dolthubapi, it used 100% of the CPU while processing the work, but when the work was supposed to be canceled due to timeout, Dolt was continuing to execute the query, beyond the lifecycle of the gRPC request. This resulted in the CPU staying pegged at 100% until the query completely finished.

Once Aaron found the problematic query, he was actually able to confirm that this what was happening by leveraging Dolt’s unique clone feature. He cloned a local copy of dolthub/transparency-in-pricing and then executed the same query against his local copy.
transparency-in-pricing$ dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit. "\help" for help.
transparency-in-pricing/main> SELECT r.description, r.standard_charge, h.name
-> FROM rate r
-> JOIN hospital h ON r.hospital_id = h.id
-> WHERE h.city = 'Chicago'
-> AND r.description LIKE '%Spinal%' LIMIT 1;
^CWhile the query was still processing, he tried to kill it with ^C, and found Dolt did in fact have a bug that prevented this query from being killed!
He was also able to confirm that the CPU on his host continued to grow even after he sent the interrupt signal to the process.

Aaron hypothesized the underlying cause of Dolt’s failure to abort to be most likely one of:
-
A
contexterror that is being dropped or ignored. Essentially, when thecontextis canceled, it will usually be signaled by an error on an I/O operation, or something similar. If resulting errors are ignored, then the work continues despite the context being canceled. -
It’s possible the
contextisn’t being passed down at all, to methods performing the work.
In Go, the context object is passed between API boundaries and processes and is used to enforce deadlines and cancel work. Typically you will see patterns like the following, which accept the context as its first argument, so it can be passed down through all method calls.
func DoSomething(ctx context.Context, arg Arg) error {
// ... use ctx ...
}After reviewing the source code for one of Dolt’s dependencies dolthub/go-mysql-server, Aaron found that in the case of the JOIN query run against dolthub/transparency-in-pricing, the issue was in fact an ignored context error.
Aaron found that in particular, by ignoring the context error and continuing with processing, a tight loop within the SQL code that implements the merge join was essentially reevaluating the same row contents over and over. This loop would find that the row contents did not match expectation, and the loop then attempted to fetch the next row.
While fetching the next row, which did correctly signal that the context had been canceled, this error returned from the fetch was ignored by the loop. And as a consequence, no new rows were fetched, and the same comparison was made over and over again.
This was a pretty cool bug to find, and Aaron was able to get a fix and release out shortly thereafter. But it wasn’t the only leak that’s reared its ugly head on DoltHub recently.
The case of the memory leak#
A few days ago, something eerily similar to the CPU leak we’d just fixed occurred on dolthubapi again.

In the deep, deep dark of the night, a customer reached out to us on Discord to report a brief outage they’d experienced. As it would turn out, this outage was due to an outage by the customer’s ISP, and not by DoltHub, but I wanted to investigate the report regardless.
During my investigation, I noticed something strange. We run DoltHub’s infrastructure on Kubernetes and during the night, one instance of our dolthubapi replicas had been OOMKilled, meaning the the server process crashed because the container ran out of memory.
This was strange to me in the same way that the case of the CPU leak fixed before was strange. While it’s possible for requests to dolthubapi to do memory intensive work, often this work is relegated to out-of-band processes that wont starve the container. And, in the event of a memory intensive request, I’d expect the request context to be canceled after 15 seconds, releasing the server memory.
So this server crash piqued my interest, and I went to our Prometheus graphs to get a better look at the memory utilization of our dolthubapi instance.
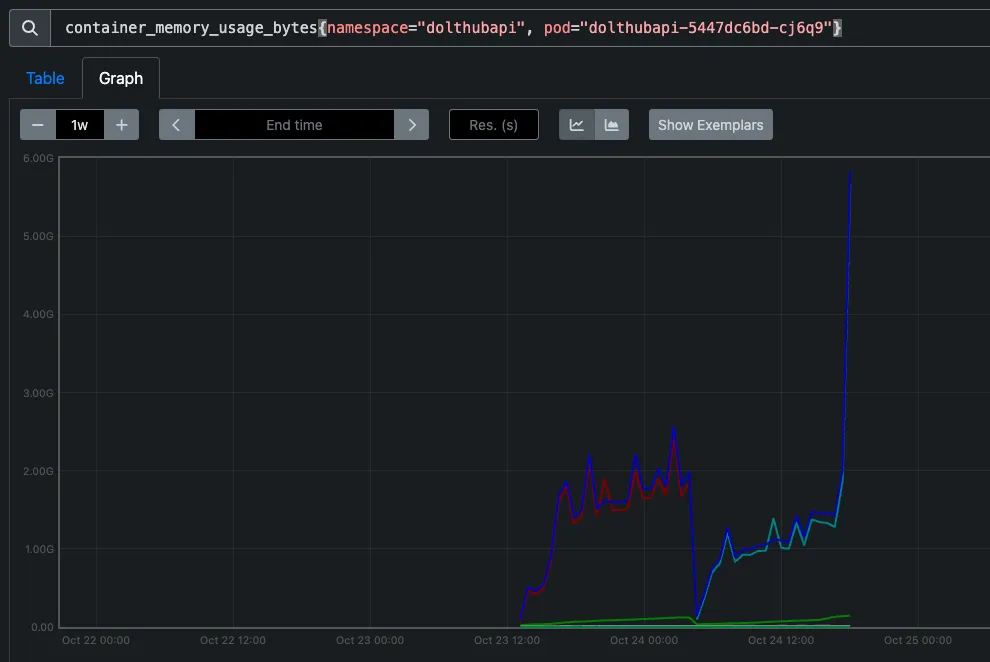
And boom. You can see from the graph the massive spike in memory for one of the pod, followed by a crash. It appeared like we had yet another leak to sleeeuuuuth.

After seeing this graph, I got the sense that this memory leak seemed very similar to the CPU leak Aaron found. Specifically, I believed that a SQL query executed by a user on DoltHub, might actually be causing this memory leak. It seemed very likely that when executing a SQL query, dolthubapi was allocating memory while processing, trying to cancel the processing after 15 seconds but failing, and continuing to process anyway.
If this were happening, I would expect the root cause of the issue to be almost identical to that of the CPU leak; either a context error was being dropped or ignored, or a context was not being passed to some query processing implementation.
To better support my theory I looked at another graph on Prometheus to see if there was a correlation between calls to SqlReadQuery and the memory spike at or around the time of the crash.
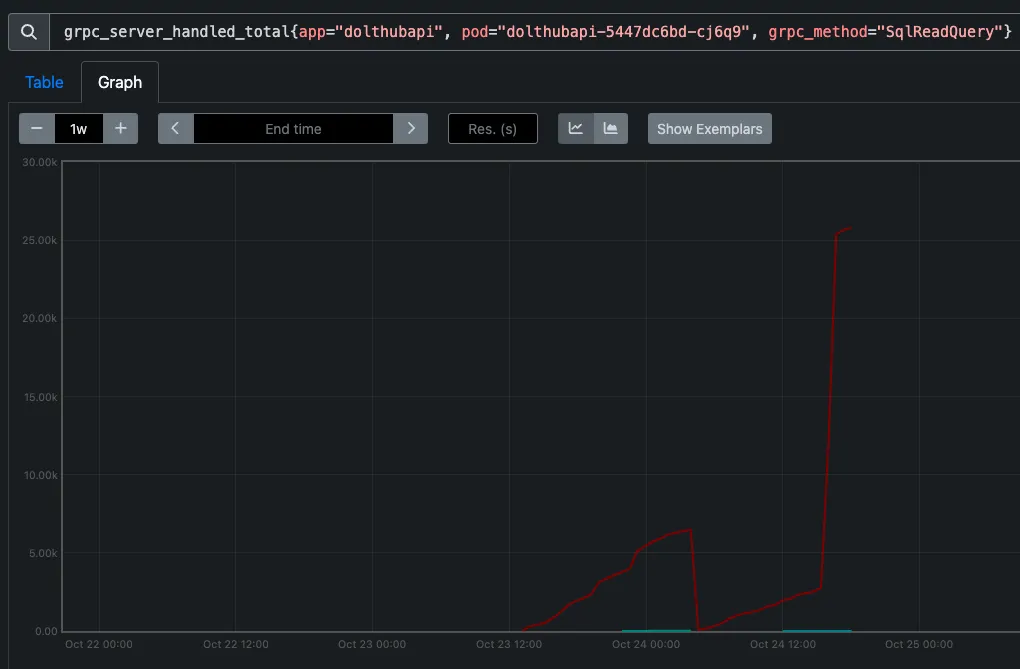
And sure enough, there was. Interestingly, not only were the calls of SqlReadQuery correlated, the number of calls appear to increase exponentially too, going from about 2500 calls to over 25,000. The evidence was starting to mount that we had indeed encountered a similar Dolt bug.
I then went to the dolthubapi server logs. It didn’t take me very long to find the problem query and the database it was run against. The database was a popular one on DoltHub called post-no-preference/options and the query ballooning memory was SELECT DISTINCT act_symbol FROM option_chain ORDER BY act_symbol;.
Because this database is public on DoltHub, I tried running the query myself on DoltHub using the SQL console. The result of the query was the standard timeout message, which was not surprising. But what was surprising was that I was able to see the memory in dolthubapi spike immediately after running the query. Moreover, I watched the memory spike for a few minutes, and it was not released by dolthubapi, long after the gRPC request had finished returning.
As one final sanity-check I went ahead and cloned the database locally. I wanted to reproduce this bug in Dolt to ensure there wasn’t something else to look for in the dolthubapi server code.
And sure enough, I could reproduce it locally. I ran the same query against my cloned copy of the database and observed the exhaustive use of memory.
option$ dolt sql -q 'SELECT DISTINCT act_symbol FROM option_chain ORDER BY act_symbol;'
^C
options$While the query was running, Dolt was using over 50GBs of memory and counting, far more than we have available in the dolthubapi server containers.

This was it; the bug I was after. I’d found it. It was over.
After confirming this I reached out to our resident exterminator, James, who shipped a fix for it.
Essentially, it involved restructuring how Dolt created the query plan in this case, so that distinct nodes are pushed below sort nodes. This means the distinct values in the resulting rows are filtered out before the rows are sorted. This change removed the need for extensive memory allocation, and also allows the query to complete in about 2 minutes.
But… something kept bothering me. Somehow this bug seemed like only a piece of a larger, more sinister bug-puzzle.

In the case of the CPU leak, when trying to reproduce the bug locally, Aaron had observed that killing the query prematurely did not stop Dolt from processing it. But, when I tried this same thing in the case of the memory leak, Dolt successfully terminated early, and released all of the accumulated memory.
Weirdly, in my local test, it seemed like Dolt was behaving properly, even though in dolthubapi I’d specifically seen the memory not get released back into the pool. So what was going on here?
Well, it turns out that when it comes to Dolt, there are actually a number of ways to execute a query against a database.
You can use the CLI to execute a query against an offline database. This is done with dolt sql or dolt sql -q, which is what I ran during my test. These commands do not operate against a live server (or so I thought) and simply read the contents of a Dolt database directory directly.
But, this is not actually true. In fact, these same commands can be used against a local live Dolt server. If you have a local Dolt server running, these commands will automatically work against that server. I didn’t realize this when I was doing my local testing, but it was a cool thing to discover after the fact.
Finally, you can execute a SQL query against a live Dolt server by connecting to it with a SQL client, like MySQL.
In my initial testing, I neglected to test if Dolt successfully killed the canceled query when it was run against a Dolt server instead of the static, offline, files.
When I went back to test it in this way, which is actually much closer to how dolthubapi executes queries against a Dolt database, I could reproduce the problem I expected to see.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| options |
+--------------------+
3 rows in set (0.00 sec)
mysql> use options;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SELECT DISTINCT `act_symbol` FROM `option_chain` ORDER BY `act_symbol`;
^C^C -- query aborted
^C^C -- query aborted
^C^C -- query aborted
^C^C -- query abortedJust like I had observed in Prometheus, and just like the case of the CPU leak weeks before, Dolt was not correctly killing the query after ^C. Even after multiple attempts, it was still claiming memory and processing the query in error. This, was the true bug. And now that it’s been found, we’ve been able to successfully put it to rest.

Conclusion#
To tell the truth, the final bug where Dolt failed to kill a query process after receiving the kill signal is slightly more nuanced, and was really more like three bugs, once we dug deeper.
First, like in the case of the CPU leak, we found there were places in the source code that were not passing the context object. This allowed query processing to continue, despite the context being canceled earlier.
Second, we observed that when a ^C is sent to a Dolt server from the MySQL client, the client actually sends a KILL QUERY command to the server. This command is, now, correctly handled by the Dolt server, but, since Dolt strives to match MySQL, we consider it an additional bug that when using the commands dolt sql and dolt sql -q against a live Dolt server, a ^C does not send a KILL QUERY command the way the MySQL client does.
And third, when an interrupt is signaled to dolt sql and dolt sql -q running against a live server, Dolt disconnects from the server, but does not close the previously used connection. This allows clients to reconnect to old connections, which too, is a bug.
The good news is that the serious bugs have all been fixed and released in Dolt v1.43.10, and as always, you can expect us to crank out bug fixes in under 24 hours. It’s been fun getting to use Dolt’s feature to make our debugging lives much easier here at DoltHub, as well. I encourage you to give Dolt a try if you haven’t yet done so.
Need to report a bug, or want to tell us how you’re using Dolt? You can reach us anytime Discord. We’d love to chat with you.
Thanks for reading and don’t forget to check out each of our cool products below:
- Dolt—it’s Git for data.
- Doltgres—it’s Dolt + PostgreSQL.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.