
One of the first questions we get from the “Dolt curious” is “How does it scale?”. We have a number of customers that run Dolt at scale, including Flock Safety and Turbine. For this article, I wanted to highlight a large public database so you can test Dolt’s scaling for yourself.
Dolt has the same scaling profile as a traditional Online Transaction Processing (OLTP) database like MySQL or Postgres. You can deploy Dolt with a single read/write primary with N read-only replicas. The primary is your scaling bottleneck. If you’re write throughput exceeds what your primary can handle, you need a bigger computer. If you’re at max computer size, you need new database software. You’ve outgrown Dolt.
That said, we don’t expect many Dolt users to face this bottleneck. If you’re building an internet-scale application, there are better databases for that. In the MySQL realm, you can go with Planetscale. Dolt’s Git-like features make it ideal for a number of use cases like mastering Machine Learning training data, versioning video game configuration, or adding branch and merge to your application. These use cases generally are not high throughput write use cases.
Over the past six months, I’ve been building a really large database for business and pleasure. I made MediaWiki work with Dolt and now I’m importing the March Wikipedia dump. The database is currently 665GB. If you look at the commit log, I get about 40,000-50,000 pages imported per day on my Mac Laptop. I’m currently at ~5.5M of 6.7M pages. Almost there.
As I’ve progressed through this import, I learned some tips to keep Dolt running well with a database this large. This blog article lets you in on my trade secrets.
Have the Right-Sized Computer#
Dolt is usually disk and memory constrained. I wrote a blog article about sizing your Dolt instance. The three main takeaways were:
- Dolt uses a lot of disk, especially for imports, because of garbage. Reclaim disk with garbage collection.
- You should have approximately 10% of the disk size of your database available in RAM.
- Dolt is generally not CPU constrained.
I’m running the Wikipedia database on my Mac M1 laptop, which admittedly is pretty beefy, 4TB Hard Drive and 128GB of RAM. The Dolt process uses about 36GB of RAM at steady state. The big issue is disk. The Wikipedia import is at approximately 650GB in permanent disk. Dolt generates about 500GB of garbage a week that gets collected down to between 10 and 20GB of permanent storage after garbage collection. So, I need to collect garbage every week or so to keep my machine from running out of disk.
Collect Garbage#
Let’s talk about garbage a little more. To keep Dolt scaling well, you must collect disk garbage using call dolt_gc(). Like Postgres, Dolt is “copy on write” and materializes intermediate state on disk. Unlike Postgres, Dolt doesn’t yet have an automated clean up process. Imports in particular generates a lot of intermediate state. Each state at transaction commit is materialized on disk. However, Dolt only needs to permanently store the latest (ie. HEAD) state and the state at any Dolt commit in the graph. The rest is garbage.
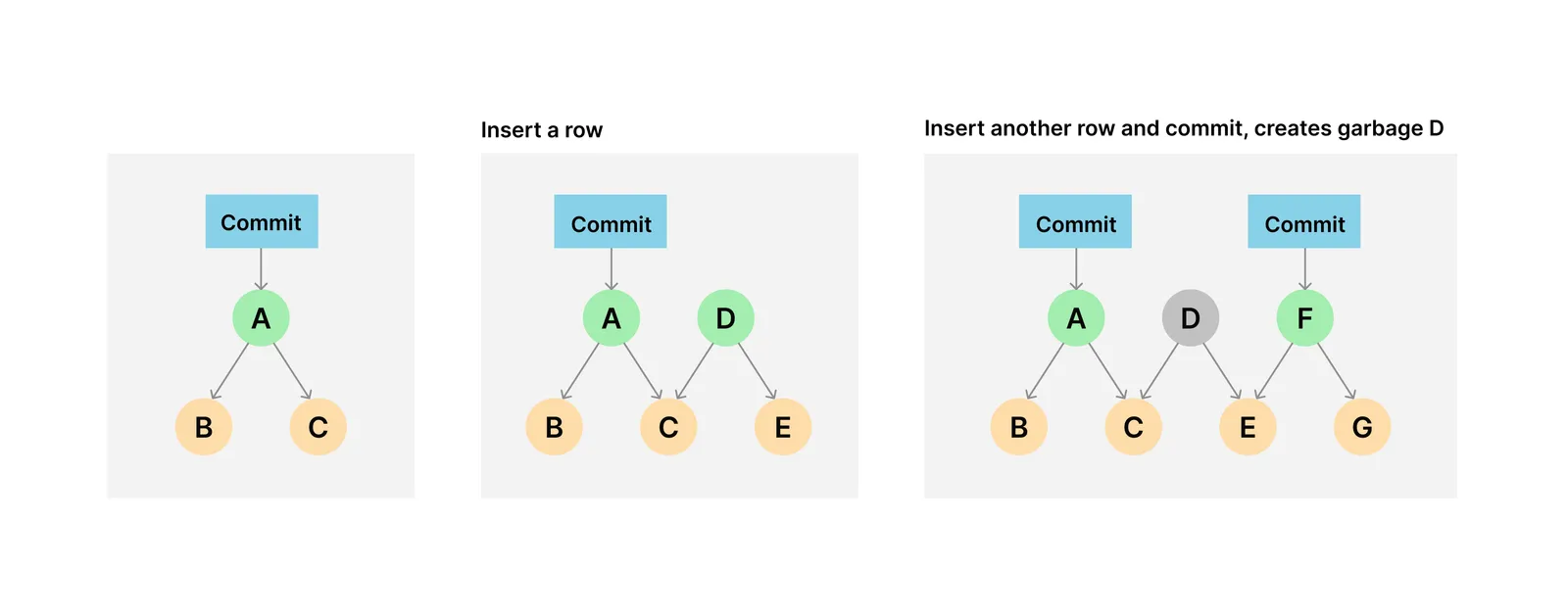
When you call dolt_gc() the garbage collection process first calculates all the garbage to collect. Then, at the end of that calculation, the process deletes all the garbage and resets any connections to the database to ensure no in flight work rendered something previously garbage not garbage. If your clients can’t handle the connection reset, you must reconnect them to Dolt as well. Most database connectors support re-establishing in flight connections because a database dropping a connection is fairly common.
To see how much garbage could be available, you can inspect Dolt’s journal file. It is the file named vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv in your .dolt/noms directory. For my Wikipedia import this file was 271GB after about 48 hours of importing data.
$ ls -lh .dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
-rw-r--r-- 1 timsehn staff 271G Oct 16 14:04 .dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvContrast this with 616GB of storage used in the .dolt/noms/oldgen directory, which is where Dolt puts most permanent storage state.
$ du -h .dolt/noms/oldgen
616G .dolt/noms/oldgenNow, we’ll run garbage collection and inspect the size of the journal file and oldgen.
$ dolt gc
$ ls -lh .dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
ls: .dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv: No such file or directory
$ du -h .dolt/noms/oldgen
627G .dolt/noms/oldgenAs you can see, we shrank the journal file to 0GB, saving 271GB while adding 11GB to oldgen as permanent storage, netting a 260GB reduction in total storage.
Unfortunately, the Wikipedia import script does not support re-establishing connections, so I must restart the import after garbage collection. The good news is, the import catches back up to its present state in about an hour.
We are working on automated garbage collection and expect it to be in Dolt sometime in Q4 2024. The first step is to remove the need to reset connections at the end of garbage collection, making garbage collection have no user impact, only a resource impact. After that, we must make garbage collection interruptible so it can be superseded if necessary by user queries. Automated garbage collection will likely start as off by default. Stay tuned for the announcement blog.
Turn On Statistics#
Modern databases use table statistics to optimize queries. If you have two large select queries being joined, it is optimal to process the select with the more restrictive where clause first. This makes the second select more restrictive based on the join clause. Table statistics are used to estimate the restrictiveness of where clauses, among other optimizations. For large databases, table statistics are essential for fast join queries.
Dolt introduced table statistics in January 2024. Since then, we’ve incrementally expanded the scope of optimizations that use table statistics. However, we restrict the automated collection of statistics to databases with a total table size of less than a million rows. So, if your database is large, turn statistics collection on by calling call dolt_stats_restart(). This will make a background thread to generate statistics. You can inspect the table statistics by querying the dolt_statistics table.
In the Wikipedia import table statistics made a big difference. Every so often, the import would call this join query which would take many minutes to return without table statistics.
SELECT /* ImportableOldRevisionImporter::import */
rev_id,rev_page,rev_timestamp,rev_minor_edit,rev_deleted,rev_len,rev_parent_id,rev_sha1,
actor_rev_user.actor_user AS `rev_user`,
actor_rev_user.actor_name AS `rev_user_text`,
rev_actor,comment_rev_comment.comment_text AS `rev_comment_text`,
comment_rev_comment.comment_data AS `rev_comment_data`,
comment_rev_comment.comment_id AS `rev_comment_cid` FROM `revision`
JOIN `actor` `actor_rev_user` ON ((actor_rev_user.actor_id = rev_actor))
JOIN `comment` `comment_rev_comment` ON ((comment_rev_comment.comment_id = rev_comment_id))
WHERE rev_page = 4003013 AND (rev_timestamp <= '20080619012627')
ORDER BY rev_timestamp DESC,rev_id DESC LIMIT 1With table statistics generated, the query returns instantly.
As I said, automated statistics generation is on by default for databases with fewer than 1M rows. We are in the process of enabling “on by default” automated statistics generation for all databases. This work is motivated by the massive performance difference statistics made in many JOINs used in the Wikipedia import. We don’t want users to miss out on these performance wins for Dolt databases at scale. Stay tuned for the announcement blog. It should be coming in the next couple weeks.
Add a Read Replica#
Dolt scales read throughput just like other traditional Online Transaction Processing (OLTP) databases. You add a replica and route read queries to the replica. In the limit, your primary database only serves write queries. Dolt offers a couple replication options.
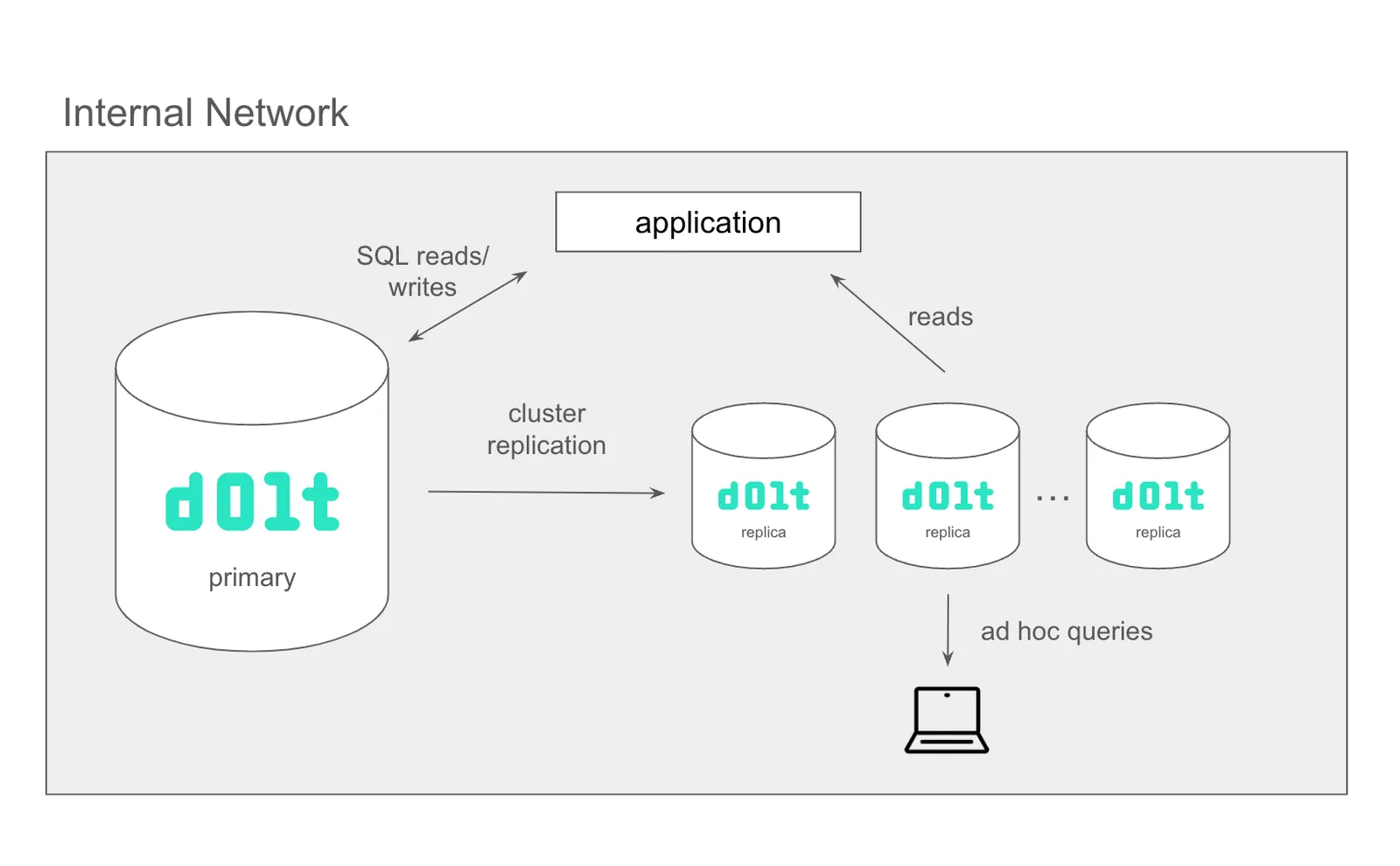
I’m not serving Wikipedia, only importing it to publish the data openly, so I haven’t encountered this scaling issue with the database I’ve been using as an example in this article.
Identify Slow Queries#
Even after all this work, you may encounter a slow query. Dolt’s SQL engine is original code built from the ground up. It’s still a work in progress. If you encounter a slow query, please make an issue. We take query performance very seriously. We can usually give you a workaround in hours and a permanent fix in days.
Conclusion#
Dolt is 1.0 and production ready to use at scale. Wikipedia is an example of a large public database that works in Dolt. Clone it and serve it to see for yourself. Questions about how to scale Dolt? Come by our Discord and we’d be happy to help you out.