
Dolt, the world’s first SQL database supporting branching and merging, has a lot of similarities to Git.
DoltHub currently has 15 people working on it, and a whopping 1/3 of us spent some amount of time in Amazon’s Builder Tools organization. Builder Tools at Amazon manages the systems required to write, build, test, and deploy software for all the products you are familiar with: AWS, www.amazon.com, Kindle, and many more. Naturally, Builder Tools is responsible for the safeguarding of source code and the systems which contain it.
From 2009 to 2014 I was a Sr. Engineer on the Source Team, which was responsible for managing Amazon’s source code. The other Dolts who were in Builder Tools are Tim (Founder, CEO), Aaron (Founder), Zach, and Jason. All of us have some amount of Amazon’s Builder Tools in our DNA today. It has highly impacted how we work on Dolt, and what problems we think are important to get right.
I thought this was the Dolt blog??#
Yes, details on Amazon’s source control may seem unrelated to Dolt. There are some pieces of inspiration on how you could deploy Dolt in a similar way. Jump to the end if you’re impatient! Probably the light bulb I want to turn on for all the database nerds is that large monolithic databases suck. Check out this white paper from Amazon: Millions of Tiny Databases. Dolt is a great database if you need lots of them.
Disclaimer#
All of the information below is more than 10 years old, so I suspect Amazon won’t care if I share this information. That said, none of this has been reviewed or approved by anyone who still works at Amazon. In fact, there are almost no details about Brazil or GitFarm on the internet, so maybe Amazon is very diligent in killing posts like this. Save a copy just in case this post disappears in the future!
The systems I’m describing here underwent continuous change from the time I started there in 2009 until today. Summarizing a 5-year project forces me to gloss over some details. Brazil and GitFarm are still critical pieces of Amazon’s internal tool set, and I’m sure they have evolved significantly beyond what I know about or describe here.
Brazil#
Amazon builds its software with a system called Brazil. Brazil was created in the early 2000’s and it was ahead of its time. Its core, driving feature was to enable sets of packages to be grouped together as “Version Sets.” Each package can depend on others, and cycles in the dependency tree are not allowed.
Each package version is built from an immutable state in a source control system. The identifier for the change contains the following information:
- Source Repository Host
- Path within the Repository
- Branch
- Revision number
The key detail here is (1) - Brazil is a Multi-Repo build system. The Multi-Repo Vs. Mono-Repo debate is a thing developers have opinions about. I’ll say I’m strongly in the camp of Multi-Repo - because of Brazil. It orchestrates a lot of complexity to enable automatic upgrades in a very scalable way. You may have opinions about Amazon, but you can’t really debate the fact that they build a lot of software. They wouldn’t be the juggernaut they are today if they couldn’t.
Brazil is a version control system. Complete with branching and merging. It allows for teams to experiment in their own isolated ways while also allowing them to stay up-to-date with other teams. I have a lot to say about Brazil, but I decided to split my original post into two. Here is a sneak peak of a pretty picture from the future!
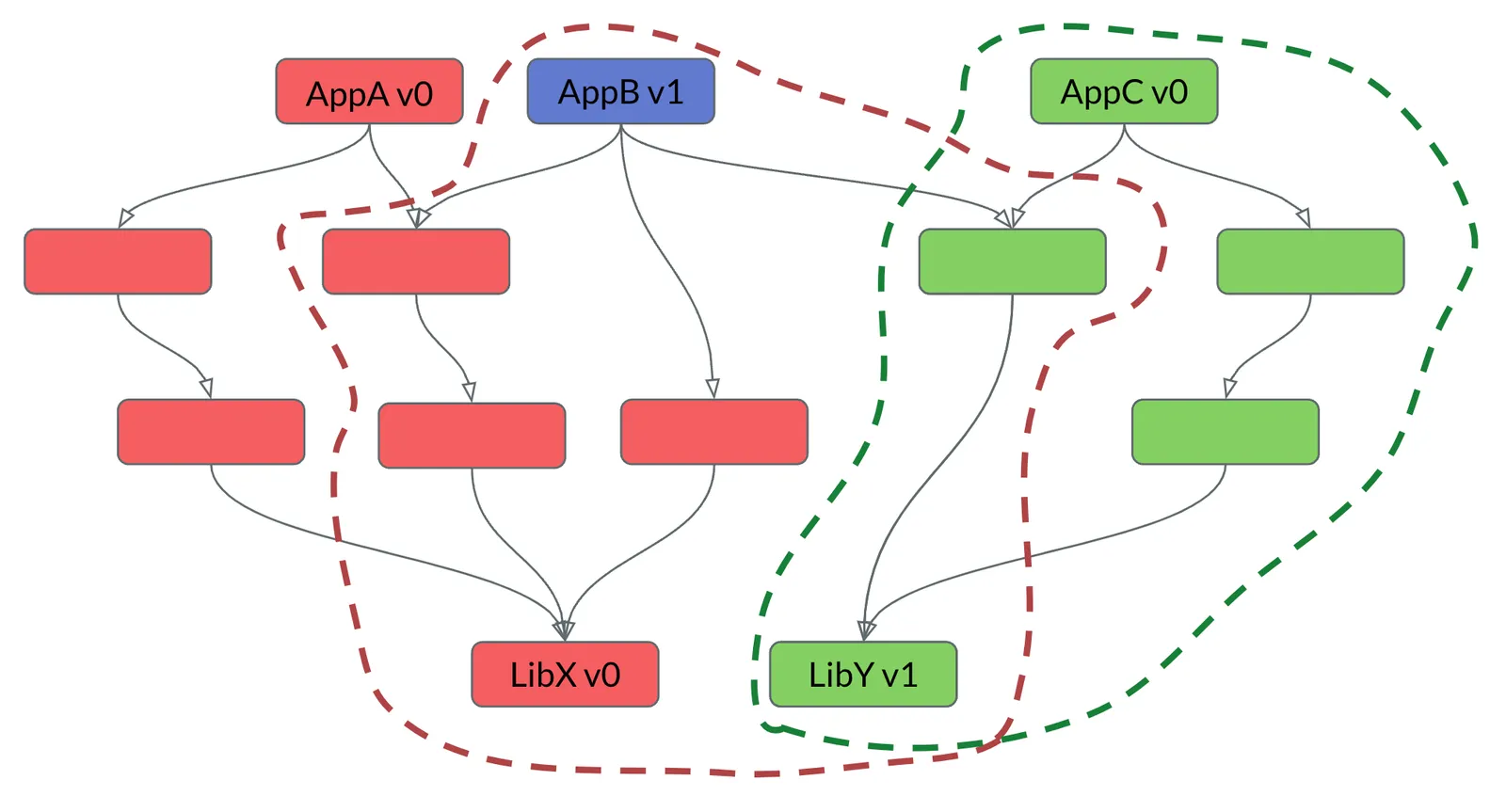
Source#
Brazil, by the late 2000s, was a multi-repository build system which had exactly two repositories, both Perforce.
As Amazon grew, one of the Perforce servers became about 10x larger than the other one. This was a result of the initial partition in source code between what you might call “frontend” and “backend” code. The front end code was Perl/Mason which drove the user experience for the retail website. I’d like to think that Perl/Mason is no longer part of Amazon’s stack, but I won’t speculate. The backend repository was for all the other services. This included all AWS services, which had gone from nothing to enormous over the course of a decade.
By 2007 when I joined Amazon, it was common to have brown outs of the larger repository. For people unfamiliar with Perforce, it’s a very chatty protocol. To p4 edit a file, you need to perform a network operation. If you wanted to know what you had changed, p4 diff was another network call. Literally every interaction a developer had with source control placed load on this central server. By 2007, this was a business problem. I’ll never forget someone coming to my desk saying “Perforce is down, we’re all going to lunch.” Remember, this is Amazon, notorious for “work hard and smart”, not Google. Killing swaths of your development organizations’ time was not OK.
Some temporary changes were put in place to lower load on the overloaded Perforce server, but they were mostly in the form of caching artifacts for the build system to avoid reads and things like that. The server was running on the largest host we could get our hands on and we were hearing about the crazy stuff Google was building to keep scaling their Perforce server. This approach was unsustainable.
There was even a Subversion server added into Brazil, which was pretty easy since Subversion and Perforce both take their inspiration from CVS (which is what Amazon used before Perforce). Developers weren’t very happy with SVN though. Furthermore, there were no developer tools to help manage multiple repositories in your workspace. Working with a mixed workspace where packages were in Perforce and SVN was nearly unbearable.
Enter Git#
When I started at Amazon, I wasn’t part of Builder Tools. I was one of the developers who depended on them. After much pain and annoyance with Perforce, I started to use Git personally to pull down source packages which I cared about. Git even includes a command to facilitate this. Unfortunately it didn’t work with the package layout that Brazil used, so I wrote a tool on top of git-fast-import which enabled Amazon developers to continue to do some work while Perforce was browning out on the daily. I shared it with others, but it was a scrappy solution that only a few brave souls were willing to try.
This caught the attention of Builder Tools, and I transferred to the team which maintained Perforce in 2009. After settling in and understanding the Brazil build system a little better, I proposed the idea of adding support for Git to Brazil.
This idea floated about as well as a lead balloon. It’s hard to remember now, but in 2009, Git was not the industry standard for source control. It had only gone 1.0 in 2005. Developers didn’t understand how it worked (maybe still don’t) and there was Mercurial which was more user friendly. GitHub was in its infancy. There were several large companies which had failed to use Git and publicly stated as much. I had multiple engineers more senior than myself send the results of a Google search for “does git scale?” to prove how wrong I was.
Perforce Shadow#
Nevertheless, I still worked on the team which was responsible for Perforce stability, and Perforce was anything but stable. Not only did it brown out frequently, it also corrupted data and some files were irretrievable. There was a secondary server we could failover to, but it was manual and honestly there was only one person on the team I’d trust to do the flip in an emergency.
There was a strong fear that if we kept our code only in Perforce that we could cause risk to the business in the form or lost code, untrustworthy audit trails due to lost history, and so forth. I convinced my manager to let me build a mechanism to replicate every write to our Perforce servers into Brazil package level Git repositories. We effectively built a replication system based entirely on top of Perforce user facing operations and git-fast-import.
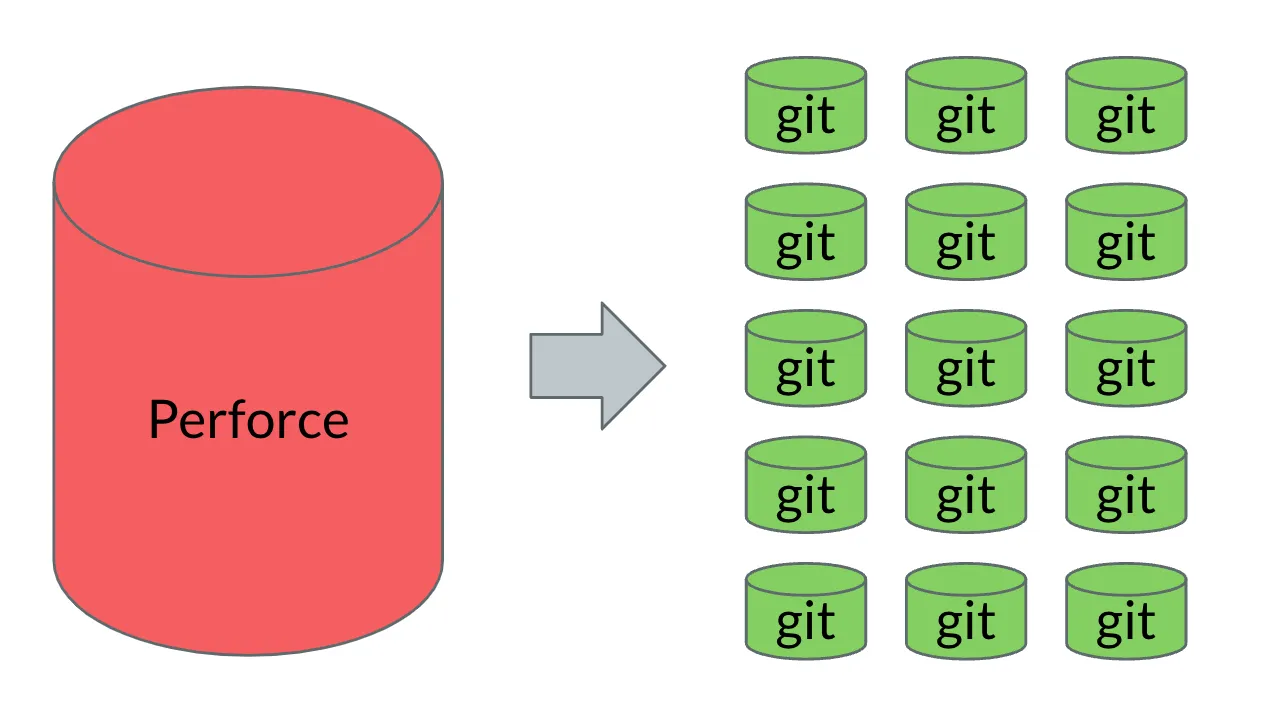
In 2009, Brazil had about 40K packages. How were we going to maintain 40K Git repositories?
GitFarm#
Toward the end of 2009, I started working on a system to manage lots of Git repositories. I called it GitFarm.
The general idea was that there were three copies of each Brazil Package in GitFarm, spread out in multiple small hosts. Each host has a Java program which would manage the Git repositories on the host. There was a stream of events which came from Perforce that each JVM monitored, and when a specific JVM determined that one of its packages was updated, it followed these steps:
- JVM checked with the Routing DB to verify that it was still the primary responsible for the package.
- Using
git-fast-importchanges from Perforce were replicated into the Git copy on the host. - Routing DB was updated.
- Secondaries determine they are out of sync from the primary.
- Using
git fetchthe secondaries update their state.
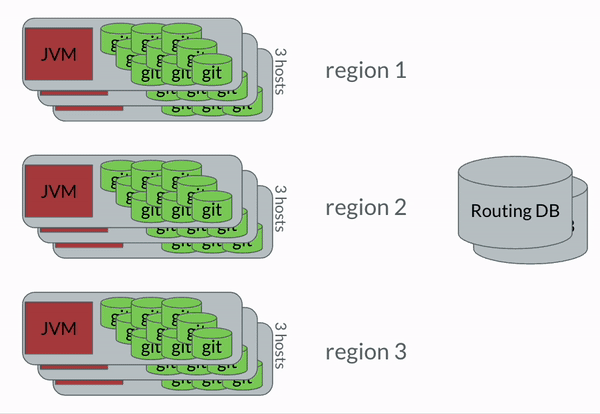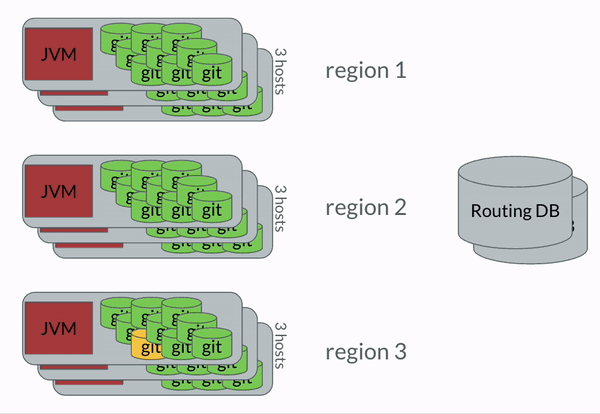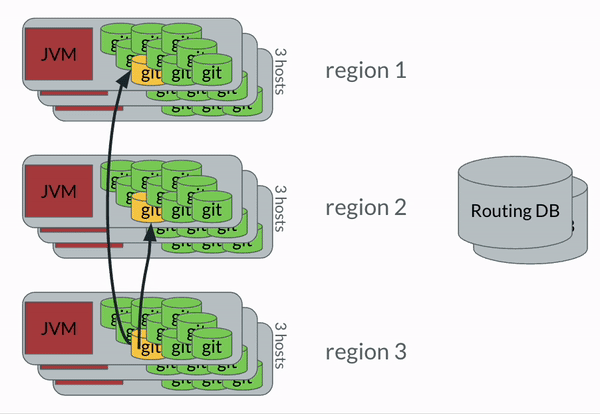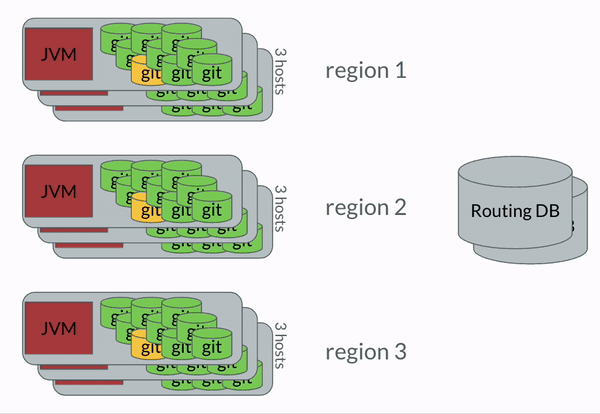
The most important bit to take away here was that once the code was in GitFarm, all movement of changes was done entirely with Git’s standard protocols. We wanted to leverage the pieces of Git which were well oiled. This very much applies to Dolt, btw. Syncing between Dolt databases works very similarly to how Git does.
There were several pieces which didn’t work terribly well. I made the terrible decision to use an eventually consistent database for the Routing DB, which caused many problems. I also put too much faith in the JVM being able to stream bytes for the underlying Git protocol. We fixed both of those things eventually, but phase one of reliably extracting all writes from Perforce into secondary Git repositories was complete.
Git Proxies#
Now that we had copies of the source, why not start using them for developer benefit? By 2011 or so, there were plenty of developers starting at Amazon who already had Git experience, and they didn’t want to bother with Perforce. Furthermore, if we did it right, developers using Git could do their jobs without really putting any load on Perforce - thus buying us time.
We added the ability to read from GitFarm by adding access to an SSH Daemon for everyone at Amazon. This SSHD instance didn’t allow general access, just the ability to run git-upload-pack, which is the server side command executed when you run git pull. There were also client side hooks which converted a git push operation to actually perform all the operations required to write the change into Perforce.
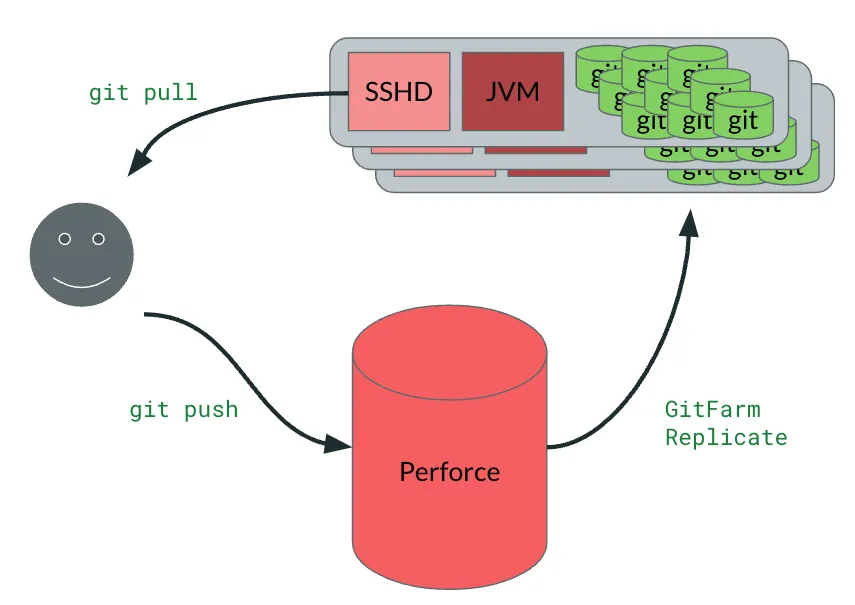
The end result was that developers never needed to touch Perforce unless they were submitting code. For those users, no network transit was required to start editing a file, view a diff, or whatever else was required to do their work. This translated to measurably less load per user on Perforce.
We called this feature Git Proxies, and it had the secondary effect which was actually more important than reducing load on Perforce. It allowed individuals to try out this newfangled Git thing without needing to move their code. It was a “Try Before You Buy” approach which allowed individuals to see the benefits of local revision control before making any migrations or anything else that was a one way door. In a pinch you could always go back to Perforce if you didn’t know how to move forward with Git.
Making GitFarm Production Ready#
By 2012 more than 20% of all changed pushed to Perforce were coming through Git Proxies. There were entire teams who were convinced they wanted Git and never wanted to touch Perforce again. This, coupled with an all-day outage of main Perforce server for reasons I don’t remember, set the stage to turn GitFarm from not just a secondary cache for Perforce, but as a primary supported source repository for Brazil.
As I mentioned above, Brazil was pretty amenable to having multiple source repositories. While we proposing going from 3 repositories to 10s of thousands of repositories, Brazil didn’t really need very many changes at all. GitFarm, on the other hand, needed to put its big boy pants on and become production ready.
A lot of stability work had been done by this time. The Routing DB wasn’t some janky eventually consistent database - it was an Oracle database. The JVM was not responsible for any byte streaming - that was all moved into the SSH side of things. Host health and failover was much more solid thanks to the Distributed Failure Detection Daemon (DFDD) - a widely deployed gossip library in AWS at the time. We had cold backups of every GitFarm repository in S3 too.
The last gaps we needed to fill before we could receive writes directly to GitFarm were all about Enterprise. Specifically permissions, auditing, and the need to be able to expunge history - all of which Git natively has limited ability to do.
Permissions were pretty straightforward. Prior to running git-upload-pack We’d verify that the user could write to the repository. This allowed for package level repositories, but we punted on branch level permissions at the time.
Auditing and removing history were a little more dicey. To solve these, GitFarm had a parallel history which was only visible to GitFarm itself. It was a serial commit history which recorded the alterations to the repository along with the user identity and other useful details about the transaction.
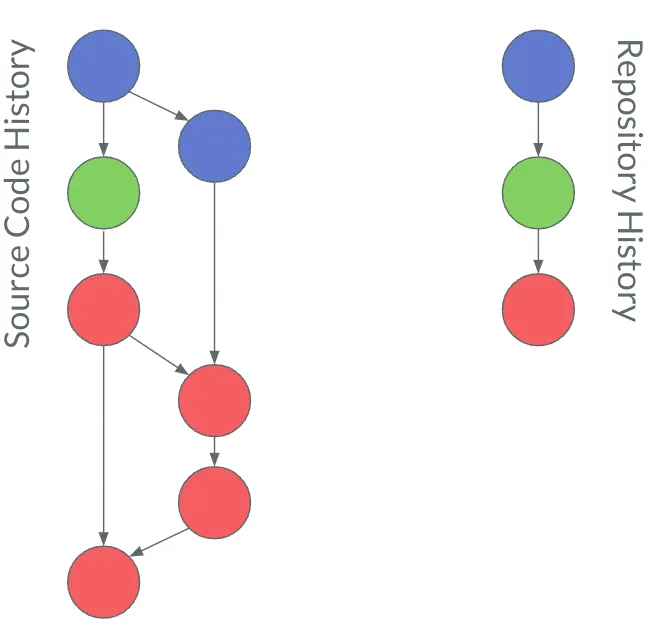
Did you know that you can have any number of unrelated histories in a Git repository? Dolt too! We leveraged this fact in GitFarm to record a parallel history that was used to ensure that we had full confidence in the quality of the repository. When a user pushed a change into GitFarm, the source code was transmitted like any other Git change. Prior to completing the update, GitFarm would write a record in a parallel disconnected history. For example, a user pushes in the four red commits, that results in one event record in the repository history.
When an operator would expunge history from the repository using git-filter-branch, they would include a note in this parallel history about it so that we could have high confidence that we weren’t losing information that might be needed in an audit.
DoltFarm?#
The Git migration at Amazon had a lot of things going in it’s favor, but the most important thing was a natural partition point. The Brazil Package layout was essential. Many applications have such partitions. They may be by customer, developer team, or something else, but often times we assume all of our data is going in one database. We do that because having multiple databases sounds like more work.
A necessary step to support Git at Amazon was how we could try it out before committing to it. Dolt is very similar, in that it’s very easy to create a Dolt database, either by importing existing data or setting up replication. If you have an existing SQL system which is serving your business, we know changing that may be difficult. There are ways Dolt can benefit you without making it the central piece of your infrastructure.
Possibly the most important conviction I had when people told me “Git doesn’t scale” was that it doesn’t scale in the same way that people habitually expect. It scales by virtue of the fact that it’s so easy to create many repositories. This was absolutely a motivation for Dolt to be easy and light weight. It’s a database that still runs as a monolithic process - so it has all the scaling challenges which come with that. Postgres and MySQL have these problems too. Creating a new Dolt database is extremely light weight though, and you can take advantage of that. Maybe you need to create a DB, use it, then throw it away. No problem. Dolt is cheap.
Lessons#
As I said at the top, Builder Tools highly influenced several of the people here at Dolt. Convictions we have:
- Multiple outage events involving lost data made us history obsessed. You can’t rollback if you don’t have history. History is valuable.
- Light weight branching allows for rapid and risk-free experimentation. Git and Dolt are great at this.
- “Try Before you Buy” tooling can be the best way to convince people you are building something they need. You can see this in Dolt with our support for replicating out of your existing systems into Dolt. It’s ridiculously easy to kick the tires:
$ dolt init
Successfully initialized dolt data repository.
$ dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit. "\help" for help.
db/main>Dolt is a tool that can be abused in all sorts of ways. Don’t think of it like your mother’s database. You can do new things with it, and some of your peers may doubt your methods. That’s OK. Prove them wrong. Come tell us what you’ll build with Dolt on our discord server!
