
We’re building Dolt, the world’s first version-controlled SQL database. Dolt lets you branch and merge your database tables just like you do with your Git files.
When we tell people we built this technology, we get one of two responses:
- That’s so cool, I can think of a bunch of ways to use this at my company!
- Huh. What would you do with that?
A few years ago, our answer to the question in the second response was mostly hypothetical. We could think of lots of ways that we would use Dolt ourselves, but we didn’t really know what other people would build with it.
Today, we have a much better idea thanks to customers who have used Dolt’s version-control features to build a lot of different applications in a bunch of different domains.
Use cases we can share publicly#
All the use case examples in this section come from real customers in the wild who have agreed to let us talk about them publicly. This is how Dolt is being used today by our customers.
Game development#
Modern games have a lot of data. When you think about the structure of most modern games, the actual source code of the game is a relatively small portion of the package. Most of the what comes on the disk (or in the Steam download) is actually data: character models, dialog trees, quest data, equipment and enemy stats, etc. This amounts to gigabytes of data in many cases, independent of the source code.
In the age of freemium and subscription gaming, the task of managing all this configuration data becomes even more pressing: to keep players engaged over the long haul, you want to roll out new content on a very regular basis. Dolt helps game studios manage the complexity of their giant game data stores to keep the content rolling out in an orderly fashion.
Several game studios are using Dolt to manage their game configuration data. One of our earlier customers in this category is Scorewarrior, who make the free-to-play game Total Battle.
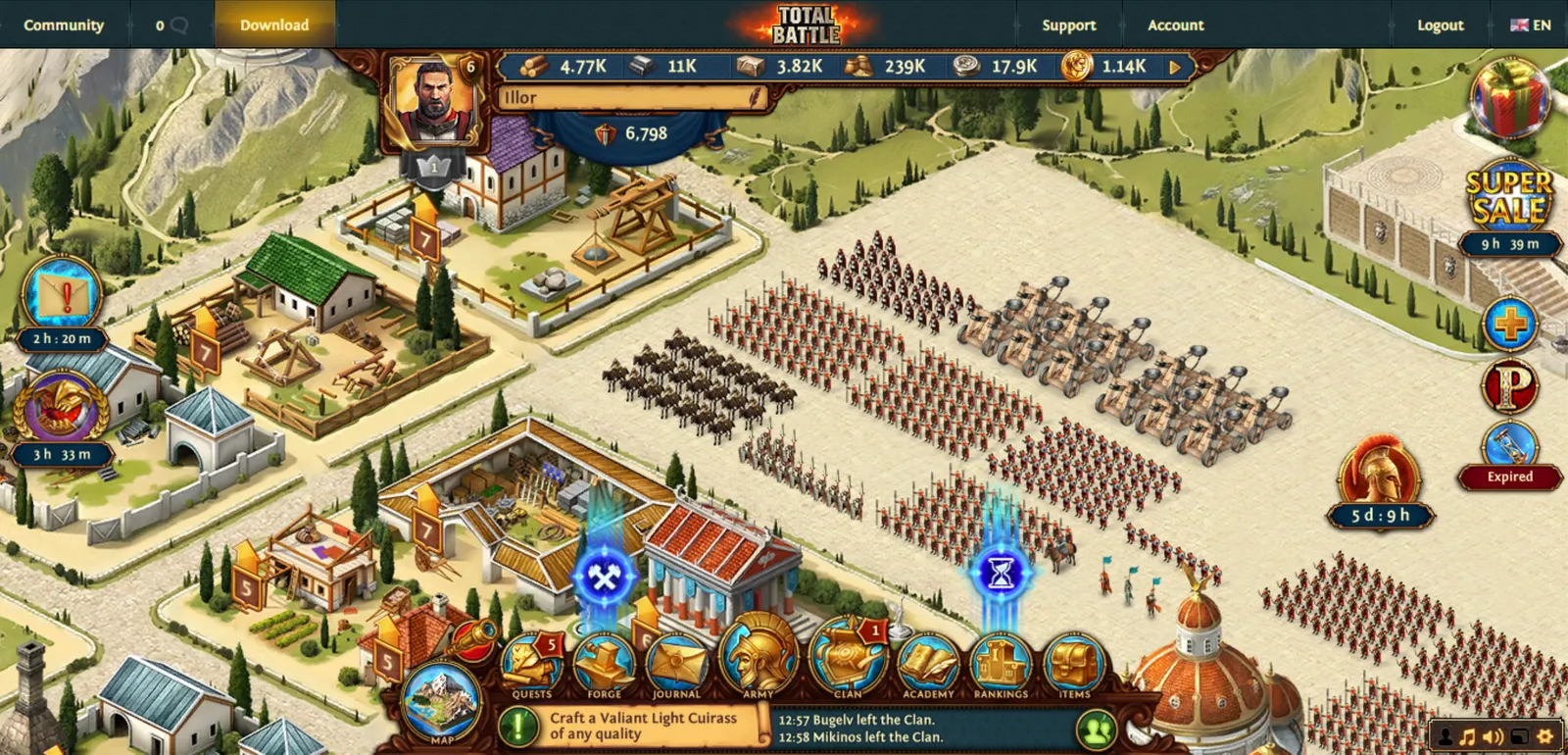
Scorewarrior stores most of their game configuration data in Dolt. They use Dolt’s branch and merge functionality to develop new content on branches and merge it back to main when it’s ready to ship to their player base. Here’s an example of some of the data they store:
+-------+------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------+
| stars | CREATE TABLE `stars` ( |
| | `star_system_id` int NOT NULL, |
| | `segment_id` int NOT NULL, |
| | `star_id` int NOT NULL, |
| | `effect_id` int NOT NULL, |
| | `price_unlock` json NOT NULL, |
| | `client_config` json DEFAULT (json_object()), |
| | `rating_contribution` bigint NOT NULL DEFAULT '0', |
| | `unlock_condition` text NOT NULL, |
| | PRIMARY KEY (`star_system_id`,`segment_id`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-------+------------------------------------------------------------------+This piece data is used to power the game feature below:
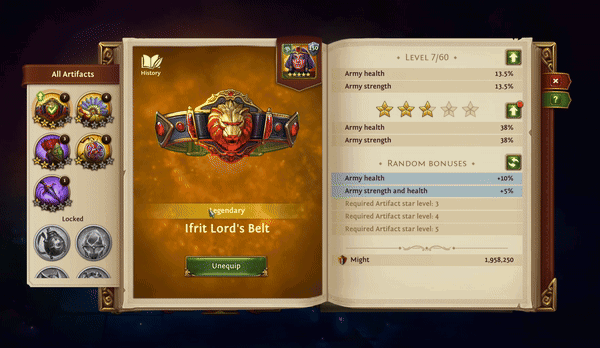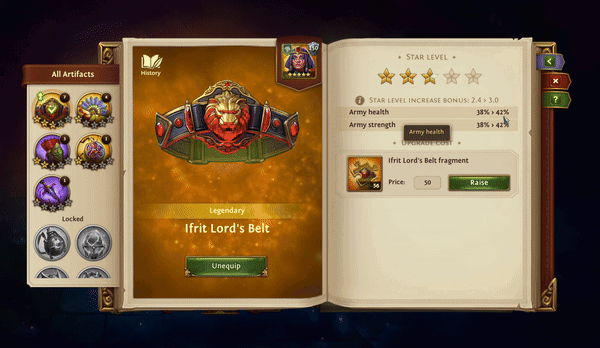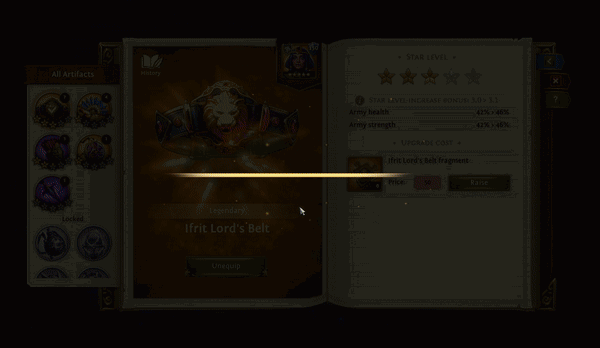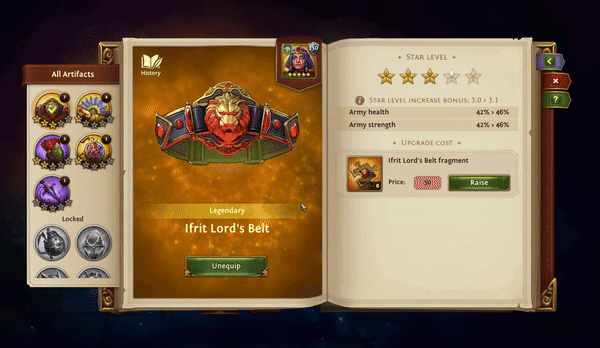
Game developers saw the potential for Dolt earlier than a lot of other domains, precisely because game configuration data has become so heavyweight in recent years. Before Dolt, these studios were storing giant JSON blobs in Git and suffering from constant merge conflicts and poor performance. Thanks to these early customers, we’ve prioritized development of JSON features in Dolt to be able to merge the contents of two JSON docs without conflict in most cases. And we’re now faster than Postgres or MySQL for most JSON operations, with the performance difference really showing up at large document sizes.
Dolt is a great match for managing game configuration data, both at build time and even at runtime. You can read more about this use case in our long blog about Scorewarrior here.
Machine learning training data#
AI is having a moment, to put it mildly. Most of the attention right now is concentrated on LLMs like ChatGPT, but earlier paradigms of AI have also been making steady progress in their capabilities. Most such work is still referred to by the older term of art “machine learning” (ML), and it’s what powers such impressive feats as image recognition and many prediction algorithms. Like LLMs, machine learning requires a large quantity of training data, which is then used to create statistical models that can predict the features of novel input based on the training.
One prominent Dolt customer in this domain is Flock Safety, who builds an AI safety solution for law enforcement and private security.

Wherever there’s large amounts of structured data, Dolt can help manage it. Unlike traditional DBMS
solutions, Dolt offers a critical advantage for ML: reproducibility. Because it’s possible to query
the training data as it existed at any point in time, ML customers can always reproduce any given
model exactly, even when the training data has changed in the meantime. Flock initially chose Dolt
solely for this feature, and then over time discovered they also had uses for Dolt’s other version
control capabilities. They use diffs of their training data between model revisions to better
understand understand why its results changed. And they use branches so that their teams of data
engineers can add new features to the model on a branch while still updating the training data on
main.
You can read more about Flock Safety and how they use Dolt here.
Medical data#
One exciting sub-domain of ML is using medical data with AI and simulation to generate new drugs. One of Dolt’s earliest paying customers, Turbine, is using Dolt to track the data they use to develop new cancer drugs.
Turbine’s use of Dolt is similar to Flock’s, but they make heavier use of the branch and merge workflow. In their case, they built a custom application on top of Dolt to implement a PR workflow for changes to the data, similar to the PR workflow on GitHub that most engineers are familiar with.
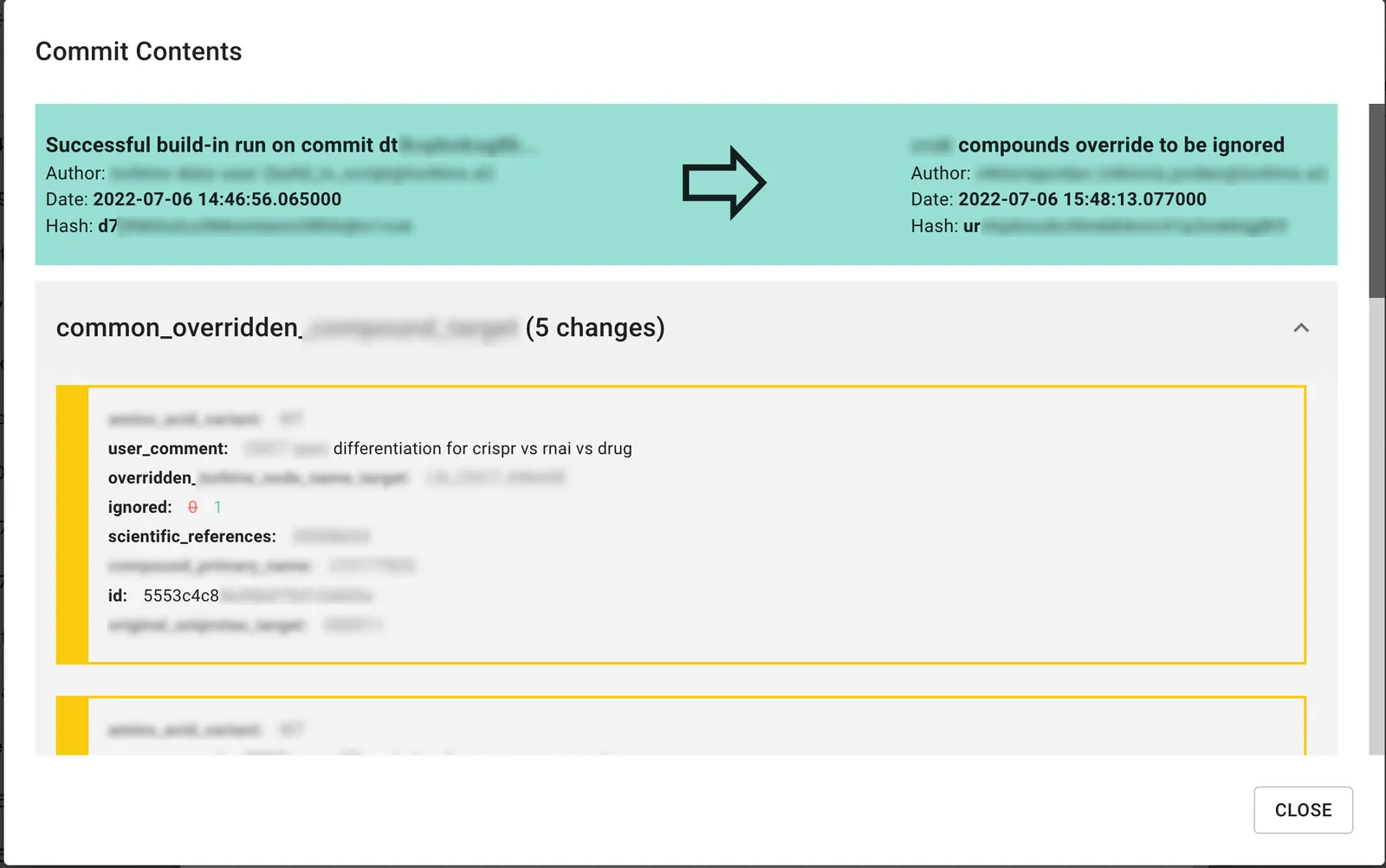
Their impressive GUI powered by Dolt also enables the reproducibility critical to ML workflows. In their case, they decided to build rollback directly into the application GUI so that researchers can rewind to any point in the history of the data for an experiment with a single click.
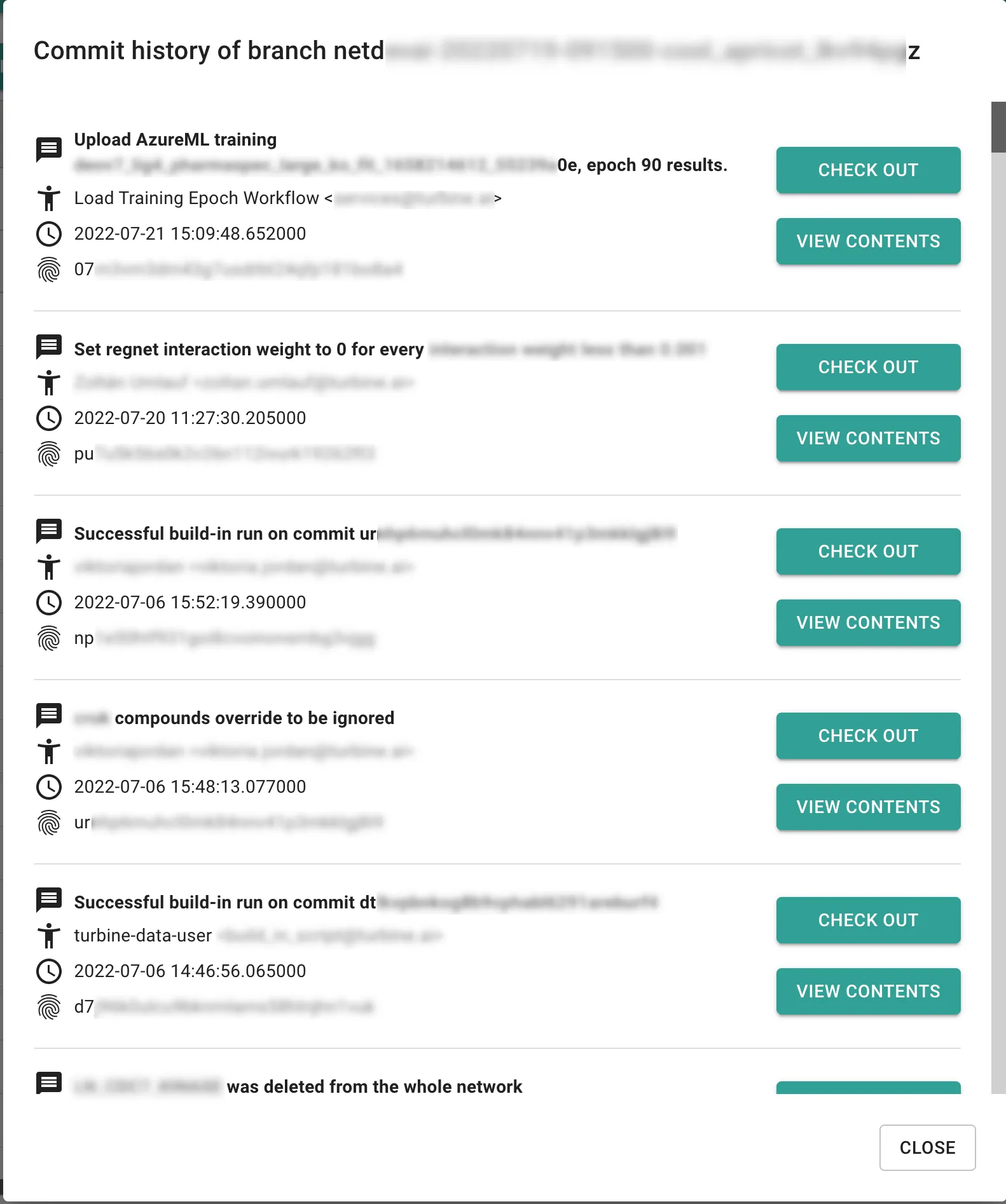
You can read more about Turbine’s use of Dolt in our blog post here.
Content management for a catalog#
Branch and merge workflows like Turbine’s make a lot of sense whenever data is being changed carefully in batches by humans, like it is during a PR for source code. Many database applications have this kind of human-curated data management as their primary job. We tend to lump this kind of application under the term content management system (CMS). Examples are wikis, blogs, product catalogs, etc. The common thread that ties such applications together is that humans (not automated systems) create most of the data.
The benefit of branching and merging in a CMS is allowing parallel work streams: you have individuals or teams making changes in isolation, which they want to eventually merge back together into something sensible to release to the world. Without the capability to merge, branches are much less useful, and in our opinion Dolt is the only SQL database that has true branches, since it’s the only one that can do merges.
One of the best examples of this use case among our customers is Threekit, who provide a 3D modeling services for their customers.
Threekit’s customers are typically running digital storefronts, and use Threekit to create and manage a catalog of virtual assets for their retail products. Threekit built a branch and merge feature to enable their larger customers to work better in parallel. These customers have large teams that are making many different changes to the catalog at the same time, so they use branches and merges to manage those changes more predictably.
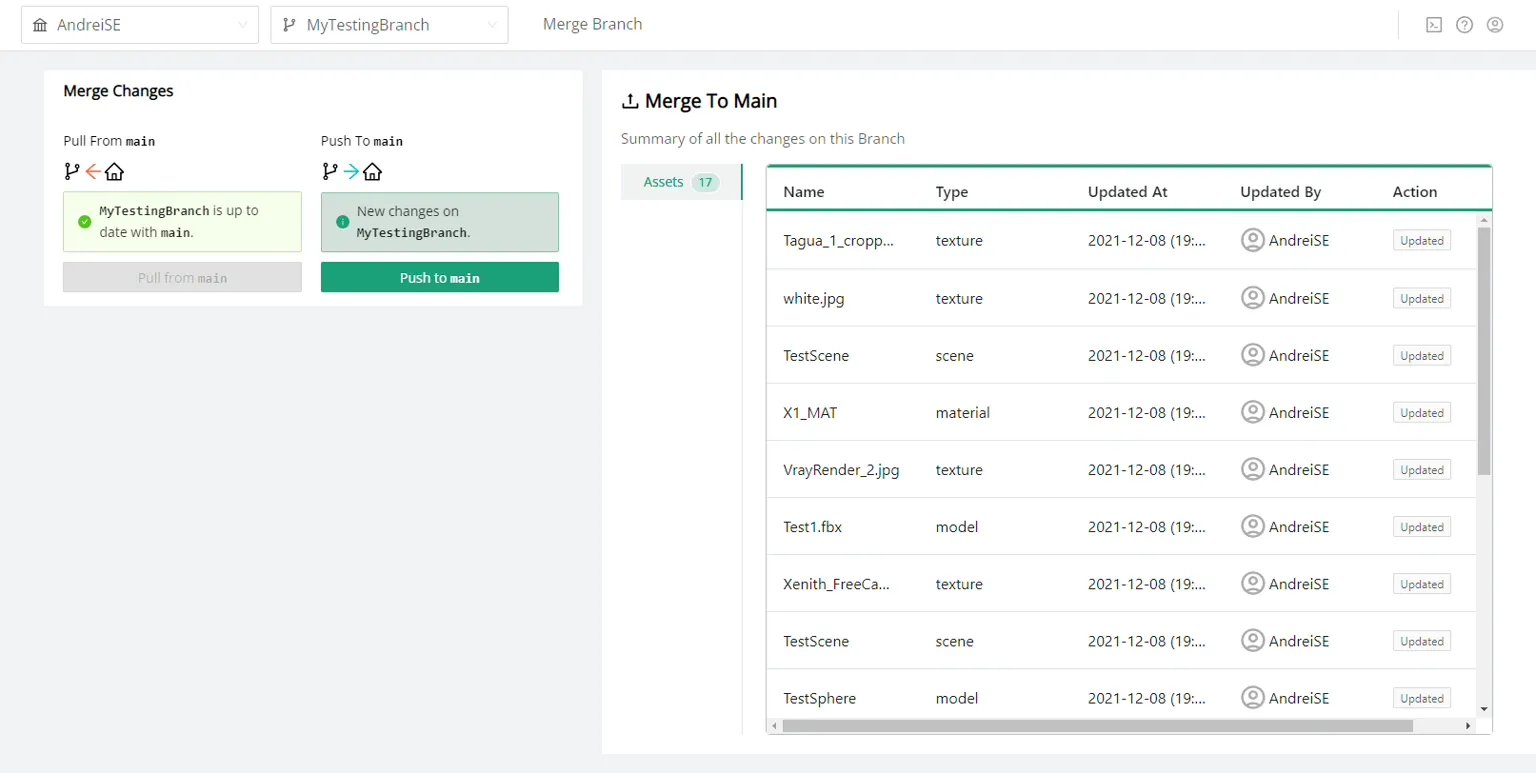
These workflows give Threekit’s customers the ability to develop many parallel changes in isolation, preview their changes before making them live, and ensure that every change gets reviewed before release.
You can read more about Threekit’s use of Dolt in our blog post here.
Data quality control#
In many applications, data exists as low-level entities to be displayed by a beautiful GUI. But sometimes the data is just data: it’s domain-specific configuration that you expect humans to read and understand directly without much intervening software interpretation. Applications that treat their data this way are a special case of a CMS, where the data is being managed much more directly.
Nautobot is a network configuration manager that helps their customers build out large network deployments. Changes to network configuration are critically important, as they can take down entire websites with a single mistake. Nautobot integrated with Dolt to build a branch and merge workflow in their app.
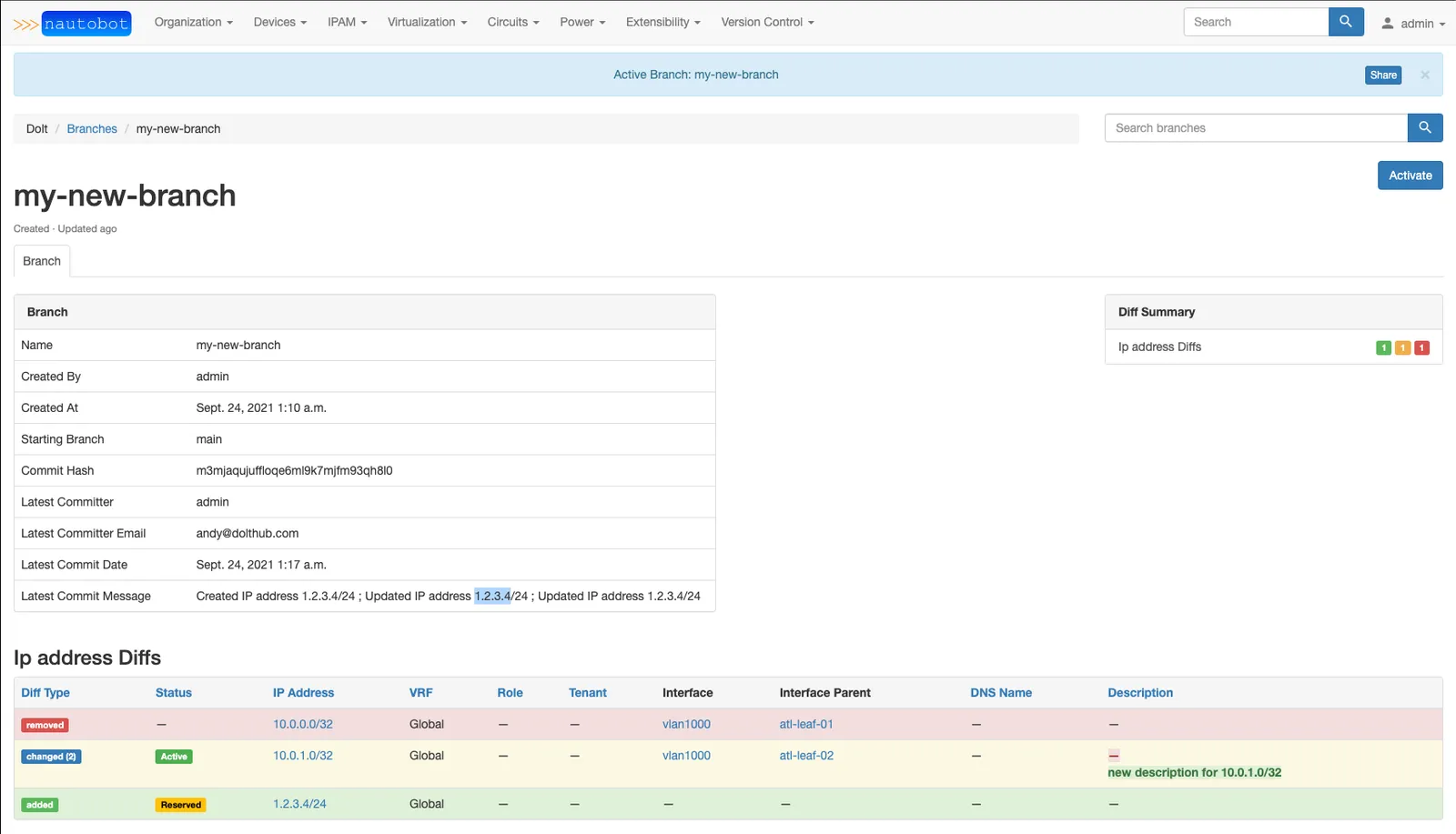
Building on top of Dolt lets Nautobot force all changes to network configuration through human review, which makes it less likely that a catastrophic mistake will slip through. Other version control concepts are useful here as well. It’s possible to compare two revisions of a configuration to see what changed, or to rollback to a known good configuration after an error.
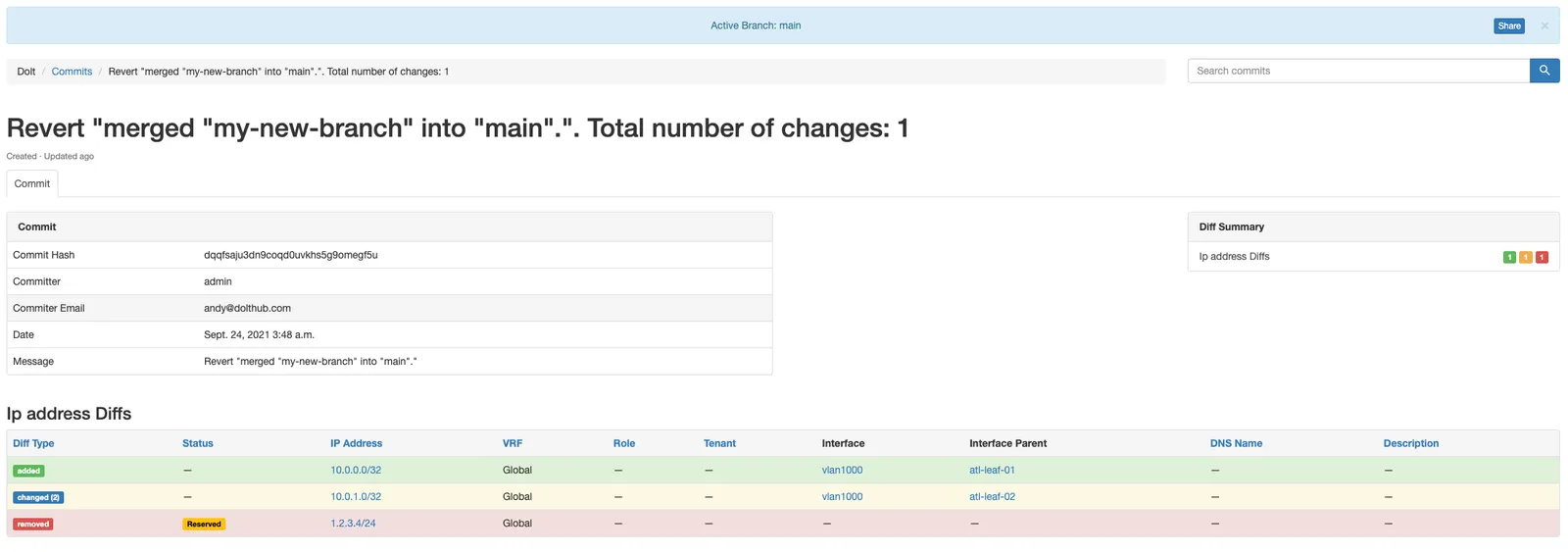
Subjecting data changes to the same quality-control processes as source code makes sense when the consequences of an error can be really bad. Network configuration is one domain where this is obviously true, and we’re sure you can think of many others.
You can read more about how Nautobot integrates with Dolt in our blog here.
Customer use cases we can’t discuss publicly yet, or we think will be big in the future#
We have spoken to many customers using Dolt for other use cases, but who aren’t comfortable with us discussing them publicly. There are also use use cases that we aren’t sure many people are using yet, so it’s harder for us to predict they will be as big as the ones above, but we think they’re interesting enough to share.
Compliance#
Publicly traded companies in the US are subject to the Sarbanes-Oxley act (SOX), which requires firm controls and auditing to prevent systems and data that impact financial data from being tampered with in a way that could mislead investors. Other countries and US states have similar compliance laws that companies must comply with, most of which boil down to a requirement that policies and auditing measures be put in place to ensure that it’s not easy for a single bad actor to tamper with materially significant systems, and that there are ways to detect that they have after the fact.
Dolt can meet a variety of compliance requirements out of the box. For example, you can use it to require that all data changes to sensitive systems are reviewed by another person.
Or for systems that only require audit capability: you get those for free with Dolt. Dolt’s version control ensures that every change to a Dolt database records who made the change, when, and for what reason.
ads/main> select * from dolt_log;
+----------------------------------+----------------+-------------------+---------------------+----------------------------+
| commit_hash | committer | email | date | message |
+----------------------------------+----------------+-------------------+---------------------+----------------------------+
| 76qerj11u38il8rb1ddjn3d6kivqamk2 | Brian Hendriks | brian@dolthub.com | 2024-10-08 01:17:37 | just a little tampering |
| gram7r07nvcfahi0ku1jl0sdm936n9hg | Brian Hendriks | brian@dolthub.com | 2024-10-08 01:16:15 | some impressions |
| 7oen8e22633v11v9p6gpb535r3i9h88u | Brian Hendriks | brian@dolthub.com | 2024-10-07 22:52:09 | Initial Tables and Data |
| l86n1ifds32jb3roirt2nqf08ev4c3up | Brian Hendriks | brian@dolthub.com | 2024-10-07 21:02:36 | Initialize data repository |
+----------------------------------+----------------+-------------------+---------------------+----------------------------+
4 rows in set (0.00 sec)You can read more about the compliance features of Dolt in our blog here.
Golden tables#
“Golden tables” are a term of art for testing and other data-driven processes. The golden tables for a particular application are typically a carefully vetted subset of production data used for experimentation and validation purposes. Running a known process on a known set of golden tables should reliably produce the same result over and over, which allows you to verify your changes aren’t producing any unexpected side effects. Depending on the use case, you might have multiple sets of golden tables that each verify that some stage of a process works correctly, from input all the way to the result data.
Dolt assists in the golden tables use case in a couple different ways:
- Easily pull a snapshot of data directly from production with
dolt cloneat a particular commit or branch, no need to store the golden data separately out of band. - When a process produces unexpected results, run
dolt diffto see exactly how it differs.
You can read more about golden tables and other data engineering concerns in our blog here.
Distributed data collection#
Dolt is the best database to use to build a dataset with other people. To collaborate, each participant clones the database, makes their changes, and requests that they get merged back into the main fork via a pull request.
DoltHub ran a data bounty program for several years where dozens of people collaborated to build over a dozen public datasets. We paid participants for their contributions that got merged.
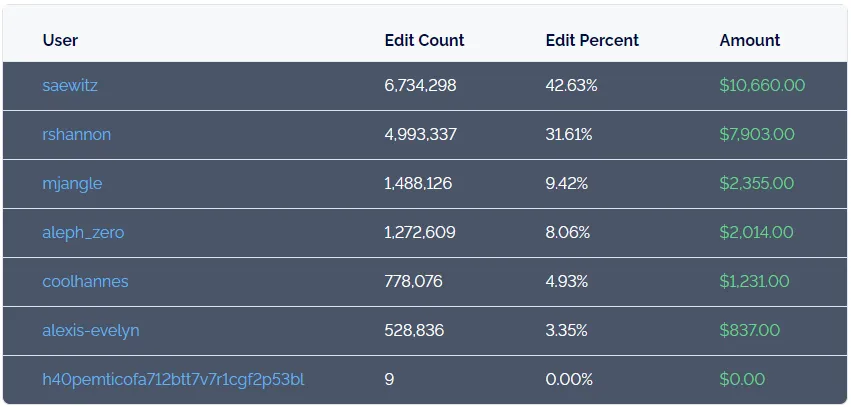
This worked very well, and to our knowledge the program was unique. It proved that the basic process of distributed collaboration with centralized vetting can produce great datasets. We ended our bounty program last year to focus on our core mission of building a database server, but we continue to think that this use case deserves more attention.
Conclusion#
Dolt is still young by database standards, and we expect that people will keep inventing new and exciting things to do with it. Do you have an idea of what you’d do with Dolt that’s not on this list? Come by our Discord and meet our engineering team and other customers.