
Dolt is the first relational database that supports Git-like versioning. Dolt’s content-addressed storage layer plugs into two wire layers, MySQL and now Postgres (DoltgreSQL).
While half of the team works on reaching 100% Postgres compatibility, I continue to chase perf. The topic of today’s blog is our Yacc SQL parser.
Parsing is commonly thought to be an insignificant fraction of query time, but as we’ve made other parts of execution faster, it has crept up to 15% of our small queries:
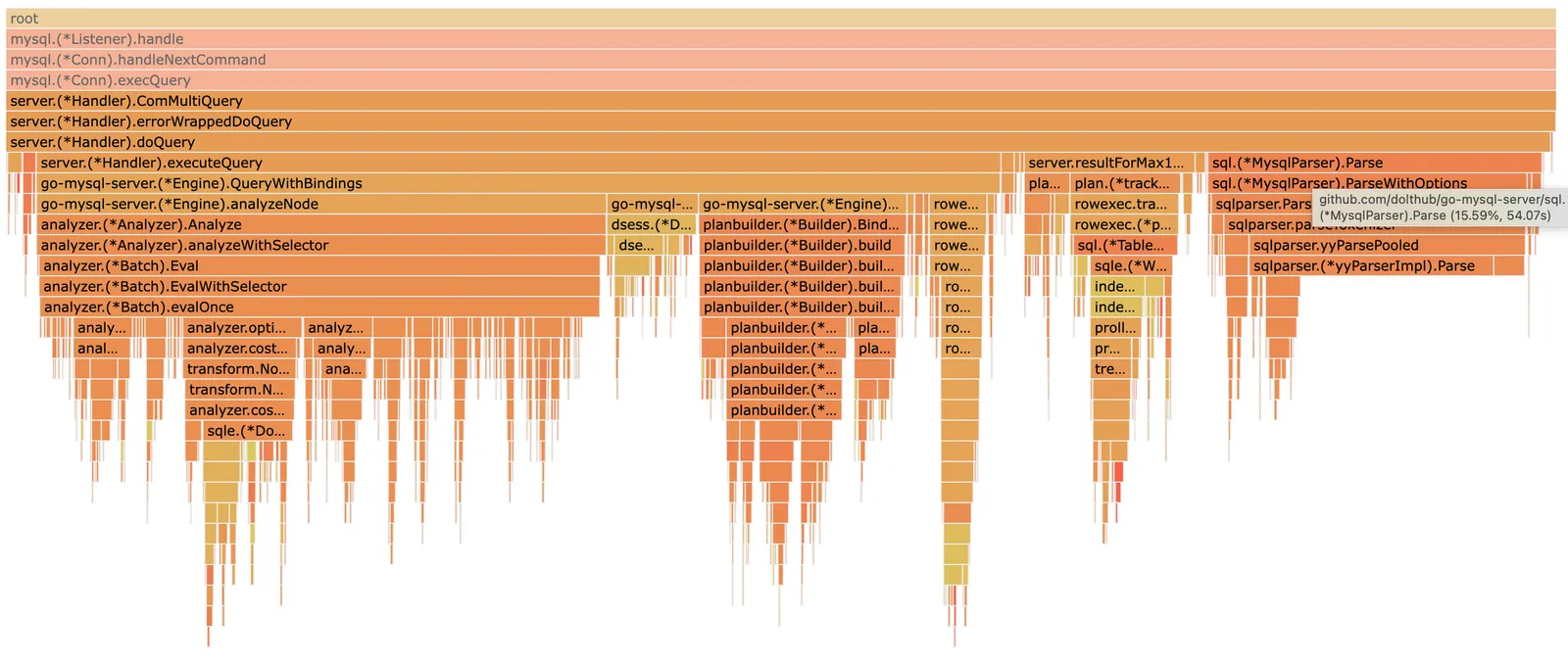
Today’s changes make parsing about 80% faster. On a linux server this translates to about ~30 microseconds of the smallest queries, and ~2% of larger queries with more involved AST structures. Here are a few notable standouts from the sysbench benchmarks:
| benchmark | before (ms) | after (ms) | latency Δ |
|---|---|---|---|
| oltp_point_select | .30 | .27 | -10.% |
| select_random_ranges | .70 | .62 | -11.4% |
| select_random_points | .64 | .61 | -4.9% |
| oltp_read_write | 11.65 | 11.24 | -3.5% |
The sysbench read averages are now nearing +40% slower than MySQL, and write averages -20% faster than MySQL.
TPC-C similarly sees about ~2% improvement on the average query, reflected in the 95% percentile tail latency (p95). Because the bulk of TPC-C queries are small selects and inserts, we’ve gained a 5% boost to the transaction throughput per second (TPS):
| metric | before | after | latency Δ |
|---|---|---|---|
| p95 (ms) | 64.5 | 60.0 | -6.95% |
| TPS | 39.3 | 41.3 | +5.07% |
Background#
Lexing and parsing a query string are the first steps in query planning. Lexing splits a query string into sets of tokens, and parsing builds those tokens into a valid sentence in our SQL grammar as a typed abstract syntax tree (AST).
There are many ways to parse strings, and we will use that variety to better understand Yacc’s bottlenecks.
Recursive descent parsers are state machines that make token-by-token decisions building ASTs from the root node downwards. The state machine below shows how recursive descent appends to the top-level Insert node moving through states. It is worth noting that the parser requires the current and next token to make decisions.
func (p *insertParser) insert() (*Insert, bool) {
// INSERT into_table_name insert_data_alias
nextId, nextTok := p.peek()
if nextId != INSERT {
return nil, false
}
p.next()
ins := new(Insert)
var id int
var tok []byte
var ok = true
for ok && nextId != 0 {
id, tok = nextId, nextTok
nextId, nextTok = p.peek()
switch id {
case INSERT:
switch nextId {
case INTO:
case ID:
ins.Table, ok = p.tableName()
default:
ok = false
}
case INTO:
ins.Table, ok = p.tableName()
case VALUE, VALUES:
var values Values
values, ok = p.tupleList()
ins.Rows = &AliasedValues{Values: values}
default:
ok = false
}
nextId, nextTok = p.next()
}
if !ok {
return nil, false
}
return ins, true
}The rest of the implementations are variations of left-recursive parsing. We still process through tokens from left to right. And we still need a lookahead token for decision making. But state transitions are inverted from top-down to bottom-up. The state machine now alternates between appending leaf tokens to a stack, and “reducing” the stack when the token sequence matches a pattern. “Reducing” is equivalent to a grammar rule, like root -> insert into_table_name insert_data_alias. The logs below show the tail end of a stack reducing an INSERT through the root state after all tokens have been shifted:
reduce stack: (46 *sqlparser.With) (111 string) (1059 sqlparser.Comments) (1596 string) (2403 sqlparser.TableName)(3228 *sqlparser.Insert)
shift stack: (46 *sqlparser.With) (111 string) (1059 sqlparser.Comments) (1596 string) (2403 sqlparser.TableName) (3228 *sqlparser.Insert) (3599 sqlparser.AssignmentExprs)
reduce stack:
shift stack: (6 *sqlparser.Insert)
reduce stack:
shift stack: (2 *sqlparser.Insert)
reduce stack:
shift stack: (1 *sqlparser.Insert)Comparing Parsers#
The chart below benchmarks ablation tests that help us understand where parsing time is spent.
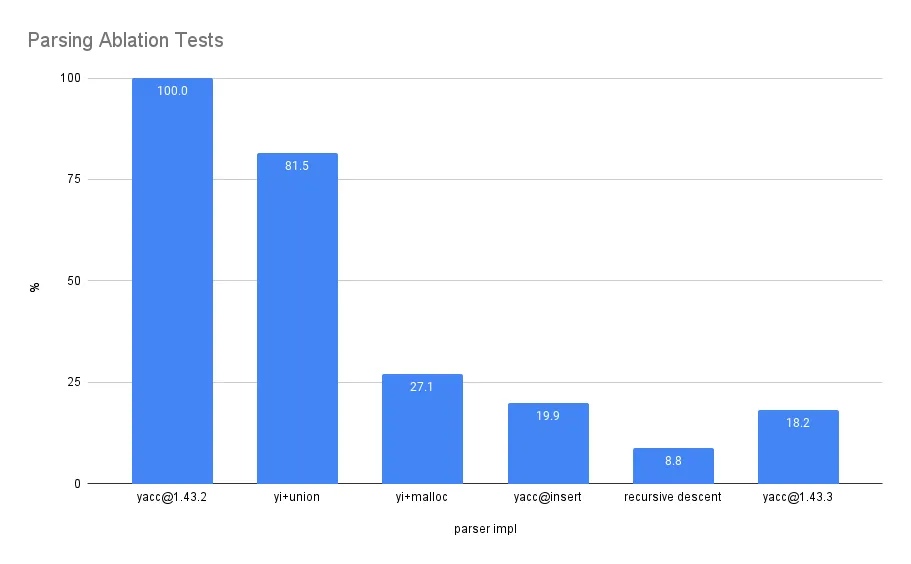
The difference between the first two bars, yacc@1.43.2 and
yacc@insert+union (yi+union), simplifies
the number of rules needed to reduce an insert statement, holding all other
data structures equal. We label this
“fewer rules” in the latency breakdown plot below.
Editing the union type used in the left-recursive parser stack is responsible for the change
between yi+union and yi+malloc. The default union type is a
145-field, 2096 byte object that Yacc uses to safely type
arguments and return values in reduction rules:
type yySymType struct {
yys int
empty struct{}
statement Statement
selStmt SelectStatement
ddl *DDL
ddls []*DDL
ins *Insert
...
// 145 type fields
}Each stack object only sets one type field, and the
yacc@insert parser only needs ~10 types to parse an INSERT. We name
this fraction of latency “duffcopy” in the breakdown below, which is how
Golang’s runtime copies arguments between memory and the stack to call
reduction rules.
yacc@insert further removes the union type malloc calls, which were
added back in the previous tests for consistency (“malloc”).
Next, we assume the difference between a minimally left-recursive stack and recursive descent is the stack organization and jumps (“stack”).
And finally, CPU profiles suggest most of the remaining portion of parsing is divided between lexing (“lexing”) and field serialization (“strconv”).
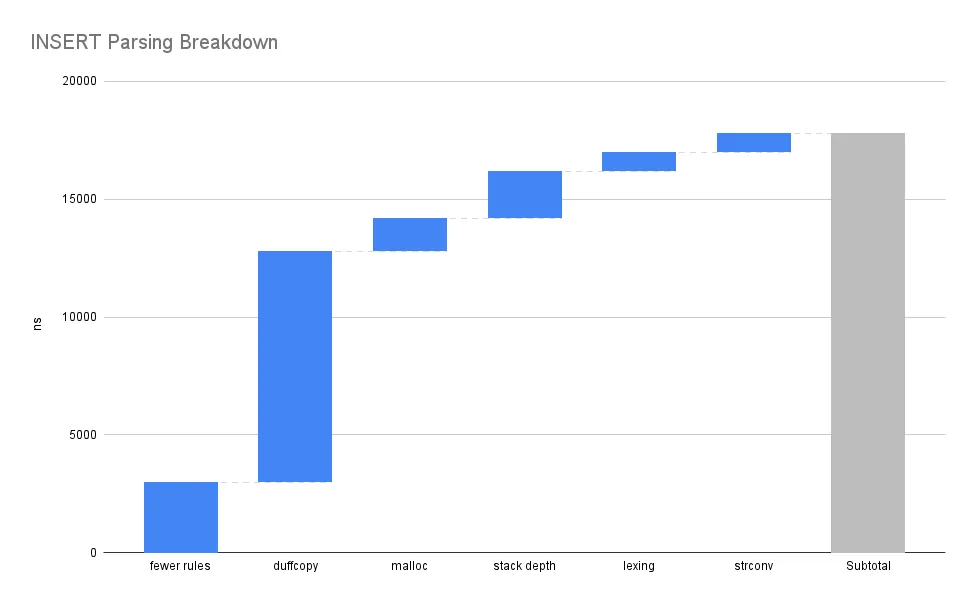
yacc@new#
Rather than copying 2096 byte objects during reductions, we can use a Go interface{} as a union type:
type yySymType struct {
yys int
val interface{}
}An interface{} is roughly composed of two parts: an underlying type, and a ref to a heap object. This takes more stack space than a built-in type, and forces the object into the heap. But in return we get much smaller objects (40 bytes).
We wrote a conversion script that inputs our original Yacc file, and outputs a file with static type conversions for the common interface type.
The conversion looks something like below:
tuple_list:
tuple_or_empty
{
$$ = Values{$1}
}
| tuple_list ',' tuple_or_empty
{
$$ = append($1, $3)
}
=>
tuple_list:
tuple_or_empty
{
$$ = Values{$1.(ValTuple)}
}
| tuple_list ',' tuple_or_empty
{
$$ = append($1.(Values), $3.(ValTuple))
}The original compiler inserted static typed access (yyVAL = Values{yyDollar[1].ValTuple}), and now the conversion is a runtime cast (yyVAL = Values{yyDollar[1].val.(ValTuple)}). The tradeoff introduces opportunities for casting exceptions, which we have to add safety checks for.
The result is not as fast as recursive descent, but it is still pretty good! Here is a before/after parsing a small INSERT query on my laptop:
BenchmarkParser-12 64779 18577 ns/op
BenchmarkParser-12 316268 3322 ns/opAnd similarly for parsing a SELECT query:
BenchmarkParser-12 64779 18577 ns/op
BenchmarkParser-12 399688 2822 ns/opIn the future we can potentially do better with recursive descending some query paths. But for now we’ve reclaimed 12% of the 15% of runtime we originally focused on. And even with recursive descent, it seems like we would bottom out at halving that 3% of remaining parse time.
Summary#
We transitioned our Yacc parser from statically union typed stack objects to runtime-casted interface types. The change removes about 80% of parsing overhead. The effect is noticeable for small queries, but even longer running joins benefit from a ~2% latency improvement.
We are approaching in-memory read/write parity with MySQL, and look forward to publishing our next update!
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!