
We built Dolt and DoltHub for data sharing. These products were our answer to the question, “Why is there no place on the internet to get access to interesting, maintained data?” A few other people answered the question at about the same time but Dolt and DoltHub are the only products to truly embrace the Git and GitHub for data vision.
The best example of open data on DoltHub is the user post-no-preference. He publishes US stock market data daily. He publishes stocks, options, earnings, and rates databases. He’s been doing this since April 2021.
The databases are extremely popular, garnering tens of thousands of monthly views combined. Why does post-no-preference publish data on DoltHub? How do you use the data? This article has the answers and more.

Motivation#
I’ll hand post-no-preference the microphone for this one because he knows his community better than I do.
Within the hobbyist trading community, there is lots of interest in leveraging sophisticated tools or creating your own, integrating with broker APIs, and trying to make sense of the markets. Usually, hobbyist traders come to the realization that in order to leverage these tools and apply their trading ideas, they need data. In crypto markets and forex, much of this data is available for free from the exchange/brokerage. In traditional securities markets, this data is tougher to come by, especially if you’re interested in history. After getting a sense that many hobbyist traders want a starting point with financial data, I decided to publish some databases that can hopefully be helpful.
Before DoltHub#
post-no-preference was already sharing this data using Dat before DoltHub existed. Dat had some deficiencies. “The data published to Dat was just daily CSVs” and “querying for particular data was not possible”. Moreover the frontend, datbase.org, “was often broken” and “was being deprecated”. post-no-preference wanted a better way.
Why DoltHub?#
Why did post-no-preference choose DoltHub to share his stock market databases? DoltHub is a free service with built-in SQL functionality. It was a natural place to post this type of data and post-no-preference didn’t mind being an early adopter.
Many developers interact with RDBMSs and DVCSs every day, but, as far as I know, Dolt is the only place where they are blended together to give you MySQL wire compatibility, equivalents for GitHub and GitLab, a similar pricing model to GitHub where public data is shared for free, web-based querying, etc. The Dolt offerings are remarkable, they continue to get better, and I don’t think I’ve really made use of most of their features.
Free#
DoltHub is free for sharing public databases. Users can use the data and clone without an account. The low barrier to entry means shared data is truly open and accessible to all.
SQL#
Dolt is the world’s first version controlled SQL database. It is MySQL-compatible. The native SQL support is a great fit for relational data like that found in stock market data.
DoltHub offers the ability to do read and write queries online, making data analysis easy. The online query feature allows for linking to specific query results, enhancing the online collaboration experience.
Online querying has always been a big draw for me. At first querying on DoltHub would only work for small queries but the Dolt team has made a ton of progress on performance and now most queries return without needing to clone.
Clones#
If you want to grab the data locally to work offline, join with other data, or run complex queries, DoltHub offers the ability to clone, push, and pull. Pull only syncs the data you don’t have. Dolt is the only database with Git-style clone, push, and pull. DoltHub is Dolt’s GitHub.
Community Collaboration#
Dolt and DoltHub have a large community of maintainers and users to provide community database support. The following is an example of a user question we get every couple months.
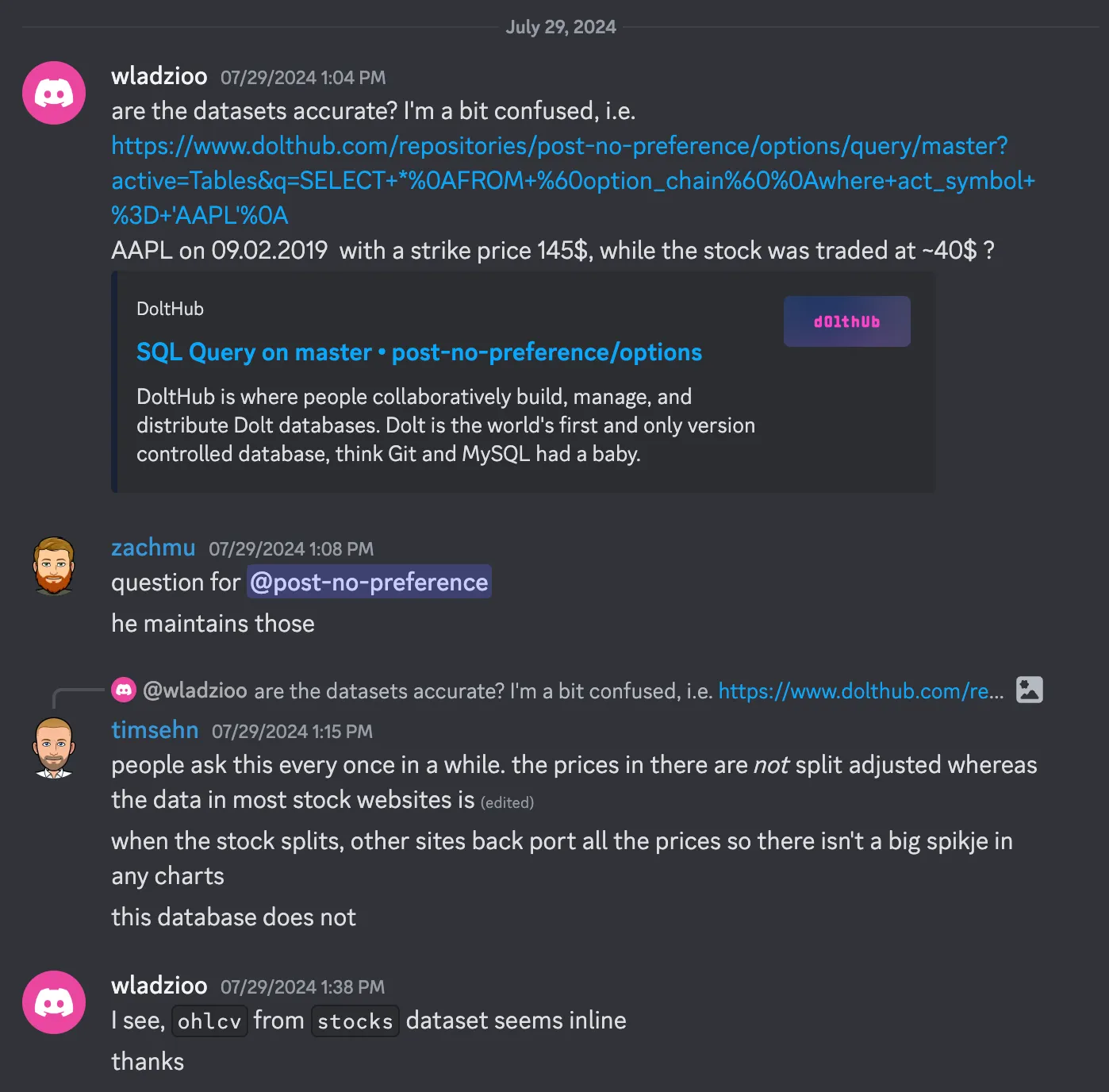
post-no-preference isn’t as available as the Dolt maintainers so we field questions for him when we can. This increases the popularity of the database because users get answers to their questions quickly, night or day.
Moreover, there is write collaboration on the databases. One user wanted to add an index to the stocks database and made a pull request. Unfortunately, this caused write amplification due to the way Dolt stores index history. So, the change was backed out. However, this is a good example of the style of open data collaboration common with source code on GitHub.
Example#
Let’s walk through an example of how to use these databases. We’ll use the stocks database.
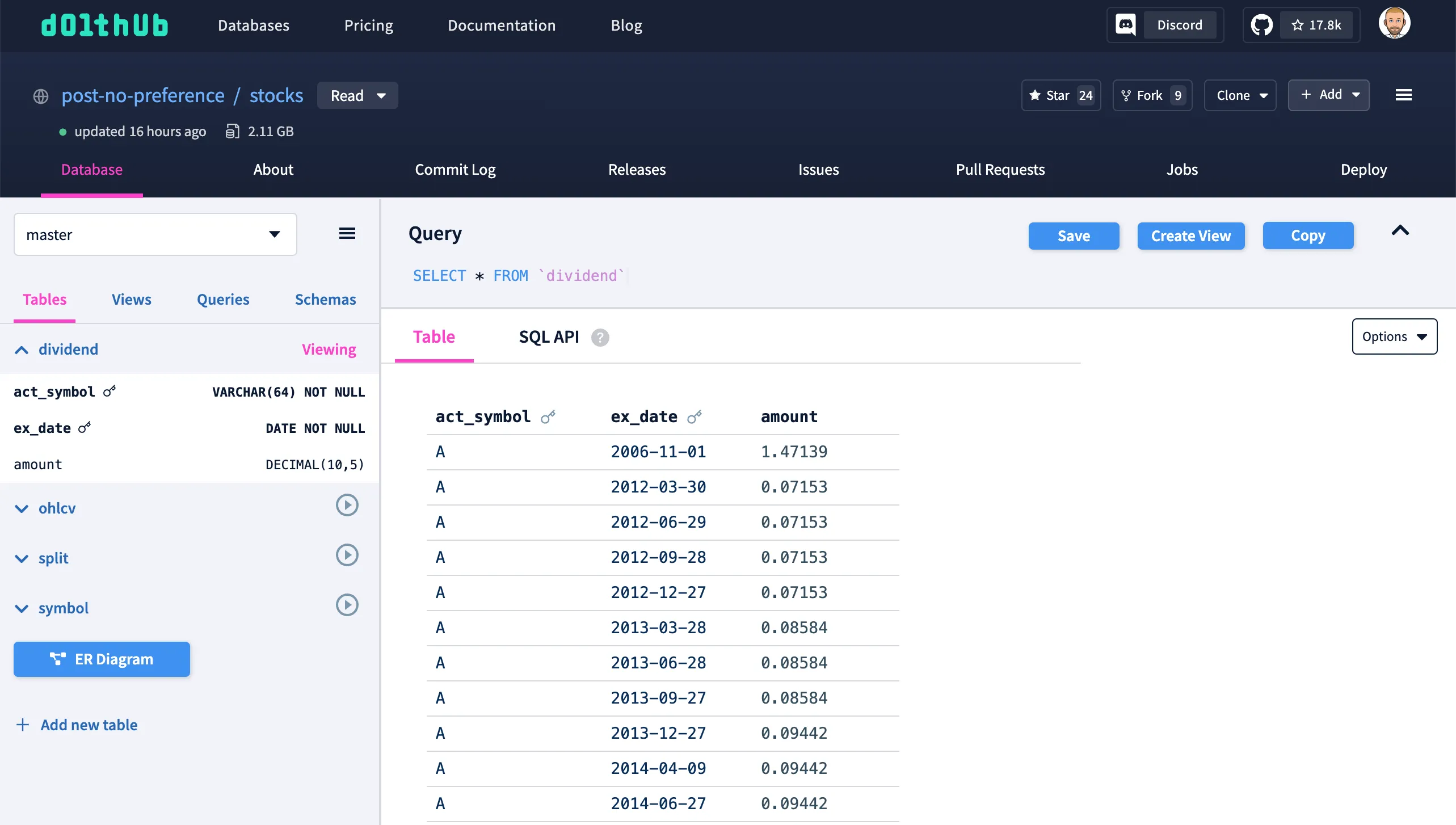
Let’s find the closing prices for Oracle stock since September 17, 2024. Oracle are the owners of MySQL, our beloved SQL language and wire protocol. We can just write the SQL query in the query box and click the “play button” to execute it. If you click on the image below, you’ll be taken to the query results page on DoltHub. You can hyperlink to query results!
The stock market has been on a bit of a tear lately. Let’s count all the stocks that have traded at an all time high in the past 7 days. This is going to be a complex group by query so I’ll want to clone the stocks database locally or run the query as a job on DoltHub and get the results as a CSV. Let’s clone the database locally.
$ dolt clone post-no-preference/stocks
$ cd stocksNow I have the data locally and I have the full power of the Dolt command line and SQL. Let’s run the query using dolt sql -q.
$ dolt sql -q "SELECT act_symbol, date, max(high) as max_price FROM ohlcv group by act_symbol having date >= '2024-09-17' and high = max(high)"
+------------+------------+-----------+
| act_symbol | date | max_price |
+------------+------------+-----------+
| BLEUU | 2024-09-18 | 10.91 |
| DYCQR | 2024-09-20 | 0.25 |
| ZVV | 2024-09-20 | 24.51 |
| AVK.R | 2024-09-23 | 0.18 |
| CAPNU | 2024-09-23 | 10.01 |
| DTSQ | 2024-09-23 | 10.00 |
| DTSQR | 2024-09-23 | 0.14 |
| EONR | 2024-09-23 | 1.20 |
| EONR.W | 2024-09-23 | 0.09 |
| GLE | 2024-09-23 | 5.16 |
| GMMA | 2024-09-23 | 20.17 |
| HPE$C | 2024-09-23 | 57.09 |
| JMID | 2024-09-23 | 25.49 |
| KLTO | 2024-09-23 | 0.85 |
| KLTOW | 2024-09-23 | 0.04 |
| LIVR | 2024-09-23 | 25.60 |
| MSTU | 2024-09-23 | 32.96 |
| MSTZ | 2024-09-23 | 19.85 |
| NEWTH | 2024-09-23 | 25.20 |
| PATN | 2024-09-23 | 20.58 |
| RFLR | 2024-09-23 | 25.51 |
| RSSE | 2024-09-23 | 19.97 |
| SBC | 2024-09-23 | 6.14 |
| SBCWW | 2024-09-23 | 0.15 |
| SCNX | 2024-09-23 | 7.99 |
| SEPM | 2024-09-23 | 29.87 |
| TSEP | 2024-09-23 | 20.07 |
| VEEA | 2024-09-23 | 12.00 |
| VEEAW | 2024-09-23 | 0.27 |
| YHNAU | 2024-09-23 | 10.02 |
+------------+------------+-----------+This is fewer than I expected as this database contains almost 16,000 symbols.
$ dolt sql -q "select count(distinct(act_symbol)) FROM ohlcv"
+-----------------------------+
| count(distinct(act_symbol)) |
+-----------------------------+
| 15916 |
+-----------------------------+I guess the stock market hasn’t been on that much of a tear recently, at least from an all time high perspective.
As you can see, you get the full power of a SQL database online or locally with a quick and easy clone. As new data is added, you simply dolt pull to grab the latest. The ease of the workflow is a “Wow!” experience.
More Open Data Sharing?#
How do we find and encourage more post-no-preference types to share open data? Some other users are publishing but we’re yet to hit critical mass. We tried data bounties to get novel data on DoltHub but it ended up being a distraction from our core database mission. What else can we do?
More incentive to share#
Recently, we released user profile badges.
We can imagine even more ways to spruce up the user profile page like a GitHub style activity chart. But, I think we need to work on the core value proposition first. Code is fun to write. Wrangling data is…less fun.
Better tooling#
Quietly, since we launched DoltHub we’ve been adding more functionality to DoltHub jobs. We started with imports and later added merges and queries.
We have some exciting additions here like customizable integration testing on Pull Request. Think hand written data tests that run every time a Pull Request is opened. We also think an import style job that triggers on a timer could be very useful. Maintaining a workflow engine is tough and GitHub actions provide hosts too small in disk to hold most Dolt databases.
Just know, we haven’t abandoned the open data mission and we’ll continue to improve tooling to see if that spurs more sharing.
Your ideas?#
Do you have any other ideas on how to get more data shared on DoltHub? Come by our Discord and let’s chat about it. Or, just skip talking to us and start publishing dammit!
Conclusion#
I’ll close with post-no-preference’s Dolt recommendation because it encapsulates a lot of what Dolt is all about.
If you’ve ever wanted to share relational data with random people on the internet, you should check out Dolt. If you ever wondered why it’s a headache to do personal development with a dev database that is separate from staging and production databases, you should check out Dolt to see if that could simplify your workflow. If you never drank the Kool Aid for NoSQL databases but still wanted to keep up with the state-of-the-art for databases, you should check out Dolt.
post-no-preference is a hero here at DoltHub. His US stock market databases are very popular. We’d love to host a million more users like post-no-preference. Are you one of them? Start sharing your databases on DoltHub today for free.