PostgreSQL's COPY Protocol

We're excited to announce that you can now import tabular data files into Doltgres using the COPY ... FROM STDIN statement. In this blog post, we'll examine how the PostgreSQL wire protocol supports importing bulk data, look at how we implemented the protocol in Doltgres, and see some example usage.
DoltgreSQL
We'll be examining the Postgres COPY wire protocol in the context of DoltgreSQL – a version-controlled relational database built to be compatible with PostgreSQL. In addition to building Doltgres, we also build Dolt, a production-quality relational database that combines the version control model of Git with the relational data syntax of MySQL. Dolt lets you branch, fork, merge, and diff your relational data using the same model as Git, as well as using efficient data structures in the storage layer inspired by Git. Lots of customers have been asking for a Postgres flavor of Dolt, so we've been hard at work building Doltgres to meet that need. Doltgres is currently in Alpha, and we're moving steadily towards a Beta release in Q1 2025.
PostgreSQL COPY Wire Protocol
PostgreSQL uses a simple and efficient wire protocol for sending and receiving bulk data with the COPY FROM and COPY TO statements. To show one way this protocol gets invoked, here's a simple example of some content from a SQL file that uses Postgres' COPY statement to load in three rows from STDIN:
BEGIN;
CREATE TABLE t (pk INT PRIMARY KEY, c1 VARCHAR(255));
COPY t FROM STDIN;
1 uno
2 dos
3 tres
\.
COMMIT;If this file is named dataload.sql, you can use the psql command line to load the data into a PostgreSQL database like this:
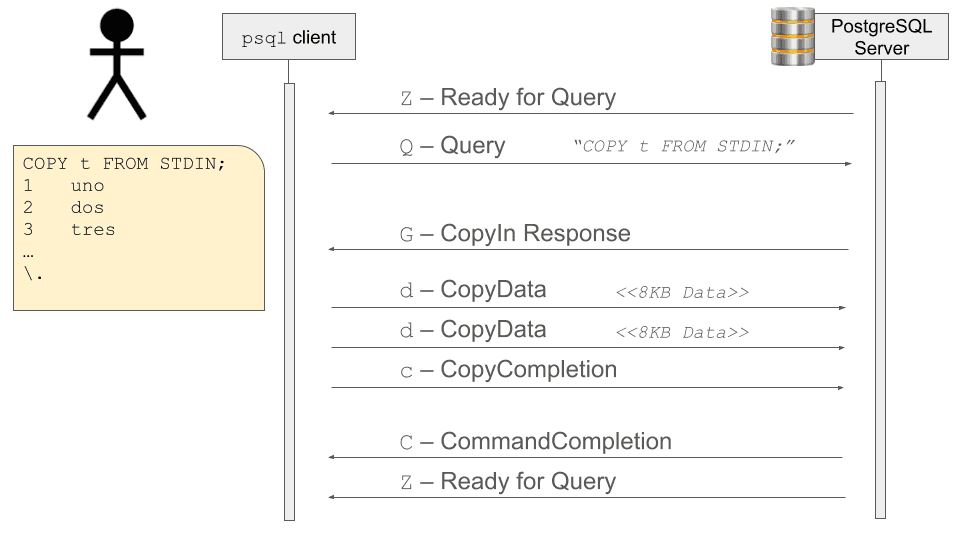
psql -U <db_user> -h <db_host_name> -d <db_name> -f dataload.sqlThe psql client parses out the statements in the SQL file and sends each of the first three statements as Query messages to the PostgreSQL server. When psql processes the COPY ... FROM STDIN statement, the server sends back a message telling the client that the server is now in "copy-in" mode. When the client is in this mode, instead of sending the next lines in another Query message, it'll chunk up the data and send it as a series of CopyData messages then let the server know it's done sending data by sending a CopyDone message. If something happens and the client encounters an error while sending the data, it'll send a CopyFail message to the server to let it know that the copy operation failed. You can read more details about the COPY messages from the Postgres wire protocol in the official PostgreSQL docs.
Here's a visual representation of the sequence of messages between the client and server when using COPY FROM STDIN:
Performance Testing COPY ... FROM STDIN
There are several ways to import data into a PostgreSQL database using SQL statements. The COPY statement has a few advantages that make it faster than other methods. For a concrete performance comparison, let's look at two ways to format the data in a SQL file that is executed by psql to load the data into our PostgreSQL 15 database. In the first approach, we use INSERT statements to load the data. We batch 500 rows at a time in each insert statement, so that means we execute 16 INSERT statements to load 8,000 rows. In the second approach, we use COPY FROM STDIN to include the same 8,000 rows as tab-formatted data directly in the SQL file.
I tested both of these approaches on my 2021 MacBook Pro M1 Max laptop. I ran psql and Postgres on the same machine, so no network latency was involved. I ran each of the SQL files three times and took an average of the total execution time against PostgreSQL 15 and Doltgres. Each row consisted of two varchar fields, and one auto-generated SERIAL field for the primary key.
For PostgreSQL, loading 8,000 rows using 16 INSERT statements took, on average, 0.109s. Loading 8,000 rows using COPY FROM STDIN took, on average, 0.064s. So, using COPY FROM STDIN was about 41% faster than using INSERT statements with PostgreSQL 15 in this example.
For Doltgres, loading 8,000 rows using 16 INSERT statements took, on average, 0.136s (24% slower than importing the data with INSERT statements via PostgreSQL 15). Loading 8,000 rows using COPY FROM STDIN took, on average, 0.085s (32% slower than using COPY FROM STDIN with PostgreSQL 15). Similar to the results we saw with PostgreSQL, using COPY FROM STDIN instead of INSERT statements was also faster with Doltgres – about 37.5% faster. It's worth noting that although the Doltgres results are slower than the PostgreSQL results, they are in the same ballpark and as we continue developing Doltgres, we'll be working to improve performance across the board.
For reference, or if you'd like to rerun these tests on your own machine, you can find the INSERT SQL file here and the COPY FROM STDIN SQL file here.
As we can see from the simple test above, using COPY FROM STDIN, instead of INSERT statements, allows you to bulk load data much more efficiently. Why is COPY FROM STDIN faster though? The first big performance win is that the client can batch records together in larger chunks and send them to the server without waiting for a response before sending the next batch. This allows the client to very efficiently send the data over the wire. This is different from our INSERT example, where the client sends one INSERT query, then waits for the server to process it and send back a response before the client sends the next INSERT query. Clients can mitigate some of this overhead by batching many rows together in a single INSERT statement, but it's still not as efficient as COPY FROM STDIN. The second big performance win is that the server has much less work to do in the COPY FROM STDIN case. With the INSERT statements approach, the server must parse the SQL statement then build (and optimize) an execution plan for it. This is a good amount of work, and when hundreds of rows have been included in each INSERT statement, it results in a longer statement to parse, which means the server is copying more data into memory to parse and process it. Compare this to the COPY FROM STDIN approach, where the server does not need to use an expensive SQL parser, and instead, simply needs to parse tab formatted data, which is an order of magnitude simpler. PostgreSQL can parse these rows very quickly, without having to load more than a single row into memory at once, and then it uses an optimized code path to insert the data into the table files.
Implementation Notes
The only potentially tricky part of implementing this protocol is to remember that there is no requirement for CopyData messages to start and end cleanly on row boundaries. This means the first CopyData message the server receives could end right in the middle of a row, and the next CopyData message would start right in the middle of that same row. Implementors must keep this in mind, otherwise row data won't be copied correctly. In our implementation in Doltgres, we recognize when a partial line has been received and then we store that data in memory until the next CopyData message is received from that connection. At that point, we have a partial line from the previous message and we prepend it to the first line of the current message, and clear the partialLine field. For tabular data, this processing is very easy, since every row is guaranteed to be on a single line. For CSV formatted data, the parsing gets a bit trickier since a row can span multiple lines and there are other escaping and quoting rules to consider.
Doltgres Support for COPY ... FROM STDIN
Now that we know how the PostgreSQL COPY ... FROM STDIN protocol messages work, let's see it in action with Doltgres.
If you don't already have Doltgres installed on your system, you can download the latest release from GitHub, then put the doltgres binary on your path, and invoke doltgres to start up the server. If you need help running doltgres for the first time, head over to the Doltgres Getting Started Guide for more information.
Once you've got Doltgres running, we can use psql to execute a file containing a COPY ... FROM STDIN statement. Here's a sample SQL file that we'll use to load some data into a table in Doltgres:
BEGIN;
CREATE TABLE Regions (
id SERIAL UNIQUE NOT NULL,
code VARCHAR(4) UNIQUE NOT NULL,
capital VARCHAR(10) NOT NULL,
name VARCHAR(150) UNIQUE NOT NULL
);
COPY regions (id, code, capital, name) FROM stdin;
1 01 97105 Guadeloupe
2 02 97209 Martinique
3 03 97302 Guyane
4 04 97411 La Réunion
5 11 75056 Île-de-France
6 21 51108 Champagne-Ardenne
7 22 80021 Picardie
8 23 76540 Haute-Normandie
9 24 45234 Centre
10 25 14118 Basse-Normandie
26 94 2A004 Corse
\.
COMMIT;Download the bonjour-doltgres-copy-from-stdin.sql file and then run it with psql to import the data into your running Doltgres server. Note that the default data format for COPY ... FROM STDIN is tab-delimited data, so make sure the whitespace between fields is a single tab character and not individual spaces. If your input file doesn't use tabs, then neither PostgreSQL and Doltgres will be able to parse out the tab-separated values correctly.
psql -h localhost -U doltgres -f ~/Downloads/bonjour-doltgres-copy-from-stdin.sql.txtIf you have any problems running the sample script above, double check that you have tabs, and not spaces, between record values, as explained above.
When you run the command above, you should see this output:
BEGIN
CREATE TABLE
COPY 11
COMMITWe can log into a SQL session on the Doltgres server by running psql -h localhost -U doltgres. From there we can verify that the data was correctly loaded into our regions table:
doltgres=> select * from regions order by id asc;
id | code | capital | name
----+------+---------+-------------------
1 | 01 | 97105 | Guadeloupe
2 | 02 | 97209 | Martinique
3 | 03 | 97302 | Guyane
4 | 04 | 97411 | La Réunion
5 | 11 | 75056 | Île-de-France
6 | 21 | 51108 | Champagne-Ardenne
7 | 22 | 80021 | Picardie
8 | 23 | 76540 | Haute-Normandie
9 | 24 | 45234 | Centre
10 | 25 | 14118 | Basse-Normandie
26 | 94 | 2A004 | Corse
(11 rows)Wrap Up
PostgreSQL's COPY statement is critical for efficiently getting data in and out of a PostgreSQL database. We're excited to have initial support for loading tabular data into Doltgres so that customers can more easily test out Doltgres. We're continuing to expand on COPY features and adding support for loading CSV-formatted data next. Doltgres is still a Alpha product, but we're making steady progress every day. If there's a missing feature you need, or if you just have some feedback or questions for us, please open up a GitHub issue on the Doltgres repo. We prioritize our work based on what customers are asking for, and we love to squash bugs and implement features FAST! ⚡️
If you want to connect directly with our development team and with other Dolt or Doltgres customers, come join us on Discord! We'd love to chat with you about databases, golang, and the many, many uses of version-controlled data! 🚀