
Dolt is MySQL-compatible. When data engineers hear “MySQL”, they think “this is not for me”. Data engineers work with “Big Data” in databases like Databricks or Snowflake. MySQL is not for big data.
In database parlance, Snowflake and Databricks are Online Analytical Processing (OLAP) databases. MySQL and Dolt are Online Transaction Processing (OLTP) databases. We would not recommend replacing your Databricks or Snowflake installation with Dolt.
But we do recommend using Dolt’s Git-style version control functionality to augment Snowflake or Databricks. Dolt can be used as a Data Staging Area to test and review data before it ever gets to your warehouse. Dolt can also be used to version your “Gold Tables”, saving time and effort ensuring the data in them is perfect. This blog will explain how.
Data Quality Control#
This blog will be a bit of a remix on my classic Data Quality Control opus. In that article, I explain the evolution of the analytics data stack at most companies, the data quality problems that arise over time, and how data quality processes and tools are adopted and evolved. It’s a long read but it’s one of our “greatest hits” and well worth it if you’re a data engineer interested in data quality.
I build up to the following image of a common data platform at many companies. In this model, data quality is an extra function performed by the analytics engineers at the company.
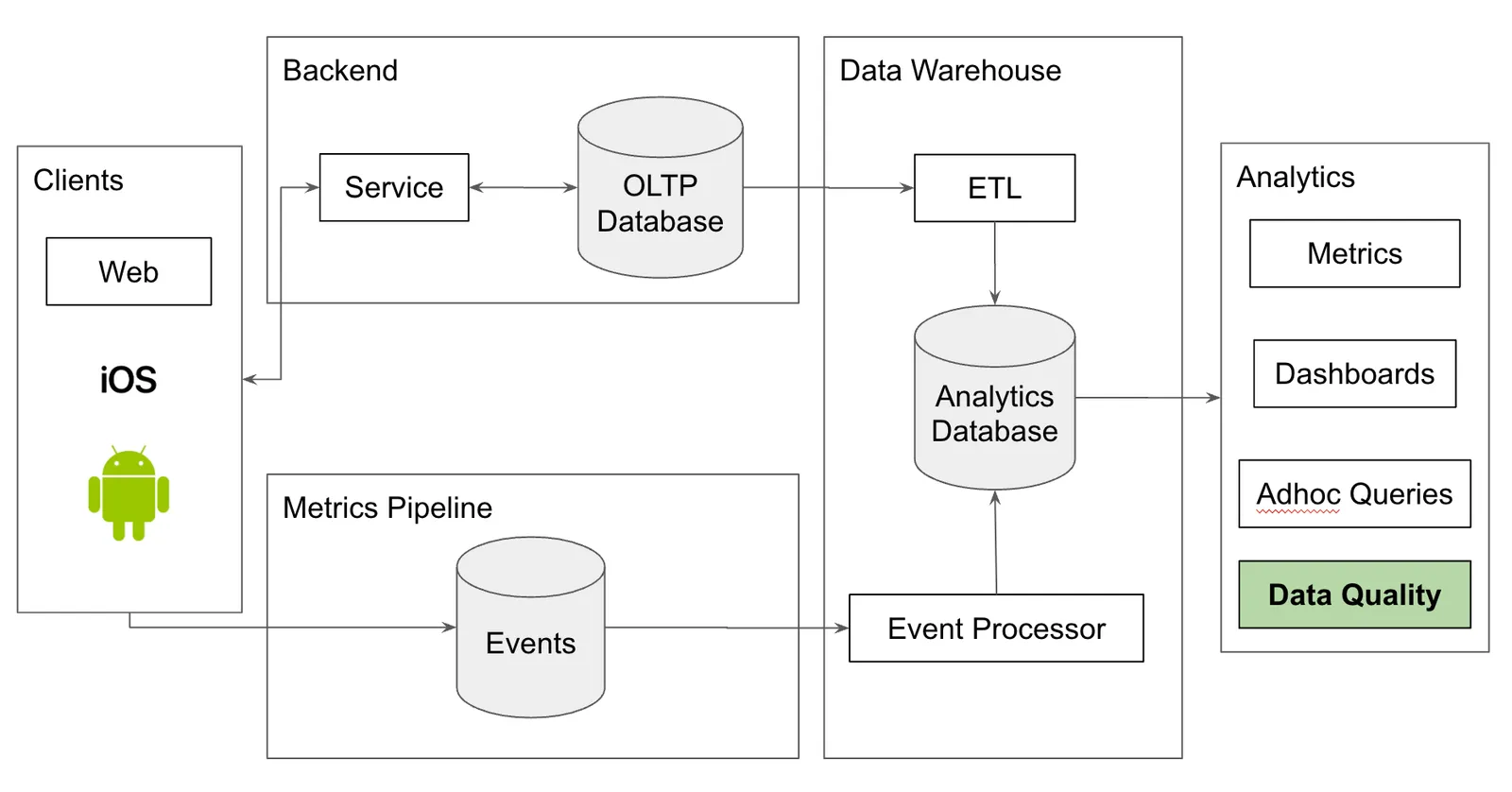
In the article I suggest a model augmentation. Use data testing and versioning tools, including Dolt, to surround your analytics database. Before data gets into your warehouse, use human review and continuous integration testing in a data staging area. For your Gold tables, use version control to save time reviewing the data to make it perfect.
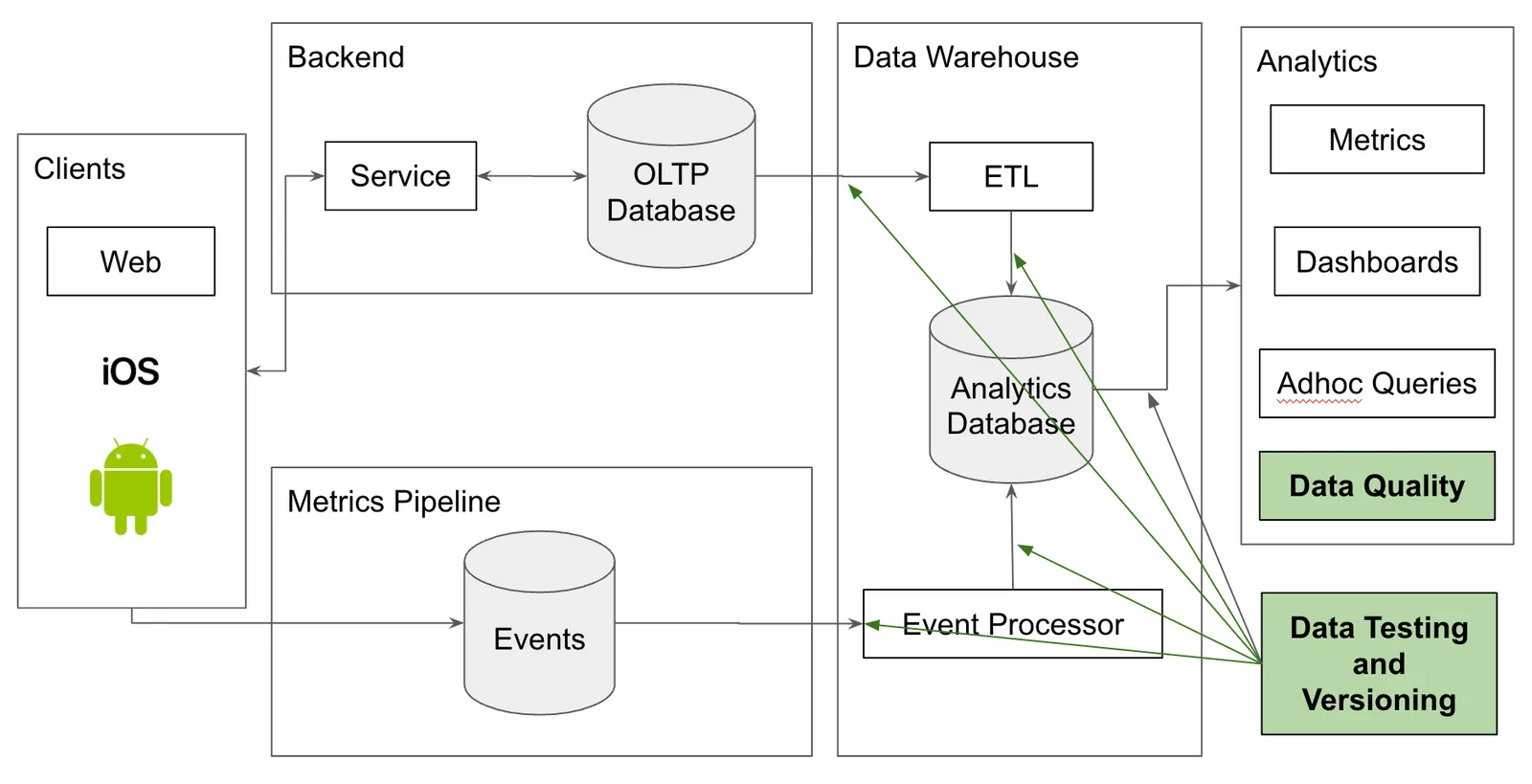
The Data Quality Control blog is light on details of how you would pull these two ideas off in practice. So next, I’ll dive into more specific details of both the data staging area and version controlled gold tables.
The Data Staging Area#
Automated testing and human review of data streamed from various sources in a data staging area improves data quality before it ever gets to the data warehouse.
For code, data engineers are used to Git workflows. Proposed code changes are made on a branch, isolated from production code. The code changes are then pushed to a central repository hosted by GitHub or GitLab. A Pull Request is made asking to merge the proposed changes to the production code. This Pull Request triggers a number of continuous integration tests that must pass before the code is merged. Additionally, humans can review what’s changed and add an extra layer of audit to make sure changes are good. Once all tests and review phases are complete, the code is merged to production. If the merge turns out to be bad, Git offers powerful revert and reset functionality to back the changes out.
We now have the technology to facilitate this process on tabular and JSON data using Dolt, the world’s first version controlled database. Dolt can be used as a data staging area. Dolt combined with DoltHub or DoltLab can provide Pull Requests and continuous integration on streamed data. Merging good, reviewed data is then data streamed into the warehouse. If changes made are faulty, the staging area can revert the changes and the bad changes will be reverted in the warehouse. These powerful capabilities meaningfully improve data quality and turn bad change recovery from a multi-day effort to a simple revert accomplished in minutes.
Implementation#
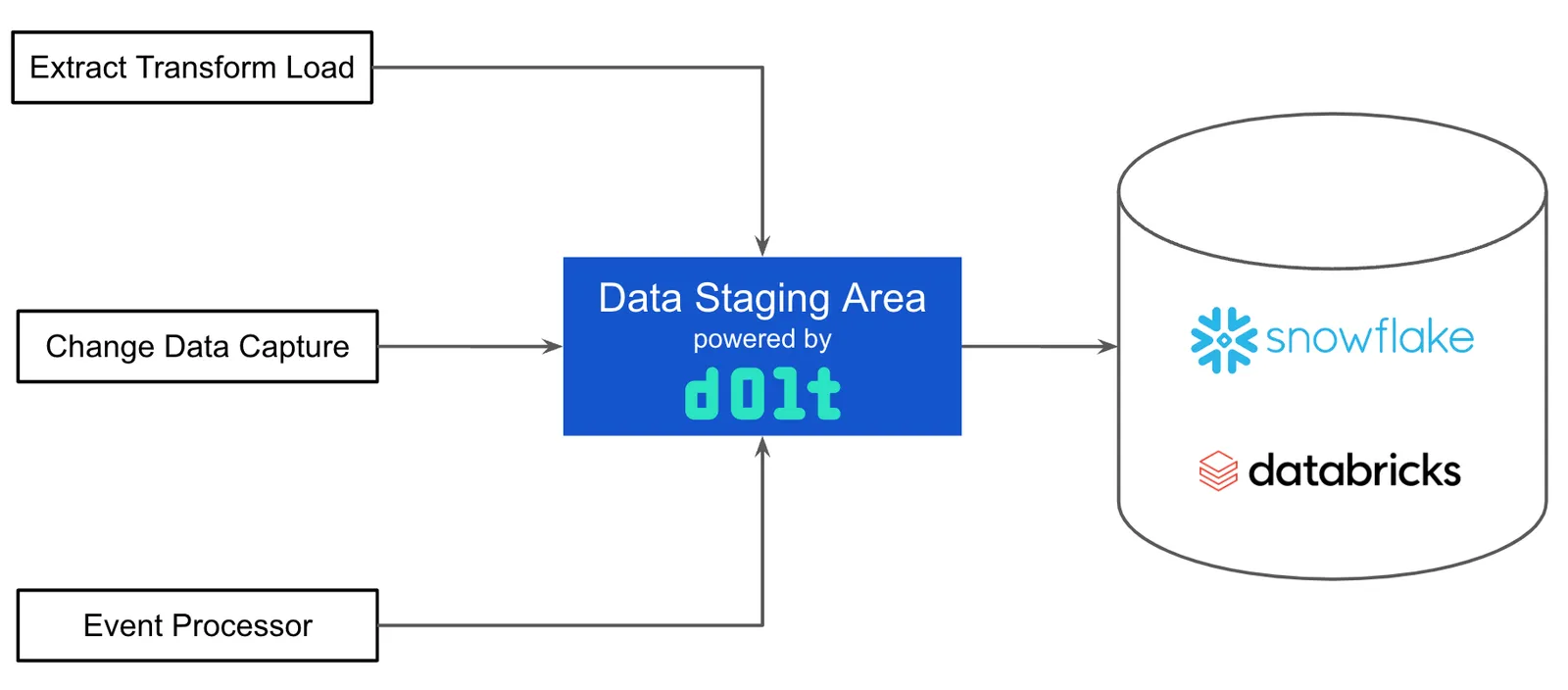
First, one or many data sources stream changes onto Dolt branches instead of directly into the warehouse. Different change sets can be streamed to multiple branches. You could have a branch per table or a branch per day. You could also make branching data aware. For instance, in an employee resource planning (ERP) system each employee’s data could be streamed to a different branch. Branches are light weight. You can have as many as you need to keep your change sets manageable.
Once the data is on a branch, a Pull Request and Continuous Integration test user interface using DoltHub or DoltLab can be implemented. Human readable and SQL queryable data diffs are produced. If you want to build a custom user interface, Dolt version control primitives are available. Data Continuous Integration testing is coming soon to DoltHub and DoltLab, but right now you could use Webhooks to connect Dolt to any continuous integration tool like GitHub Actions or Jenkins.
Once a branch is merged to main, another connector moves data from the Dolt main branch into your warehouse. This would be the same connector that moves data from MySQL to the warehouse today, just configured to read from Dolt’s main branch, no custom code required.
If a problem is discovered after the data has been merged, find the commit or commits that broke the data warehouse in the staging area using the log and diff functionality Dolt provides. Then, issue a revert of the commit, undoing the changes of that commit, or a reset, a full rollback of all changes to that point in time. Upon merge, this revert or reset change is then streamed as normal to the warehouse, fixing the bad data in the warehouse. The bad changes still exist in the data staging area so they can be debugged and fixed there.
Example#
The value of a data staging area is best illustrated through an example.
At my previous job, a critical metric was daily active users. Daily active users were segmented by country using an IP address to country mapping service provided by a vendor. As client events were processed, they were joined with an IP mapping table and then inserted into the warehouse with a country of origin column.
One day, we woke up to 1000% growth of daily active users in Iceland, putting daily active users greater than the population of the country. By this time, the company was publicly traded and daily active users was a critical metric we financially reported. This anomaly was detected by our data team and raised as an issue by the finance team. Upon investigation, the vendor had accidentally remapped a number of British IP ranges to Iceland. The ETA for a fix was unclear. In the meantime, our daily active users metrics were wrong. This was a problem for multiple weeks with Finance very upset the whole time. I was powerless to fix the issue and had to wait on the vendor, a terrible situation to be in as the person responsible for accurate business metrics.
In this case, what I really wanted was to store versions of the IP to country mapping table in a versioned database and rollback to the previous version of the table until the vendor fixed the issue. Only upon human review of the fixed data joined with my daily active user metrics would I merge new data from the vendor. A data staging area powered by Dolt would have made this month long ordeal a non-event. As you can see, a data staging area is incredibly valuable for versioning vendor data.
Version Controlled Gold Tables#
A data architecture with growing popularity is the Medallion architecture.
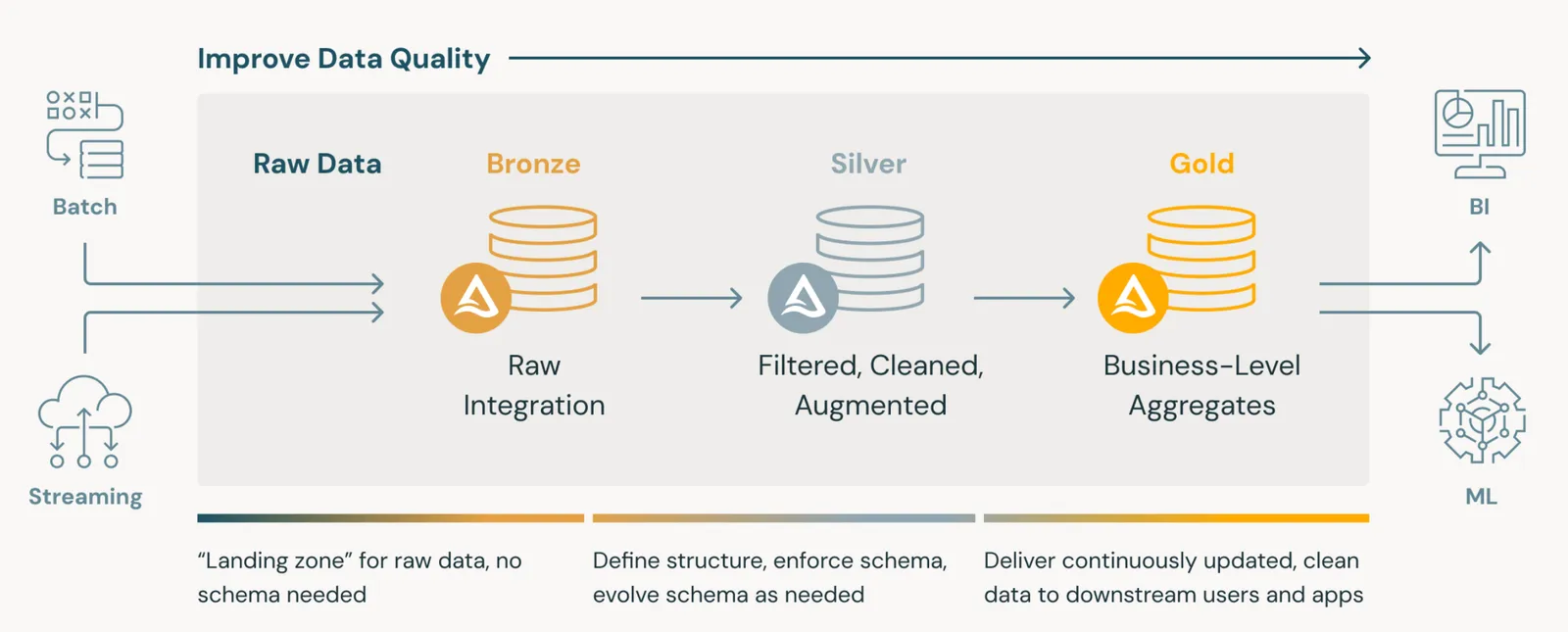
In this architecture, you define a set of “Gold Tables” intended to only contain clean data consumable by end users. Often, Gold tables are human reviewed. We spoke to one data engineer whose team employed dozens of contractors to manually review every row in their gold tables for data quality.
Human review is best done with version control. Branches, diffs, and rollbacks are essential in speeding up the process of human review. There’s a reason we don’t send an entire codebase for review, we only send the diff. The things that changed are the things that need the most review.
Like I mentioned in the data staging area section, we previously did not have the technology to version control tabular or JSON data but now we do with Dolt. We can use a similar version control process to manage our Gold tables.
Implementation#
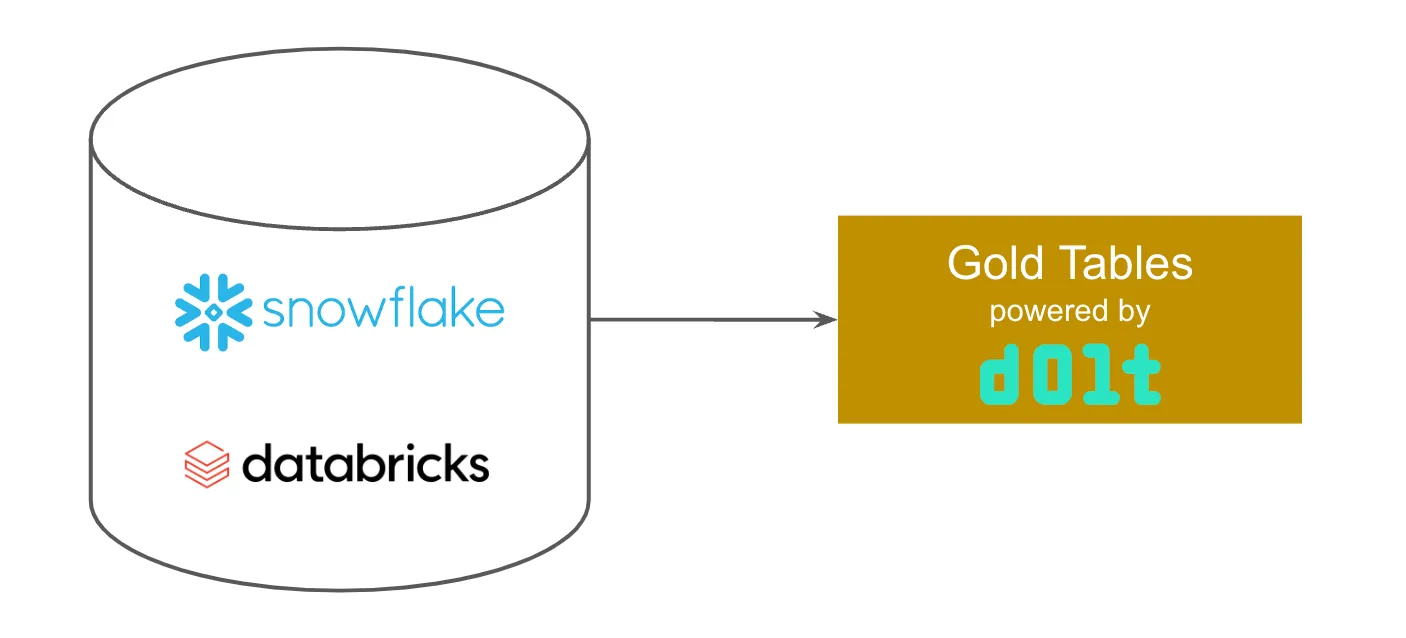
In this implementation, Dolt is the backing store for your Gold tables. Data warehouse queries are used to populate the Gold tables. This implementation is similar to the data staging area. Version controlled gold tables sit between the warehouse and your business intelligence. A data staging area instead sits between your data sources and your warehouse. But, in both cases, the implementation involves making changes to branches and using continuous integration and human review via a Pull Request workflow.
Whenever the data warehouse queries are run to regenerate or incrementally update the Gold tables, these updates are done on a Dolt branch, leaving the main branch unchanged. A Pull Request, complete with continuous integration testing, is opened for the update. This Pull Request is human reviewed to insure the changes are good. When the change passes review, you merge the Pull Request. You can then make an immutable named version or tag indicating a “data release”.
If a bad change makes it into the Gold table you can easily rollback to the previous commit or tag. Then, you can inspect and improve your integration tests to make sure a data change like that cannot make it into production again.
Example#
Leaning on another example from my previous company, we used a 15-day moving average of a few dozen key business metrics to run the business. These metrics were emailed daily to key stakeholders in a tabular format. Week-over-week change was used to gauge progress.
In this report, one would expect only yesterday’s data to be added and the 15th day to be deleted. If another day’s data changes, an unexpected revision was made and that must be investigated. As a business owner, I was always worried that I was missing revisions to this important business data. If I had Dolt, I would know when data was revised and I could initiate an investigation. Version controlled tables could have helped ensure business metric quality with revisions investigated appropriately.
Conclusion#
Dolt can be used by data engineers to implement a data staging area or version controlled Gold tables. These two additions to your data stack improve data quality and decrease time to recovery when bad data makes it into your warehouse. Interested in adding Dolt to your data stack? Come by our Discord and let’s chat.