
Recently AWS announced that it was deprecating the Quantum Ledger Database (QLDB) service by July 2025, and provided a guide for existing QLDB customers to migrate their QLDB data to PostgreSQL.
Tim, DoltHub’s CEO, addressed this deprecation announcement last week in a blog post reiterating that Dolt, like QLDB is an immutable database and can be used as an open source alternative to QLDB in the wake of its deprecation. To demonstrate this, we decided to perform a migration of QLDB’s Getting Started ledger, “vehicle-registration”, to a comparable Dolt database.
On the surface, the history of the data contained in the vehicle-registration ledger can be stored immutably by both QLDB and Dolt. In QLDB, a document based database, every database transaction is written to the ledger and document changes are tracked by their internal version numbers.
In Dolt, a relational table database, changes across all tables are committed, Git-style, creating a directed acyclic graph of changes that can be traversed, branched, diffed, and merged. Given these versioning similarities, it’s easy to imagine how Dolt can be used as a QLDB alternative. It also provides more robust and powerful versioning features than QLDB ever did.
So, to demonstrate this, I set out to export the QLDB vehicle-registration ledger and replay the history of its data in a new Dolt database.
To do this, for every QLDB transaction in vehicle-registration, I’d make a corresponding Dolt commit in a vehicle-registration Dolt database. This would not only give me a matching history of changes, but also enable Dolt’s powerful features, like diffing between commits, to easily inspect when and how the data changed over time.
However, once I began the process of performing this migration, things got pretty complicated, pretty quickly.
Before moving on, I want to give a big shout-out and “thank you” to Dan Blaner, a Principal Solutions Architect at AWS, author of the QLDB to Postgres migration guide, and a kind soul who helped me get the QLDB ledger set up. Thank you, Dan!
Prerequisites#
After following the Getting Started with QLDB guide to set up and modify data in the vehicle-registration ledger I was ready to export the ledger journal and started replaying the data history in Dolt, or so I thought.
I didn’t really realize upon my first reading of Dan’s words, that they would echo in my brain throughout the remainder of this process:
The Amazon QLDB document data model supports complex, structured documents that may contain nested elements. Tables in Amazon QLDB may contain objects with different document structures. Mapping the ledger’s flexible document model to a more rigid relational database schema can be challenging. Furthermore, the structure of a document may change over time. The migration process can’t assume that every revision of a given document has the same structure. Given these challenges, you may choose to migrate the data into Amazon Aurora PostgreSQL as JSON, which greatly simplifies the migration, but it may not be the most efficient option for accessing your data in the relational database. The alternative is to normalize the ledger data during migration, converting the document model to a relational model and accounting for any changes to the document model that occurred over time. This approach is more complex, requires more coding, and is prone to unexpected conversion errors that disrupt the migration process, but it may be a better choice, depending on how the data is accessed and used in your relational database management service.
“Can be challenging”… “requires more coding”… “prone to unexpected conversion errors”… to say the least, Dan! But undeterred, I ventured forth.
I didn’t want to store the QLDB data as JSON in Dolt. I really wanted to create a comparable, relational Dolt database, with the ledger’s full data history.
But here is where I hit my first speed bump.
As Dan stated, QLDB is a document-based database, basically a key-value store, so it does not have a rigid schema the way relational databases do.
To create a table in a QLDB ledger, you run the following PartiQL statement:
CREATE TABLE Person
That’s it. The database does not need to know about any keys/fields Person will store because they’ll be written to Person at INSERT time.
Relational databases, on the other hand, require table schema to be defined upfront. Schema change in these databases are much more involved/complicated, especially if a schema change affects relationships between tables.
This fundamental difference between document and relational database requirements threw a wrench in my plan to attempt to replay the QLDB history exactly as is in a Dolt database.
So I decided to work around this by attempting to model the vehicle-registration document schema as a relational table schema.
Here’s the document schema for the vehicle-registration tables:
Person {
FirstName
LastName
DOB
GovId (Indexed)
GovIdType
Address
}
DriversLicense {
LicensePlateNumber (Indexed)
LicenseType
ValidFromDate
ValidToData
PersonId (Indexed)
}
VehicleRegistration {
VIN (Indexed)
LicensePlateNumber (Indexed)
State
City
PendingPenaltyTicketAmount
ValidFromDate
ValidToDate
Owners {
PrimaryOwner {
PersonId
}
SecondaryOwners [
{
PersonId
}
...
]
}
}
Vehicle {
VIN (Indexed)
Type
Year
Make
Model
Color
}As you can see, there are four tables: Person, DriversLicense, VehicleRegistration, and Vehicle. Each table has various fields, some have nested documents within those fields, and none of the fields have data types. Some table fields are Indexed to allow performant search of the documents in the table, but there is no explicit or guaranteed relationship between identically named fields between tables.
To model these tables as relational SQL tables, I came up with the following schema:
CREATE TABLE VehicleRegistration (
Id varchar(22) primary key,
State varchar(2) not null,
City varchar(255) not null,
PendingPenaltyTicketAmount decimal(5, 2),
ValidFromDate datetime not null,
ValidToDate datetime not null
);
CREATE TABLE Person (
Id varchar(22) primary key,
FirstName varchar(255) not null,
LastName varchar(255) not null,
DOB datetime not null,
GovId varchar(255) not null,
GovIdType varchar(255) not null,
Address varchar(2000) not null
);
CREATE INDEX GovIdIdx ON Person (GovId);
CREATE TABLE VehicleOwnership (
VehicleRegistrationIdFk varchar(22) not null,
PersonIdFk varchar(22) not null,
IsPrimaryOwner boolean,
FOREIGN KEY (VehicleRegistrationIdFk) REFERENCES VehicleRegistration(Id) ON DELETE CASCADE,
FOREIGN KEY (PersonIdFk) REFERENCES Person(Id) ON DELETE CASCADE,
PRIMARY KEY (VehicleRegistrationIdFk, PersonIdFk)
);
CREATE TABLE DriversLicense (
Id varchar(22) primary key,
LicenseType varchar(255) not null,
ValidFromDate datetime not null,
ValidToDate datetime not null,
PersonIdFk varchar(22),
FOREIGN KEY (PersonIdFk) REFERENCES Person(Id) ON DELETE CASCADE
);
CREATE TABLE Vehicle (
Id varchar(22) primary key,
VehicleType varchar(255) not null,
Year int not null,
Make varchar(255) not null,
Model varchar(255) not null,
Color varchar(255) not null
);
CREATE TABLE VinMapping (
VIN varchar(255) primary key,
VehicleIdFk varchar(22),
VehicleRegistrationIdFk varchar(22),
FOREIGN KEY (VehicleIdFk) REFERENCES Vehicle(Id) ON DELETE RESTRICT,
FOREIGN KEY (VehicleRegistrationIdFk) REFERENCES VehicleRegistration(Id) ON DELETE RESTRICT
);
CREATE TABLE LicensePlateNumberMapping (
LicensePlateNumber varchar(255) primary key,
VehicleRegistrationIdFk varchar(22),
DriversLicenseIdFk varchar(22),
FOREIGN KEY (VehicleRegistrationIdFk) REFERENCES VehicleRegistration(Id) ON DELETE RESTRICT,
FOREIGN KEY (DriversLicenseIdFk) REFERENCES DriversLicense(Id) ON DELETE RESTRICT
);You’ll notice quite a few differences between the document schema and my relational schema.
First, I’ve added some extra tables to explicitly define the relationship of columns between tables. For example, creating a LicensePlateNumberMapping table with foreign keys to both VehicleRegistration and DriversLicense. This guarantees that the LicensePlateNumber field in both the QLDB DriversLicense table and VehicleRegistration table are the same.
Also notice that I’ve added an Id column to many tables, although the QLDB document schema did not contain an Id field in any of its tables.
I did this because although the QLDB tables do not contain an explicit Id field in their data definitions, documents are often associated to each other using an internal metadata id field, a field is generated by QLDB for each document. Since some updates I ran while working through the Getting Started guide associated specific documents with metadata.ids of others, I added this column on each relational table to correspond to these documents metadata.ids.
Once I defined my initial Dolt schema, I was ready to export the QLDB vehicle-registration transaction journal and start replaying the transactions in the Dolt database.
But… the perceptive reader will realize that my predefined schema workaround above is both “real” and “fake”, and I want to touch on this before continuing on.
First, my idea is “real” in the sense that it allowed me to successfully replay QLDB transactions for this specific example database that has, basically, the minimum number of transactions a ledger database can have. So in the sense that it works for me for this blog, it’s real.
But this workaround is actually much more “fake” than it is real. It’s fake, meaning this workaround can’t realistically be used for replaying a true, production-level ledger database, because a point-in-time “schema” of the document tables isn’t accurate enough to actually replay how the tables change over the course of their life.
As I mentioned earlier, a document table can exist with only a CREATE TABLE Person statement. In MySQL and in Dolt, a table cannot exist without column definitions.
Keys/fields are only created in QLDB during an INSERT, if they don’t already exist. So, to truly be accurate during a transaction replay in Dolt, you’d need to find the first INSERT transaction for the Person table in the QLDB journal, and then create a corresponding Person table in Dolt, with columns that match the fields defined in the INSERT.
Not only that, but there are also no data types in QLDB tables, so the kind of data stored in a field is not guaranteed to be similar at all between document versions. This is the opposite case for Dolt, where table columns require explicit data types to be defined, and will error when INSERTs contain incongruent value types. You might see now how this difference exponentially increases the complexity of this project, even when just deciding how to model the document data as relational tables.
Additionally, because INSERTs into QLDB tables can contain nested document values, if you were trying to correctly create relational tables and their corresponding mapping tables, only when reading an INSERT QLDB transaction, you’d likely have a really, really bad time. As Dan stated before, “it would be challenging.”
This is good to keep in mind as we move on, and it’s why I decided to go with the simpler predefined schema approach.
The easy part#
After I created my initial schema workaround, my next step was exporting the vehicle-registration QLDB journal to AWS S3 and start reading it.
This was probably the easiest part of the entire process. To export the journal, you just need to click “Export” in the AWS QLDB console and select an S3 bucket where AWS will write the journal.
Once the export is complete, you’ll find two manifests in the bucket along with the full transactional data.
The manifest with the suffix .started.manifest contains some info about the export job itself. The manifest with the suffix .completed.manifest contains the keys of transactional data in the bucket.
To aid my endeavors in working with this journal data I wrote a custom tool that would download the journal data from S3, parse it, and convert each transaction into corresponding Dolt SQL statements. Again, the goal here being that I could run these statements in a Dolt database, producing a database with a commit history mirroring that of the QLDB ledger.
To get a better idea of how this might work, let’s look at an example.
Below is a much simplified representation of a QLDB ledger transaction block.
{
transactionId:"D35qctdJRU1L1N2VhxbwSn",
transactionInfo:{
statements:[
{
statement:"CREATE TABLE VehicleRegistration",
startTime:2019-10-25T17:20:20.496Z,
statementDigest:{{3jeSdejOgp6spJ8huZxDRUtp2fRXRqpOMtG43V0nXg8=}}
},
{
statement:"CREATE INDEX ON VehicleRegistration (VIN)",
startTime:2019-10-25T17:20:20.549Z,
statementDigest:{{099D+5ZWDgA7r+aWeNUrWhc8ebBTXjgscq+mZ2dVibI=}}
},
{
statement:"CREATE INDEX ON VehicleRegistration (LicensePlateNumber)",
startTime:2019-10-25T17:20:20.560Z,
statementDigest:{{B73tVJzVyVXicnH4n96NzU2L2JFY8e9Tjg895suWMew=}}
},
{
statement:"INSERT INTO VehicleRegistration ?",
startTime:2019-10-25T17:20:20.595Z,
statementDigest:{{ggpon5qCXLo95K578YVhAD8ix0A0M5CcBx/W40Ey/Tk=}}
}
]
},
revisions:[
{
data:{
VIN:"1N4AL11D75C109151",
LicensePlateNumber:"LEWISR261LL",
State:"WA",
City:"Seattle",
PendingPenaltyTicketAmount:90.25,
ValidFromDate:2017-08-21,
ValidToDate:2020-05-11,
Owners:{
PrimaryOwner:{
PersonId:"GddsXfIYfDlKCEprOLOwYt"
},
SecondaryOwners:[]
}
},
metadata:{
id:"8F0TPCmdNQ6JTRpiLj2TmW"
}
}
]
}In it, you can see the PartiQL statements that were a part of the transaction in the statements field. In this example the table VehicleRegistration was created, and the fields VIN and LicensePlateNumber were added to the table and indexed. Lastly, a value was also inserted into the table.
In the revisions field you can see data and metadata from the committed view of the transaction.
In the data field we can see that fields State, City, PendingPenaltyTicketAmount, ValidFromDate, and ValidToDate were all created in VehicleRegistration table during the INSERT as well. Owners was also added as a field to the table, and happens to be a nested document.
So now, the question is, how should this be translated into Dolt SQL?
Well, as we discussed above, there are some inherent problems with the CREATE statements, so we’ve worked around those by pre-defining the schema. Instead, we’ll just focus on replaying INSERTs, UPDATEs, and DELETEs.
Using the transaction block above as input, our Dolt SQL output would be:
INSERT INTO VehicleRegistration (Id,`State`,City,PendingPenaltyTicketAmount,ValidFromDate,ValidToDate) VALUES ('8F0TPCmdNQ6JTRpiLj2TmW', 'WA', 'Seattle', 90.25, '2017-08-21', '2020-05-11');
INSERT INTO VinMapping (VIN, VehicleRegistrationIdFk) VALUES ('1N4AL11D75C109151', '8F0TPCmdNQ6JTRpiLj2TmW');
INSERT INTO LicensePlateNumberMapping (LicensePlateNumber, VehicleRegistrationIdFk) VALUES ('LEWISR261LL', '8F0TPCmdNQ6JTRpiLj2TmW');
CALL DOLT_COMMIT('-Am', 'Insert into VehicleRegistration, VinMapping, LicensePlateNumberMapping to replay QLDB transaction D35qctdJRU1L1N2VhxbwSn');The Dolt SQL statements above make INSERTs into the the VehicleRegistration table to match the QLDB transaction, but also make INSERTs into two mapping tables to track the relationships between license plate number, vin numbers, and the registrations associated with them. The final statement in the Dolt output runs a Dolt stored procedure that creates the Dolt commit.
This process of translating QLDB transactions into Dolt SQL statements will be what my tool aims to do. It will output a single SQL file containing all statements required to create the data and its transactional history, modeled as Dolt commits.
Interestingly, once I started reading the QLDB journal data I noticed something I hadn’t anticipated before. It turns out that the journal not only contains every write transaction against the ledger, but it also contains records of every read against the ledger as well.
I assumed that read queries (SELECT statements) wouldn’t be written in the journal, since they don’t modify the table data and it also increases the storage requirement. In fact, the journal data mostly contains read queries.
This fact further complicated my plan to replay the QLDB history exactly, since Dolt commits traditionally only track data changes resulting from writes. Reads against Dolt tables are not persisted anywhere. To most accurately replay the transactions of the QLDB database in Dolt, I’d need to do something like:
CALL DOLT_COMMIT('-Am', '--allow-empty', 'SELECT * FROM VehicleRegistration');This would create an empty Dolt commit the would produce an empty diff, and the read query would need to be stored in the commit message, since there’s nowhere else to really put it (outside of making a separate table).
This was a pretty interesting discovery, but for this project I opted to discard the QLDB read transactions all together, for simplicity.
The hard part#
Using my tool, I was able to download the QLDB transaction journal, read the entries, and isolate write-transactions I would translate into Dolt SQL.
This was hard. Even for just the small number of write transactions in this tiny example database… This was hard.
What made it hard was that the core of what’s required here (to do this correctly) is parsing PartiQL statements, which is SQL-esque syntax for document databases, and translating them to valid Dolt/MySQL SQL statements.
As an example, consider the following PartiQL INSERT statement:
INSERT INTO VehicleRegistration
<< {
'VIN' : '1C4RJFAG0FC625797',
'LicensePlateNumber' : 'TH393F',
'State' : 'WA',
'City' : 'Olympia',
'PendingPenaltyTicketAmount' : 30.45,
'ValidFromDate' : `2013-09-02T`,
'ValidToDate' : `2024-03-19T`,
'Owners' : {
'PrimaryOwner' : { 'PersonId': 'GddsXfIYfDlKCEprOLOwYt' },
'SecondaryOwners' : []
}
} >>Parsing this syntax correctly, handling its capitalizations, handling its uses of single quotes and backticks, handling its nested data structures, and then generating valid Dolt/MySQL SQL statements is a large amount of work and a large amount of code (You were right again, Dan).
But worse too, is it would all be bespoke code, completely dependent on the source, QLDB document model and the target, Dolt database model. And that’s basically how my tool turned out. It’s really only useful for this exact QLDB database, in this exact state.
Since I’m not smart enough to pull off the PartiQL to MySQL translation myself, I once again went to my bag of cheats and workarounds. Instead of actually attempting to translate the syntaxes, I instead parsed the revisions field of the QLDB journal transaction blocks whenever an INSERT or UPDATE occurred, specifically for the data field.
Since this field contained the commit view (final view) of the modified document at the end of the transaction, I decided I would use that commit view data to update the corresponding row(s) in the Dolt database to match that view. This way, the resulting Dolt commit would reflect the same state of the data that the QLDB transaction did.
However, once again, this approach, too, is both real and fake.
Like before, it’s real in the sense that it worked for this exact small, example database. But it’s fake in that it would not work very well for a production sized QLDB ledger.
This example database has very simple transactions that only contain a single write statement per transaction block.
But you can imagine a production transaction block that contains many INSERT, UPDATE, and DELETE statements that depend on each other to modify some document(s).
And, while modifying tables based on the commit view of the documents is probably correct a lot of the time, it’s also very easy for it to be incorrect often, especially if you’re trying to build accurate relationships between tables in your target Dolt database.
Nonetheless, I was able to use this approach and update my tool to do this sufficiently for the INSERT and UPDATE transactions in the example journal.
Using my tool, the following QLDB INSERT:
INSERT INTO Person
<< {
'FirstName' : 'Raul',
'LastName' : 'Lewis',
'DOB' : `1963-08-19T`,
'GovId' : 'LEWISR261LL',
'GovIdType' : 'Driver License',
'Address' : '1719 University Street, Seattle, WA, 98109'
},
{
'FirstName' : 'Brent',
'LastName' : 'Logan',
'DOB' : `1967-07-03T`,
'GovId' : 'LOGANB486CG',
'GovIdType' : 'Driver License',
'Address' : '43 Stockert Hollow Road, Everett, WA, 98203'
},
{
'FirstName' : 'Alexis',
'LastName' : 'Pena',
'DOB' : `1974-02-10T`,
'GovId' : '744 849 301',
'GovIdType' : 'SSN',
'Address' : '4058 Melrose Street, Spokane Valley, WA, 99206'
},
{
'FirstName' : 'Melvin',
'LastName' : 'Parker',
'DOB' : `1976-05-22T`,
'GovId' : 'P626-168-229-765',
'GovIdType' : 'Passport',
'Address' : '4362 Ryder Avenue, Seattle, WA, 98101'
},
{
'FirstName' : 'Salvatore',
'LastName' : 'Spencer',
'DOB' : `1997-11-15T`,
'GovId' : 'S152-780-97-415-0',
'GovIdType' : 'Passport',
'Address' : '4450 Honeysuckle Lane, Seattle, WA, 98101'
} >>produces the following Dolt SQL:
INSERT INTO Person (Id,FirstName,LastName,DOB,GovId,GovIdType,Address) VALUES ('1nmeyhNA5JVLeUsHfvHnxg', 'Brent', 'Logan', '1967-07-03', 'LOGANB486CG', 'Driver License', '43 Stockert Hollow Road, Everett, WA, 98203');
INSERT INTO Person (Id,FirstName,LastName,DOB,GovId,GovIdType,Address) VALUES ('2f0tCDNt3NgGlHFKc0E4kW', 'Raul', 'Lewis', '1963-08-19', 'LEWISR261LL', 'Driver License', '1719 University Street, Seattle, WA, 98109');
INSERT INTO Person (Id,FirstName,LastName,DOB,GovId,GovIdType,Address) VALUES ('D35rKlKGKas776EQcPC7F4', 'Salvatore', 'Spencer', '1997-11-15', 'S152-780-97-415-0', 'Passport', '4450 Honeysuckle Lane, Seattle, WA, 98101');
INSERT INTO Person (Id,FirstName,LastName,DOB,GovId,GovIdType,Address) VALUES ('F6qRrCYP1doAKCfRaz7lbi', 'Melvin', 'Parker', '1976-05-22', 'P626-168-229-765', 'Passport', '4362 Ryder Avenue, Seattle, WA, 98101');
INSERT INTO Person (Id,FirstName,LastName,DOB,GovId,GovIdType,Address) VALUES ('HbD9zOmuEunEkaG8QBUbck', 'Alexis', 'Pena', '1974-02-10', '744 849 301', 'SSN', '4058 Melrose Street, Spokane Valley, WA, 99206');
CALL DOLT_COMMIT('-Am', 'insert into Person, qldb transaction id: LCmBuAR9MoF9t8oUYlmxuO');Now all that’s left for my tool to do, is to handle the DELETE transactions it encounters in the journal.
The really hard part#
Interestingly, QLDB DELETEs are not the same as DELETEs in Dolt and MySQL. In relational databases, a DELETE removes a row. With Dolt, this is no big deal because you have the full history of the row in prior commits. So you can easily revert a delete to get a row back to its previous state.
Here’s how DELETEs work in QLDB:
In Amazon QLDB, use the DELETE command to mark an active document as deleted in a table by creating a new, but final revision of the document. This final revision indicates that the document is deleted. This operation ends the lifecycle of a document, which means that no further document revisions with the same document ID can be created.At this time, I don’t really have a simple idea for how to model this type of behavior in Dolt… so for the purposes of this project, I treated every DELETE as a row deletion.
Unfortunately, though, because DELETE QLDB transactions do not contain a final commit view of the document “deleted” (there is no revisions.data in the transaction block), I could not employ my previous hack of using revision data. With DELETE QLDB transactions, the only choice I was left with was to attempt to parse and translate the PartiQL DELETE statement into Dolt SQL.
And this is really, really hard. I even tried to cheat again by making ChatGPT do the work for me, and he didn’t even want to do this, saying:
To convert a PartiQL statement to an equivalent MySQL statement in Go, we can create a basic function that handles the conversion. However, since PartiQL is an expressive query language that can handle nested data structures and other advanced features, the conversion process may be complex and involve parsing and translating various elements of the query.
Here’s a simple example of how you might start such a function. This function will handle basic SELECT queries as an initial step. You may need to extend it for more complex queries.
package main
import (
"fmt"
"strings"
)
// ConvertPartiQLToMySQL converts a PartiQL query to an equivalent MySQL query
func ConvertPartiQLToMySQL(partiql string) (string, error) {
// For simplicity, we'll assume the PartiQL statement is a basic SELECT query
// and we will replace certain keywords to convert it to MySQL.
// Remove any leading or trailing spaces
partiql = strings.TrimSpace(partiql)
// Replace PartiQL keywords with MySQL equivalents
replacements := map[string]string{
"SELECT": "SELECT",
"FROM": "FROM",
"WHERE": "WHERE",
// Add more mappings as needed
}
// Convert PartiQL to MySQL
mysqlQuery := partiql
for partiqlKey, mysqlKey := range replacements {
mysqlQuery = strings.ReplaceAll(mysqlQuery, partiqlKey, mysqlKey)
}
// Return the converted query
return mysqlQuery, nil
}
func main() {
partiqlQuery := "SELECT name, age FROM users WHERE age > 30"
mysqlQuery, err := ConvertPartiQLToMySQL(partiqlQuery)
if err != nil {
fmt.Println("Error converting query:", err)
return
}
fmt.Println("Converted MySQL query:", mysqlQuery)
}Absolutely useless.
So, to handle the DELETE transactions for this project, knowing that I wasn’t going to code up something particularly useful for generally translating PartiQL DELETEs to Dolt DELETEs, I opted for galaxy-brained hardcoding:
func (d *personParsedPartiQl) deleteAsDoltSql(ctx context.Context, transactionId string) (string, error) {
deleteStmt := ""
// todo: actually parse partiql
// cheat and just check against hardcoded first and last name
firstName := "Larry"
lastName := "David"
shouldDelete := false
if strings.Contains(d.stmt, firstName) && strings.Contains(d.stmt, lastName) {
shouldDelete = true
}
if !shouldDelete {
return "", ErrNoDoltSqlEquivalent
}
deleteStmt += fmt.Sprintf("DELETE FROM VehicleOwnership WHERE PersonIdFk = (SELECT p.Id FROM Person as p WHERE p.FirstName = '%s' AND p.LastName = '%s');", firstName, lastName) + "\n"
deleteStmt += fmt.Sprintf("DELETE FROM DriversLicense WHERE PersonIdFk = (SELECT p.Id FROM Person as p WHERE p.FirstName = '%s' AND p.LastName = '%s');", firstName, lastName) + "\n"
deleteStmt += fmt.Sprintf("DELETE FROM Person WHERE FirstName = '%s' AND LastName = '%s';", firstName, lastName) + "\n"
deleteStmt += d.addAndCommitDoltSql(ctx, fmt.Sprintf("delete from %s, %s, %s qldb transaction id: %s", VehicleOwnershipTableName, DriversLicenseTableName, PersonTableName, transactionId))
return deleteStmt, nil
}This allowed me to finish my tool and generate a Dolt SQL file that kind of replays the QLDB vehicle-registration ledger history.
The result#
So what are the actual results of this project?
Well it’s pretty cool. I do now have a Dolt database hosted on DoltHub that resembles the vehicle-registration QLDB ledger.
After my tool read and processed the journal file, it created a file called vehicle-registration-replay.sql. From there, I only needed to do two things to make my Dolt database.
First, import the initial schema:
$ mkdir qldb-vehicle-registration
$ cd qldb-vehicle-registration
$ dolt init
$ dolt sql < ./vehicle-registration-schema.sqlAnd second, import the replay SQL:
$ dolt sql < ./vehicle-registration-replay.sqlThat’s it!
Now I can view the Dolt commit log as if its a transaction log and I can diff between commits to see how my data has changed.
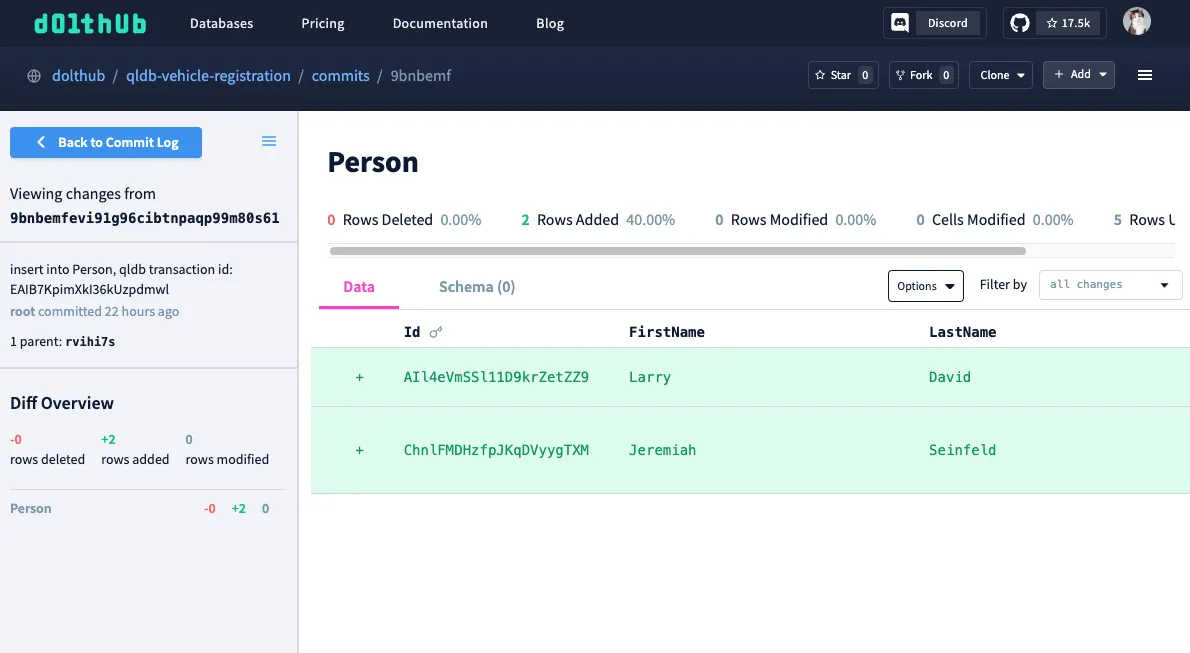
Also, unlike QLDB, let’s say I want to work with the data in its prior state, before Larry David was removed. In my local copy of the database, I can simply checkout a new branch at the commit before he was deleted.
Let’s checkout a diff between commits (transactions), where Larry and his vehicle information were removed.
$ dolt diff lpo45jkglkc3ac98di3k2eiafvqkioa5 HEAD
diff --dolt a/Person b/Person
--- a/Person
+++ b/Person
+---+------------------------+-----------+----------+---------------------+------------------+-----------+---------------------------------------+
| | Id | FirstName | LastName | DOB | GovId | GovIdType | Address |
+---+------------------------+-----------+----------+---------------------+------------------+-----------+---------------------------------------+
| - | AIl4eVmSSl11D9krZetZZ9 | Larry | David | 1904-02-29 00:00:00 | P666-555-444-333 | Passport | Hilarious ave, Los Angeles, CA, 90210 |
+---+------------------------+-----------+----------+---------------------+------------------+-----------+---------------------------------------+
diff --dolt a/Vehicle b/Vehicle
--- a/Vehicle
+++ b/Vehicle
+---+------------------------+-------------+------+---------+-------+-------+
| | Id | VehicleType | Year | Make | Model | Color |
+---+------------------------+-------------+------+---------+-------+-------+
| - | Fi6cVfFtDFgFdmmYHkyqTc | Sedan | 1906 | Toyanda | Prius | Black |
+---+------------------------+-------------+------+---------+-------+-------+
diff --dolt a/VehicleOwnership b/VehicleOwnership
--- a/VehicleOwnership
+++ b/VehicleOwnership
+---+-------------------------+------------------------+----------------+
| | VehicleRegistrationIdFk | PersonIdFk | IsPrimaryOwner |
+---+-------------------------+------------------------+----------------+
| - | Lo2MYe8cJ9B57NIM2HBAFy | AIl4eVmSSl11D9krZetZZ9 | 1 |
+---+-------------------------+------------------------+----------------+
diff --dolt a/VehicleRegistration b/VehicleRegistration
--- a/VehicleRegistration
+++ b/VehicleRegistration
+---+------------------------+-------+-------------+----------------------------+---------------------+---------------------+
| | Id | State | City | PendingPenaltyTicketAmount | ValidFromDate | ValidToDate |
+---+------------------------+-------+-------------+----------------------------+---------------------+---------------------+
| - | Lo2MYe8cJ9B57NIM2HBAFy | CA | Los Angeles | 90.25 | 2017-08-21 00:00:00 | 2020-05-11 00:00:00 |
+---+------------------------+-------+-------------+----------------------------+---------------------+---------------------+
diff --dolt a/VinMapping b/VinMapping
--- a/VinMapping
+++ b/VinMapping
+---+-------------------+------------------------+-------------------------+
| | VIN | VehicleIdFk | VehicleRegistrationIdFk |
+---+-------------------+------------------------+-------------------------+
| - | 1G1ZG57B38F112851 | Fi6cVfFtDFgFdmmYHkyqTc | Lo2MYe8cJ9B57NIM2HBAFy |
+---+-------------------+------------------------+-------------------------+Looks good!
Now I can just check out a new branch called with-larry at that previous commit, and I’ll have the database at the state it was in before Larry was deleted.
$ dolt checkout lpo45jkglkc3ac98di3k2eiafvqkioa5 -b with-larry$ dolt sql -q "select FirstName,LastName from Person;"
+-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Brent | Logan |
| Raul | Lewis |
| Larry | David |
| Jeremiah | Seinfeld |
| Salvatore | Spencer |
| Melvin | Parker |
| Alexis | Pena |
+-----------+----------+If this were a production database, I would also feel very good about moving forward with Dolt as my immutable vehicle-registration database. The table schema is explicit and logical. Relationships between table elements are no longer simply implied, but are now consistent and verifiable.
Additionally, I could continue to model each SQL transaction on my database as a Dolt commit by enabling the dolt_transaction_commit setting, so this database would still be pretty close to a transactional ledger in practice.
Additionally, in the event I ever wanted to migrate away from Dolt, it would be far easier to go from a relational table model back to a document model. Of that I am completely sure. It’s always easier to go from typed structure to untyped structure.
Conclusion#
Practically speaking, if I were to do this work for an actual production database, I’d opt to download a point-in-time snapshot of each table in the ledger and transform that state of the data into CSV files that match the schema I’d designed for the corresponding Dolt database. From there I could easily import those CSV files into Dolt tables.
I would not try to replay the history of the data changes that occurred in the QLDB ledger, unless doing so would be really, really worthwhile. Unfortunately, experience has shown me that attempting to do this accurately and effectively would require quite a lot of bespoke code that’s pretty difficult to get right (at least for simpletons like me).
I do think that the Dolt database is a much better immutable database than QLDB, not just because QLDB is deprecated either. Dolt provides much richer versioning features that are worth taking advantage of, without sacrificing any of the benefits the ledger database offers. I hope you’ve enjoyed reading about my endeavor to migrate a QLDB ledger to Dolt.
Thanks for reading and don’t forget to check out each of our cool products below:
- Dolt—it’s Git for data.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.