
Dolt has the DNA of Git within it, and one aspect of Git which I believe hasn’t gotten enough attention is the workspace. The workspace is the place where you do your work. It’s where you write code, make changes, and test things out. It’s where you make mistakes and fix them. It’s where you merge and rebase. It’s where you do everything that you never want to share with anyone else.
What is unknown to many is that there are two levels of your workspace in git. The first is the files you have on disk which you read and edit, and the second has gone by a few names (index, cache, staging), but I’ll call it the “staging area”. The staging area is where you put the changes you want to commit.
Dolt has the same DNA as Git, and it applies directly to Dolt’s workspace. Today we’ll talk generally about these two levels of the workspace and introduce a new set of Dolt tables to help you make sense of your workspace.
The Workspace#
When you are writing code stored by Git, what you work with is always the files you have on disk. When you compile
code, you expect it will use those files alone. In Dolt, it’s the same thing. When you run select * ... on your
data, you expect it to be what you have checked out. Furthermore, when you edit your code, or your data, the idea
that your work area has changed from HEAD is simple to understand.
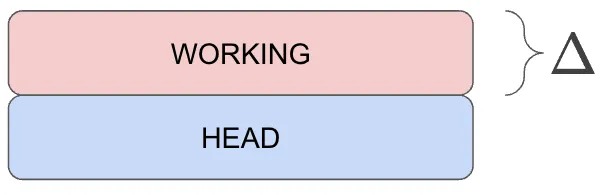
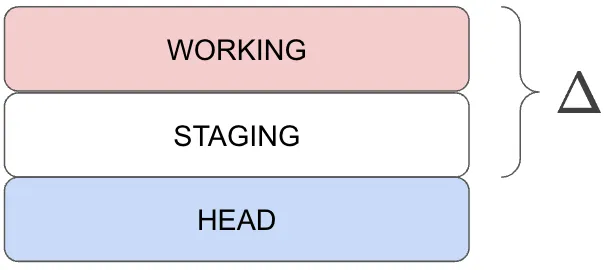
This is a simple way to think about it, but it’s not the truth. The workspace is two layers of delta, or “diff”, on top of HEAD. HEAD is a committed state, complete with a SHA address and everything. This is a more correct picture of the situation.
When you run git status, something similar has probably been printed for you:
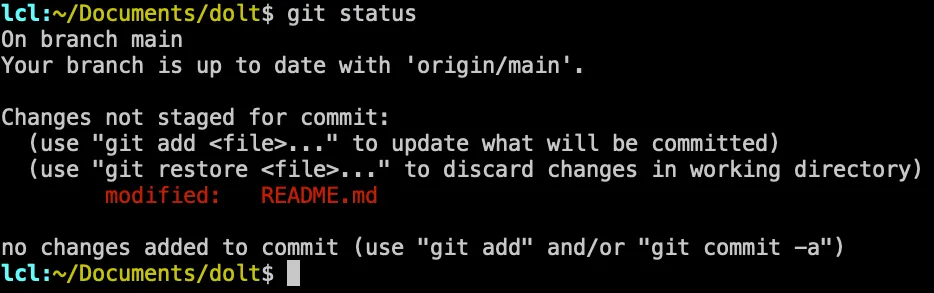
And if you follow the provided instructions, you’ll run git commit -a, because let’s face it, we all only read the
last few words of everything.
If we slow down the process, and perform the add README.md and check status again, you’ll see the status has transitioned to
green, and will be committed.
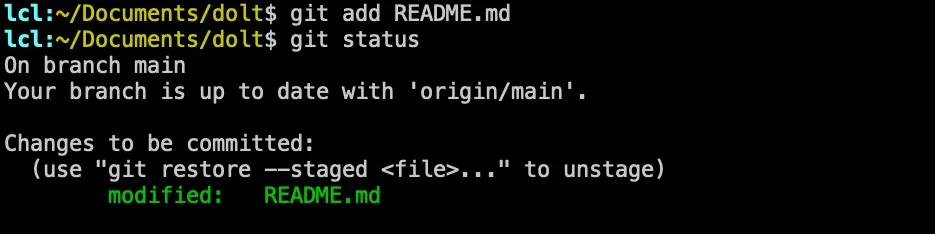
What has occurred here is you’ve moved the README.md out of just being a file on your hard drive, to a tracked entity in Git which is placed in your Staging Area.
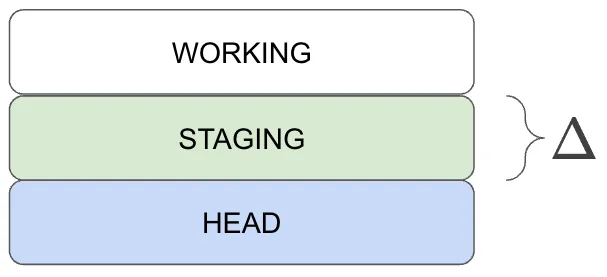
When you commit, without using the -a flag, the state of Staging becomes HEAD. Committing with -a simply sticks
everything in the Workspace into Staging before completing the commit.
In Dolt, tables are like files in Git. You can see the same workspace ideas in our shell.
But Why?#
In your day to day editing of code and data, you may wonder why this additional complexity is necessary.
First, there are technical requirements of Git and Dolt to have a “place” to resolve conflicts. When you attempt to merge two branches, this is particularly true with Git, the objects of the result are stored in Staging. This is what prints after a merge conflict.
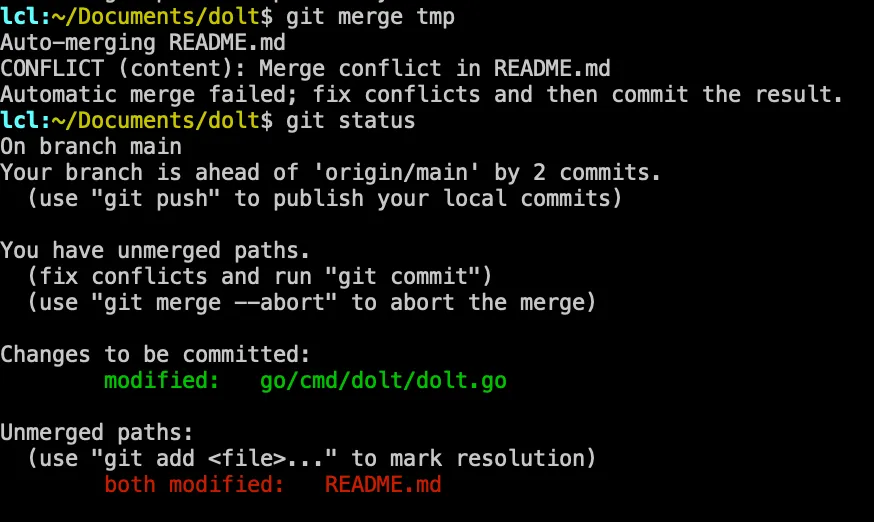
It’s interesting to call out that the green file, dolt.go has been materialized in the Git object store, while
the README.md file is simply the conflicts written into the file for you to sort out. In Git terms, there is
a very clear separation between Staged changes and Working changes. Dolt is different in this regard, and we’ll get
to that in a bit.
Second, there are interesting operations you can perform which leverages the fullness of the model. The git add --patch
operation is a very good example of this. For example, it’s not uncommon to find a spelling error in my code. I typically
run across these when I’m writing actual code in the same file, and I don’t want the commits of new code to be muddied
with unrelated grammatical fixes. I use git add --patch to help me select which portions of code I want to commit.

From the last status message there, you can see that the README.md is both modified in Working and Staging. This means
Staging is different from HEAD, and Working is different from Staging.
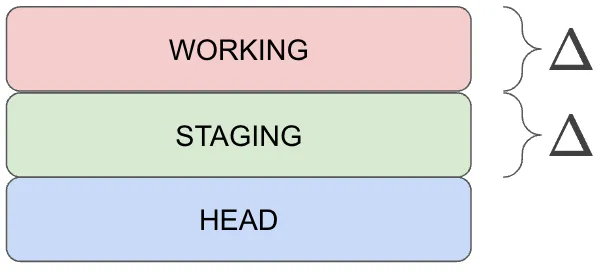
git add --patch allows you to manipulate the Workspace such that you have full control over the code you commit.
There are other workflows which are possible when you get used to git add --patch, in particular in cases where
you need to perform a partial revert of a change, or do a hard reset of your workspace but just need to save
one key piece. It can be used when in the middle of an interactive rebase to split a single commit into two.
Working with the Workspace#
The main thing you need to know is what you see in git status. The two sections of the output will tell you clearly
what is staged and what is not. There are even instructions on how to alter files in each state. Status only tells you
which files are in each state though. Using the --staged option on git diff, you can see more details.

In the output of status, you can see that the git reset and git restore commands can be used to move things
out of a given state.
What’s Different With Dolt#
As mentioned above, Dolt is a little different from Git. The first thing to call out is that the Workspace of Dolt is materialized in your database. Unlike depending on the filesystem for your workspace, Dolt is required to record all objects into it’s storage system because that’s how databases work. You can’t really query your data if the database hasn’t indexed it. In order to deal with merge conflicts in a SQL context, we employ additional tables to show you which rows have conflicts.
So… the technical requirement for having a staging area is not as strong as with Git. How about all these
workflows mentioned above and git add --patch - surely people working with data could want such things?
They do. Honestly, a database typically has a dozen or so tables, and
a source tree can have hundreds of files easily. So mapping of Tables to Files when comparing Dolt and Git is not
a perfect comparison. It’s actually pretty reasonable to imagine a situation where you have added a dozen rows
to a table, but you only want to commit some of them. What about hundreds or thousands of additional rows?
The potential for leveraging Staging in Dolt is real, but again, Dolt isn’t Git. git add --patch is a workflow
which walks you though which changes you could stage. That doesn’t really make sense in SQL.
What does make sense in SQL? Tables. Additional system tables to be specific. In the latest version of Dolt,
we’ve introduced the dolt_workspace_{table} system tables. Now you can look at your workspace at any time
in it’s raw form. It’s similar to the dolt_diff_{table} approach, but since workspaces are always relative to
HEAD, we don’t need the commits and date columns. From our Dolt example above, here is what the users table
looks like after you’ve modified it twice.
db1/main*> select * from dolt_workspace_users;
+----+--------+-----------+-------+-------------+---------+---------------+
| id | staged | diff_type | to_id | to_username | from_id | from_username |
+----+--------+-----------+-------+-------------+---------+---------------+
| 0 | true | added | 2 | mojo | NULL | NULL |
| 1 | false | modified | 2 | sami | 2 | mojo |
+----+--------+-----------+-------+-------------+---------+---------------+
2 rows in set (0.00 sec)You can see that the row with id 2 is both staged with a change to set the username to “mojo”, and there
is a staged change to set the same row’s username to “sami”. If you commit right now, “mojo” will be
recorded as the value, but if you select from the table, you’ll see what’s in the workspace.
Currently these tables are readonly, but we are working on allowing targeted writes to this table to give you the ability to manipulate you workspace directly. We’ll keep you posted!
Feedback Welcome#
When users ask for dolt add --patch, it’s not always clear how Git features map onto SQL. We believe
the path we are on is a reasonable approach, but maybe you disagree? Join us on Discord
to help us understand how you want to use Dolt!