
This year, Dolt started passing every test in the sqllogictest suite. Correctness is crucial for reliability, but also lets us confidently reengineer the SQL engine for performance.
One of the ways we are making query execution faster is custom key-value (KV) layer SQL logic. The generic SQL logic in go-mysql-server understands and manipulates presentation-layer rows. This is developer friendly, but the boundary between the engine and implementor adds overhead. Removing this execution step can dramatically improve the performance of queries that spend a lot of time moving between the KV and SQL layers.
We will focus on lookup joins as a entrypoint into a Dolt KV execution engine that brings our Dolt:MySQL Sysbench latency multiple below 2x.
Where Has The Time Gone#
Sysbench is a benchmark that iteratively runs queries against an in-memory database. We benchmark common read and write queries to test Dolt’s end to end optimizer and execution efficiency compared to MySQL.
Our write queries have been faster than MySQL since our format change (and keep getting faster), but we still lag on read queries.
Why are Dolt’s read queries slower than MySQL? The way we run sysbench does not take networking or prepared statement shortcuts at the moment, so the read path exclusively spends time optimizing queries, executing queries, and reading data from Dolt’s chunkstore.
Here is an overview of that lifecycle:
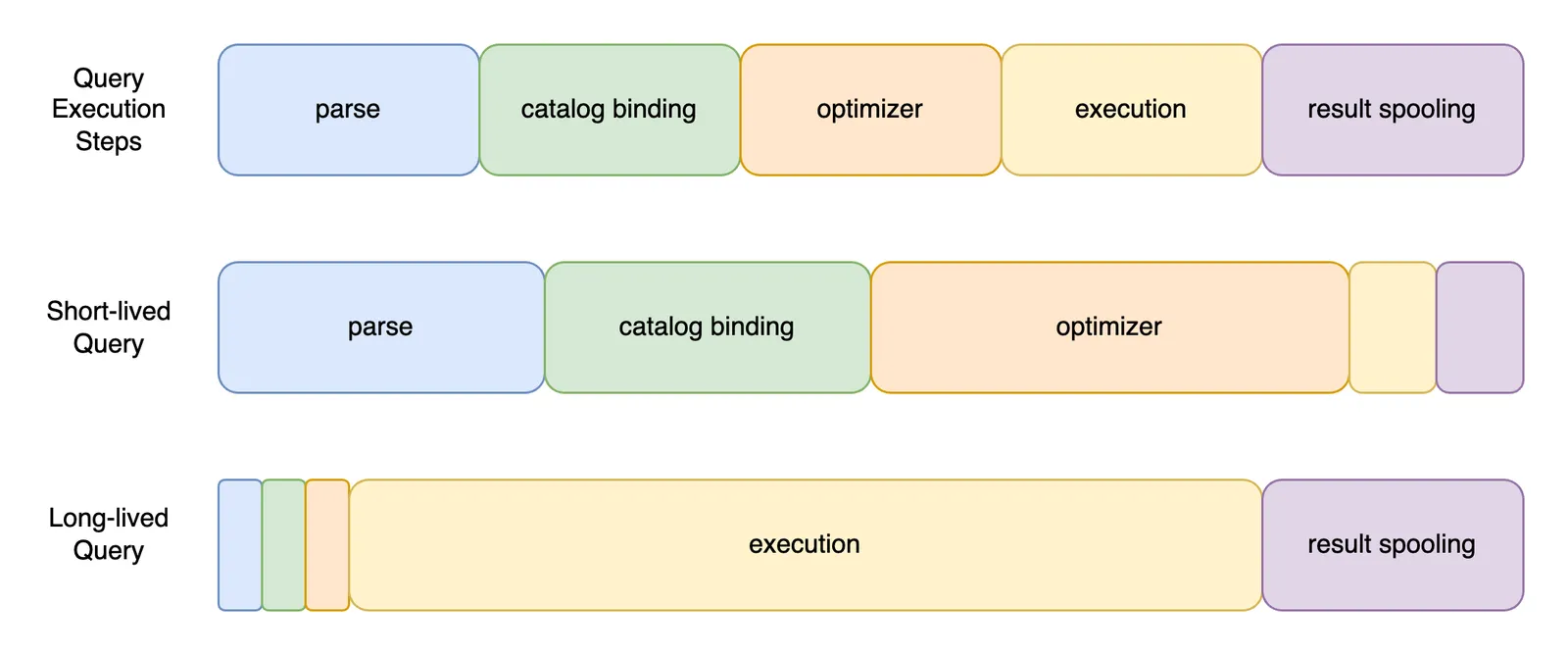
Short-lived queries spend the least amount of time in execution and are bottlenecked by analysis (middle row). Long-running queries spend the most amount of time in execution, and analysis has little impact on their latency (bottom row). The only difference between a read query from a database that fits in memory vs not is that cache misses become disk IOs that swell the query time spent in execution.
Long Running Read Queries#
Long running queries are bottlenecked by execution. The only way we speed execution is by working smarter: use indexes to read fewer rows, use more efficient data structures in memory, and execute filters lower in the tree.
One way to improve execution performance that we had not considered until recently is alternative execution architectures. It is common for databases to have multiple libraries for executing queries. Successive libraries can be progressive improvements of previous versions, optimized for different workloads or resource constraints, or partial implementations that only support a subset of operators. Users can select the best engine for their workload, the optimizer can have fixed rules for how to choose between the options based on a query or expected result set size, or an engine can adaptively switch between execution frameworks depending on runtime information.
New Execution Format#
SQL rows are shaped differently at different layers in Dolt’s stack. Keys and values for a chunk are stored as two concatenated lists of byte arrays KV pairs are zipped from the two byte lists using row-specific offsets. A row’s KVs are flattened into a physical schema ordering at the SQL layer. A table’s physical schema is filtered through to a set of projection columns. And then the SQL engine spools result rows to the MySQL wire format.
It gets more complicated the deeper you go, but the point is there are a lot of conversions. We built all of our SQL logic at the layer with the easiest semantics, but at the cost of conversion expense.
Joins are one type of query that pays a triple conversion overhead. Rows move back and forth between SQL and KV representations to do a lookup join, as shown below.
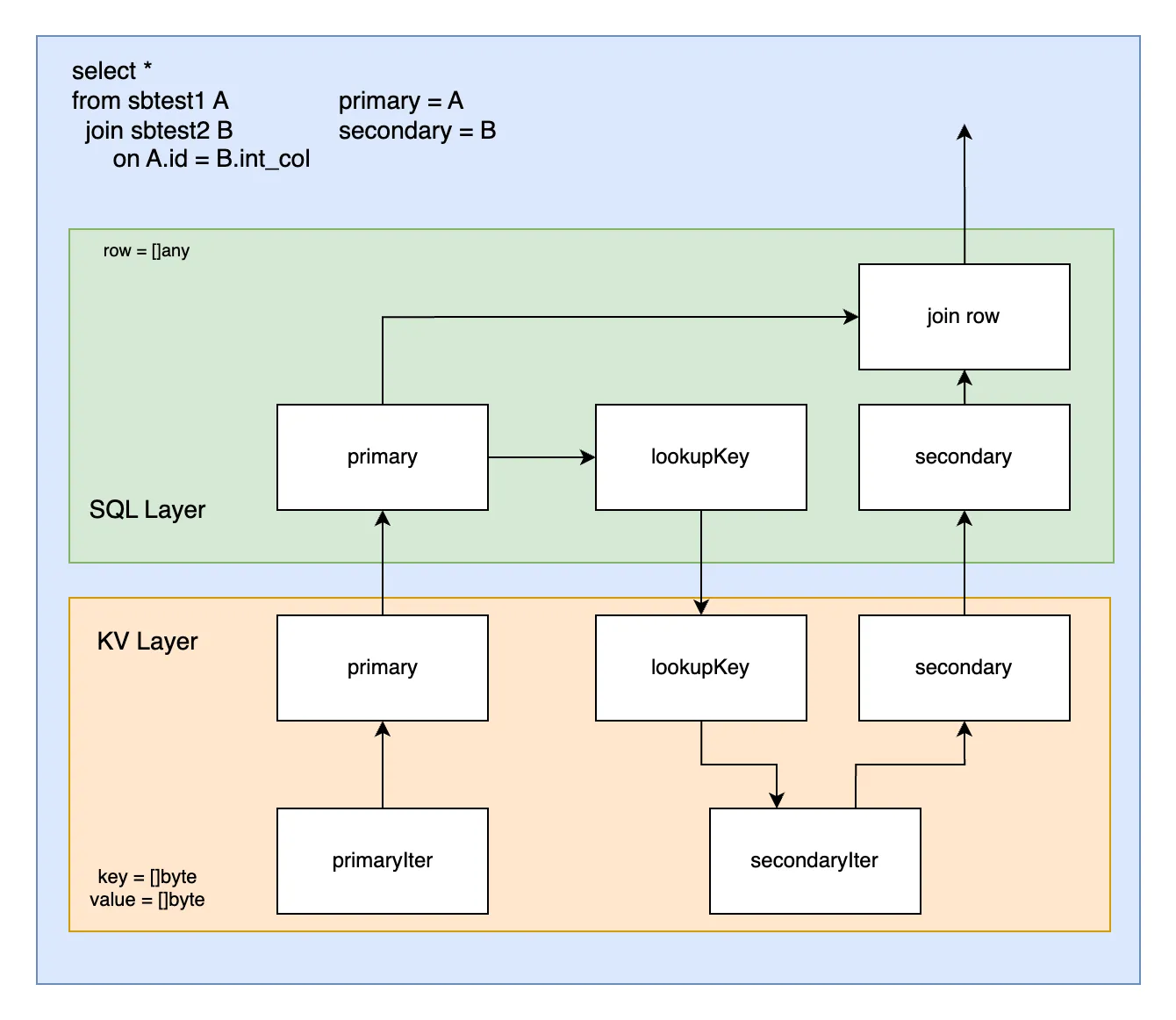
How expensive is it? A lookup join spends about half of its time converting between these layers. And so rewriting this to elide the SQL layer conversion ends up reducing join execution latency by half.
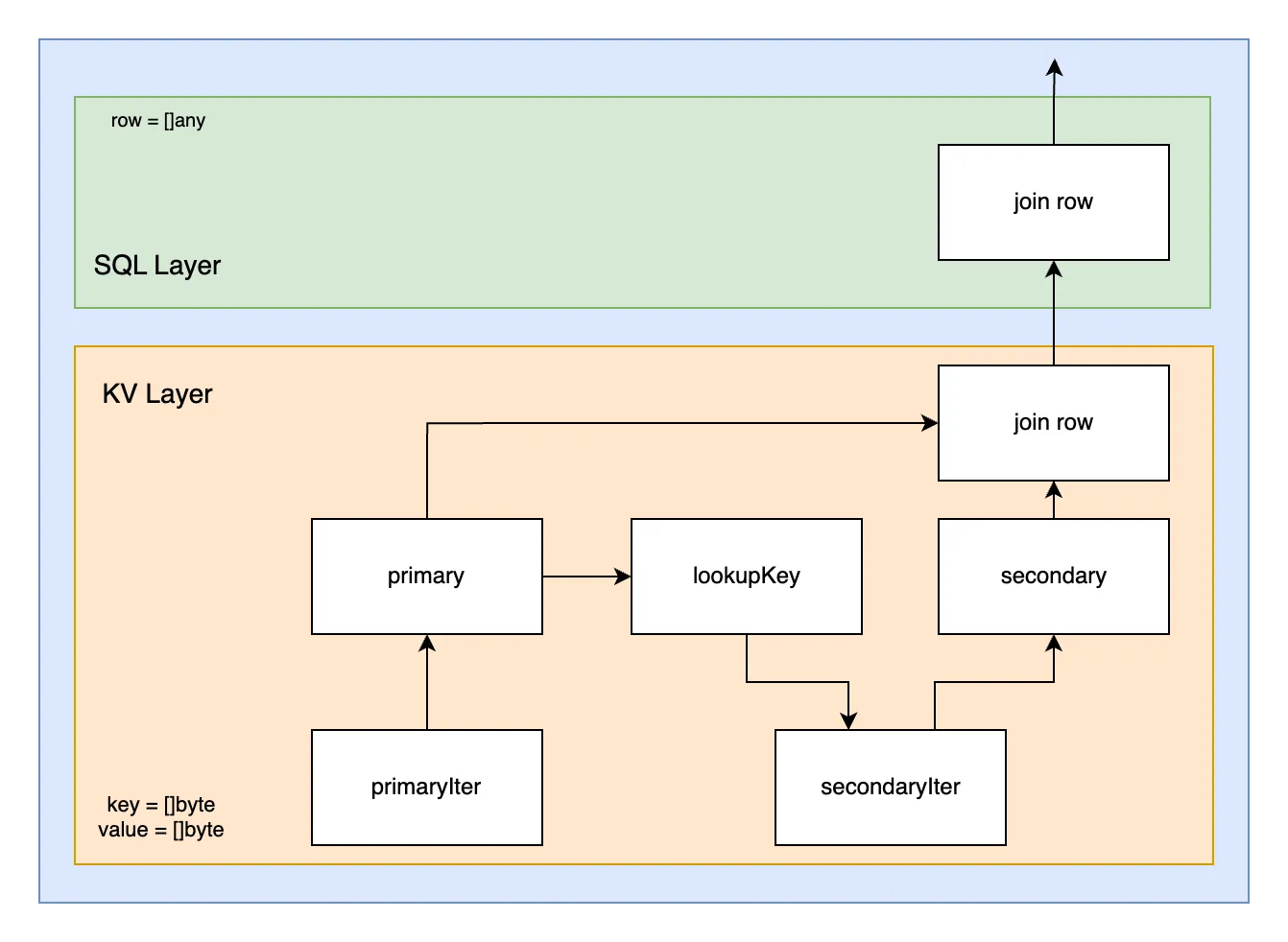
Here is the same join logic, but without translating between the SQL and KV layers. The presentation layer has delegated a portion the logic to the key-value layer and only expects a row in return. This is much more efficient.
Here is the performance difference on my MacBook before/after:
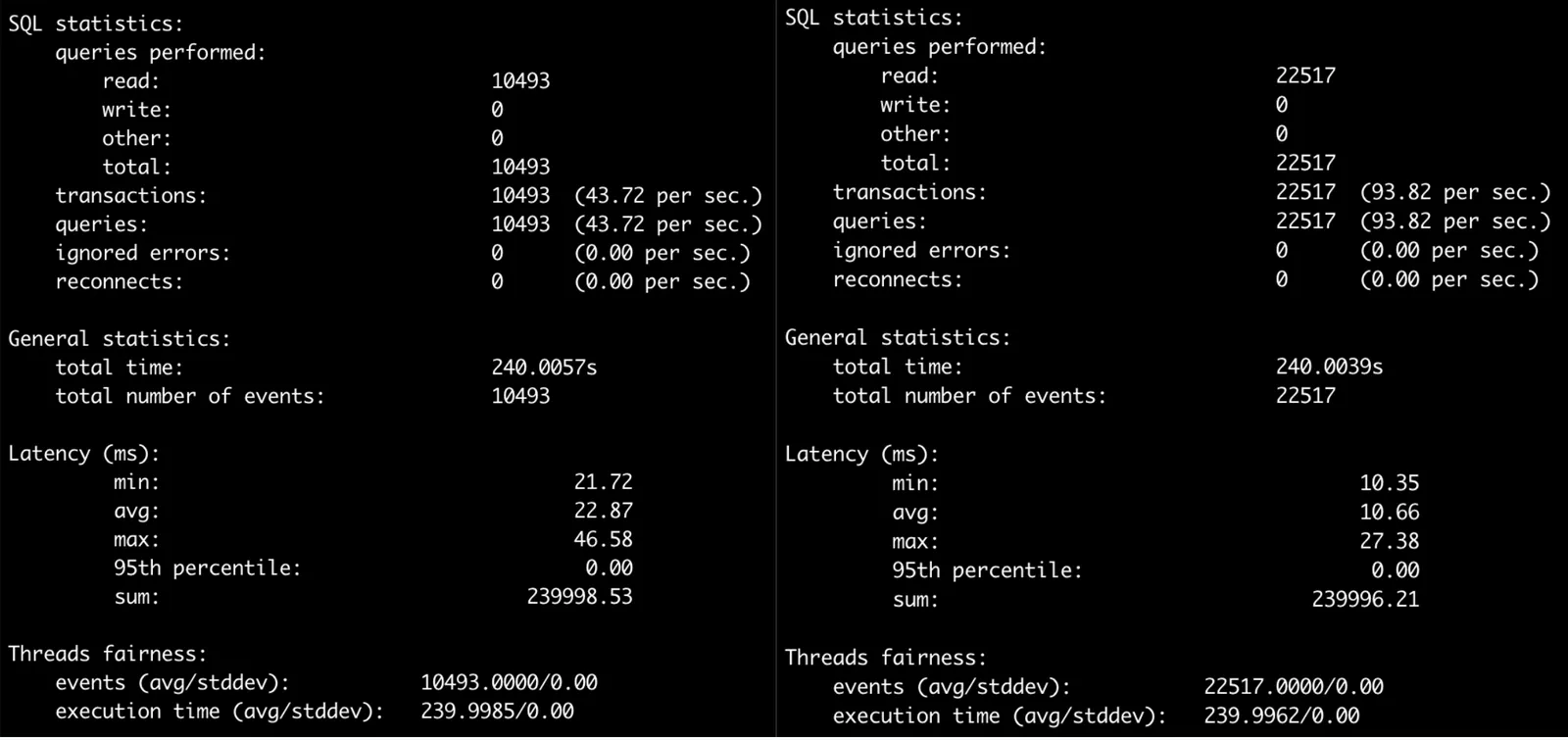
We double the throughput and half the latency by replacing the old join operator with the Dolt specific update. The new version pays the conversion penalty once only for valid join rows.
Implications#
Dipping into alternative join strategies has pros and cons. We will roll out improvements for more operators over time. For example, we may experiment with KV-side inner joins, hash joins, and merge joins. We could also fuse KV-side operators, replacing three+ table joins with KV-logic. We can also substitute different operators depending on whether we expect a query to be short or long-lived.
The main downside is that KV logic is more complicated than presentation layer logic and has a larger surface area for bugs. This can have the positive effect of expanding our testing thoroughness. But it increases the likelihood of short-term correctness regressions.
Summary#
We are continuing to revamp our SQL engine for performance. Implementing execution operators on Dolt’s native storage formats will be one important lever furthering us towards this goal.
Here is the most recently release including the change in this blog, bringing Dolt’s read average in sysbench below 2x compared to MySQL. MySQL numbers are on the left, Dolt numbers are on the right, and the latency multiplier between the two is the right-most column.
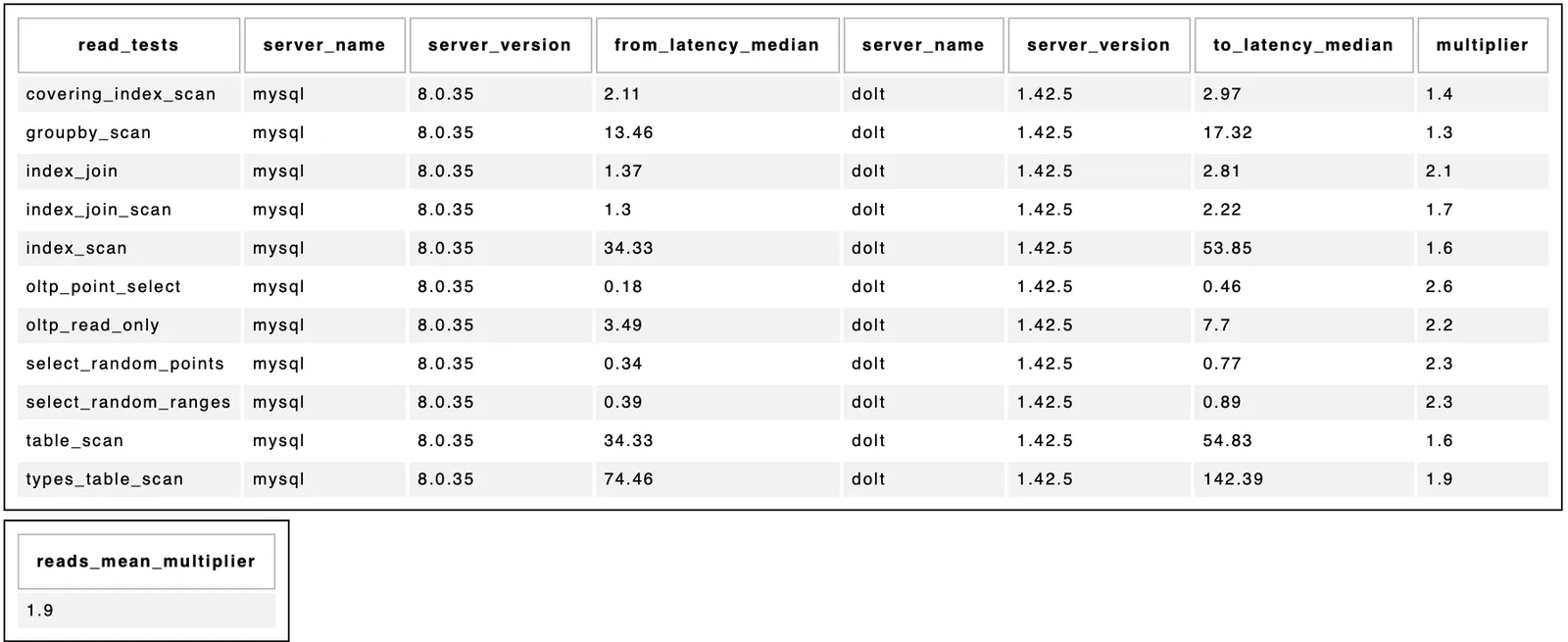
There is a lot of work to do, but we will continue making steady progress!
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!