
The first production version of Dolt was released a little over a year ago. Since then we have been narrowing the performance differences between MySQL and Dolt. We’ve blogged several times recently about improving Dolt’s transactional throughput on the TPC-C benchmark. And we are back today for another update.
Dolt is about 3x MySQL’s single client transactional performance, down from 4x a month ago.
Background#
We left off discussing how most TPC-C queries fall into three query latency buckets. Small queries (~.1-1ms) comprise the majority of transactions. COMMIT is a write bottleneck at the end of every transaction (~5ms). Certain index lookups also take about ~5ms. And then there are joins that with cache misses contribute the highest latency queries (~80ms).
The new set of improvements touches each of those latency groups. More efficient name resolution speeds small queries, many medium cardinality prefix scans are faster now, and join planning cost estimation is much faster.
The fraction of time spent in ~1ms queries will continue to increase as we trim tail latency performance. Something like 65% of query time is spent executing 1ms or below queries currently.
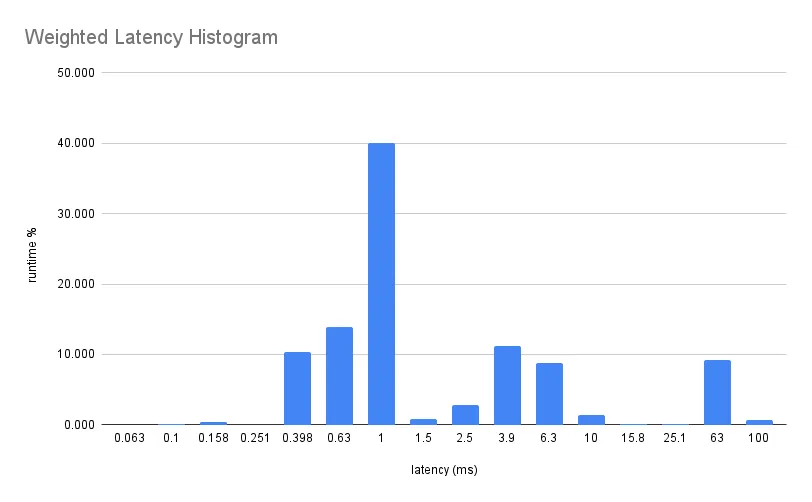
In aggregate Dolt does about 1000 queries per second with one client on TPC-C. That is about 1ms per query, adding up to an average new order transaction every 30ms.
In practice, a new order transaction will be something like 30 _ 800us queries (24ms), plus a 2 to 10ms COMMIT. The next throughput goal is 2x MySQL’s performance, which is one transaction every 20ms / 50TPS on our benchmarking hardware. For comparison, that might look like 30 _ 600us (18ms) plus a 1 to 5ms COMMIT. We have some ideas of how to get there, but it is twice as big of a performance increase compared to the 25->33TPS change.
Table List Caching#
In the last update, we used a schema hash to cache objects downstream of the table schema. When the schema changes, we compute a new set of objects that every root of the database with that schema shares.
We can apply a similar strategy to resolving table names. Before, Dolt would bind a table name string to an table object for the current transaction by:
-
Reading the table address list for a root
-
Appending a set of generated system table names (diff table, history table, …etc)
-
Scanning the list for a table name match
Each of these steps is expensive. Reading the address list deserializes an object, generated system tables create 5 tables for each user table, and then scanning the 5X bigger list can be expensive when done repeatedly.
This list of tables only changes when we create, delete, or change a table name, which is a simple number of places to invalidate a table root’s list name key.
In between changes the server will cache a map of table names, which
replaces the three steps above with two map lookups. The first accesses
the table map for a given key tableListHash->map[string], and the
second searches for the specific table name.
The fix here was surprisingly effective at speeding up small reads and writes.
Key Range Iterators#
By default, Dolt performs index scans on key ranges using binary search with a generic callback. The compare function can be arbitrarily general and represent any combination of key ranges. But the CPU overhead of the callback actually rate-limits some index scans.
The callback is particularly burdensome when the abstract “range” is
really a consecutive sequence of keys on disk. In these cases, we would
like to just read keys until we’ve reached the end of a range. We now
opportunistically try to convert generic ranges into specific
[start,end) key ranges when possible. We do this by trying to
increment the last field in a range. For example, scanning x = 1 AND y = 2 on INDEX xyz_idx(x,y,z) can be represented by reading
[(x=1,y=2),(x=2,x=3)). Instead of asking if every row is (1,2), we
create a stop cursor at (2,3) that is cheap to compare to the start
cursor.
There were three main TPC-C index scans this change targeted. They were around 5ms before the change, and pushed into the ~1ms range after the change.
SELECT o_entry_d FROM orders1 WHERE o_w_id = 1 AND o_d_id = 5 AND o_c_id = 1891 ORDER BY o_id DESC;
SELECT c_id FROM customer1 WHERE c_w_id = 1 AND c_d_id= 6 AND c_last='ABLECALLYABLE' ORDER BY c_first;
SELECT o_id, o_carrier_id, o_entry_d FROM orders1 WHERE o_w_id = 1 AND
o_d_id = 9 AND o_c_id = 1709 ORDER BY o_id DESC;MCV Truncating#
Dolt uses table statistics to choose better join plans. The distribution of index keys can be used to infer the estimated number of rows a specific table/filter combination will return. Histograms segment the keyspace into coarse buckets are simple to store and yield simple estimates.
Key distributions within buckets can be non-uniform, and one way to recapture lost signal is to track most common values (MCVs). We assume most of the bucket is uniform, and record outliers separately.
Dolt had an antipattern where we recorded a fixed set of MCVs for all buckets regardless of whether MCVs represented outliers. This added a constant and expensive overhead to cost estimation. In practice, many of Dolt’s MCVs for TPC-C tables are not statistically significant. We do better only recording MVCs that are twice as frequent as the average
Before each of ~1000 buckets had three MCVs. Those lists are fed into an estimator that manually joins two index MCV lists:
var mcvMatch int
var i, j int
for i < len(l.Mcvs()) && j < len(r.Mcvs()) {
v, err := cmp(l.Mcvs()[i], r.Mcvs()[j])
if err != nil {
return nil, err
}
switch v {
case 0:
rows += l.McvCounts()[i] * r.McvCounts()[j]
lRows -= float64(l.McvCounts()[i])
rRows -= float64(r.McvCounts()[j])
lDistinct--
rDistinct--
mcvMatch++
i++
j++
case -1:
i++
case +1:
j++
}
}As we saw in the key range section above, running key comparison function thousands of times is expensive! This is a crude measure, but useful MCVs are usually those with abnormally high frequencies. Improving statistics efficiency and accuracy is an area of active interest for us.
Lastly for reference, this is the type of TPC-C query that benefits from this improvement:
SELECT COUNT(DISTINCT (s_i_id)) FROM order_line1, stock1 WHERE ol_w_id = 1 AND ol_d_id = 4 AND ol_o_id < 3010 AND ol_o_id >= 2990 AND s_w_id= 1 AND s_i_id=ol_i_id AND s_quantity < 18;
+------------------------------------------------------------------------------------------------------------+
| plan |
+------------------------------------------------------------------------------------------------------------+
| Project |
| ├─ columns: [countdistinct([stock1.s_i_id])] |
| └─ GroupBy |
| ├─ SelectedExprs(COUNTDISTINCT([stock1.s_i_id])) |
| ├─ Grouping() |
| └─ LookupJoin |
| ├─ IndexedTableAccess(order_line1) |
| │ ├─ index: [order_line1.ol_w_id,order_line1.ol_d_id,order_line1.ol_o_id,order_line1.ol_number] |
| │ ├─ filters: [{[1, 1], [4, 4], [2990, 3010), [NULL, ∞)}] |
| │ └─ columns: [ol_o_id ol_d_id ol_w_id ol_i_id] |
| └─ Filter |
| ├─ ((stock1.s_w_id = 1) AND (stock1.s_quantity < 18)) |
| └─ IndexedTableAccess(stock1) |
| ├─ index: [stock1.s_w_id,stock1.s_i_id] |
| ├─ columns: [s_i_id s_w_id s_quantity] |
| └─ keys: 1, order_line1.ol_i_id |
+------------------------------------------------------------------------------------------------------------+Summary#
We talked about improvements that move Dolt from 4x to 3x MySQL’s TPC-C performance in single client benchmarks.
The long tail of latency is getting compressed. There are still occasional joins and index scans with antagonistic caching patterns. But COMMIT is the most consistent contributor of latency above the 1ms now. Dolt needs to amortize COMMIT latency over the duration of a 20ms query, rather than adding 5-10ms all at the end. And then we probably need to slim the 1ms queries another 20% to reach 2x MySQL’s performance.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!