
The inspiration for Dolt and DoltHub was data sharing. Most data today is shared via file. Common data formats are CSV, XML, or JSON. Dolt is a fully capable MySQL-compatible SQL database with Git-like version control. We share open source using Git. Why not share open data using Dolt?
Dolt’s SQL format has a number of advantages over alternatives in ensuring data quality. This blog will explain how SQL types and constraints can ensure data quality for data sharing or in any application.
Types#
When you define a table in SQL, you define a set of columns. Each column has a type. A column type can be a string like varchar, char, or text. String types often come with an associated maximum length like varchar(100) or char(4), meaning a variable length string of size 100 characters or a fixed length string of 4 characters respectively. A column type can be a number like int (short for integer), decimal, or float. The type of a column restricts the data and data length that can be stored in it. This can useful for data quality because an integer type column cannot, for instance, contain a string. You know what you’re going to get when you query it.
Let’s say we are building a table of the fifty US states with facts about the state. We define a name column of maximum length 30 characters and a 2 character abbreviation code.
states/main*> create table states (name varchar(30), abbreviation char(2));
states/main*> INSERT into states(abbreviation, name) values ('AK', 'Alaska'), ('AL', 'Alabama'), ('AZ', 'Arizona'), ('AR', 'Arkansas'), ('CA', 'California'), ('CO', 'Colorado'), ('CT', 'Connecticut'), ('DE', 'Delaware'), ('FL', 'Florida'), ('GA', 'Georgia'), ('HI', 'Hawaii'), ('ID', 'Idaho'), ('IL', 'Illinois'), ('IN', 'Indiana'), ('IA', 'Iowa'), ('KS', 'Kansas'), ('KY', 'Kentucky'), ('LA', 'Louisiana'), ('ME', 'Maine'), ('MD', 'Maryland'), ('MA', 'Massachusetts'), ('MI', 'Michigan'), ('MN', 'Minnesota'), ('MS', 'Mississippi'), ('MO', 'Missouri'), ('MT', 'Montana'), ('NE', 'Nebraska'), ('NV', 'Nevada'), ('NH', 'New Hampshire'), ('NJ', 'New Jersey'), ('NM', 'New Mexico'), ('NY', 'New York'), ('NC', 'North Carolina'), ('ND', 'North Dakota'), ('OH', 'Ohio'), ('OK', 'Oklahoma'), ('OR', 'Oregon'), ('PA', 'Pennsylvania'), ('RI', 'Rhode Island'), ('SC', 'South Carolina'), ('SD', 'South Dakota'), ('TN', 'Tennessee'), ('TX', 'Texas'), ('UT', 'Utah'), ('VT', 'Vermont'), ('VA', 'Virginia'), ('WA', 'Washington'), ('WV', 'West Virginia'), ('WI', 'Wisconsin'), ('WY', 'Wyoming');
Empty set (0.01 sec)
states/main*> select * from states;
+----------------+--------------+
| name | abbreviation |
+----------------+--------------+
| Wisconsin | WI |
| Illinois | IL |
| Colorado | CO |
| Alabama | AL |
| Washington | WA |
| Nebraska | NE |
| West Virginia | WV |
| Pennsylvania | PA |
| Idaho | ID |
| New Jersey | NJ |
| South Carolina | SC |
| Georgia | GA |
| Michigan | MI |
| Ohio | OH |
| Louisiana | LA |
| Alaska | AK |
| Mississippi | MS |
| Maine | ME |
| Connecticut | CT |
| Florida | FL |
| Missouri | MO |
| Massachusetts | MA |
| Arkansas | AR |
| North Carolina | NC |
| Texas | TX |
| Minnesota | MN |
| Virginia | VA |
| Montana | MT |
| Indiana | IN |
| Wyoming | WY |
| Hawaii | HI |
| Nevada | NV |
| Oklahoma | OK |
| Iowa | IA |
| New York | NY |
| Rhode Island | RI |
| Vermont | VT |
| North Dakota | ND |
| Tennessee | TN |
| California | CA |
| Delaware | DE |
| Kansas | KS |
| Arizona | AZ |
| New Mexico | NM |
| Oregon | OR |
| South Dakota | SD |
| Kentucky | KY |
| Utah | UT |
| New Hampshire | NH |
| Maryland | MD |
+----------------+--------------+
50 rows in set (0.00 sec)If we try to insert a value that does not fit our types, the insert will be rejected. Here, we try to insert a three letter abbreviation in a two character column and the insert is rejected.
states/main> insert into states(name, abbreviation) values ('District of Columbia', 'DOC');
Error 1105 (HY000): string 'DOC' is too large for column 'abbreviation'Types are the most basic way to ensure data quality. Strings must fit in the size of the column and numbers must be numbers of the appropriate definition. You can’t put a decimal value in an integer column.
Constraints#
In addition to types, SQL provides additional constraints. SQL Constraints are defined on your column or table and prevent inserts, updates, and deletes to the table or column that violate the set constraints. Just like types, constraints ensure data quality by preventing bad data from getting into your table in the first place. The database ensures data quality by defining the shape of the data that is allowed in it.
There are six possible constraints defined in SQL:
- Primary Keys
- Unique Keys
- NOT NULL
- Defaults
- Check Constraints
- Foreign Key Constraints
I will discuss how each constraint can help ensure data quality and provide a useful example for each.
Primary Keys#
Primary keys are the first type of constraint you should know. In most databases, primary keys are a unique identifier that identifies a row. A primary key must be unique. No two rows can have the same primary key. A table can only have one primary key. Primary keys can be a single column, usually a numerical “id”. Primary keys can also be multiple columns, called a “composite primary key”. If a primary key can be built from columns in the table without the use of a synthetic numerical id, the data is “naturally keyed”.
Primary keys are strongly recommended for most database tables. Tables without a primary key are called keyless tables. Keyless tables are slower to query. For tables that have a primary key, select queries are much faster if the where clause contains the primary column. Most tables you will run into in production databases will have a primary key.
Primary keys also guarantee each row is unique. This uniqueness constraint can be used to ensure data quality. For our example, we will make the state name the primary key because it is necessarily unique. Without a primary key, the table could accidentally get updated to contain two states of the same name with different facts.
Let’s first exhibit this behavior on the table defined above, which does not have a primary key.
states/main*> insert into states values('California', 'CA');
Empty set (0.01 sec)
states/main*> select * from states where name='California';
+------------+--------------+
| name | abbreviation |
+------------+--------------+
| California | CA |
| California | CA |
+------------+--------------+
2 rows in set (0.00 sec)Now, let’s try to add a primary key to the table with a duplicate row.
states/main*> alter table states add primary key(name);
Error 1062 (HY000): duplicate primary key given: [California]As you can see, the database enforces uniqueness even when trying to add a primary key to a table. Now, let’s delete the duplicate row and try again.
states/main*> delete from states where name='California' limit 1;
Empty set (0.02 sec)
states/main*> select * from states where name='California';
+------------+--------------+
| name | abbreviation |
+------------+--------------+
| California | CA |
+------------+--------------+
1 row in set (0.00 sec)
states/main*> alter table states add primary key(name);We now have a primary key on the name column.
states/main*> show create table states;
+--------+------------------------------------------------------------------+
| Table | Create Table |
+--------+------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2), |
| | PRIMARY KEY (`name`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+------------------------------------------------------------------+
1 row in set (0.00 sec)Now, if we try to create a duplicate row, the database prevents it.
states/main*> insert into states values('California', 'CA');
Error 1062 (HY000): duplicate primary key given: [California]As you can see, primary keys can be used to ensure uniqueness of rows by acting as an identifier for a row. The database will not allow you to create two rows with the same primary key.
Because I’m using Dolt for these examples, I’m going to also show off some version control features. I’m going to make a Dolt commit here so if I need to go back or compare to this database state, I can. A Dolt commit is like a Git commit.
states/main*> call dolt_commit('-Am', "First example") ;
+----------------------------------+
| hash |
+----------------------------------+
| vtull6q2e076ir7k7g0ngb80f9gvegcj |
+----------------------------------+
1 row in set (0.02 sec)Unique Keys#
What if multiple columns in my table are unique, not just the primary key? You can add another type of key called a unique key. This is like a primary key but you can have many columns in your table that have unique keys. A table can only have one primary key.
Let’s go back to our example. Why is Maine’s abbreviation ME and Massachusetts’ abbreviation MA? What if a user got confused and made Maine’s MA? Our current table schema would allow it.
states/main> update states set abbreviation='MA' where name='Maine';
Empty set (0.01 sec)
states/main*> select * from states where abbreviation='MA';
+---------------+--------------+
| name | abbreviation |
+---------------+--------------+
| Maine | MA |
| Massachusetts | MA |
+---------------+--------------+
2 rows in set (0.00 sec)Let’s add a unique key to prevent this. First, we have to put the table back how it was. After I finished the Primary Key section, I made a Dolt commit. I can always rewind to the last Dolt commit with a call dolt_reset('--hard')
states/main*> call dolt_reset('--hard');
+--------+
| status |
+--------+
| 0 |
+--------+
1 row in set (0.01 sec)
states/main> select * from states where abbreviation='MA';
+---------------+--------------+
| name | abbreviation |
+---------------+--------------+
| Massachusetts | MA |
+---------------+--------------+
1 row in set (0.00 sec)Now, I can add the unique key.
states/main> alter table states add unique key(abbreviation);
states/main*> show create table states;
+--------+------------------------------------------------------------------+
| Table | Create Table |
+--------+------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2), |
| | PRIMARY KEY (`name`), |
| | UNIQUE KEY `abbreviation` (`abbreviation`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+------------------------------------------------------------------+
1 row in set (0.00 sec)
states/main*> update states set abbreviation='MA' where name='Maine';
Error 1062 (HY000): duplicate unique key given: [MA]As you can see, the database prevents duplicate state abbreviations now.
I’ll finish off with a Dolt commit because having one was handy after the first section.
states/main*> call dolt_commit('-am', "Second example") ;
+----------------------------------+
| hash |
+----------------------------------+
| pu2ijh2p51kfcsl2u237bk6253g02h96 |
+----------------------------------+
1 row in set (0.01 sec)NOT NULL#
So up until now, you’ll notice the constraints we added were keys. Keys are not defined on a column itself. Rather, they show as a separate schema element in the table definition.
states/main*> show create table states;
+--------+------------------------------------------------------------------+
| Table | Create Table |
+--------+------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2), |
| | PRIMARY KEY (`name`), |
| | UNIQUE KEY `abbreviation` (`abbreviation`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+------------------------------------------------------------------+This is because keys are indexes. To provide the uniqueness constraints provided by primary or unique keys, you must alter the way the table is stored.
But we can also define constraints on the column itself. The first column level constraint I’ll describe is NOT NULL. A value in a database can be defined or it can be NULL. NULL is weird. You can’t compare to NULL using the equality operator =. So, =NULL will not work. You must explicitly say IS NULL or IS NOT NULL. For this and other reasons, you may not want a column to allow NULL values in it. You may want to force the column to be defined.
If we add a column to a table without specifying a default or NOT NULL constraint, all the values start off as NULL.
states/main> alter table states add column population int;
states/main*> select * from states where abbreviation='CA';
+------------+--------------+------------+
| name | abbreviation | population |
+------------+--------------+------------+
| California | CA | NULL |
+------------+--------------+------------+
1 row in set (0.00 sec)And to show off what I mean with the equality operators.
states/main*> select count(*) from states where population=NULL;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
states/main*> select count(*) from states where population IS NULL;
+----------+
| count(*) |
+----------+
| 50 |
+----------+
1 row in set (0.00 sec)
states/main*> select count(*) from states where population IS NOT NULL;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)As you can see, NULL values can cause bugs. So, we can add a NOT NULL constraint to a column. But, we can’t if the column has NULL values.
states/main*> alter table states modify column population int not null;
Error 1048 (HY000): column name 'population' is non-nullable but attempted to set a value of nullSo, we can set the population column value to 1 and then add the NOT NULL constraint.
states/main*> update states set population=1;
Empty set (0.01 sec)
states/main*> alter table states modify column population int not null;
states/main*> show create table states;
+--------+------------------------------------------------------------------+
| Table | Create Table |
+--------+------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2), |
| | `population` int NOT NULL, |
| | PRIMARY KEY (`name`), |
| | UNIQUE KEY `abbreviation` (`abbreviation`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+------------------------------------------------------------------+
1 row in set (0.00 sec)Now, let’s try to set a population value to NULL.
states/main*> update states set population=NULL where name='California';
Error 1048 (HY000): column name 'population' is non-nullable but attempted to set a value of nullThe database prevents us from having NULL values in the population column. Let’s finish off with a Dolt commit.
states/main*> call dolt_commit('-am', "Third example");
+----------------------------------+
| hash |
+----------------------------------+
| cnjqr9rs0np4dci7md11baaf4p9llar6 |
+----------------------------------+
1 row in set (0.01 sec)Defaults#
Defaults are another column level constraint. The default value of a column is the value assigned to the row if the value being assigned to the column is NULL. Defaults are useful in ensuring data quality by always assigning some value to a column.
Let’s assign a default value of 0 to the population column of our table so we can add our NOT NULL constraint. In order for a default value to be populated we must drop and re-add the column.
states/main> alter table states drop column population;
states/main*> alter table states add column population int not null default 0;
states/main*> select * from states where abbreviation='CA';
+------------+--------------+------------+
| name | abbreviation | population |
+------------+--------------+------------+
| California | CA | 0 |
+------------+--------------+------------+
1 row in set (0.00 sec)Defaults can be functions of other columns in the table. For instance, we could make the default for the abbreviation column be the first two letters of the state name, upper cased.
states/main*> alter table states modify column abbreviation char(2) default(UPPER(LEFT(name, 2)));Now, I’ll add the District of Columbia, even though it’s not a state to test our new abbreviation default.
states/main*> insert into states(name) values ('District of Columbia');
Empty set (0.01 sec)
states/main*> select * from states where name='District of Columbia';
+----------------------+--------------+------------+
| name | abbreviation | population |
+----------------------+--------------+------------+
| District of Columbia | DI | 0 |
+----------------------+--------------+------------+
1 row in set (0.00 sec)As you can see, defaults can play a powerful role in ensuring data quality by assigning likely values to columns instead of having rows with NULL values.
We’ll finish off with a Dolt commit.
states/main*> call dolt_commit('-am', "Fourth example");
+----------------------------------+
| hash |
+----------------------------------+
| rqo26f81k8gfkf1qqilvi3h1bnp31pft |
+----------------------------------+
1 row in set (0.01 sec)Check Constraints#
Check constraints are very powerful. Check constraints allow you to define properties of a column that must be true using SQL. The database will not allow values that do not match check constraints to be inserted into the table.
To show off check constraints I need some real state populations. I headed over to ChatGPT and had it build me a SQL query to update all the populations as of the 2020 census into my table. After a bit of prompting, I got the following:
states/main> UPDATE states SET population = CASE name
-> WHEN 'Alabama' THEN 5024279
-> WHEN 'Alaska' THEN 733391
-> WHEN 'Arizona' THEN 7151502
-> WHEN 'Arkansas' THEN 3011524
-> WHEN 'California' THEN 39538223
-> WHEN 'Colorado' THEN 5773714
-> WHEN 'Connecticut' THEN 3605944
-> WHEN 'Delaware' THEN 989948
-> WHEN 'Florida' THEN 21538187
-> WHEN 'Georgia' THEN 10711908
-> WHEN 'Hawaii' THEN 1455271
-> WHEN 'Idaho' THEN 1839106
-> WHEN 'Illinois' THEN 12812508
-> WHEN 'Indiana' THEN 6785528
-> WHEN 'Iowa' THEN 3190369
-> WHEN 'Kansas' THEN 2937880
-> WHEN 'Kentucky' THEN 4505836
-> WHEN 'Louisiana' THEN 4657757
-> WHEN 'Maine' THEN 1362359
-> WHEN 'Maryland' THEN 6177224
-> WHEN 'Massachusetts' THEN 7029917
-> WHEN 'Michigan' THEN 10077331
-> WHEN 'Minnesota' THEN 5706494
-> WHEN 'Mississippi' THEN 2961279
-> WHEN 'Missouri' THEN 6154913
-> WHEN 'Montana' THEN 1084225
-> WHEN 'Nebraska' THEN 1961504
-> WHEN 'Nevada' THEN 3104614
-> WHEN 'New Hampshire' THEN 1377529
-> WHEN 'New Jersey' THEN 9288994
-> WHEN 'New Mexico' THEN 2117522
-> WHEN 'New York' THEN 20201249
-> WHEN 'North Carolina' THEN 10439388
-> WHEN 'North Dakota' THEN 779094
-> WHEN 'Ohio' THEN 11799448
-> WHEN 'Oklahoma' THEN 3959353
-> WHEN 'Oregon' THEN 4237256
-> WHEN 'Pennsylvania' THEN 13002700
-> WHEN 'Rhode Island' THEN 1097379
-> WHEN 'South Carolina' THEN 5118425
-> WHEN 'South Dakota' THEN 886667
-> WHEN 'Tennessee' THEN 6910840
-> WHEN 'Texas' THEN 29145505
-> WHEN 'Utah' THEN 3271616
-> WHEN 'Vermont' THEN 643077
-> WHEN 'Virginia' THEN 8631393
-> WHEN 'Washington' THEN 7693612
-> WHEN 'West Virginia' THEN 1793716
-> WHEN 'Wisconsin' THEN 5893718
-> WHEN 'Wyoming' THEN 576851
-> END
-> WHERE name IN (
-> 'Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado', 'Connecticut', 'Delaware', 'Florida', 'Georgia',
-> 'Hawaii', 'Idaho', 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana', 'Maine', 'Maryland', 'Massachusetts',
-> 'Michigan', 'Minnesota', 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada', 'New Hampshire', 'New Jersey',
-> 'New Mexico', 'New York', 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon', 'Pennsylvania', 'Rhode Island',
-> 'South Carolina', 'South Dakota', 'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington', 'West Virginia',
-> 'Wisconsin', 'Wyoming'
-> );
Empty set (0.01 sec)Not the prettiest SQL but it works! Pretty cool use of generative AI. This saved me a bunch of time.
So, let’s say we wanted to make sure all the populations are less than 40M and greater than 500,000. This is where check constraints come in. These are just a couple of facts we can encode in check constraints but you can imagine a bunch more.
states/main*> alter table states add check (population < 40000000);
states/main*> alter table states add check (population > 500000);
Error 1105 (HY000): check constraint is violated.Huh? I wonder what state is smaller than 500,000 people.
states/main*> select * from states where population < 500000;
+----------------------+--------------+------------+
| name | abbreviation | population |
+----------------------+--------------+------------+
| District of Columbia | DI | 0 |
+----------------------+--------------+------------+
1 row in set (0.00 sec)My check constraint found my fake District of Columbia example! This shows the power of check constraints. Let’s delete that row and add the constraint.
states/main*> delete from states where name='District of Columbia';
Empty set (0.01 sec)
states/main*> alter table states add check (population > 500000);
states/main*> show create table states;
+--------+-----------------------------------------------------------------------+
| Table | Create Table |
+--------+-----------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2) DEFAULT (upper(LEFT(`name`, 2))), |
| | `population` int NOT NULL DEFAULT '0', |
| | PRIMARY KEY (`name`), |
| | UNIQUE KEY `abbreviation` (`abbreviation`), |
| | CONSTRAINT `states_chk_hl70piav` CHECK ((`population` < 40000000)), |
| | CONSTRAINT `states_chk_baqs6ebf` CHECK ((`population` > 500000)) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+-----------------------------------------------------------------------+
1 row in set (0.00 sec)And we’ll make a Dolt commit to finish off this example.
states/main*> call dolt_commit('-am', "Fifth example");
+----------------------------------+
| hash |
+----------------------------------+
| i7378p2nao32rhipgtorsdseacfi5djq |
+----------------------------------+
1 row in set (0.01 sec)Foreign Keys#
Data in SQL databases is often structured in multiple, related tables that are intended to be joined together. Foreign key constraints allow you to make sure a value in your table exists in another table, resulting in proper joins. This type of constraint is useful in verifying data across multiple tables is correctly inserted.
Let’s continue our example. Let’s add a country table and a country column in the states table. Then, we’ll add a foreign key to make sure a state always has a country defined in the countries table.
First, we add the countries table and populate it with the United States.
states/main*> create table countries (name varchar(30) primary key, abbreviation char(2));
states/main*> insert into countries values ('United States', 'US');
Empty set (0.01 sec)Then we add a country column to the states column and populate it correctly.
states/main*> alter table states add column country varchar(30);
states/main*> update states set country='United States';
Empty set (0.01 sec)Now, we’re ready to add the foreign key. This forces the country names in the states table to exist in the countries table.
states/main*> alter table states add foreign key (country) references countries(name);
states/main*> show create table states;
+--------+---------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+---------------------------------------------------------------------------------------+
| states | CREATE TABLE `states` ( |
| | `name` varchar(30) NOT NULL, |
| | `abbreviation` char(2) DEFAULT (upper(LEFT(`name`, 2))), |
| | `population` int NOT NULL DEFAULT '0', |
| | `country` varchar(30), |
| | PRIMARY KEY (`name`), |
| | UNIQUE KEY `abbreviation` (`abbreviation`), |
| | KEY `country` (`country`), |
| | CONSTRAINT `states_ibfk_1` FOREIGN KEY (`country`) REFERENCES `countries` (`name`), |
| | CONSTRAINT `states_chk_hl70piav` CHECK ((`population` < 40000000)), |
| | CONSTRAINT `states_chk_baqs6ebf` CHECK ((`population` > 500000)) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+--------+---------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Now if we try to insert a “state”, in this case province, from another country, the database prevents us from making that mistake. We must first add Canada as a country if we want to populate the states table with states from other countries.
states/main*> insert into states(name, abbreviation, population, country) values ('Ontario', 'ON', 14734014, 'Canada');
Error 1452 (HY000): cannot add or update a child row - Foreign key violation on fk: `states_ibfk_1`, table: `states`, referenced table: `countries`, key: `[Canada]`And finally, we’ll again finish off with a Dolt commit.
states/main*> call dolt_commit('-Am', 'Last example');
+----------------------------------+
| hash |
+----------------------------------+
| 6bms0qli11sld5ntqs1aiq1613g5hga1 |
+----------------------------------+
1 row in set (0.01 sec)SQL for Data Sharing#
As you can see, SQL allows you to define the shape of your data in the schema. So, why do we share data in schemaless formats like CSV?
SQL databases used to be hard to share. Most SQL databases optimize for query performance. Thus, the storage format was designed for speed, not sharing. Most of the time, you can’t just copy the disk contents of a SQL database, paste it onto another machine, and read the data. For sharing, there’s CSV exports, SQL dumps, and backup utilities. If you want to share the contents of a SQL table, the easiest way was to export to CSV, but you lose the schema of the database.
We have a new storage format in Dolt, designed from the ground up to be shared. Just like Git allows for distributed sharing and collaboration through history, branch, and merge of files, Dolt provides these same tools to SQL tables. I’m going to share the database I just created with the world.
First, I create the database on DoltHub.
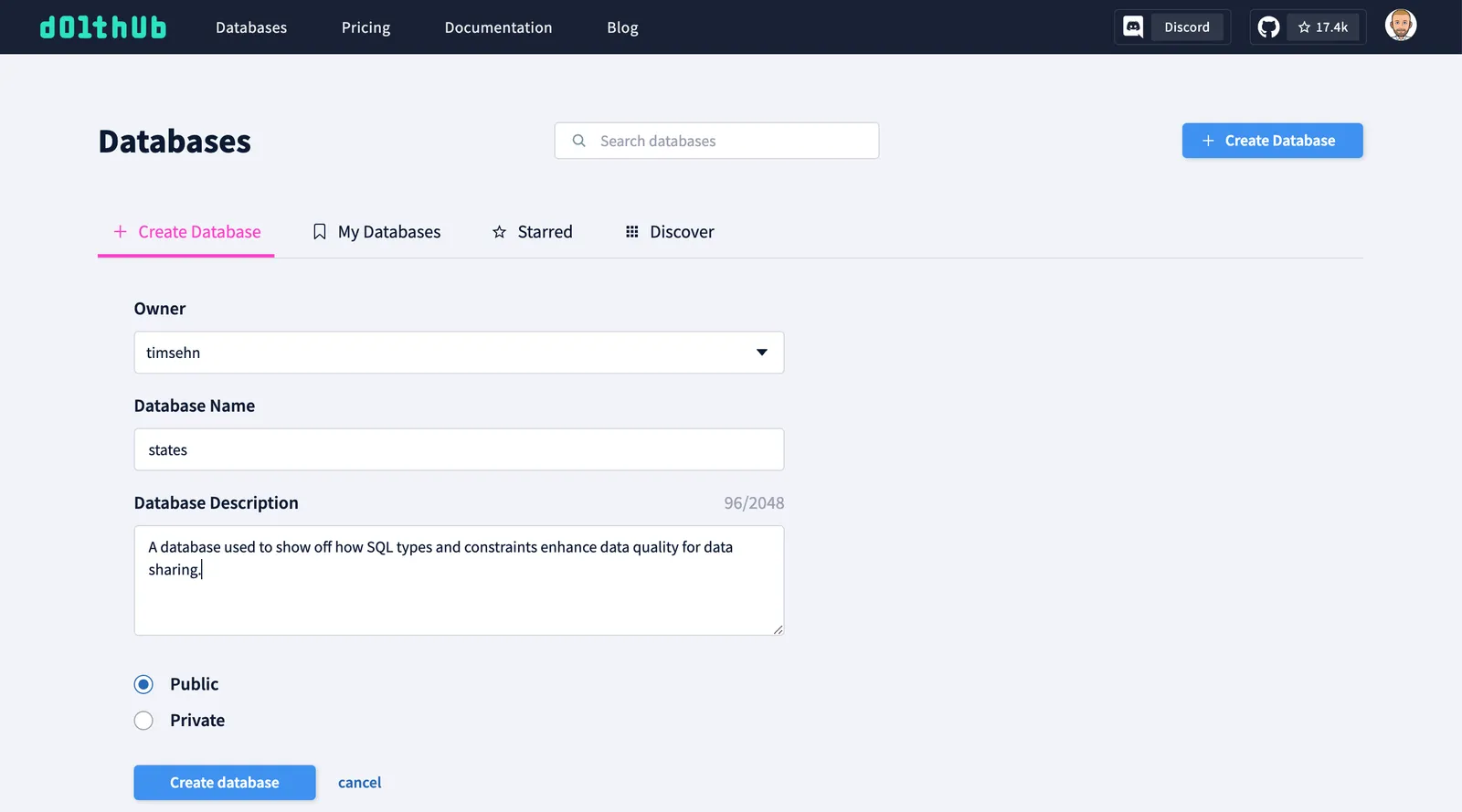
Then I set that database as my database’s remote and push, just like Git.
states/main> call dolt_remote('add', 'origin', 'timsehn/states');
+--------+
| status |
+--------+
| 0 |
+--------+
1 row in set (0.02 sec)
states/main> call dolt_push('origin', 'main');
+--------+-----------------------------------------------------+
| status | message |
+--------+-----------------------------------------------------+
| 0 | To https://doltremoteapi.dolthub.com/timsehn/states |
| | * [new branch] main -> main |
+--------+-----------------------------------------------------+
1 row in set (2.46 sec)Now, the world can have read and write access to my database. Writes can be appropriately permissioned and done through a fork and pull request workflow, just like open source on GitHub.
A random person looking at this database has a good idea from the schema, the types and constraints, what the data is intended for and how it is structured. This is in contrast to a CSV where they would have to guess how the data should be structured. Can population be NULL? Can I have a three letter abbreviation? SQL should be the language of data sharing.
Conclusion#
SQL is a great language for data sharing because the schema describes the shape of the data using types and constraints. Schemaless sharing is an artifact of a past world where copying databases was hard. Sharing databases with schema and data using Dolt is the future of data sharing. Curious to learn more? Stop by our Discord and we’d be happy to chat about data quality.