
Last month we announced that we were making changes to how Dolt stores JSON documents, in order to make Dolt best-in-class for manipulating JSON within a SQL database. Today, we’re going to explore exactly what that means, how we accomplished it, and why Dolt’s unique features help it stand out.
Dolt’s most powerful feature has always been our fast diff and merge, powered by Prolly Trees. Comparing database branches is fast and easy, even if those branches are on different forks of the database running on different machines. Just like Git, pulling changes from upstream is fast when the changes are small, even if those changes have to be merged in. This makes Dolt a no-brainer for version controlling large datasets in a decentralized manner.
But for most of Dolt’s life, this sweet deal came with a pretty large caveat: while we were really good at diffing and merging table data, diffing and merging JSON documents within the table was slow. We’ve supported merging concurrent changes to JSON values since January, but we did it by deserializing both documents and loading them both into memory. For large documents with small changes, this was noticeably, painfully slow compared to the rest of the merge process. And this always felt like a missed opportunity. Not everyone is using JSON, but if you are, why wouldn’t you want to diff and merge it just like you do with all your other data?
There was no technical reason why we had to be this slow. Prolly trees are the fantastic data structure that make version controlled relational data possible, but they’re not limited to relational data. Prolly trees were originally created for Noms, which was a NoSQL document store, and Dolt still has a lot of Noms DNA in it.
We wanted to see if we could leverage this to build a better document store within Dolt. Dolt is still a relational database first and foremost, but we believe Dolt can provide the best of both worlds.
The Challenge#
When we started our JSON investigation, we realized that it wasn’t just version control features that were slow. Most of our JSON operations were slow. But to be fair, the competition wasn’t much better. MySQL’s JSON handling is notoriously slow. Postgres has Generalized Inverted Indexes (GINs) that allow for fast document filtering and indexing, but is sluggish at modifying documents. Looking at the current state of the ecosystem, we realized that this could be an opportunity to speed up all JSON operations in Dolt, not just the version control ones.
If we could accomplish that, then Dolt could boast the fastest SQL engine for working with JSON. We could make Dolt the perfect solution for anyone looking to combine relational data and documents.
We looked at how Dolt was currently being used and came up with a list of requirements:
- We learned that the most common use for JSON columns in a SQL database is to treat it as an opaque value, with all JSON logic handled entirely by the client. In these usage patterns, the JSON column is essentially a text column with additional JSON validation: its structure is not used to filter queries, and queries do not select its individual keys. The client application modifies the returned value, and writes the new result back to the database.
- In places where the structure is used in MySQL (the SQL dialect that Dolt implements), the idiomatic way to use it is to add a generated column that transforms the SQL value, and then to query the original or generated column, as needed. While the ISO standard for JSON defines functions for inspecting and manipulating JSON, these are not often used in queries.
- We believe this is a chicken-and-egg problem: Users avoid JSON manipulation on the server because it’s slow, it’s slow because it’s not prioritized, and it’s not prioritized because users avoid it.
- Since the most common operation was simply reading JSON from the database, it was vital to not compromise on this access pattern: no matter how we store JSON data, we must be able to materialize it back into JSON as quickly as possible. Any optimizations must work within this constraint.
There’s an obvious way to optimize reading JSON without inspecting it: simply store the document as a text blob. Querying the column would be as simple as reading the bytes currently in storage, with zero overhead.
In fact, this was how our previous implementation worked. It’s trivially the fastest at reading JSON, but comes at the cost of every single other operation that a user might care about. And that cost is why no other engine that we’re aware of does this: every engine we looked at uses a custom binary encoding, designed to optimize lookups in the document, at the cost of adding overhead to simple selects. But we wanted to minimize this tradeoff as much as possible.
The High Level Approach#
Dolt uses Prolly Trees because they give us two very important properties: history independence and structural sharing. These are both incredibly valuable properties for a distributed database. Structural sharing in particular means that two tables that differ only slightly can re-use storage space for the parts that are the same. Most SQL engines obtain structural sharing for tables by using B-trees or a similar data structure… but that doesn’t extend easily to JSON documents. Some tools like Git and IPFS achieve structural sharing for directories by using a tree structure that mirrors the directory… but that creates a level of indirection for each layer of the document, which would slow down queries if the document had too many nested layers. Something else was needed.
From the get-go, we had one key insight that governed our approach: Dolt is really good at diffing and merging tables, because a Prolly Tree is very good at representing a flat data structure. If we could represent a JSON document as a flat table, then we could store it a Prolly Tree, and we could apply the same algorithms optimizations on it that we do for tables.
For example, if you had a JSON document that looked like this:
{
"a": "value1",
"b": {
"c": "value2",
"d": "value3"
},
"e": ["value4", "value5"]
}You could visualize that document as a table, like this:
+--------+----------+
| key | value |
+--------+----------+
| $.a | "value1" |
| $.b.c | "value2" |
| $.b.d | "value3" |
| $.e[0] | "value4" |
| $.e[1] | "value5" |
+--------+----------+This principle guided our entire design and implementation process. We started with a straightforward implementation that stored JSON as a table identical to the one you see above. But it turned out to have several drawbacks:
- Like I said before, the most common workflow for JSON documents in SQL databases is simply returning them in the result set. This requires converting the document from its internal representation into standard JSON. And the more processing that needs to be done, the more overhead this creates. While engines like Postgres and MySQL define their own custom binary encoding for documents, their encoding has enough structural similarities to JSON that the overhead is minimal. But converting a table like this into a JSON object would require so much processing that for simple queries, the processing would take longer than the rest of the query combined.
- For deeply nested documents, storing every possible path into the object would require asymptotically more space than the original document. This was simply not acceptable.
- Such a drastic change to how documents were represented in the database would likely mean that older databases would need to do expensive migrations to the new format, while older versions of Dolt wouldn’t be able to read newer databases . Since one of the main purposes of Dolt is to share databases the way Git shares file systems, we decided that was unacceptable too.
We were confident that representing a document as a relational table was the correct way to extend all of Dolt’s functionality to documents, but we knew we needed to do it in a way that made it possible to quickly convert back to JSON, without inflating the amount of storage needed.
Our requirements felt like a set of contradictions:
- We needed to be able to make small mutations quickly, like deleting a key, while reusing any parts of the document that didn’t change.
- But we couldn’t mirror the shape of the document or else deeply nested objects would be slow.
- We needed to store documents in a way that closely resembled actual JSON so we could return it quickly.
- But we also needed to be able to view the document as a flat table that mapped paths to values.
- And we also couldn’t store every possible path in the document, since simply listing all those paths would require storage space we didn’t have.
Here’s how we accomplished it anyway.
Brief Aside: The Storage Layer and Merkle Trees#
All data in Dolt is stored as content-addressed chunks. If a value is too large to fit in a single chunk, it gets broken up into multiple chunks, and each of those chunks becomes the leaf nodes of a Merkle tree. Each node holds the address of the nodes below it, and the the address of the root node is used to refer to the entire value.
All values in Dolt get stored this way, be it tables, strings, or JSON documents. When the engine needs to read an entire value, it walks the entire tree, assembling the full value from its individual chunks.
But often, only part of the value is actually needed. So Dolt can label the edges of this tree, adding a key, and then use those keys to quickly find the chunk containing the relevant data.
There’s a lot that gets glossed over here. Writing a value into the data store has a number of important design decisions, such as:
- How should we divide the original value into chunks? Where do we draw the boundaries?
- How do we label the edges of the tree in order to find data quickly?
These decisions have a huge impact on our ability to make changes to the value while still maintaining structural sharing and history independence. But for simply reading the value, these decisions don’t matter at all. The engine does not need to understand the tree labels or the chunking algorithm in order to read the value.
This turned out to be the critical piece of the puzzle. At the time, we were storing JSON documents as text blobs, because this was the fastest way to read them back out, at the expense of every other operation. And like every other data type, if a document was too large, it would be split up into multiple chunks in a Merkle tree. But the labels on this tree were completely unused: existing Dolt engines neither wrote to these labels, nor read from them. If a newer version of Dolt added labels to the tree or made changes to the chunking algorithm, older versions of Dolt would still be able to read them. And those reads would still be fast, with practically no overhead.
We realized that we could leverage this in order to store JSON documents in a Prolly Tree. A Prolly Tree is, at its core, a special type of Merkle tree with extra rules about how to serialize data into its leaf nodes. Existing Dolt engines would treat these new trees identically to the old ones. But newer engines would be able to leverage these extra rules to perform additional optimizations.
The Solution#
When Dolt writes a JSON document into storage, it normalizes the document by sorting the keys in each object. It then divides the document into tokens, in such a way that any value (including composite values like arrays and objects) starts and ends on a token boundary. We then gave each boundary a name, in a manner similar to JSONPath. These names are ordered: given two names, we could know with certainty which came first within the document.
In order to determine chunk boundaries, we perform a rolling hash on these tokens. We have a custom rolling hash chunker implementation that we use to ensure that chunks fall within a certain distribution of sizes. Whenever the chunker draws a new chunk boundary, we label that chunk with the name of that boundary. Effectively, the name tells us the last token that was parsed before ending the chunk.
Since the tokens are ordered, we can use these names as keys in a search tree. If we have the name of a location and want to determine whether that location exists in the document, we can do a K-ary search and identify the only chunk that can possibly contain that location. And since we also gave a name to the boundary marking the start of the chunk, we can scan forward from that position to find the target location.
This is best demonstrated with an example.
Suppose we insert the same JSON document from before:
{
"a": "value1",
"b": {
"c": "value2",
"d": "value3"
},
"e": ["value4", "value5"]
}The chunker might end up splitting the document into these chunks.
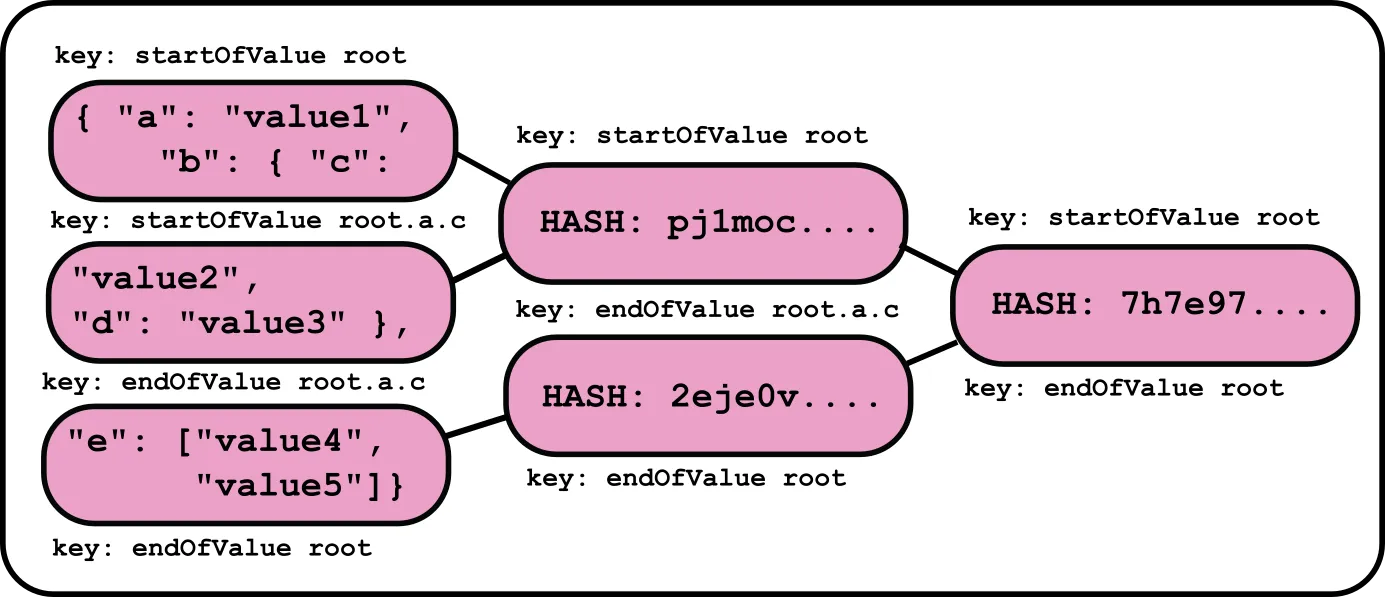
Of course, in a real example, the chunks would be much larger.
Now if we wanted to insert an additional value into the document, (say, inserting the string "JSON is fun" at location root.c2), we can quickly determine by comparing the boundary keys that chunk 1 is the only chunk that could possibly contain this value. Dolt scans forward from the start of the chunk, identifying where the specified location would be. It then reruns the rolling hash chunker to see if the position of the next boundary has moved as a result of that insertion. The most likely outcome is that no boundaries have shifted, and the new value of the document looks like this:

The blue nodes are the ones that have changed between the new and old trees. Dolt will reuse chunk 0 and chunk 2. Existing references to the old object (such as on another branch) will use the same storage for these chunks as the new value.
With this approach, any of Dolt’s Prolly Tree based algorithms can be extended to work on JSON documents as well as tables. Version control, fast diffing, and three way merging with automatic conflict resolution are all now on the table. If you have two large documents with a small number of differences between them, Dolt can quickly identify which chunks have changed, ignoring every chunk that stayed the same.
This approach solves all of our problems from before:
- The performance of reading JSON documents from storage is completely unaffected. It continues to have practically zero overhead.
- We are now effectively storing a small amount of additional metadata alongside the document: a single JSON path per chunk, which has no meaningful impact on storage requirements unless your paths are absurdly long.
- JSON documents written using this strategy remain readable by existing versions of Dolt. Existing documents get automatically updated to this new strategy whenever an engine running a newer version of Dolt writes to them. Thus, no user is required to update Dolt or migrate their databases (although there are now performance benefits for doing so.)
Conclusion#
We think this is a pretty novel and powerful approach to storing structured data. Using Prolly Trees to represent structured data allows for easy and instant copies of even enormous documents, efficient diffing of these documents, and deduplication of common structures on disk.
There’s lots of use cases for this power, but the one we love the most is version control. We believe that everything should be version controlled. Especially your databases. And especially the documents that you store in those databases, even if you’re storing JSON in a SQL database. We think mixing JSON and SQL is like mixing chocolate and peanut butter: there’s no reason you can’t get the best of both worlds.
If you have a use case and you’re not sure if Dolt can help, drop us a line on Discord or Twitter. We take user requests seriously: just see our 24 Hour Pledge for fixing bugs! We’re happy to help you figure out how Dolt can improve your database.