
Multiversion concurrency control (MVCC) is a technique relational databases use to avoid concurrent transactions blocking one another. This is how databases move beyond the performance limitations of two-phase locking. Most databases have converged on what MVCC “looks like”, so that e.g. MySQL and PostgreSQL (Postgres) implement MVCC in a way that seems similar to users despite having very different storage layouts.
Dolt is a relational database with similarities to MySQL and Postgres. But Dolt implements Git semantics, a very different flavor of versioning. Git is a safety-first MVCC, even though the two models usually occupy different worlds. Git uses branches to isolate units of work offline. The way branches are isolated and coordinated is similar to long-lived transactions. Concurrent writers do not block one another, but conflicting edits are materialized when coordinating commits.
We will compare three MVCC implementations, two B-Trees and one Merkle Tree. We will see that MySQL, Postgres, and Dolt’s nuances are mostly opaque to users. For example, default isolation modes and conflict resolution look similar between the three. But storage layouts have interesting effects on anomaly detection and lifecycle maintenance.
Storage#
There are multiple ways to perform lockless concurrent transactions (see section 2), but multiversion optimistic concurrency control (MVOCC) is the most common choice for commercial databases. All forms of MVOCC persist multiple versions of records to disk. This lets concurrent transactions share storage without confusing which rows are visible to which transactions.
Postgres#
Postgres uses append-only storage to write multiple row versions. The diagram below shows how rows are written as a linked list with most recent keys added to the end of the list. This is called oldest-to-newest (O2N) append only storage:
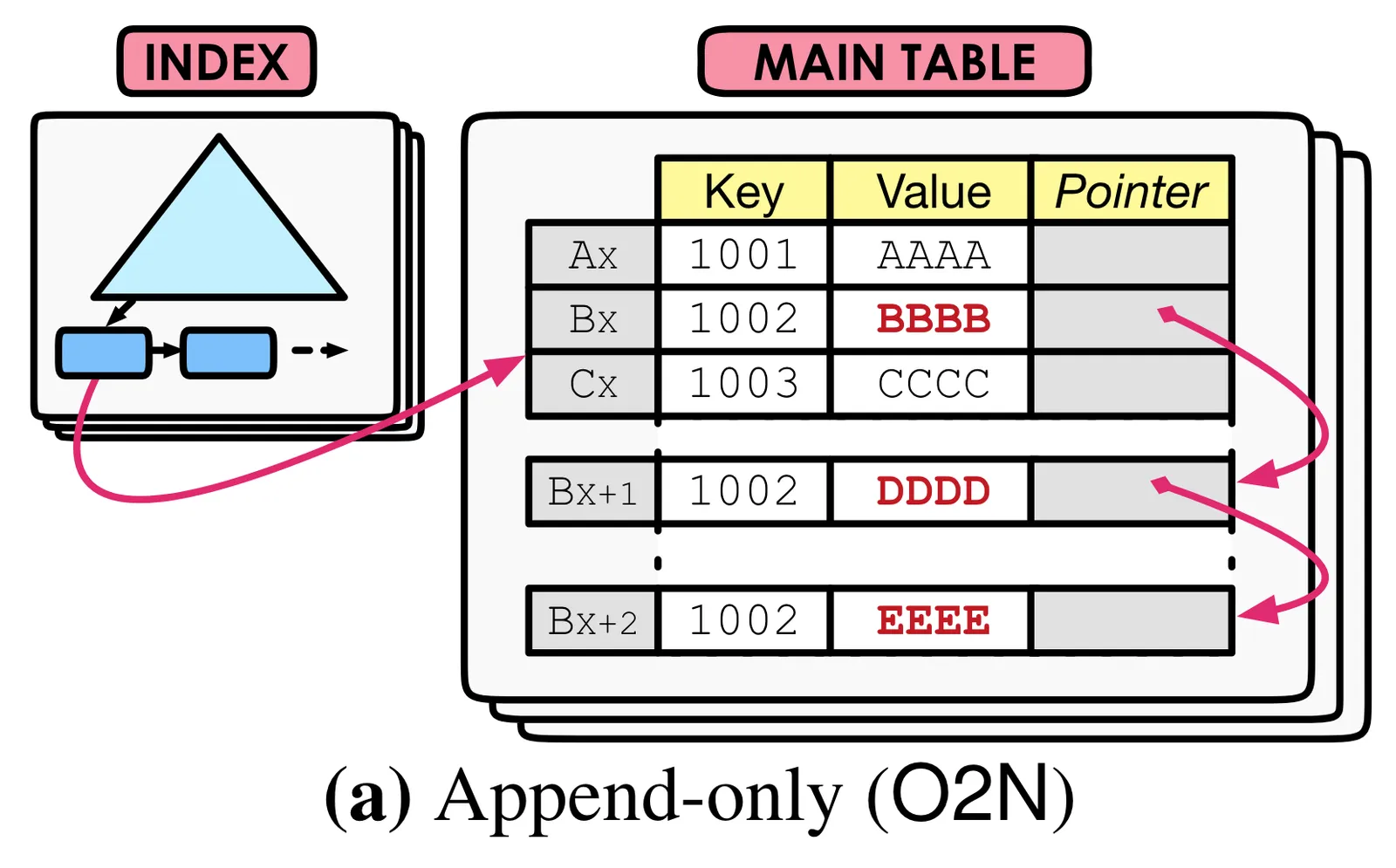
A transaction issues reads using its transaction id. After identifying a row by key, Postgres traverses the linked list to find the most recent valid version within the transaction’s view.
MySQL#
In contrast, MySQL separates a main version of row storage from a write ahead log of all versions deltas:
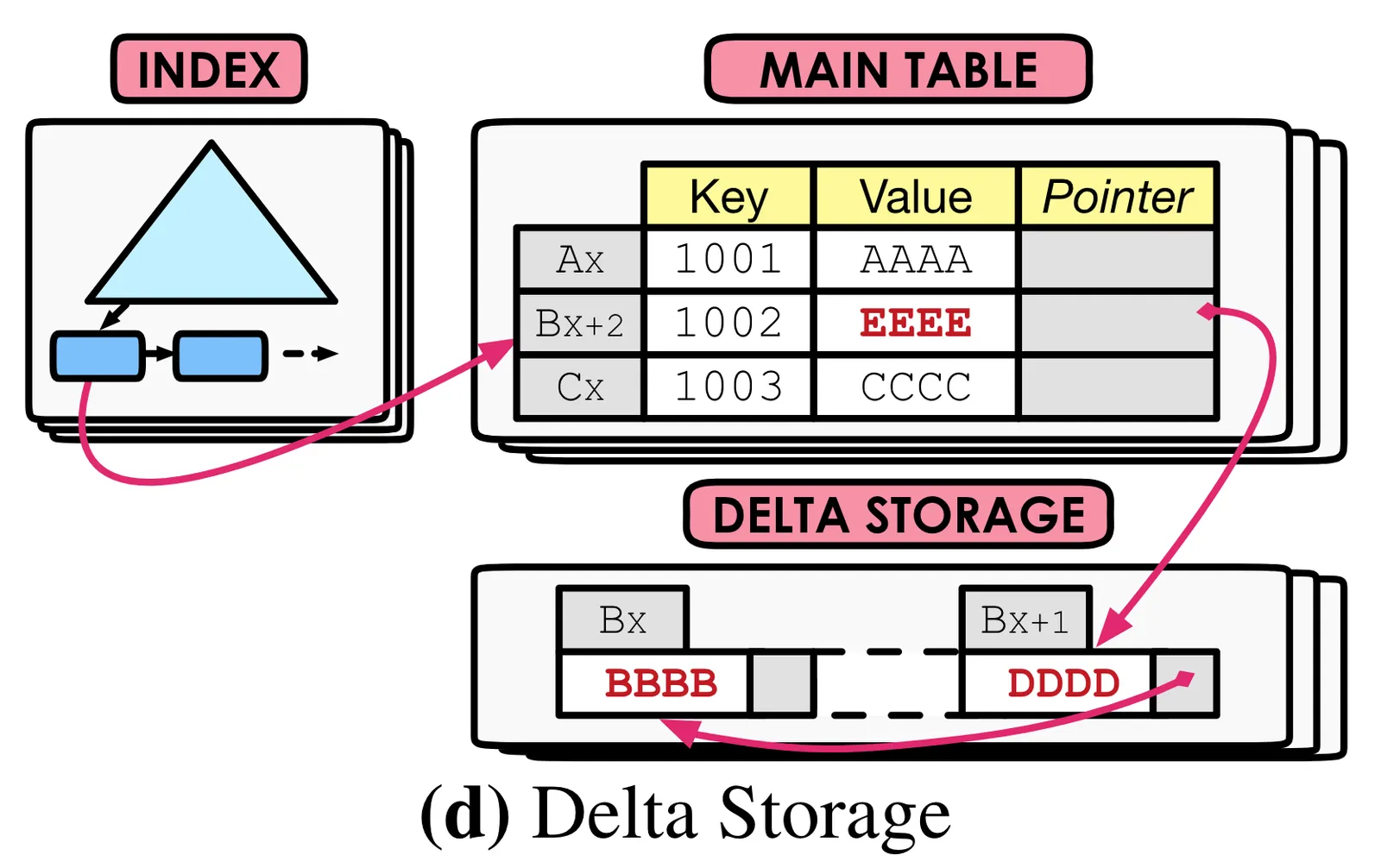
MySQL still uses linked-list semantics to distinguish tuple versions, but there are really two different formats for representing rows on disk.
Dolt#
Dolt writes are append only, similar to Postgres. But the way versioning works is very different.
Dolt stores its data as Merkle Trees, which are designed for diffing and merging trees proportional to the number of differences. Internal nodes are keyed by the hash of their contents.
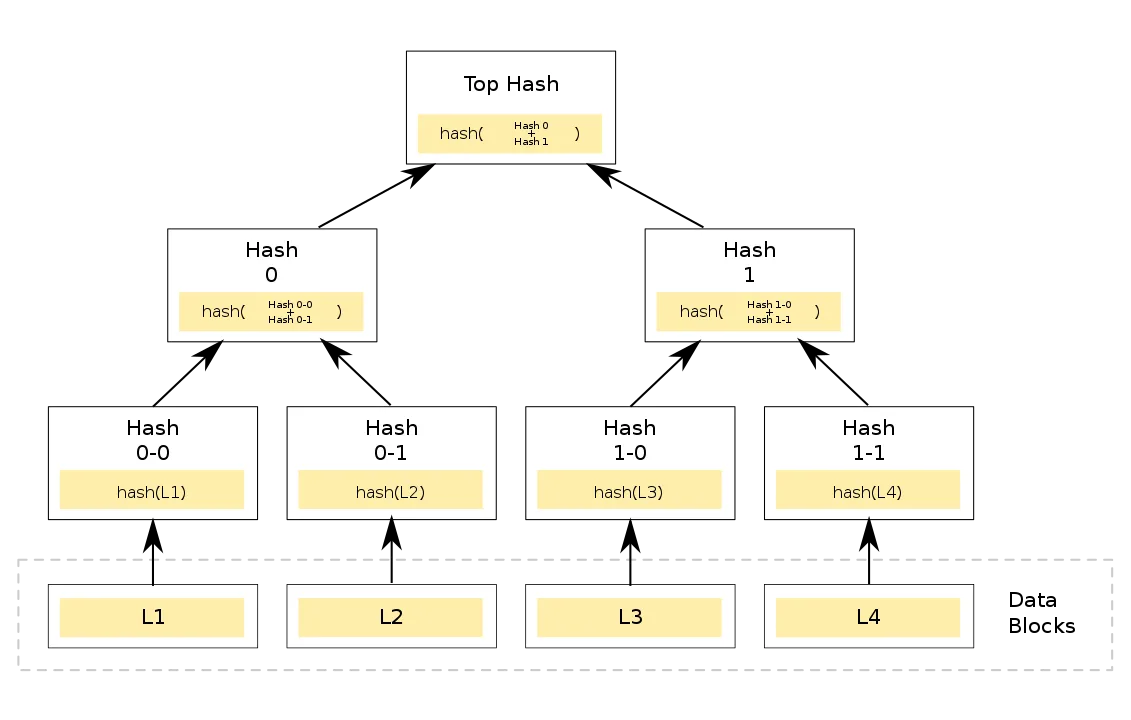
Prolly trees are generalizations of this content sharing that terminate in key-value pairs the same way as a B-Tree would.
Two transactions reading different data versions won’t even share the same tree root! At transaction start time, each transaction records the root hash which uniquely identifies the Prolly Tree’s contents when the transaction began. But common substructures will overlap for the same reason, Prolly trees are history independent and never write the same data blocks twice.
If B-Tree MVCC is binary search and linked list search, Dolt MVCC is binary search and hashing.
Default Isolation#
Anything short of pessimistic concurrency (two-phase locking) sacrifices safety for performance. Many years of studying MVCC has revealed race conditions that optimistic concurrency implementations risk (good summary of anomalies here). Different isolation levels are exposed to different sets of race conditions.
Postgres, MySQL, and Dolt all naturally implement “monotonic atomic view”. A B-Tree uses its transaction id to traverse a version linked list until reaching the last row within its scope of view. Likewise, a Prolly Tree root hash identifies a unique snapshot of a database. In this mode reads are consistent to a snapshot at the beginning of a transaction.
Conflict Resolution#
A monotonic view is not enough to prevent concurrent read-write transactions from racing. For example, one type of write skew is listed below. T1 issues a write contingent on a certain read that T2 invalidates:
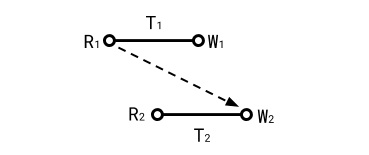
The holy grail of isolation produces results that look like they were executed sequentially. We still want the transactions to be concurrent, we just want the final “ordering“‘s result to be the same as if transactions would have executed sequentially.
Postgres#
Serializable snapshot isolation (SSI) is the most common way to implement this behavior (see PostgreSQL’s docs, FoundationDB’s conflict detection, and CockroachDB’s list of snapshot isolation anomalies. Rather than rearchitecting storage layers that are naturally monotonic-world-view, databases overlay transaction read-sets to identify unsafe dependency cycles.
MySQL#
MySQL’s strictest isolation level prevents some but not all anomalies (see the table here).
Dolt#
There are two halves to conflict resolution in Dolt. Dolt does not yet support a SERIALIZABLE isolation mode the way Postgres does. A serializable Dolt would probably implement SSI, using supplemental information to abort unsafe dependency cycles.
Dolt’s Git half detects write conflicts in a different way. Dolt
merges trees to materialize conflicts. In an interactive context those conflicts can either be merged safely or thrust upon the user to resolve.
Below is an example of a database whose row identified by pk=1 was changed to 10 by branch ours and 0 by branch theirs:
docs $ dolt merge make-conflicts
Updating jjkqslpnbbvjh7efdhcsqdh68ekl0leb..5gmleh5ksmtsdeeaqeagpsitpug4ntoj
Auto-merging docs
CONFLICT (content): Merge conflict in docs
Automatic merge failed; fix conflicts and then commit the result.
docs $ dolt conflicts cat docs
+-----+--------+----+----+
| | | pk | c1 |
+-----+--------+----+----+
| | base | 1 | 1 |
| * | ours | 1 | 10 |
| * | theirs | 1 | 0 |
+-----+--------+----+----+In a transactional context, these branches are concurrent and one should abort. On the other hand, the example below
would merge cleanly to form (pk=1,c1=10,c2=10) because the two transactions touched different columns.
+-----+--------+----+----+----+
| | | pk | c1 | c2 |
+-----+--------+----+----+----+
| | base | 1 | 1 | 1 |
| * | ours | 1 | 10 | 1 |
| * | theirs | 1 | 1 | 10 |
+-----+--------+----+----+----+B-Trees can’t do that!
Garbage Collection#
Maintaining copies of rows means MVCC databases grow in size proportionally to the write throughput. Different storage formats have different amounts of write amplification and different ways of cycling row versions.
Postgres#
Postgres’s append only storage requires garbage collecting, or “vacuuming” to remove dead rows interleaved with live rows. The same paper from before describes a range of garbage collection options in Section 5. In practice, Postgres periodically scans and rewrites pages to remove clutter.
MySQL#
MySQL’s cleanup is more straightforward that Postgres’s. We mentioned before how InnoDB segments main storage from an append only log. Garbage collection on MySQL truncates the log at safe points without having to rewrite pages.
Dolt#
By default Merkle Trees keep around row versions indefinitely. Their hash map-like behavior lets Merkle Trees search arbitrary version depths without the O(n) performance falloff you see with oldest-to-newest linked lists of row versions.
So garbage collection in Dolt has two different shapes. One clears dead rows that never made it into a transaction. This requires rewriting an append-only database similar to Postgres. The second tunes the depth of desired versioning history. We call this “tiered storage,” because you can store different versions of the data at different arm lengths.
For comparison, we can think about the way MySQL streams write-ahead log backups. Rather than keep the entire log local to the disk, MySQL replicates a history of changes to cheap storage and truncates the log periodically. Merkle Trees similarly do not need to keep all historical versions locally. It usually makes sense to store infrequently accessed versions in a highly compressed format, or remotely in a blobstore. You can read a bit more about how Dolt tiered storage works here.
Summary#
We discussed how common traits of MVCC databases compare to Merkle Trees with Git semantics. Merkle Trees have similar nonblocking behavior, default isolation levels, and some similarities to B-Tree garbage collection. But Merkle Trees store rows in very different ways, which leads to more nuanced conflict resolution strategies and different garbage collection and file lifecycle goals.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!