
Designing a schema for your relational database is a daunting task that has long term implications for the database’s performance, maintainability, and correctness. And it often requires making decisions before having a clear picture of the exact shape and distribution of your data, or what the common access patterns will look like. It’s not a permanent decision: tables can be altered and databases migrated. But these migrations can be slow and expensive.
To top it all off, some data is less amenable to relational modeling than others. Polymorphic Data, in particular, is a common occurrence that is difficult to model in SQL. You’ve probably worked with polymorphic data before, even if you’re not familiar with the term.
Example: Patient Payment Info#
Imagine you’re a medical provider storing patient payment methods. Every patient is either insured or uninsured, and you need to store different data for each patient based on their insurance status.
If you’ve written code in a functional language, you might be familiar with algebraic data types. For instance, you could represent this schema in Haskell with the following ADT:
type Provider = String
type MemberId = Int
type CardNumber = String
type BillingAddress = String
data PaymentInfo = Insured Provider MemberId | Uninsured CardNumber BillingAddressIf you’re more accustomed to object oriented programming, you might implement this same data type via abstract classes and inheritance, like the following Java code:
abstract class PaymentInfo {}
class Insured extends PaymentInfo {
String provider;
int memberId;
}
class Uninsured extends PaymentInfo {
String cardNumber;
String billingAddress;
}These are both examples of polymorphic data: a datatype where the data can take multiple different shapes. The word comes from Greek roots: “poly” meaning many, and “morph” meaning form. So, data that can take many forms. When a relational database needs to model polymorphic data, we typically use the term polymorphic association instead.
Sometimes, like in the above example, a polymorphic association is the best way to model your data type. But there’s no obvious way to represent this data in a relational database. If you want to include data like this in your database, you’re going to have to make some tradeoffs. Let’s look at some different schemas that attempt to model this data. We’re going to use MySQL as our chosen dialect here, but the process is similar regardless of dialect.
Approach 1 - Single Table With Nullable Fields#
The simplest schema would be one that has a single table, with a field for each value that may appear in a record, or may be NULL. Such a schema would look like this:
CREATE TABLE patients(
id INT PRIMARY KEY,
insurance_provider TEXT,
insurance_member_id INT,
card_number TEXT,
billing_address TEXT);In each row, we set insurance_provider and insurance_member_id if the patient is insured, and card_number and billing_address if the patient is uninsured. The unused fields get set to NULL.
This technique is sometimes also called “Single Table Inheritance” or “Table-Per-Hierarchy”, because a single table is used to represent an entire hierarchy of types.
This works, but it has several problems. Mainly, our data has several invariants that the database cannot easily validate. Among them:
-
In a single row, the fields for insured and uninsured patients should not both be set to non-NULL values.
-
We would like to enforce that
insurance_member_idcannot be NULL for insured patients, but we can’t add aNOT NULLconstraint on the column, because it also must beNULLfor uninsured patients. -
We can add constraints to the table, but they’re pretty obtuse, and the error messages if the constraints get violated are opaque:
CREATE TABLE patients(
id INT PRIMARY KEY,
insurance_provider TEXT,
insurance_member_id INT,
card_number TEXT,
billing_address TEXT,
CHECK ((insurance_provider IS NULL) = (insurance_member_id IS NULL)),
CHECK ((card_number IS NULL) = (billing_address IS NULL)),
CHECK ((insurance_provider IS NULL) + (card_number IS NULL) = 1));
This will result in an error if we attempt to insert a patient record with neither payment type or both payment types, but the error message isn’t very helpful:
> INSERT INTO patients(id, insurance_provider, insurance_member_id) VALUES(1, "OneMedical", NULL);
ERROR 3819 (HY000) at line 1: Check constraint 'patients_chk_1' is violated.These checks would only grow in complexity as the number of fields in each payment method grows. And what if we later want to add a third type of payment info? We’d have to add additional columns to the table, modifying every existing row and changing the table schema.
There’s another, more subtle issue happening here: performance. A schema like this is fast for small datasets because storing all the records in a single table allows the engine to perform fewer joins. But as the size of the dataset grows, this table could become a bottleneck. And any query that only cares about insured patients would still be operating on the entire table, which may be slow. Adding an index on insurance_provider would help, but this now adds the overhead of maintaining a secondary index, and might preclude the engine from using a different index to further optimize the query.
So not only is this approach ugly, but it’s typically slow too. The only reason to take this approach is if you know that it’s fast for your specific data and access patterns. In general, we can do better.
Approach 2 - Nullable Parent-to-Child Foreign Keys#
Splitting the data into multiple tables makes it easier to enforce structural constraints on the data. Here’s the most obvious way to do that: Since there are fields only relevant to insured patients, and fields only relevant to uninsured patients, we should put those related fields into their own tables, and use a foreign key in the base table to reference them. The new database schema looks like this:
CREATE TABLE insured_payment_info(
id INT PRIMARY KEY,
insurance_provider TEXT NOT NULL,
insurance_member_id INT NOT NULL
);
CREATE TABLE uninsured_payment_info(
id INT PRIMARY KEY,
card_number TEXT NOT NULL,
billing_address TEXT NOT NULL
);
CREATE TABLE patients(
id INT PRIMARY KEY,
insured_payment_info_id INT,
uninsured_payment_info_id INT,
FOREIGN KEY (insured_payment_info_id)
REFERENCES insured_payment_info(id)
ON DELETE CASCADE,
FOREIGN KEY (uninsured_payment_info_id)
REFERENCES uninsured_payment_info(id)
ON DELETE CASCADE,
CHECK ((insured_payment_info_id IS NULL) + (uninsured_payment_info_id IS NULL) = 1)
);
-- A query to show all data for all records (similar to Approach 1) would like like:
SELECT
patients.id as id,
insurance_provider,
insurance_member_id,
card_number,
billing_address
FROM patients LEFT JOIN insured_payment_info on insured_payment_info_id = insured_payment_info.id
LEFT JOIN uninsured_payment_info on uninsured_payment_info_id = uninsured_payment_info.id;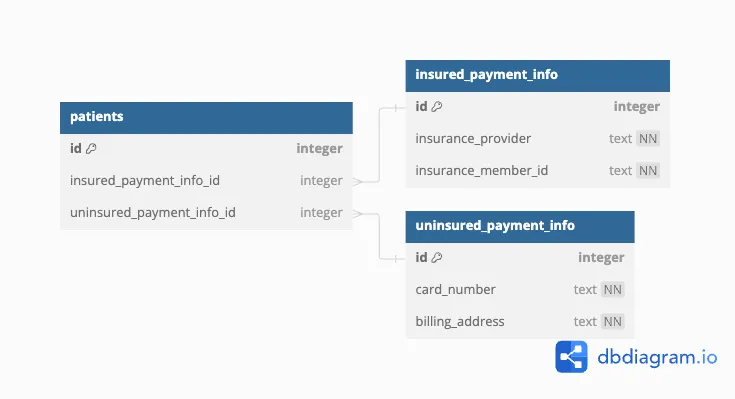
This has several advantages over the first approach:
-
The
NOT NULLconstraints make it obvious from inspection that if a patient has insurance, then none of the insurance-related fields areNULL. -
Join operations that only care about insured or uninsured patients (but not both) can run more efficiently by only operating on the relevant table.
But several drawbacks remain:
-
Adding a new payment type still requires changing the schema of the
patientstable. -
Verifying that exactly one of the foreign keys is not
NULLrequires an additionalCHECKthat may be hard to read and maintain.
And this comes with additional downsides compared to the first approach:
-
Queries that care about both a patient ID and that patient’s payment info need to do an extra join. For some queries (getting the payment info for a given patient id) this can be optimized, but other queries (like getting all patients with a specific provider) may require additional indexes to optimize the join.
-
Inserting new records becomes more complicated, since multiple tables must be updated in sequence.
For most use cases, this will probably be better than the first approach. At the very least it’s easier for the engine to preserve your invariants and provides better errors for operations that would violate them. But bear in mind that it’s not without its tradeoffs. But this isn’t the only way to split the data into multiple tables.
Approach 3 - Tagged Union of Foreign Keys#
The previous approaches all required additional CHECKs to make sure that each row contains exactly one form of payment info. We can avoid these checks if we use a single column for both foreign keys, and a “tag” column to indicate which form is being used.
The schema looks like this:
CREATE TABLE patients(
id INT PRIMARY KEY,
payment_type enum('insured', 'uninsured') NOT NULL,
payment_info_id INT, -- a foreign key to either 'insured_payment_info' or 'uninsured_payment_info'
);In doing this, we lose the foreign key constraint, but we can get it back using some cleverness around generated columns:
CREATE TABLE patients(
id INT PRIMARY KEY,
payment_type enum('insured', 'uninsured') NOT NULL,
payment_info_id INT, -- a foreign key to either 'insured_payment_info' or 'uninsured_payment_info'
insured_payment_info_id INT AS (IF(payment_type = 'insured', payment_info_id, NULL)) STORED,
uninsured_payment_info_id INT AS (IF(payment_type = 'uninsured', payment_info_id, NULL)) STORED,
FOREIGN KEY (`insured_payment_info_id`) REFERENCES insured_payment_info(id) ON DELETE CASCADE,
FOREIGN KEY (`uninsured_payment_info_id`) REFERENCES uninsured_payment_info(id) ON DELETE CASCADE
);
-- A query to show all data for all records (similar to Approach 1) would like like:
SELECT
patients.id as id,
insurance_provider,
insurance_member_id,
card_number,
billing_address
FROM patients LEFT JOIN insured_payment_info on insured_payment_info_id = insured_payment_info.id
LEFT JOIN uninsured_payment_info on uninsured_payment_info_id = uninsured_payment_info.id;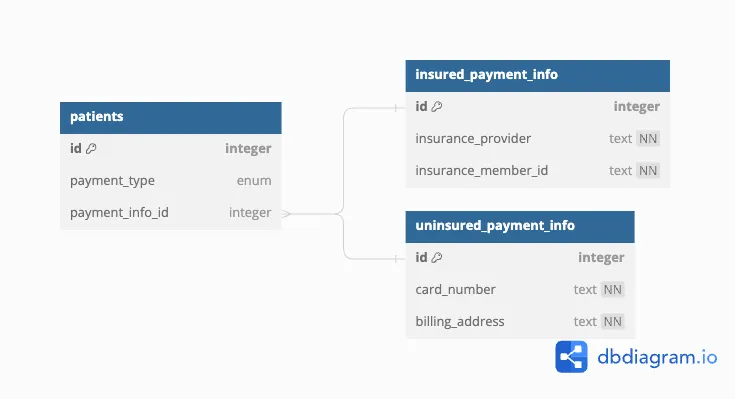
There’s value in being able to express our invariants using the specific tools like FOREIGN KEY and NOT NULL constraints instead of arbitrary CHECKs. It makes the schema more readable and easier to maintain. But like the previous approaches, it also has its trade-offs:
-
The generated columns must be stored, not virtual, because MySQL doesn’t allow foreign keys on virtual columns. This will increase the size of the table on disk.
-
The columns written to during insert operations are completely disjoint from the columns that should be used in queries. If a query accidentally compares with the
payment_info_idcolumn instead of one of the generated columns, it may return incorrect results. Thus, querying this table is more error-prone than normal.
Up to this point, we’ve been putting the foreign key on the “supertype” and referencing the tables containing the different implementations. But we could just as easily do the reverse instead.
Approach 4 - Child-to-Parent Foreign Keys#
We can once again use generated columns and foreign keys in order to enforce that each patient has no more than one payment info, although here it looks slightly different. As an additional optimization, we can reuse the globally unique patient id as the primary key column in the child tables.
The new database schema looks like this:
CREATE TABLE patients(
id INT UNIQUE AUTO INCREMENT,
payment_type ENUM('insured', 'uninsured'),
PRIMARY KEY (id, payment_type)
);
CREATE TABLE insured_payment_info(
id INT PRIMARY KEY,
insurance_provider TEXT NOT NULL,
insurance_member_id INT NOT NULL,
payment_type ENUM('insured', 'uninsured') AS ('insured') STORED,
FOREIGN KEY (id, payment_type)
REFERENCES patients(id, payment_type)
ON DELETE CASCADE
);
CREATE TABLE uninsured_payment_info(
id INT PRIMARY KEY,
card_number TEXT NOT NULL,
billing_address TEXT NOT NULL,
payment_type ENUM('insured', 'uninsured') AS ('uninsured') STORED,
FOREIGN KEY (id, payment_type)
REFERENCES patients(id, payment_type)
ON DELETE CASCADE
);
-- A query to show all data for all records (similar to Approach 1) would like like:
SELECT * from patients LEFT JOIN insured_payment_info using (id, payment_type)
LEFT JOIN uninsured_payment_info using (id, payment_type);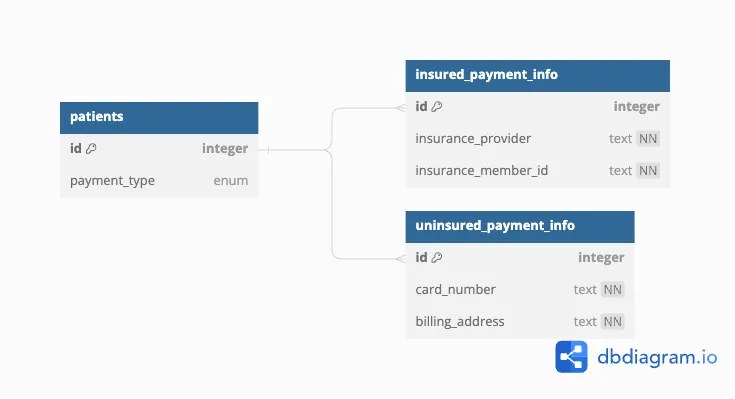
By using both the id and payment_type columns in the foreign key, this guarantees that the payment type in the parent table matches the child table containing the reference.
This approach has an odd feature: we had to declare that both id and payment_type are in the parent primary key, even though the id column is already unique. But this is necessary for the foreign keys to work: this way, if a patient’s payment type is modified (say, from “uninsured” to “insured”) the row in the child table corresponding to the old payment method will get deleted. This guarantees that our invariants still hold even after the table is updated.
However, like every other approach, this has its own trade-offs:
-
The
payment_typeenum must be stored in every row in the child tables, even though the value is always the same. -
While this approach prevents a user from having multiple payment methods, it’s can’t detect cases where a user has no payment methods. And since the process for adding new records requires that the
patientstable is updated first, there’s no way to fix this.
Deciding on an approach#
None of these approaches are perfect, but each has something it does best.
-
Approach #1, the “Single Table” approach, is conceptually the simplest.
-
Approach #2, the “Nullable Foreign Key” approach, uses the smallest about of space.
-
Approach #3, the “Tagged Union” approach, is the only one that can enforce every invariant without resorting to arbitrary
CHECKexpressions. -
Approach #4, the “Child-to-Parent Foreign Key” approach, results in the simplest logic for update and select statements, and provides an easy way to use a single auto-incrementing id across all tables. It’s also the only approach that can add additional implementations without having to modify the parent table.
So which one is the best? As always, the answer is “it depends”. If performance is critical, then you’re probably going to be doing your own benchmarking to figure out what’s fastest for your specific data and access patterns. If performance isn’t critical, you probably want to optimize for some combination of readability, maintainability, and safety, which is ultimately subjective.
There’s no community consensus here either, as the many near-identical questions on StackOverflow can attest.
In a way, it’s not that surprising that a relational database would struggle to handle this kind of data. Polymorphic data is most strongly associated with inheritance patterns and abstract data types, which were popularized by Smalltalk in 1972 and Hope in 1975, respectively. Relational algebra was invented in 1970 and predates both of them. In a literal sense… SQL was not made for this.
But I’m burying the lede a bit, because SQL’s come a long way in the past 50 years. There is one other way to tackle polymorphic data in SQL, and it’s a recent addition to the standard. I’m talking, of course, about everyone’s favorite Javascript-derived object notation.
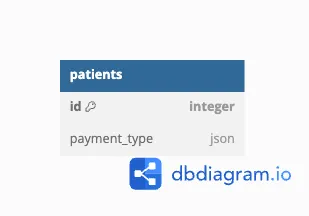
Approach 5 - JSON#
Every major SQL engine supports JSON as a column type, and exposes a semi-standardized suite of functions for filtering and manipulating JSON documents. Since JSON is inherently semi-structured, it’s great for storing polymorphic data. So the final approach is simply: “Use a JSON column.”
That’s it. That’s the entire description of the database schema:
CREATE TABLE patients(
id INT PRIMARY KEY,
payment_info JSON
)
You can then write your queries using the JSON provided by most SQL dialects. These queries run fast enough on modern engines, even without an explicit index… except MySQL. MySQL’s JSON support is really slow for large documents. If you’re writing in the MySQL dialect, you should use Dolt instead, since we’re currently rolling out optimizations that make JSON in Dolt miles faster than MySQL, and frankly, make Dolt best-in-class for manipulating JSON documents. And if your specific query hasn’t been upgraded yet, drop us a line or and we’ll do that one next.
So for example, getting all unique insurance providers would look like this:
SELECT DISTINCT payment_info->>"$.insurance_provider" from patients;Of course, using JSON like this means that we’re getting zero validation on the shape of the data. Fortunately, the SQL standard for JSON has support for json-schema to do this validation as a constraint check.
Unfortunately, it’s not pretty:
CREATE TABLE patients(
id INT PRIMARY KEY,
payment_info JSON
CHECK (JSON_SCHEMA_VALID('{
"anyOf": [
{
"$ref": "#/definitions/insured"
},
{
"$ref": "#/definitions/uninsured"
}
],
"definitions": {
"insured": {
"properties": {
"insurance_member_id": {
"type": "number"
},
"insurance_provider": {
"type": "string"
},
"payment_type": {
"const": "insured",
"type": "string"
}
},
"type": "object"
},
"uninsured": {
"properties": {
"billing_address": {
"type": "string"
},
"card_number": {
"type": "string"
},
"payment_type": {
"const": "uninsured",
"type": "string"
}
},
"type": "object"
}
}
}', payment_info))
);Honestly, you probably shouldn’t do this. Writing JSON schemas is complicated and evaluating them is slow. And any change to a JSON value will cause the entire value to be re-evaluated.
Using JSON here still has its strength: it’s the easiest to write queries for without getting bogged down in relational algebra, and the easiest to extend with new implementations. And on most engines, evaluating those queries will still be reasonably fast.
Conclusion#
So do the benefits of writing JSON queries and deferring schema design justify using JSON over an actual relational schema? Again, it’s hard to say. None of these solutions are perfect. Ultimately, unless performance is critical, I’d go with whichever one feels easiest to read, maintain, and debug. All five of these approaches are adequate. They all work. In the absence of any standard best practice… just go with whichever one is the most comfortable to work with. At the end of the day, developer velocity is still the bottleneck the vast majority of the time. Don’t prematurely optimize.
And when you decide it’s time to optimize for performance… drop us a line on Discord or Twitter. If you’re already using Dolt, we take user requests very seriously. We have a 24 Hour Pledge for fixing bugs. If you’re not already using Dolt, give it a try or drop us a line anyway. We believe that every database is better with version control, including yours. And we’re happy to help you get started and figure out whether Dolt is right for you.