
Dolt implements a Git-style commit graph on top of a Prolly-tree-based storage engine. This architecture makes Dolt the world’s first and only version controlled SQL database.
One of the major capabilities a version controlled SQL database provides is three-way merge. What is three-way merge and how does it work in a SQL database? This blog explains.
Note, the first section explains what three-way merge is and how it works for text files. It will be a review for some. If you’re confident you understand three-way merge, you can skip to the Three-way Merge in a SQL database section.
What is Three-way Merge?#
Merging is a fundamental concept of version control. Merging is the act of reconciling multiple versions’ changes into a single version. Brian makes changes to a file. Aaron makes changes to the same file. If Brian and Aaron try to combine their changes, what should the file look like? This is merge.
Two-way Merge#
The easiest way to understand merge is through example. Let’s merge two lists using two-way merge and three-way merge to show the difference. Until recently, version control was constrained to sets of files so you can imagine these lists as checked into a version control system in the same file, databases.txt.
Version 1:
Oracle
Postgres
SQL Server
MySQL
DoltVersion 2:
Oracle
PostgreSQL
Microsoft SQL Server
MySQLTwo-way merge looks at a raw set of differences, or diff, of the two files. Two-way merge forces the user to choose which set of changes he or she wants in the resulting merged file.
Oracle
< Postgres
> PostgreSQL
< SQL Server
> Microsoft SQL Server
MySQL
- DoltIn this case, the user must make three decisions. Should the resulting file have Postgres, PostgreSQL, or both? Should it have SQL Server, Microsoft SQL Server, or both? Should Dolt be included or not?
Three-way Merge#
What if we knew the original list in databases.txt that both changes came from? How would that help our merge?
Let’s say the Original copy looked like so:
Oracle
Postgres
SQL ServerThus, the diff between Original and Version 1 (i.e. diff 1) would be:
Oracle
Postgres
SQL Server
+ MySQL
+ DoltAnd the diff between Original and Version 2 (i.e. diff 2) would be:
Oracle
< Postgres
> PostgreSQL
< SQL Server
> Microsoft SQL ServerSo, we know one user added MySQL and Dolt and the other user changed Postgres and SQL Server to their more formal names, PostgreSQL and Microsoft SQL Server. The two users didn’t modify the same information, in this case lines, so we’re pretty sure we need no more information to process the merge! We take the two additions from diff 1 and we combine those with the modifications in diff 2 resulting in the following merge.
Oracle
PostgreSQL
Microsoft SQL Server
MySQL
DoltThis is the power of three-way merge. Three-way merge reduces the number of decisions the merger must make to process the merge.
Conflicts#
In the two-way merge example, the user had to make three “decisions” to process the merge. In version control parlance, a decision a user has to make to process a merge is called “resolving a conflict”. Thus, a “conflict” is a pair of changes that cannot be resolved automatically via the merge algorithm.
Conveniently, in the contrived example above the three-way merge could proceed with zero conflicts, but three-way merges can result in conflicts. Let’s say the original version of databases.txt was not:
Oracle
Postgres
SQL Serverand instead was a list produced at Oracle HQ:
Oracle
MySQLThe resulting diffs would be:
Oracle
+ Postgres
+ SQL Server
MySQL
+ DoltAnd:
Oracle
+ PostgreSQL
+ Microsoft SQL Server
MySQLNow we have two conflicts. Should it be Postgres, PostgreSQL, or both? Should it be SQL Server, Microsoft SQL Server, or both? The addition of Dolt can still be processed automatically because it only exists on one side of the merge. Your version control system (ie. Git) will spit out something like:
Oracle
<<<<<<< version1
Postgres
SQL Server
=======
PostgreSQL
Microsoft SQL Server
>>>>>>> version2
MySQL
DoltTo proceed with this merge, you must delete <<<<<<<, =======, and >>>>>>> and make the file look like you want. A valid merge could be:
Oracle
Postgres
SQL Server
MySQL
DoltNotice how this is different than the result created by our first three-way merge? This is because both users edited the file at the same time and the merging user must decide whether they want short names, formal names, or both. I like short names and it seems so does the merger. Merges with conflicts are not deterministic, they require user input to complete.
Branches#
You need a user interface to tell your version control system what to merge. This user interface is branches. Branches are parallel, evolving copies of your files. Branches exist to be merged.
In the canonical Git version control branch setup, there is a main branch and users make a branch off main to make changes. When their changes are ready, they merge their changes back into main and delete their branch. There are other branch setups but this is the most popular.
Let’s show off the merge example from the Conflicts section using Git and branches so you can see how branches allow you to organize changes for merge. I included some handy pictures to help you visualize what is going on behind the scenes in the Git commit graph.
First, let’s set up our Git repository and make an initial commit.
$ mkdir show-off-merge
$ cd show-off-merge
$ git init
Initialized empty Git repository in /Users/timsehn/dolthub/git/show-off-merge/.git/
$ touch databases.txt
$ emacs databases.txt
$ cat databases.txt
Oracle
MySQL
$ git add databases.txt
$ git commit -m "Original databases list"
[main (root-commit) 35d85e5] Original databases list
1 file changed, 2 insertions(+)
create mode 100644 databases.txt
$ git branch
* main
$This makes a very simple, single node commit graph.
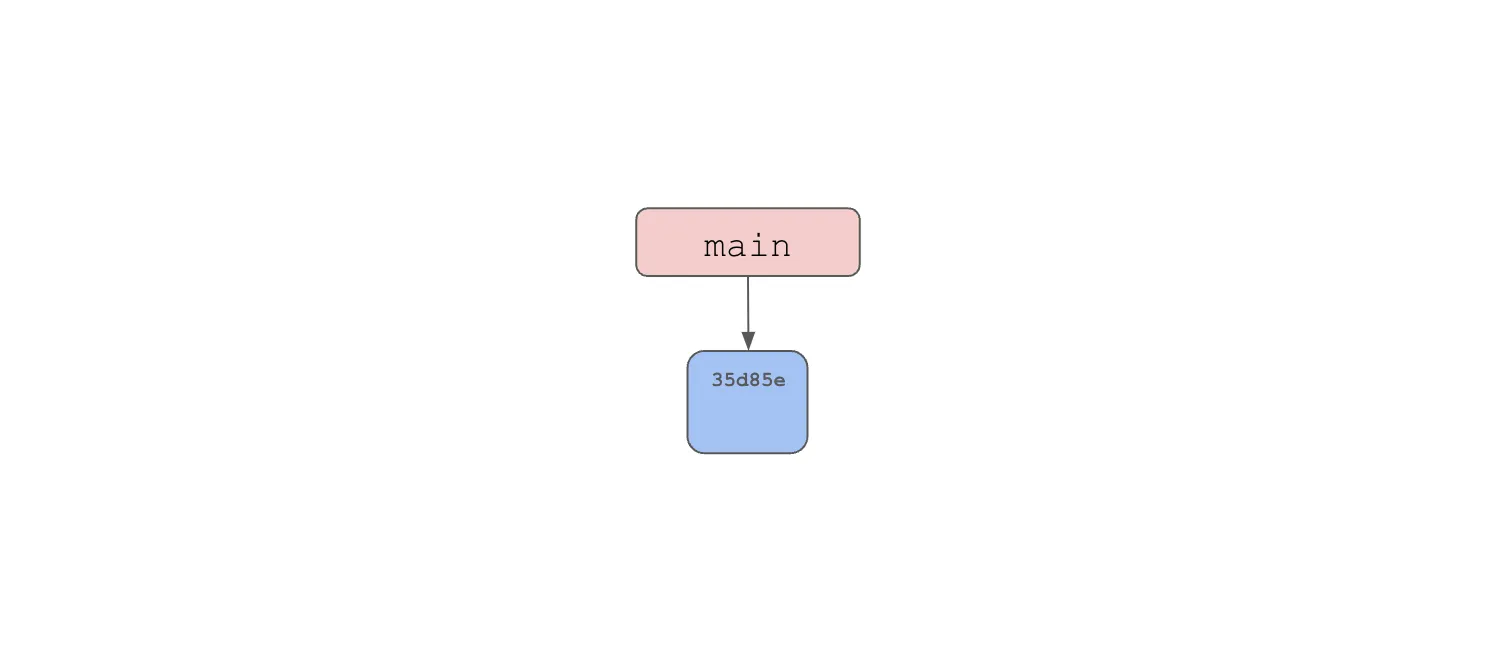
Now, we’ll make two branches, one for each set of edits we’ll make to databases.txt.
$ git branch add-databases-informal
$ git branch add-databases-formal
$ git branch
add-databases-formal
add-databases-informal
* mainThis makes the following commit graph. Note, branches are pointers to commits. In this case, all three branches point to the same commit.
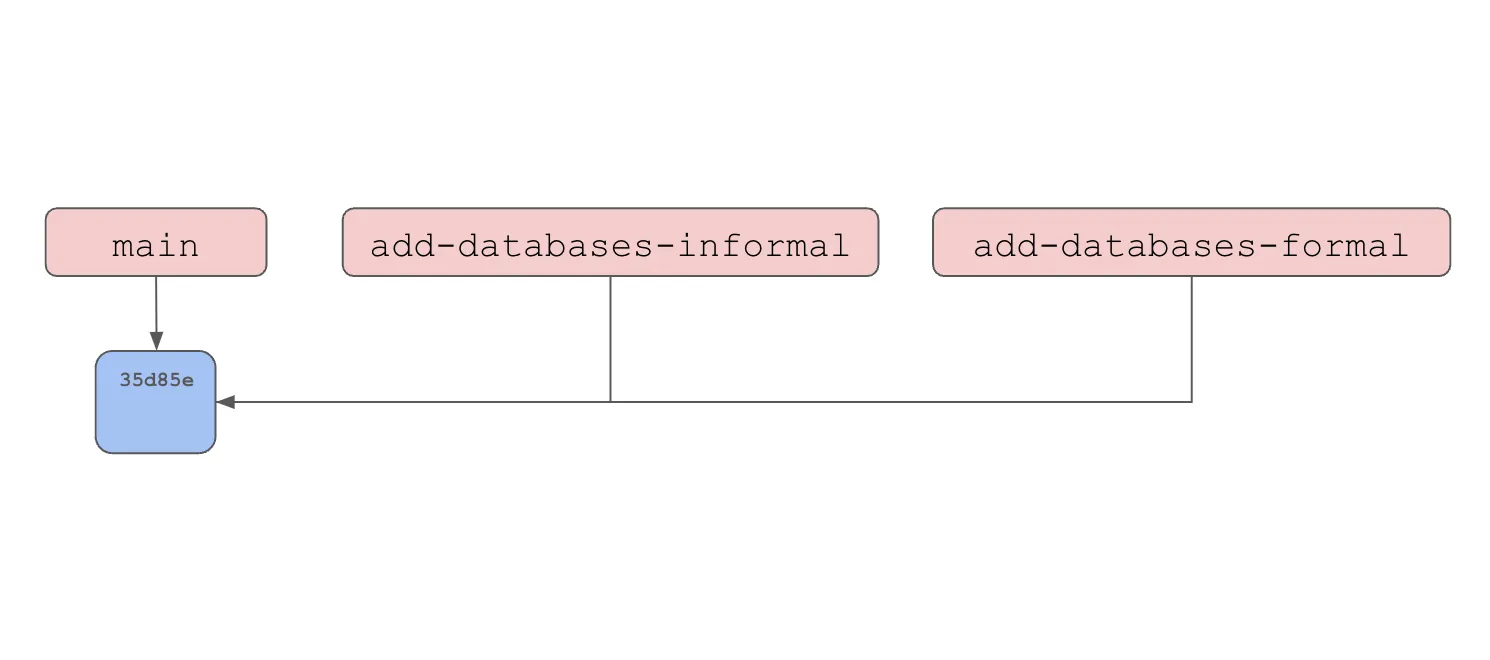
Now, we’ll checkout the add-databases-informal branch and make our changes.
$ git checkout add-databases-informal
Switched to branch 'add-databases-informal'
$ emacs databases.txt
$ cat databases.txt
Oracle
Postgres
SQL Server
MySQL
Dolt
$ git commit -am "Add databases. Informal names."
[add-databases-informal f9f959a] Add databases. Informal names.
1 file changed, 3 insertions(+)This makes a new HEAD commit of the add-databases-informal branch.
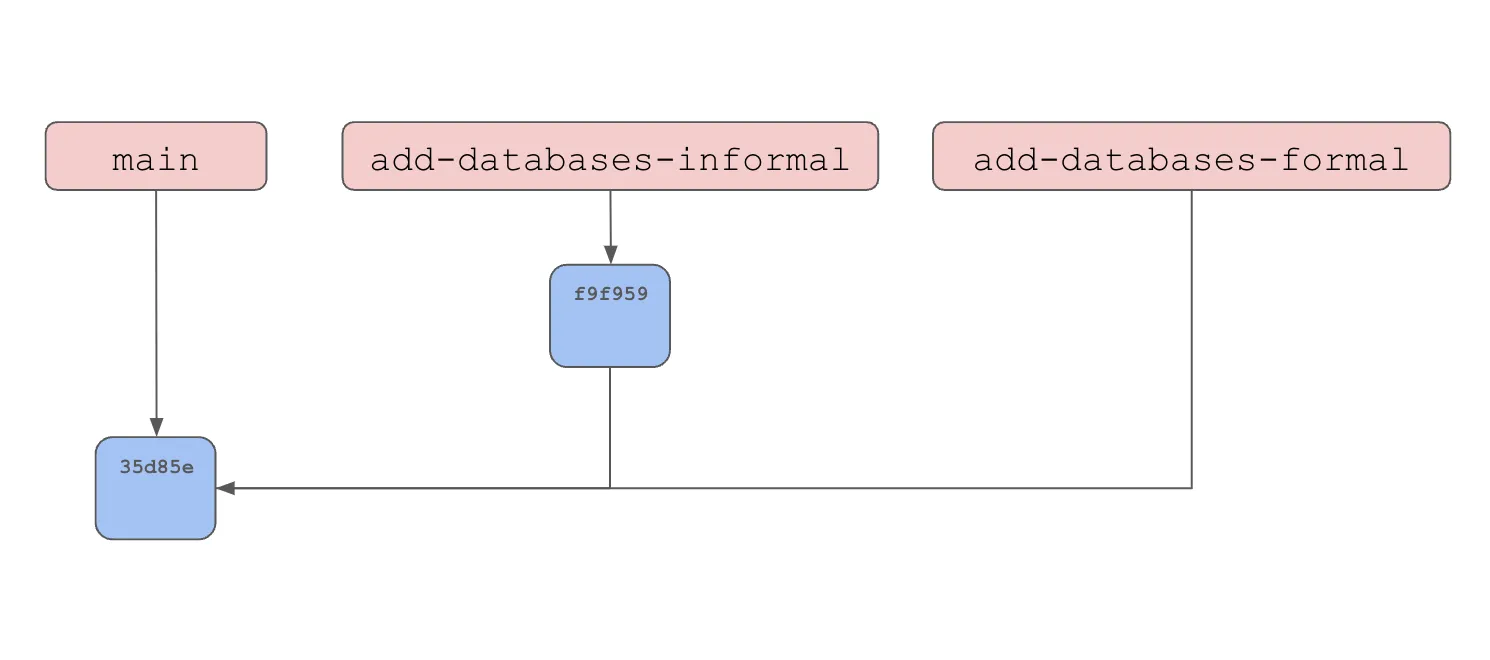
And then we’ll checkout the add-databases-formal branch and make our changes.
$ git checkout add-databases-formal
Switched to branch 'add-databases-formal'
$ emacs databases.txt
$ cat databases.txt
Oracle
PostgreSQL
Microsoft SQL Server
MySQL
$ git commit -am "Add databases. Formal names."
[add-databases-formal adb8b25] Add databases. Formal names.
1 file changed, 2 insertions(+)This makes a new HEAD commit of the add-databases-formal branch.
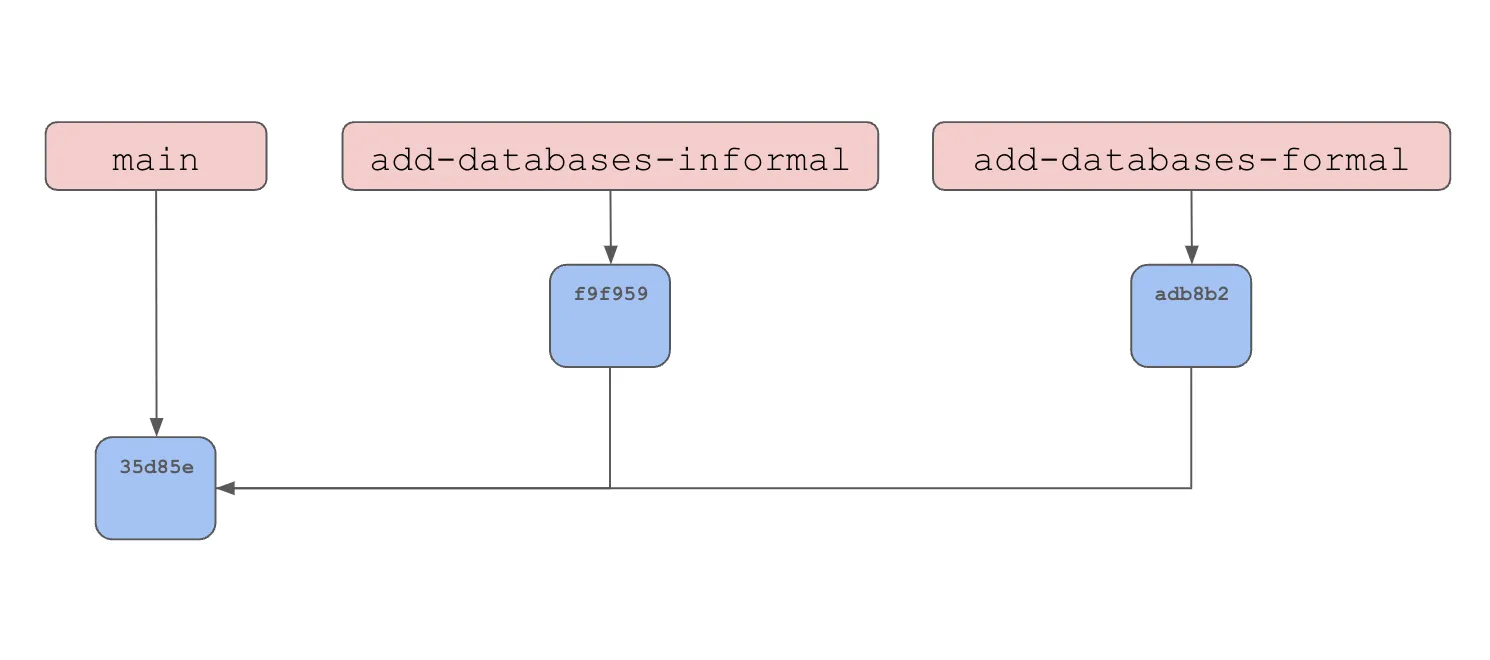
Now we will checkout the main branch and merge all our branches together. First, the add-database-informal branch.
$ git checkout main
Switched to branch 'main'
$ git merge add-databases-informal
Updating 35d85e5..f9f959a
Fast-forward
databases.txt | 3 +++
1 file changed, 3 insertions(+)
$ git branch -d add-databases-informalNote, the first merge is what is called a “fast-forward merge” because there are no parallel changes to consider. The change is just appended to the end of main.
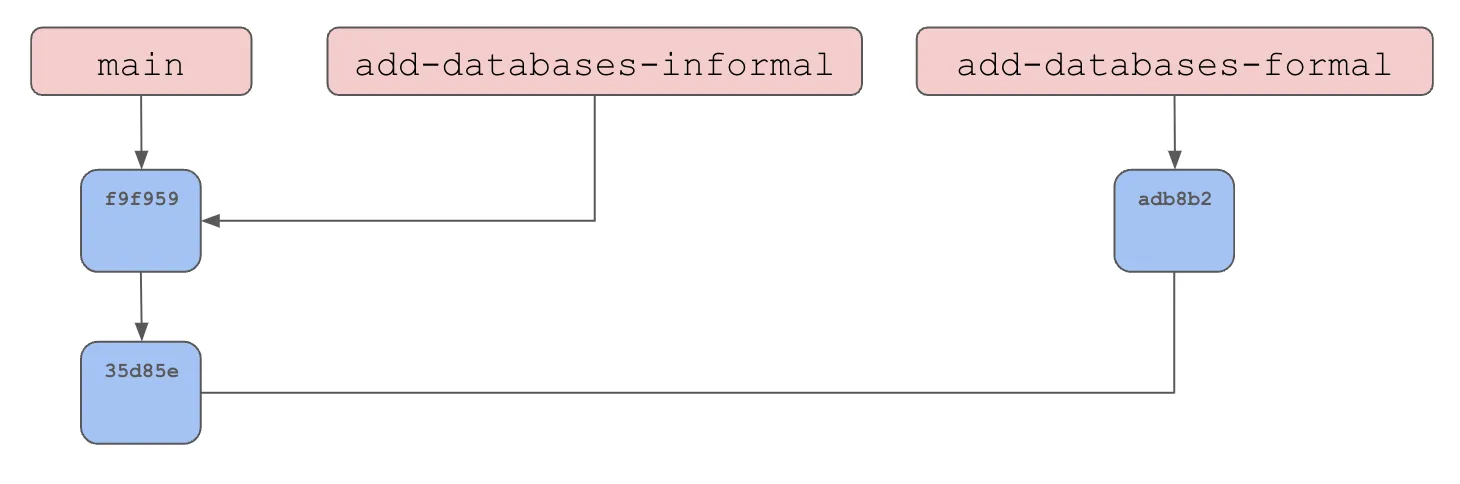
Now we merge the add-databases-formal branch. This is an actual three-way merge.
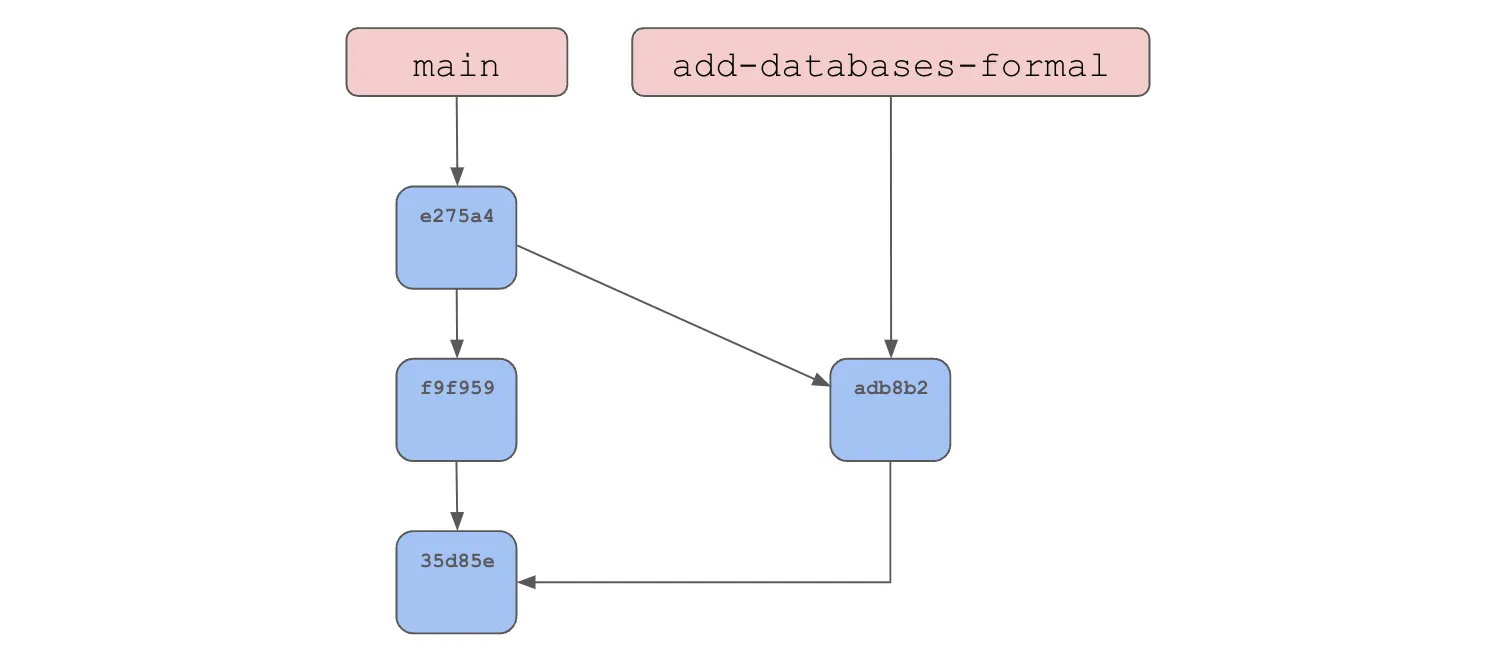
$ git merge add-databases-formal
Auto-merging databases.txt
CONFLICT (content): Merge conflict in databases.txt
Automatic merge failed; fix conflicts and then commit the result.
$ cat databases.txt
Oracle
<<<<<<< HEAD
Postgres
SQL Server
=======
PostgreSQL
Microsoft SQL Server
>>>>>>> add-databases-formal
MySQL
DoltAnd voila, we were able to reproduce our conflict we showed off in the conflicts section. Let’s resolve the conflict and finish the merge.
$ emacs databases.txt
$ cat databases.txt
Oracle
Postgres
SQL Server
MySQL
Dolt
$ git add databases.txt
$ git commit -am "Finish the merge by choosing the informal database names"
[main e275a4a] Finish the merge by choosing the informal database names
$ git branch -d add-databases-formalYou can see in the log the last commit is denoted as a merge that contains two parents.
$ git log
commit e275a4a01d14c5dbb36f0d8e0f6cc6c44f0dfadf (HEAD -> main)
Merge: f9f959a adb8b25
Author: Tim Sehn <tim@dolthub.com>
Date: Tue Jun 4 13:45:26 2024 -0700
Finish the merge by choosing the informal database names
commit adb8b25e37301587c8c73d1b436cfc4cdd2e72db (add-databases-formal)
Author: Tim Sehn <tim@dolthub.com>
Date: Tue Jun 4 13:41:02 2024 -0700
Add databases. Formal names.
commit f9f959ac846d4f7ab9276b67ece7abe6652c5123 (add-databases-informal)
Author: Tim Sehn <tim@dolthub.com>
Date: Tue Jun 4 13:39:41 2024 -0700
Add databases. Informal names.
commit 35d85e5fb600ff341bd4c31c986aa2bbce999463
Author: Tim Sehn <tim@dolthub.com>
Date: Tue Jun 4 13:35:34 2024 -0700
Original databases listThis creates the following commit graph with the merge commit pointing to two parents.
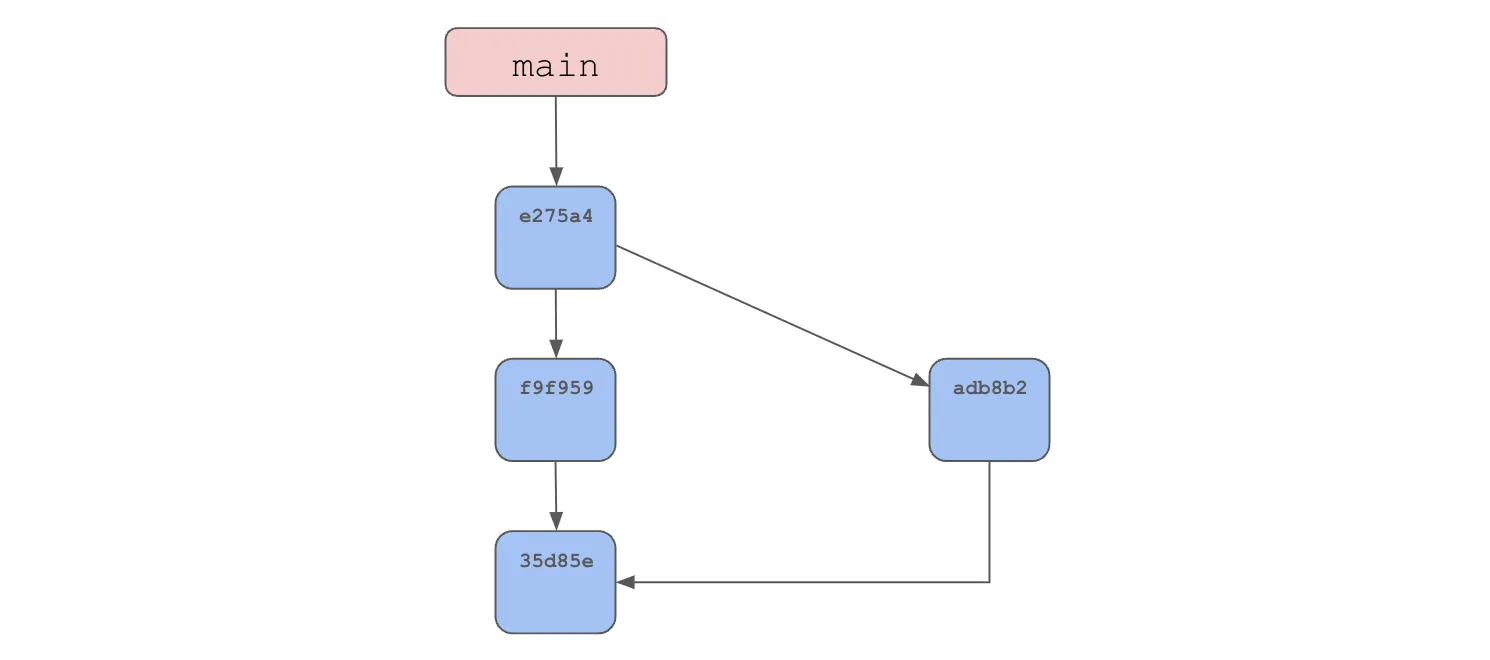
As you can see, branches allow you to organize multiple edits and are the basis for merges.
How Three-way Merge Works#
Three-way merge of files is a three step process:
- Find the merge base
- Perform the merge
- Resolve conflicts
There are a couple of core algorithms at work that allow merge to work at scale. First, there is an algorithm to find the merge base in the commit graph. Second, there is the actual merge algorithm. Resolving conflicts is up to the user.
Find the Merge Base#
So, how do you identify the original databases.txt that the new versions came from? You find the closest common ancestor or “merge base”. There’s even a git command to tell you the merge base of two commits.
$ git merge-base -a adb8b25e37301587c8c73d1b436cfc4cdd2e72db f9f959ac846d4f7ab9276b67ece7abe6652c5123
35d85e5fb600ff341bd4c31c986aa2bbce999463In our example, the merge base is quite easy, it’s the initial commit, the parent commit of both our new commits. But finding the merge base can be quite complicated.
With commits laid out in a graph, a “leet code style” algorithm called lowest common ancestor is used to find the merge base. Unless you’re willing to pre-process the graph a brute force approach is needed. You walk the graph in breadth-first order from the into and from commits until you find a commit in the other’s list. Unless your commit graph is very large and your merge base is far away, finding the merge base is quite fast.
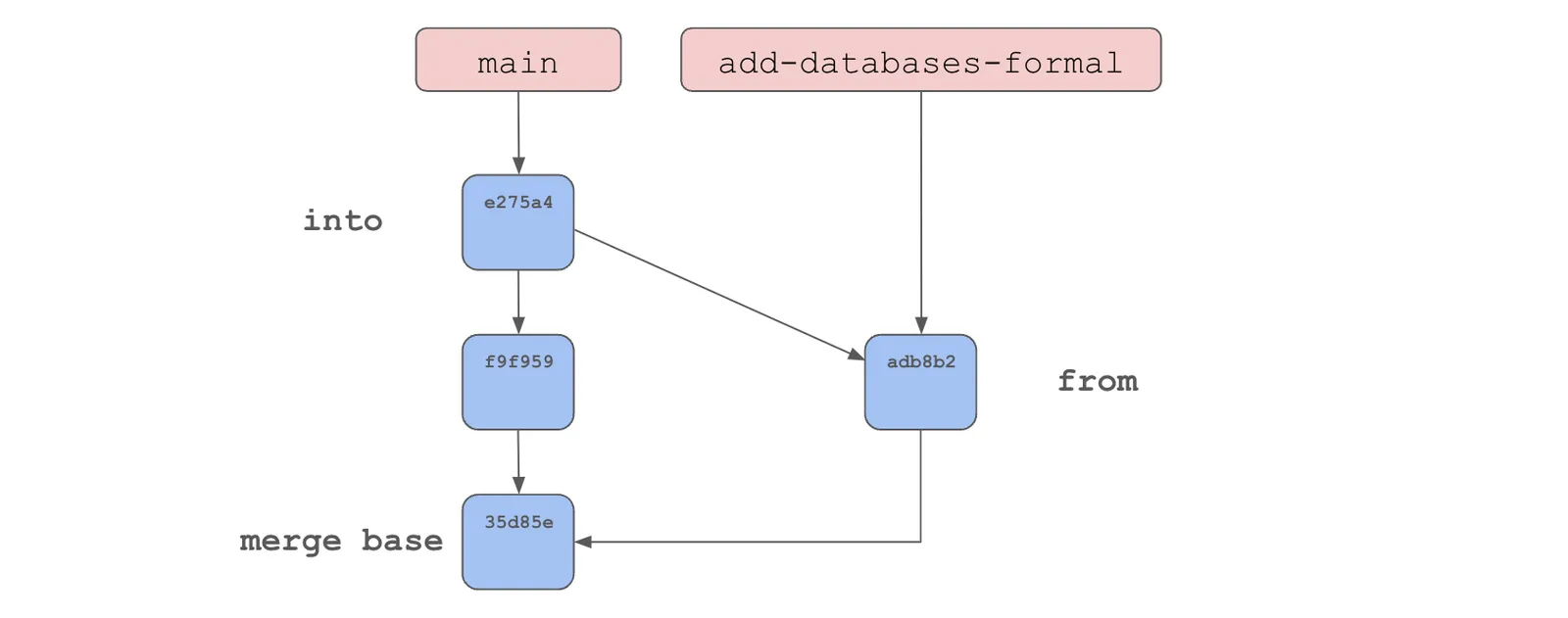
However, if your commit graph is large and your branch histories have diverged substantially, finding the merge base can be a compute intensive operation. Git started pre-processing the graph in 2.18 to speed up merge base calculation. Dolt pre-processes the graph using a commit closure to speed up merge base calculation.
There is a cross merge case where you have two nearest common ancestors in a three-way merge. These are kind of hard to make in practice but can happen. In this case, Git uses a recursive three-way merge algorithm to handle this case, where the two nearest common ancestors are themselves merged to form a nearest common ancestor on which to run the merge algorithm.
diff3 Merge Algorithm#
Now that you have a merge base, you must merge the actual target files. This is done using an algorithm called diff3. diff3 has been in Unix since 1979. The algorithm is fairly complicated and uses longest-possible sequences to determine merge-able chunks.
The fundamental observation of three-way merge is that if we look at all the changes between merge base and into and all the changes between merge base and from, that is the set of changes that should appear in the value that results from the merge of into and from. In other words, apply both sets of changes to the merge base.
Three-way Merge in a SQL Database#
Now that you know what a three-way merge is and have seen an example in files, did you know that you can also three-way merge a SQL database?
Transactions#
Most SQL databases have had a primitive three-way merge for a long time: transactions. Transactions are used to manage concurrent edits to the same tables. Clients open a transaction using START TRANSACTION, execute SQL, and then close the transaction with COMMIT. If there are any concurrent edits to the same data, the first COMMIT wins and subsequent COMMITs fail and a ROLLBACK is issued. This means conflicting writes in separate transactions fail.
In most SQL databases, transaction concurrency is accomplished using row-level locking. When a transaction modifies a row, it acquires a lock on that row. If a concurrent transaction encounters a locked row, the transaction either queues or fails, depending on the database.
The are some caveats. Some databases like older versions MySQL don’t support data description layer (DDL) transactions. MySQL 8.4 did launch support for Atomic Data Definition Statements.
Transactions are meant to be short-lived. With long-lived transactions, the chances of a conflicting write increases. The number of queued transactions can grow beyond your databases ability to hold them all. If you modify a lot of data in a long-lived transaction, you can essentially lock your whole database to reads and writes.
For very long-lived transactions we now have an alternative, Git-style three-way merge. Database version control now exists including three-way merge.
Prerequisites#
In order to do three-way merge on a SQL database, your database must:
- Be stored in a commit graph of versions
- Produce the differences (ie. diff) between two versions fast
Commit graph#
You first need to be able to represent your database versions in a commit graph, including branches. Commit graphs rely on the objects stored in them being content-addressed. A content-address is a value that summarizes the data stored within an object into a simple, smaller value, usually a hash. Two databases containing the same data must produce the same content-address.
Content-addressing a database is no small feat. You need the same database to produce the same content-address, no matter what order it was built in, called history independence. In Dolt, content-addressing is achieved using a custom storage engine based on a novel data structure called a Prolly Tree.
Fast diff#
Computing diffs on large files can be very compute intensive. In Git, files greater than 100MB are known to cause performance issues. This is why you are prevented from pushing these files to GitHub and why Git LFS exists.
Databases are often much larger than 100MB. In order to compute diffs on large databases, a custom storage engine is required. In traditional B-tree based storage engines, computing diffs scales with the size of the table.
To get around this limitation, Dolt again uses Prolly Trees. Not only do Prolly Trees provide the history independence required to store databases in a commit graph, but they can also be diffed with costs proportional to the size of the differences, rather than to the size of the table. They do this while still providing B-tree-like seek performance. Prolly Trees are a purpose-built data structure for database version control. Dolt is the only SQL database built on Prolly Trees.
Merge Process#
Three-way merge in a SQL database is a six step process whereas three-way merge of files is a three step process.
- Find the Merge Base
- Perform Schema Merge
- Resolve any Schema Conflicts
- Perform Data Merge
- Resolve any Data Conflicts
- Resolve any Constraint Violations
Now, let’s dive into each step in order.
1. Find the Merge Base#
The first step in the merge process is to identify the merge base.
Dolt uses a similar algorithm to the merge base algorithm described above to find the merge base. Dolt uses a pre-computed commit closure to speed up the process. Dolt’s use of commit closures is worth a whole blog in itself. Aaron’s launch blog does a pretty good job explaining their motivation, how they work, and the merge performance improvements they garner.
Dolt does not support multiple merge bases in the cross merge case. In this event, Dolt will just fail to merge. To get around it, you can merge the two merge bases manually.
2. Perform Schema Merge#
Next, we must merge the schemas of both versions. Data merge cannot be performed until the schemas of both databases match.
Schema is generally small compared to data. How large could a table definition possibly be? A megabyte scale table definition seems unreasonable. Thus, schema merge is computationally light weight. The diffs to process are generally small.
However, schema merge is logically complex. There are a bunch of corner cases to handle. Schema is merged according to the following set of rules for tables, columns, indexes, foreign keys, and check constraints. If the “Mergeable” column says “Yes” that means the merge processes without conflict and produces a reasonable result. For instance, if two branches are merged that add two different columns to the same base table, the resulting merged table has both additional columns.
Tables#
| Left Branch | Right Branch | Caveat | Mergeable |
|---|---|---|---|
| Add t1 | Add t1 | Same Schema | Yes |
| Add t1 | Add t1 | Different Schema | Schema Conflict |
| Delete t1 | Delete t1 | Yes | |
| Modify t1 | Delete t1 | Schema Conflict | |
| Modify t1 | Modify t1 | Same Schema | Yes |
| Modify t1 | Modify t1 | Different Schema | Schema Conflict |
Columns#
| Left Branch | Right Branch | Caveat | Mergeable |
|---|---|---|---|
| Delete c1 | Delete c1 | Yes | |
| Modify c1 | Delete c1 | Schema Conflict | |
| Add c1 | Add c1 | Same Type, Same Constraints, Same Data | Yes |
| Add c1 | Add c1 | Different Type | Schema Conflict |
| Add c1 | Add c1 | Same Type, Different Constraints | Schema Conflict |
| Add c1 | Add c1 | Same Type, Same Constraints, Different Data | Data Conflict |
| Modify c1 | Modify c1 | Same Type, Same Constraints, Same Data | Yes |
| Modify c1 | Modify c1 | Incompatible Type Change | Schema Conflict |
| Modify c1 | Modify c1 | Compatible Type Change | Yes |
| Modify c1 | Modify c1 | Same Type, Different Constraints | Schema Conflict |
| Modify c1 | Modify c1 | Same Type, Same Constraints, Different Data | Data Conflict |
Foreign Keys#
| Left Branch | Right Branch | Caveat | Mergeable |
|---|---|---|---|
| Add fk1 | Add fk1 | Same definition | Yes |
| Add fk1 | Add fk1 | Different definition | Schema Conflict |
| Delete t1 | Delete t1 | Yes | |
| Modify fk1 | Delete fk1 | Schema Conflict | |
| Modify fk1 | Modify fk1 | Same definition | Yes |
| Modify fk1 | Modify fk1 | Different definition | Schema Conflict |
Indexes#
| Left Branch | Right Branch | Caveat | Mergeable |
|---|---|---|---|
| Add i1 | Add i1 | Same definition | Yes |
| Add i1 | Add i1 | Different definition | Schema Conflict |
| Delete i1 | Delete i1 | Yes | |
| Modify i1 | Delete i1 | Schema Conflict | |
| Modify i1 | Modify i1 | Same definition | Yes |
| Modify i1 | Modify i1 | Different definition | Schema Conflict |
Check Constraints#
| Left Branch | Right Branch | Caveat | Mergeable |
|---|---|---|---|
| Add ck1 | Add ck1 | Same definition | Yes |
| Add ck1 | Add ck1 | Different definition | Schema Conflict |
| Delete ck1 | Delete ck1 | Yes | |
| Modify ck1 | Delete ck1 | Schema Conflict | |
| Modify ck1 | Modify ck1 | Same definition | Yes |
| Modify ck1 | Modify ck1 | Different definition | Schema Conflict |
3. Resolve any Schema Conflicts#
In the event of a schema conflict, the user must be presented with a user interface to view and resolve conflicts. In Dolt, this interface is influenced heavily from Git but adapted to SQL, the interface you have available in a SQL database.
The dolt_status system table tells you which tables have conflicts and whether they are schema or data conflicts. An example table looks like:
three_way_merge> SELECT * FROM dolt_status;
+------------+--------+-----------------+
| table_name | staged | status |
+------------+--------+-----------------+
| people | false | schema conflict |
+------------+--------+-----------------+Then there is the dolt_schema_conflicts table that describes the conflict.
three_way_merge> SELECT table_name, description, base_schema, our_schema, their_schema FROM dolt_schema_conflicts;
+------------+----------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+
| table_name | description | base_schema | our_schema | their_schema |
+------------+----------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+
| people | different column definitions for our column age and their column age | CREATE TABLE `people` ( | CREATE TABLE `people` ( | CREATE TABLE `people` ( |
| | | `id` int NOT NULL, | `id` int NOT NULL, | `id` int NOT NULL, |
| | | `last_name` varchar(120), | `last_name` varchar(120), | `last_name` varchar(120), |
| | | `first_name` varchar(120), | `first_name` varchar(120), | `first_name` varchar(120), |
| | | `birthday` datetime(6), | `birthday` datetime(6), | `birthday` datetime(6), |
| | | `age` int DEFAULT '0', | `age` float, | `age` bigint, |
| | | PRIMARY KEY (`id`) | PRIMARY KEY (`id`) | PRIMARY KEY (`id`) |
| | | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin; | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin; | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin; |
+------------+----------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+-------------------------------------------------------------------+And finally, we have a convenience procedure called dolt_conflicts_resolve to take ours or theirs side of the merge and resolve the conflict. Otherwise, the user must modify the schema to the desired merge state and delete the row from dolt_schema_conflicts to resolve the conflict.
To complete the merge, the user issues a call to the dolt_commit() procedure to commit the merge.
4. Perform Data Merge#
After the schemas of the tables are merged, it is time to merge the data in the tables.
Merging large tables is computationally complex. Thus, you need table data stored in a data structure that can be diffed quickly. Prolly Trees fit the bill for Dolt. Prolly Trees are a recent invention, pioneered by the Noms team in 2015-2018. Thus, Dolt is the first SQL database to provide three-way merge on data in tables.
Unlike schema merge, data merge is logically simple. Data is identified by primary key across versions. If two branches modify different keys, the changes can be safely merged. If two branches modify the same key, a further diff is performed. If the two branches modify different columns in the row, the changes can be safely merged. If the two branches modify the same [primary key, column] pair to the same value, that is the merged value. However, if two branches modify the same [primary key, column] pair to a different value a data conflict is thrown.
A special case in the above rule is JSON-typed columns. An additional merge check is performed if two branches modified a JSON column identified by primary key to a different value. JSON-typed columns safely merge if the changes on each branch did not modify the same key in the stored JSON. Thus, two branches can be merged they modify the same JSON object, identified by primary key, but don’t modify the same keys in the JSON itself.
Algorithmically, data merge is processed using a slightly simpler algorithm than described in diff3 Merge Algorithm section because primary keys are substituted for longest possible sequences as cross version identifiers.
There is also an additional conflict check if two primary keys are modified to satisfy the different column edits “mergeable” condition. So, you walk through the primary keys of the into and from sets, and process each according to the following rules:
- Modified row is the same in into and from
If into.primarykey == from.primarykey and into.value == from.value, merge.primarykey = into.primarykey.
Result: Merged row is the value of into
- Modified row is different in into and from
If into.primarykey == from.primarykey and into.value != from.value, inspect columns. Conflict if edit on the same column to different values. Otherwise, merge.primarykey.values = merged.values.
Result: Conflict if the edits are to the same column and different values. Otherwise, merge edits to columns. Merged row is set to the merged values in columns.
- New or deleted row in into
If into.primarykey != from.primarykey, merge.primarykey = into.primarykey.
Result: Add or delete into row in merged set
- New or deleted row in from
If from.primarykey != into.primarykey, merge.primarykey = from.primarykey
Result: Add or delete from row in merged set
This may seem a bit complicated but the results are intuitive as you will see later in an example.
5. Resolve any Data Conflicts#
In the event of a data conflict, the user must be presented with a user interface to view and resolve conflicts. Again, this interface is inspired by Git but adapted to SQL. The interface is very similar to the one described in the Schema Conflicts section.
The dolt_status system table tells you which tables have conflicts and whether they are schema or data conflicts. An example table looks like:
three_way_merge> SELECT * FROM dolt_status;
+------------+--------+-----------------+
| table_name | staged | status |
+------------+--------+-----------------+
| people | false | data conflict |
+------------+--------+-----------------+Two additional tables can be used to explore and resolve conflicts. The dolt_conflicts table tells you the number of conflicts in each table. The dolt_conflicts_<tablename> table lists the individual rows in conflict for the table <tablename>.
SELECT * FROM dolt_conflicts;
+--------+---------------+
| table | num_conflicts |
+--------+---------------+
| people | 3 |
+--------+---------------+
SELECT * FROM dolt_conflicts_people;
+-----------------+----------------+---------+-----------------+----------+----------------+---------------+--------+----------------+---------+------------------+-----------------+----------+------------------+-----------+
| base_occupation | base_last_name | base_id | base_first_name | base_age | our_occupation | our_last_name | our_id | our_first_name | our_age | their_occupation | their_last_name | their_id | their_first_name | their_age |
+-----------------+----------------+---------+-----------------+----------+----------------+---------------+--------+----------------+---------+------------------+-----------------+----------+------------------+-----------+
| Homemaker | Simpson | 1 | Marge | 37 | Homemaker | Simpson | 1 | Marge | 36 | NULL | NULL | NULL | NULL | NULL |
| Bartender | Szyslak | 2 | Moe | NULL | Bartender | Szyslak | 2 | Moe | 62 | Bartender | Szyslak | 2 | Moe | 60 |
| NULL | NULL | NULL | NULL | NULL | Student | Simpson | 3 | Bart | 10 | Student | Simpson | 3 | Lisa | 8 |
+-----------------+----------------+---------+-----------------+----------+----------------+---------------+--------+----------------+---------+------------------+-----------------+----------+------------------+-----------+Again, the convenience procedure called dolt_conflicts_resolve can be used to take the ours or theirs side of the merge and resolve the conflict. Otherwise, the user must modify the conflicting row to the desired merge state and delete the row from dolt_conflicts_<tablename> to resolve the conflict.
To complete the merge, the user issues a call to the dolt_commit() procedure to commit the merge.
6. Resolve any Constraint Violations#
Adding even more logical complexity are foreign keys. Data merges that involve foreign keys may not be able to be resolved at merge time because multiple tables are involved. This is best seen through an illustrative example.
Consider the following schema:
mysql> create table employees (
id int,
last_name varchar(100),
first_name varchar(100),
age int,
primary key(id),
constraint over_18 check (age >= 18));
mysql> show create table employees;
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| employees | CREATE TABLE `employees` (
`id` int NOT NULL,
`last_name` varchar(100),
`first_name` varchar(100),
`age` int,
PRIMARY KEY (`id`),
CONSTRAINT `over_18` CHECK ((`age` >= 18))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
mysql> create table pay (id int,
salary int,
primary key(id),
foreign key (id) references employees(id));
mysql> show create table pay;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| pay | CREATE TABLE `pay` (
`id` int NOT NULL,
`salary` int,
PRIMARY KEY (`id`),
CONSTRAINT `kfkov1vc` FOREIGN KEY (`id`) REFERENCES `employees` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+We have three tables, two of which reference a parent table via foreign key. We then delete a row in the parent table on one branch and insert a value referencing the deleted row on another branch.
mysql> insert into employees values (0, 'Smith', 'Ella', 34), (1, 'Baker', 'Jack', 27);
mysql> insert into pay values (0, 50000);
mysql> call dolt_commit('-am', "Data for foreign key doc");
+----------------------------------+
| hash |
+----------------------------------+
| kgjb1tdbqt3vsn2e3nv06n5a6jdaqtk8 |
+----------------------------------+
mysql> call dolt_checkout('-b', 'delete-parent');
+--------+
| status |
+--------+
| 0 |
+--------+
mysql> delete from employees where id=1;
mysql> call dolt_commit('-am', "Deleted Jack Baker, id=1");
+----------------------------------+
| hash |
+----------------------------------+
| pd8r1j7or0aonincnc8iutsdjqnkmtsb |
+----------------------------------+
mysql> call dolt_checkout('main');
+--------+
| status |
+--------+
| 0 |
+--------+
mysql> insert into pay values (1, 48000);
mysql> call dolt_commit('-am', "Added salary for Jack Baker id=1");
+----------------------------------+
| hash |
+----------------------------------+
| 44h9p2k59o59rc1lcenkg4dghe052um0 |
+----------------------------------+Finally, we attempt to merge and because the resulting merge has constraint violations we cannot commit the merge.
mysql> call dolt_merge('delete-parent');
Error 1105: Constraint violation from merge detected, cannot commit transaction. Constraint violations from a merge must be resolved using the dolt_constraint_violations table before committing a transaction. To commit transactions with constraint violations set @@dolt_force_transaction_commit=1To resolve this error, the constraint violation must be resolved manually before the merge can proceed. This means making sure all foreign key checks satisfy the requisite constraints. Similarly to the conflicts system tables, you can view the number of violated constraints in the dolt_constraint_violations system table and the actual constraint violations in the dolt_constraint_violations_<tablename> system tables. In this case, you must either add back the “Jack Baker” row or delete the salary for the “Jack Baker” reference.
SQL Transactions in Dolt#
I’ll dive into one more merge nuance before I get into an illustrative example, standard SQL transactions in Dolt. As we discussed earlier, transactions in standard SQL databases implement a basic three-way merge. How are SQL transactions handled in Dolt?
Dolt uses the same logic to perform Commit Graph merges as it does to merge standard SQL transactions. You can think of a SQL transaction in Dolt performing the above merge steps on the proposed working set to the current working set with concurrent transactions resolving in some order. If a conflict is encountered, a ROLLBACK statement is issued for the first transaction that conflicted.
This is a different locking and merge technique than standard SQL databases which use locks to provide concurrency and conflict detection. This can result in Dolt producing different results than you are used to under concurrency.
Because SQL transactions and Dolt merges share the same transaction merge code, interactive Dolt merges must be performed in a single transaction in the SQL context. This means you must turn off AUTOCOMMIT and begin a transaction with START TRANSACTION to perform an interactive merge. You then call the dolt_merge() procedure and you can proceed through the six merge phases. The dolt_commit() call that completes the merge implicitly commits the transaction you started with START TRANSACTION. If you have AUTOCOMMIT enabled, a dolt_merge() call that encounters a conflict is automatically rolled back just like a standard SQL transaction.
Example#
Let’s walk through a schema and data merge example with no conflicts to illustrate the above concepts and user interface. I’m using the Dolt command line because that ignores SQL context complexity.
First to set up, we create a database table and insert a couple rows. Finally, we make a commit. This will be used as our merge base.
$ mkdir threeway_merge
$ cd threeway_merge
$ dolt init
Successfully initialized dolt data repository.
$ dolt sql -q 'create table `databases`(name varchar(30) primary key)'
$ dolt sql -q 'show tables'
+--------------------------+
| Tables_in_threeway_merge |
+--------------------------+
| databases |
+--------------------------+
$ dolt sql -q 'insert into `databases` values ("Oracle"), ("MySQL")'
Query OK, 2 rows affected (0.00 sec)
$ dolt add databases
$ dolt commit -m "Databases table with initial rows"
commit t19jjvtjrmddqnp2s1djbbe0j7k2pfra (HEAD -> main)
Author: timsehn <tim@dolthub.com>
Date: Wed Jun 12 15:30:35 -0700 2024
Databases table with initial rows
To trigger our commit as our merge base, we create two branches.
$ dolt branch add-release-date
$ dolt branch add-latest-versionThen, we add a release date column and populate it on the add-release-date branch, finishing with a commit.
$ dolt checkout add-release-date
Switched to branch 'add-release-date'
$ dolt sql -q 'alter table `databases` add column release_date date'
$ dolt sql -q 'show create table `databases`'
+-----------+------------------------------------------------------------------+
| Table | Create Table |
+-----------+------------------------------------------------------------------+
| databases | CREATE TABLE `databases` ( |
| | `name` varchar(30) NOT NULL, |
| | `release_date` date, |
| | PRIMARY KEY (`name`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-----------+------------------------------------------------------------------+
$ dolt sql -q 'update `databases` set release_date="1979-06-01" where name="Oracle"'
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
$ dolt sql -q 'update `databases` set release_date="1995-05-23" where name="MySQL"'
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
$ dolt sql -q 'select * from `databases`'
+--------+--------------+
| name | release_date |
+--------+--------------+
| MySQL | 1995-05-23 |
| Oracle | 1979-06-01 |
+--------+--------------+
$ dolt diff
diff --dolt a/databases b/databases
--- a/databases
+++ b/databases
CREATE TABLE `databases` (
`name` varchar(30) NOT NULL,
+ `release_date` date,
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
+---+--------+--------------+
| | name | release_date |
+---+--------+--------------+
| < | MySQL | NULL |
| > | MySQL | 1995-05-23 |
| < | Oracle | NULL |
| > | Oracle | 1979-06-01 |
+---+--------+--------------+
$ dolt add databases
$ dolt commit -am "Added release date column and relevant release dates"
commit ape4hm5hicsoci3uscs466cciiv7dis6 (HEAD -> add-release-date)
Author: timsehn <tim@dolthub.com>
Date: Wed Jun 12 15:42:17 -0700 2024
Added release date column and relevant release datesThen, we add a latest version column and populate it on the add-latest-version branch, finishing with a commit.
$ dolt checkout add-latest-version
Switched to branch 'add-latest-version'
$ dolt sql -q 'alter table `databases` add column latest_version varchar(30)'
$ dolt sql -q 'update `databases` set latest_version="19c" where name="Oracle"'
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
$ dolt sql -q 'update `databases` set latest_version="8.4.0" where name="MySQL"'
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
$ dolt sql -q 'select * from `databases`'
+--------+----------------+
| name | latest_version |
+--------+----------------+
| MySQL | 8.4.0 |
| Oracle | 19c |
+--------+----------------+
$ dolt diff
diff --dolt a/databases b/databases
--- a/databases
+++ b/databases
CREATE TABLE `databases` (
`name` varchar(30) NOT NULL,
+ `latest_version` varchar(30),
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
+---+--------+----------------+
| | name | latest_version |
+---+--------+----------------+
| < | MySQL | NULL |
| > | MySQL | 8.4.0 |
| < | Oracle | NULL |
| > | Oracle | 19c |
+---+--------+----------------+
$ dolt add databases
$ dolt commit -am "Added latest_version column and relevant values"
commit kkdc9381jghbj4obvbvbajd2t7bj7g4f (HEAD -> add-latest-version)
Author: timsehn <tim@dolthub.com>
Date: Wed Jun 12 15:46:47 -0700 2024
Added latest_version column and relevant valuesNow, the moment of truth, the merge. The first is a fast-forward because there are no parallel changes on main.
$ dolt checkout main
Switched to branch 'main'
$ dolt merge add-release-date
Fast-forward
Updating ape4hm5hicsoci3uscs466cciiv7dis6..ape4hm5hicsoci3uscs466cciiv7dis6
databases | 2 **
1 tables changed, 0 rows added(+), 2 rows modified(*), 0 rows deleted(-)
$ dolt sql -q "select * from `databases`"
+--------+--------------+
| name | release_date |
+--------+--------------+
| MySQL | 1995-05-23 |
| Oracle | 1979-06-01 |
+--------+--------------+Now, the second branch. This is the true three-way merge scenario.
$ dolt merge add-latest-version
Updating eovnrsqrhnvl4nep0ak2k88e4tu2mjs2..kkdc9381jghbj4obvbvbajd2t7bj7g4f
commit eovnrsqrhnvl4nep0ak2k88e4tu2mjs2 (HEAD -> main)
Merge: ape4hm5hicsoci3uscs466cciiv7dis6 kkdc9381jghbj4obvbvbajd2t7bj7g4f
Author: timsehn <tim@dolthub.com>
Date: Wed Jun 12 15:49:11 -0700 2024
Merge branch 'add-latest-version' into main
databases | 2 **
1 tables changed, 0 rows added(+), 2 rows modified(*), 0 rows deleted(-)
$ dolt sql -q "select * from `databases`"
+--------+--------------+----------------+
| name | release_date | latest_version |
+--------+--------------+----------------+
| MySQL | 1995-05-23 | 8.4.0 |
| Oracle | 1979-06-01 | 19c |
+--------+--------------+----------------+And we get the expected result. Two columns added with all cells populated.
This simple example belies all the technical complexity from the storage engine up to make three-way merge work at scale. As part of our discontinued Data Bounties initiative, we’ve merged millions of rows into tables containing hundreds of millions of rows. Dolt merge works at scale.
This blog is already reaching opus length, I will follow up with a blog that has more merge examples that generate and resolve conflicts.
Conclusion#
Dolt is the first SQL database to implement three-way merge of schema and data. This functionality is powered by Dolt’s unique storage engine that features a commit graph and Prolly-tree based storage for fast diff. Curious to learn more? Come by our Discord and we’d be happy to chat.