Dolt Is 25% Faster Running TPC-C

Dolt is the first relational database that versions data the same way Git versions source code. Dolt is 100% MySQL compliant and implements Git's interface with the same "proportional to diff" runtime.
We spend a lot of time making sure we compete with MySQL on every angle, including performance. In previous blogs we talk about reaching 1x writes and 2x reads in sysbench, and more recently work focused on TPC-C.
Methodology
We currently run TPC-C with one client scaled to one table on an AWS
m5a.2xlarge with a 30GB gp3 volume. We run tpcc.lua prepare,
collect index statistics once, and then run tpcc.lua run for 8 minutes. We
run the MySQL benchmark and the Dolt benchmark consecutively on the same
host.
We are interested in testing concurrently and running background statistic updates, but are optimizing the simplest model before testing scaled variations.
Stats
The TLDR of today is that we are 4x MySQL's single threaded TPC-C throughput, down from 5x at the beginning of the year. We have some graphs that describe that trend in mostly the same way:
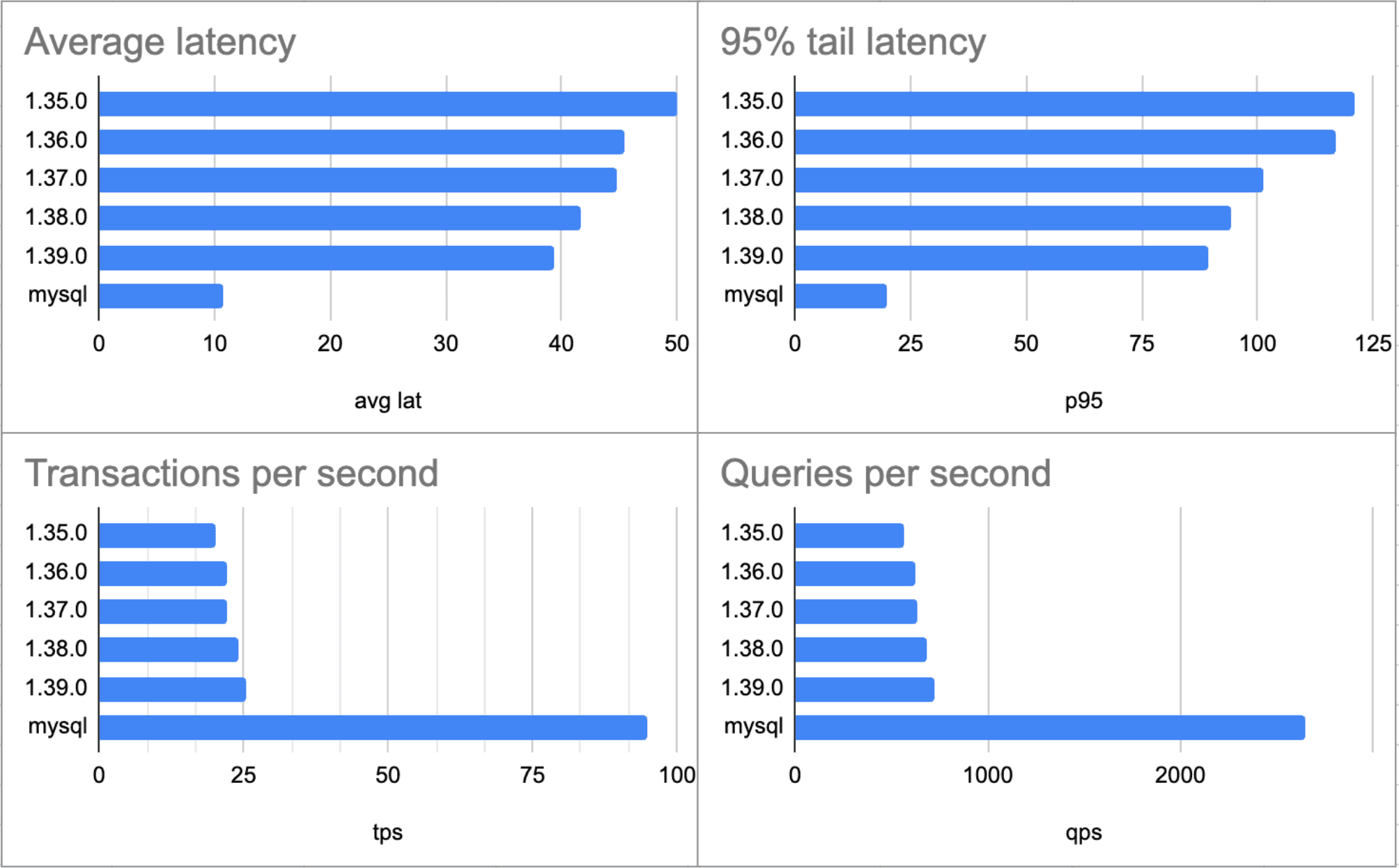
These plots summarize the main metrics we use to measure TPC-C:
- queries per second (QPS)
- average latency for all queries
- transactions per second (TPS) (1/average latency)
- 95% latency (p95)
As we make Dolt faster, these trends will all continue moving in the same direction. I would expect us to exceed 3x MySQL's performance by the end of the year, with QPS, average latency, and p95 all tracking similarly. We'll describe some of the work that moved the needle later.
A second observation is that previously, Dolt spent the most time executing queries with latency between 1ms and 10ms. The plot below is a weighted average of where Dolt spends time during a TPC-C run. (This is in contrast to a plot of query latency, which would just horizontally translate queries left as things get faster):
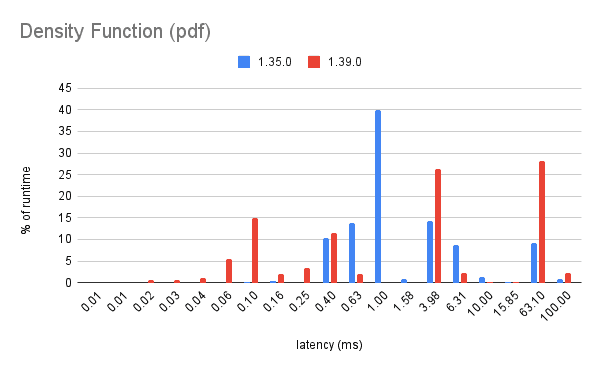
Version 1.35.0 spent 65% of the time executing ~1ms queries. But now small queries execute much faster in Dolt. The bottleneck is now ~5ms and ~100ms queries, which dominate 60% of TPC-C's runtime.
Small changes to the 5ms and 60ms queries will now disproportionally improve our TPC-C performance, shifting the bottleneck back in the other direction.
Perf Details
Most sysbench tests hammer the same query repeatedly. TPC-C's mixed workload is a much harder benchmark, running something like 50 different queries per transaction. Each COMMIT writes more data to more tables, the database reaches 10GB's in size, cache coherency is a big source of tail latency.
It is hard to fool TPC-C with optimizations that do not generalize in a way that customers benefit. But this is also why we love TPC-C. Throughput gains are a balanced reflection of how accurately real mixed workloads perform on Dolt.
We will discuss some of the work focused on making small queries fast.
Schema Caching
The initial caching we added for sysbench used "store root values" as the caching key. Store root values are Merkle hashes of the database state, which change after every write. Mixed read and write workloads benefit little from caching that depends on frequently changing root values. Fortunately, most of the cached objects we use only change in between DDL operations. So we started using schema hashes as cache keys. Expensive index, check, and trigger objects are now reused as long as a table's schema doesn't change.
Filter Coercion
Dolt's SQL engine lazily evaluates filter expression types. If an equality expression's two arguments are not the same type at execution time, we cast the two operands to a common type to match MySQL's behavior. But this casting is expensive. We can often preemptively cast operands to skip this runtime check.
EXPLAIN UPDATE stock2 SET s_quantity = 5 WHERE s_i_id = 64568 AND s_w_id= 1`;
Update
└─ UpdateSource(SET stock2.s_quantity:2 = 5)
└─ Filter
├─ Eq
│ ├─ stock2.s_w_id:1!null
- │ └─ 1 (tinyint)
+ │ └─ 1 (smallint)
└─ IndexedTableAccess(stock2)
├─ index: [stock2.s_i_id]
├─ static: [{[64568, 64568]}]
├─ colSet: (1-17)
├─ tableId: 1
└─ Table
└─ name: stock2Ref Checking
All parent references in a Dolt database have valid child references. It is rare, but garbage collection cycles can delete dangling child references that uncommitted transactions depend on.
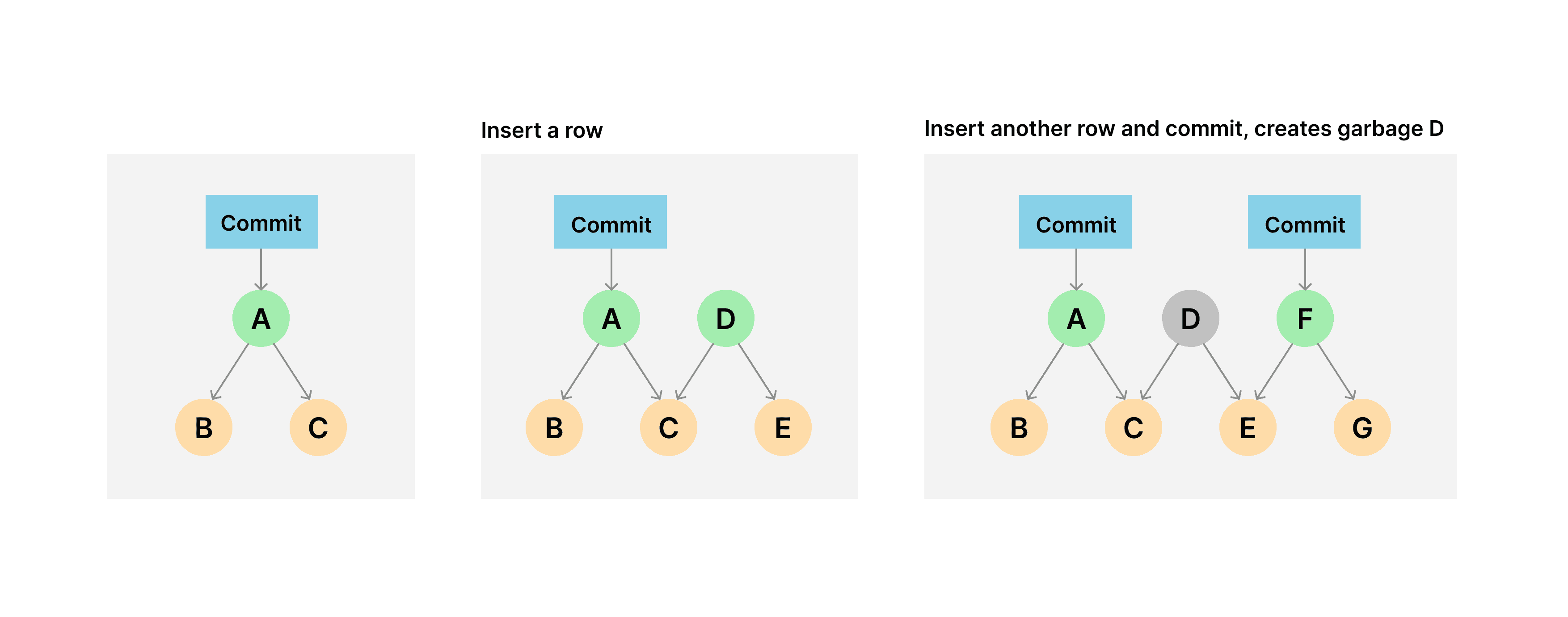
We perform sanity checks when committing new data to ensure GC has not invalidated new chunks. In the future we might be able to elide these checks for transactions that begin and end outside of a GC cycle, but in the meantime we limited the number of pending refs we check and pooled ref collection.
Analysis Shortcuts
One of the motivations for rewriting our query binder was limiting common analyzer rules in favor of query-specific rules. Rules that only targeted one or two query types are inlined during binding. We went a bit farther this time with simple INSERT, UPDATE, and DELETE queries because they common and benefit from few transformations.
EXPLAIN INSERT INTO
order_line1 (ol_o_id, ol_d_id, ol_w_id, ol_number, ol_i_id, ol_supply_w_id, ol_quantity, ol_amount, ol_dist_info)
VALUES (3343,5,1,3,45870,1,8,447,'yyyyyyyyyyyyyyyyyyyyyyyy');
+--------------------------------------------------------------------------------------------------------------------------+
| plan |
+--------------------------------------------------------------------------------------------------------------------------+
| Insert(ol_o_id, ol_d_id, ol_w_id, ol_number, ol_i_id, ol_supply_w_id, ol_quantity, ol_amount, ol_dist_info) |
| ├─ Table |
| │ └─ name: order_line1 |
| └─ Project |
| ├─ columns: [ol_o_id, ol_d_id, ol_w_id, ol_number, ol_i_id, ol_supply_w_id, , ol_quantity, ol_amount, ol_dist_info] |
| └─ Values(3343,5,1,3,45870,1,8,447,'yyyyyyyyyyyyyyyyyyyyyyyy') |
+--------------------------------------------------------------------------------------------------------------------------+We now short circuit analysis for DML operations that lack subqueries. We also now use a simpler execution index assignment rule for DMLs because they are so common and simple to build.
Indexing
Our append-only chunk journal periodically writes journal index entries to speedup server initialization. But the size of index entries and batching flushes was a high source of tail latency. Chunk writes now eagerly write smaller index entries to buffers that flush to disk in the background.
Transaction Overhead
Transactions read and modify some system variables to maintain session consistency and bookkeeping. One of these is the "SQL_MODE" variable, which can modify how we parse queries and which validation rules are enforced. The default value is long string that is expensive to load, so we have a fast path that makes the default SQL_MODE cheap. Other system variables are counters, which we refactored from mutex protected integers into atomic integers.
Spooling
By default we assume queries will return many rows. So we batch and
spool results to limit network overhead back to the client. But the
overhead of this background work hurts the performance of small queries,
like START TRANSACTION, DML, and COMMIT statements. We now use a
custom spooler for query types that return a predictable number of
rows. We will be
able to generalize this in the future for reads that return a single
row.
Summary
TPC-C is a great way to make Dolt faster. The benchmark tests a mix of slow and fast reads and writes on a large database. Making TPC-C faster has even improved our sysbench metrics in many cases.
And we're still getting faster! The latest release is 3.5X MySQL's transaction throughput. We will issue an update again when we reach 3X MySQL's performance.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!