
This is the third in a series about how Dolt stores bytes on disk. The first two parts provide a lot of context about what today’s blog is about: A new storage format!
Two weeks ago we reviewed the existing storage system and its index lookups. This should look familiar:
One week ago we covered some interesting finding on the information density of our existing storage, and how we can use dictionary compression to reduce our storage footprint by as much as 50%.

If either of the images is not recognizable to you, I strongly recommend you take look at those posts before continuing.
A New Format. Why?#
Given the findings from last week, we are building a new storage format which we are calling an Archive. At the moment, we are considering Archives to be colder storage than our existing NOMS table files, but they could very well be optimized to be a replacement. The more immediate roadmap item which we are working toward is enabling the ability to truncate your database history and put the data removed into storage somewhere else. With this goal in mind, we want to get the Chunks of your old history, ie all the stuff you want to ship off, into a storage format which compact, has high integrity, and more flexibility.
The following requirements are guiding the design discussed below:
- Asynchronous assembly of archives. Compacting existing storage files without disruption is necessary due to the time requirements of compression.
- Archives should be as compact as possible.
- Constant time reads of individual Chunks from the Archive is required.
- Integrity of the bytes within the data and index must be verifiable with strong cryptographic checksums.
- Semi structured Metadata for the Archive must be embedded withing the file to enable richer applications in the future.
What We’ve Come Up With#
The Noms format has proved remarkably robust for us, so we start with a similar approach, but will add a little more flexibility. First, the high level format is very similar to NOMS, with the addition of the Metadata section.

These sections are not portrayed proportionally, and each is responsible for:
- Data: The Data block is a range of storage that is read using offsets and lengths. Each addressable piece of data is called a ByteSpan. There is not a 1-1 correlation of ByteSpans to Chunks, unlike the equivalent ChunkRecords in the NOMS format. Each ByteSpan is referred to by its sequence position in the file, and we address them starting a
1, because0is used as the empty/NULL ByteSpan. - Index: The Index block contains all the address information for what is stored in Data. The primary interface for for looking up Chunks is the same as for NOMS:
ContainsandRetrieve. The Index layout has been overhauled for the use of dictionary compression, and we’ll spend most of today talking about it. - Metadata: The Metadata block exists to allow us to add other information we might care about related to the Archive. This might include the version of Dolt which created the archive, and possibly links to DoltHub to indicate where other related Archives might be stored. Ultimately it’s future proofing to allow us to have more flexibility in the future.
- Footer: The Footer section is a constant size end of the file which contains the information required to load and parse the previous three sections. The Footer also contains the SHA512 checksum of each section such that we can verify integrity. Finally, there is a version byte which will allow us to evolve the format over time.
The New Index#
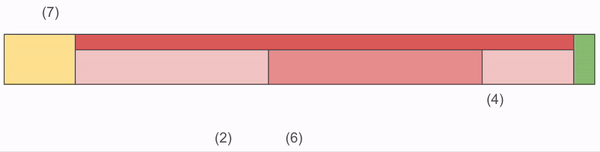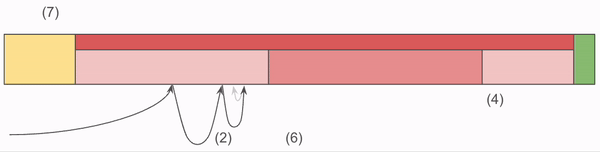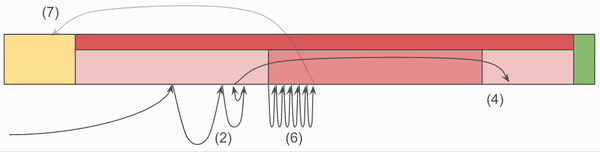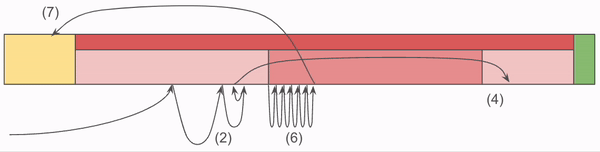
Similar to the NOMS Index, the Archive index consists of a group of maps which allow us to quickly determine if a Chunk is in the file, and if so where it is in the Data block. The Archive Index drops the use of Ordinals, and depends strictly on the ordering of the four maps below being aligned:

- ByteSpan Map: Each entry from 1-N (inclusive) is the Length of each ByteSpan. While loading the Index into memory, the Offset of each is calculated as the sum of all the Lengths which came before. N is the total number of ByteSpans in the Archive, which will vary depending on the amount of compression performed.
- Prefixes Map: Similar to NOMS, we store a
uint64which is the first 8 bytes of the Chunk address. M is the number of Chunks stored in the Archive, and the Prefix Map is in sorted order so that we can quickly search for a given address using a Prolly Search. - Chunk Reference Map: Chunk References consist of two integers which are ByteSpan identifiers. The first ByteSpan is the dictionary used to compress the Chunk, and the second ByteSpan is the compressed Chunk itself.
- Suffixes Map: Similar to NOMS, we store the Chunk address suffixes to ensure that we don’t misidentify Chunks with on the Prefix. After the Prefix search is completed, we compare the desired address with the Suffix to ensure we didn’t run into a false positive.
Contains#
The Contains operation is one of our primary access patterns, and it is fairly similar to the NOMS operation.
- Strip the first 8 bytes of the address, and call that the Prefix.
- Perform a search on the Prefix map, once one is found search the vicinity for additional matches.
- For the set of matched Prefixes, use their indexes to lookup in the Suffixes Map for a match of the Address.
- If one matches, the Chunk exists in the file.
In the following example, there are 3 keys: ABC, LMN, and TUV. For each, the first character is considered the Prefix, and the second two are the Suffix. This is exactly the same example from the previous review, so if you want to compare and contrast, take a look.

The first thing to call out is that the left most portion of the index has 5 entries, while the three on the right have 3. These counts are determined from the footer. Also note that the IDs for each are not all 0 based. To clarify:

Let’s determine if the storage file contains ABC. We pull the Prefix, A off of our desired address ABC. The Prefix Map contains A,L,T, so doing a binary search we determine that the index 0 contains the prefix.

This example contains no collisions in the Prefix Map, but in the general case we find all matching Indexes, and look up each one in the Suffix Map.

Using the 0 index from the prefix search, we look at the Suffix index 0, and confirm that the Suffix, BC matches what we are looking for. Therefore, this Archive contains the Chunk ABC.
Retrieve#
To Retrieve the object requires additional steps. Using the Contains algorithm, we get the Prefix/ChunkRef/Suffix index of the Chunk found, then:
- Get the ChunkReference, and from that we get two ByteSpan IDs: Dictionary and Data
- Dictionary and Data are then used to grab each from the Offset and Lengths of each in the ByteSpan Map.
- Finally, both ByteSpans are read from disk, and used to decompress the Chunk for us.
To continue our example, to retrieve the value for ABC, using the index 0 from before, we obtain the ChunkReference:

The two values in the ChunkReference, 4 and 5, refer to the ByteSpan ID:

Now, with the two ByteSpan IDs, we can read both Offsets/Lengths from disk to obtain our dictionary and compressed data. Note, the ByteSpan map in the following image has the calculated offsets added to the picture as underlined values. These are the sum of the lengths which precede each.

These two reads give us a dictionary of D3 and data of 61,47,69,74. Using the zStandard protocol, we decompress the data using the dictionary, and the result is the Chunk we were looking for.
Conclusion#
We are currently working out kinks in our build system to enable us to use the zStd C implementation, but we should have this available to beta test in the next week or two. The initial release will enable you to perform garbage collection with an additional flag, --compress, which will reduce the size of your database footprint. Before we can make it the default though, we want to make sure the performance is acceptable, so check in next week for more updates on the Dolt Storage! If you just can’t wait, join us on Discord!