
Dolt is a MySQL-compatible SQL database with Git-like versioning features. It supports branching, merging, diff, push, pull and clone of the entire database — schema and data. Dolt’s data versioning features are based on a unique sorted index structure called a Prolly-tree, which we’ve blogged about a number of times previously.
One of the advantages of a Prolly-tree is structural sharing between historical revisions of the data in a database. This structural sharing naturally falls out of how Prolly-trees encode the sorted tuples that make up the contents of a table or index in a revision of the database. Dolt makes concrete trade offs in choosing how to encode and store table and index data into Prolly-trees, and those trade offs effect how the trees change between revisions and consequently how much structural sharing Dolt achieves for different types of edits against tables and indexes with different schemas.
This blog post is a quick look at a specific, relatively popular Dolt database and how it behaves with regards to structural sharing in Dolt. In particular, we will see why its current schema achieves very compelling structural sharing and why adding an seemingly natural index on the primary table of the dataset causes the space utilization of the database to grow substantially. In the conclusion, we’ll talk about future feature work we hope to build into Dolt to better handle the indexed use case.
Stocks Database#
DoltHub is a website we run where people can collaborate on and share public and private datasets in the form of Dolt databases. One of the more popular public datasets on DoltHub is the post-no-preference/stocks database, which has OHLCV data for a number of exchange traded securities traded on exchanges in the United States.
The database itself includes some extra details like dividends and splits, but the bulk of the data comprises the ohlvc table, which has the datapoints for each ticker on each trading day. At the time of this writing, the ohlcv table has 13,380,581 entries across 14,108 tickers going back to 2018-01-16. The schema of the ohlcv table looks like:
stocks/master> show create table ohlcv;
+-------+------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------+
| ohlcv | CREATE TABLE `ohlcv` ( |
| | `date` date NOT NULL, |
| | `act_symbol` varchar(16383) NOT NULL, |
| | `open` decimal(7,2), |
| | `high` decimal(7,2), |
| | `low` decimal(7,2), |
| | `close` decimal(7,2), |
| | `volume` bigint, |
| | PRIMARY KEY (`date`,`act_symbol`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin |
+-------+------------------------------------------------------------------+
1 row in set (0.00 sec)For our purposes, it’s important to take note of the PRIMARY KEY, which is (date, act_symbol). Also of note is the typical import and edit pattern of this data set. The recent commit log for the stocks database looks like:
stocks/master> select commit_hash, date, message from dolt_log limit 10;
+----------------------------------+---------------------+----------------------------+
| commit_hash | date | message |
+----------------------------------+---------------------+----------------------------+
| 99tckrp62d59f6vli48oh5ohsutg4gus | 2024-04-09 09:46:36 | ohlcv 2024-04-08 update |
| al4k6r9b62hkb5u1nf3bs9a9qdsfb8th | 2024-04-08 09:00:35 | symbol 2024-04-07 update |
| bpi2g2ied5v7kv2gc5h3cnnqd764vdbl | 2024-04-07 10:46:15 | split 2024-04-07 update |
| o9mepvhicosdnfptliklonnnrp4gqbne | 2024-04-06 09:46:35 | ohlcv 2024-04-05 update |
| fslle64m8lb4t28dotfbl2b66sugbrm6 | 2024-04-05 09:46:35 | ohlcv 2024-04-04 update |
| 3prq3de30d122aa4ldp2ug5j3mnsvq4t | 2024-04-04 09:46:35 | ohlcv 2024-04-03 update |
| t6dik101n83sgko26esqf03r11pp2hjs | 2024-04-03 10:00:07 | dividend 2024-04-03 update |
| u4m82vnmi8jao0kjmt4bfub8jsaduva8 | 2024-04-03 09:46:35 | ohlcv 2024-04-02 update |
| hcan9bo9fiqbnne056r2ikv7f22uimpt | 2024-04-02 10:01:14 | dividend 2024-04-02 update |
| 6ff5m2i3uc66nov6fs4dqhq7ul9q4r6e | 2024-04-02 09:46:35 | ohlcv 2024-04-01 update |
+----------------------------------+---------------------+----------------------------+
10 rows in set (0.00 sec)The messages indicate that a whole day’s worth of ohlcv data gets added at a time. And indeed, we can see that in the diffs:
stocks/master> select to_date, to_act_symbol, to_open, to_high, to_low, to_close, to_volume, from_date, from_act_symbol, diff_type from dolt_diff_ohlcv where to_commit = '99tckrp62d59f6vli48oh5ohsutg4gus' limit 10;
+------------+---------------+---------+---------+--------+----------+-----------+-----------+-----------------+-----------+
| to_date | to_act_symbol | to_open | to_high | to_low | to_close | to_volume | from_date | from_act_symbol | diff_type |
+------------+---------------+---------+---------+--------+----------+-----------+-----------+-----------------+-----------+
| 2024-04-08 | A | 143.80 | 145.79 | 143.01 | 144.46 | 1247293 | NULL | NULL | added |
| 2024-04-08 | AA | 36.91 | 37.15 | 36.21 | 36.34 | 4690518 | NULL | NULL | added |
| 2024-04-08 | AAA | 25.13 | 25.13 | 25.08 | 25.08 | 2001 | NULL | NULL | added |
| 2024-04-08 | AAAU | 23.09 | 23.19 | 22.95 | 23.15 | 3099474 | NULL | NULL | added |
| 2024-04-08 | AACG | 1.02 | 1.10 | 1.02 | 1.07 | 3790 | NULL | NULL | added |
| 2024-04-08 | AACI | 11.37 | 11.85 | 11.37 | 11.50 | 9288 | NULL | NULL | added |
| 2024-04-08 | AACT | 10.58 | 10.59 | 10.57 | 10.59 | 171756 | NULL | NULL | added |
| 2024-04-08 | AADI | 2.10 | 2.25 | 2.08 | 2.15 | 82272 | NULL | NULL | added |
| 2024-04-08 | AADR | 62.06 | 62.48 | 62.06 | 62.48 | 128 | NULL | NULL | added |
| 2024-04-08 | AAGR | 0.31 | 0.35 | 0.31 | 0.35 | 112475 | NULL | NULL | added |
+------------+---------------+---------+---------+--------+----------+-----------+-----------+-----------------+-----------+
stocks/master> select (select distinct to_date from dolt_diff_ohlcv where to_commit = '99tckrp62d59f6vli48oh5ohsutg4gus') as to_date, (select distinct from_date from dolt_diff_ohlcv where to_commit = '99tckrp62d59f6vli48oh5ohsutg4gus') as from_date, (select distinct diff_type from dolt_diff_ohlcv where to_commit = '99tckrp62d59f6vli48oh5ohsutg4gus') as diff_type;
+------------+-----------+-----------+
| to_date | from_date | diff_type |
+------------+-----------+-----------+
| 2024-04-08 | NULL | added |
+------------+-----------+-----------+
1 row in set (0.10 sec)Because Dolt is storing the rows of the table in a clustered-index Prolly-tree ordered by the primary key, all of these new rows get inserted into one contiguous range of leaf chunks which starts at the end of the leaf chunks of the previous version of the tree. The end result looks something like this edit from the Prolly-tree blog:
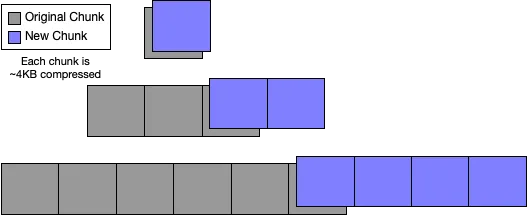
Overall we get very nice structural sharing.
A seemingly reasonable index#
Given its schema, the ohlcv table’s schema can quickly get us all the ohlcv data for a given date.
stocks/master> select date, max(open), min(open) from ohlcv where date = '2024-04-08' group by (date);
+------------+-----------+-----------+
| date | max(open) | min(open) |
+------------+-----------+-----------+
| 2024-04-08 | 7928.00 | 0.00 |
+------------+-----------+-----------+
1 row in set (0.05 sec)What if we want to process all the entries associated with a given ticker?
stocks/master> select act_symbol, max(open), min(open) from ohlcv where act_symbol = 'GLD' group by (act_symbol);
+------------+-----------+-----------+
| act_symbol | max(open) | min(open) |
+------------+-----------+-----------+
| GLD | 215.98 | 111.46 |
+------------+-----------+-----------+
1 row in set (5.41 sec)Ouch—it took over 100 times as long. What happened? The act_symbol = 'GLD' clause actually has higher specificity than the date = '2024-04-08' clause:
stocks/master> select count(*) from ohlcv where act_symbol = 'GLD';
+----------+
| count(*) |
+----------+
| 1570 |
+----------+
1 row in set (4.14 sec)
stocks/master> select count(*) from ohlcv where date = '2024-04-08';
+----------+
| count(*) |
+----------+
| 9524 |
+----------+
1 row in set (0.03 sec)However, the query plans for these two queries are somewhat different.
stocks/master> explain select date, max(open), min(open) from ohlcv where date = '2024-04-08' group by (date);
+--------------------------------------------------------------------------------------------------------+
| plan |
+--------------------------------------------------------------------------------------------------------+
| Project |
| ├─ columns: [ohlcv.date, max(ohlcv.open), min(ohlcv.open)] |
| └─ GroupBy |
| ├─ SelectedExprs(MAX(ohlcv.open), MIN(ohlcv.open), ohlcv.date) |
| ├─ Grouping(ohlcv.date) |
| └─ Filter |
| ├─ (ohlcv.date = '2024-04-08') |
| └─ IndexedTableAccess(ohlcv) |
| ├─ index: [ohlcv.date,ohlcv.act_symbol] |
| ├─ filters: [{[2024-04-08 00:00:00 +0000 UTC, 2024-04-08 00:00:00 +0000 UTC], [NULL, ∞)}] |
| └─ columns: [date open] |
+--------------------------------------------------------------------------------------------------------+
11 rows in set (0.00 sec)
stocks/master> explain select act_symbol, max(open), min(open) from ohlcv where act_symbol = 'GLD' group by (act_symbol);
+---------------------------------------------------------------------------+
| plan |
+---------------------------------------------------------------------------+
| Project |
| ├─ columns: [ohlcv.act_symbol, max(ohlcv.open), min(ohlcv.open)] |
| └─ GroupBy |
| ├─ SelectedExprs(MAX(ohlcv.open), MIN(ohlcv.open), ohlcv.act_symbol) |
| ├─ Grouping(ohlcv.act_symbol) |
| └─ Filter |
| ├─ (ohlcv.act_symbol = 'GLD') |
| └─ Table |
| ├─ name: ohlcv |
| └─ columns: [act_symbol open] |
+---------------------------------------------------------------------------+
10 rows in set (0.00 sec)For the first query, the query plan uses a filtered indexed table access to only scan the matching rows in the table. Then end result is that Dolt only scans the matching rows in the Prolly-tree, and so only has to look at 9,542 rows. For the act_symbol = 'GLD' clause, Dolt has no index to use. Instead, it needs to scan the entire table and it ends up scanning through all 13 million+ rows in order to find the 1,570 that are needed for the query.
A seemingly easy way to fix this is to add an index. The simplest index is to just index by act_symbol as well:
stocks/master> alter table ohlcv add index (act_symbol);And indeed, in this case, where the data set reasonably fits in cache and the major overhead of the previous query was CPU, that is enough to get us back to essentially parity with the date-based query:
stocks/master*> explain select act_symbol, max(open), min(open) from ohlcv where act_symbol = 'GLD' group by (act_symbol);
+---------------------------------------------------------------------------+
| plan |
+---------------------------------------------------------------------------+
| Project |
| ├─ columns: [ohlcv.act_symbol, max(ohlcv.open), min(ohlcv.open)] |
| └─ GroupBy |
| ├─ SelectedExprs(MAX(ohlcv.open), MIN(ohlcv.open), ohlcv.act_symbol) |
| ├─ Grouping(ohlcv.act_symbol) |
| └─ Filter |
| ├─ (ohlcv.act_symbol = 'GLD') |
| └─ IndexedTableAccess(ohlcv) |
| ├─ index: [ohlcv.act_symbol] |
| ├─ filters: [{[GLD, GLD]}] |
| └─ columns: [act_symbol open] |
+---------------------------------------------------------------------------+
11 rows in set (0.00 sec)
stocks/master*> select act_symbol, max(open), min(open) from ohlcv where act_symbol = 'GLD' group by (act_symbol);
+------------+-----------+-----------+
| act_symbol | max(open) | min(open) |
+------------+-----------+-----------+
| GLD | 215.98 | 111.46 |
+------------+-----------+-----------+
1 row in set (0.04 sec)And it seems like this would be a common operation that people working with the stocks database would want to perform. So, why doesn’t this database already ship with this index?
The structure of a Dolt index#
Dolt secondary indexes are stored in Prolly-trees, the same as the primary clustered index of a keyed SQL table. In the case of a primary key index, the format for the Prolly-tree entry is Key([ordered, primary, key, columns]), Value([all, non-, primary, key, columns]). In the case of a secondary key index, the KV-pair that gets inserted into the Prolly-tree is actually: Key([ordered, secondary, key, columns, all, remaining, primary, key, columns]), Value([]).
When Dolt resolves a queried row through the secondary index, it gets back the index entry and, if it needs data dependencies that are not already in the index tuple, looks up the primary key tuple in the original clustered index for the table. That means that, for act_symbol = 'GLD', for example, our created secondary index will have the following entries:
+-----------------------+-----------+
| Key | Value |
+-----------------------+-----------+
| ('GLD', '2018-01-16') | |
| ('GLD', '2018-01-17') | |
| ('GLD', '2018-01-18') | |
| ('GLD', '2018-01-19') | |
| ('GLD', '2018-01-22') | |
| ('GLD', '2018-01-23') | |
| ('GLD', '2018-01-24') | |
| ('GLD', '2018-01-25') | |
| ('GLD', '2018-01-26') | |
| ('GLD', '2018-01-29') | |
| ('GLD', '2018-01-30') | |
| ('GLD', '2018-01-31') | |
| .... | |
+-----------------------+-----------+By itself, this is entirely reasonable. But consider what happens to this index for our insert pattern. Every trading day, we have little over 9,500 entries to insert into this secondary index. The entries look like:
+-----------------------+-----------+
| Key | Value |
+-----------------------+-----------+
| ('A', '2024-04-08') | |
| ('AA', '2024-04-08') | |
| ('AACG', '2024-04-08')| |
| ('AADR', '2024-04-08')| |
| ('AAL', '2024-04-08') | |
| ('AAMC', '2024-04-08')| |
| ('AAME', '2024-04-08')| |
| ('AAN', '2024-04-08') | |
| ('AAOI', '2024-04-08')| |
| ('AAON', '2024-04-08')| |
| ('AAP', '2024-04-08') | |
| ('AAPL', '2024-04-08')| |
| .... | |
+-----------------------+-----------+Each one of those entries is being inserted into the middle of an existing run of entries in the existing leaf nodes. ('A', '2024-04-08') is going after ('A', '2024-04-07') and before ('AA', '2018-01-16'); ('AA', '2024-04-08') is going after ('AA', '2024-04-07') and before ('AACG', '2018-01-16'); etc.
The end result is that, at scale, the index edit and its effect on the resulting Prolly-tree looks a lot more like an edit that makes a small mutation to 9,500+ leaf nodes, rather than an edit that inserts a large-ish contiguous range of new records:
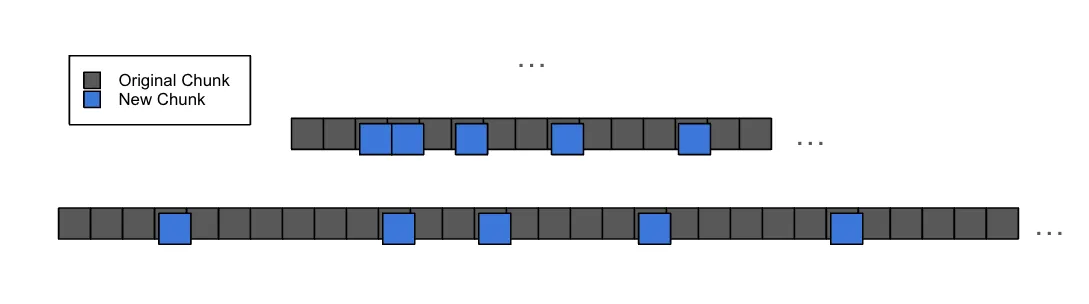
In that example graphic, each “New Chunk” only has a little bit of new information. The new index entry is there, but that’s only one of a many entries that are on that leaf chunk. Most of the contents of the new chunk are completely duplicated in the previous chunk, but Dolt’s storage format and approach to structural sharing means that both copies are kept around and referenced by separate Merkle DAGs representing the database at different points in time.
And the same thing happens, day after day, with each data import. The end result is that a database with the same inserted data that has this index, grows much faster every day than the same database which does not have the index.
Measuring the overall impact#
Let’s make it concrete and measure exactly how much storage the revisions of the underlying ohlcv table use. I took the existing stocks database and ran some experiments for the growth of the table in four different scenarios:
-
The raw data, stored in Dolt. On the first day of data, how big is the table stored in Dolt? For each new day, how big is it? In today’s database, how big is it?
-
The historical data, stored in Dolt. For each day, a new commit is made. How big is the database for all the historical versions of the data, compared to just storing the current data?
-
The raw data + the index, stored in Dolt. On the first day of data, how big is the table and the index stored in Dolt. For each new day, how big is it? In today’s database, how big is it?
-
The historical data + the index, stored in Dolt. For each day, a new commit is made. How big is the database for all historical versions of the data, including storing the historical versions of the index on
(act_symbol)?
First, a log-scale graph of the total size of the database, as a function of the number of days of data is contains:
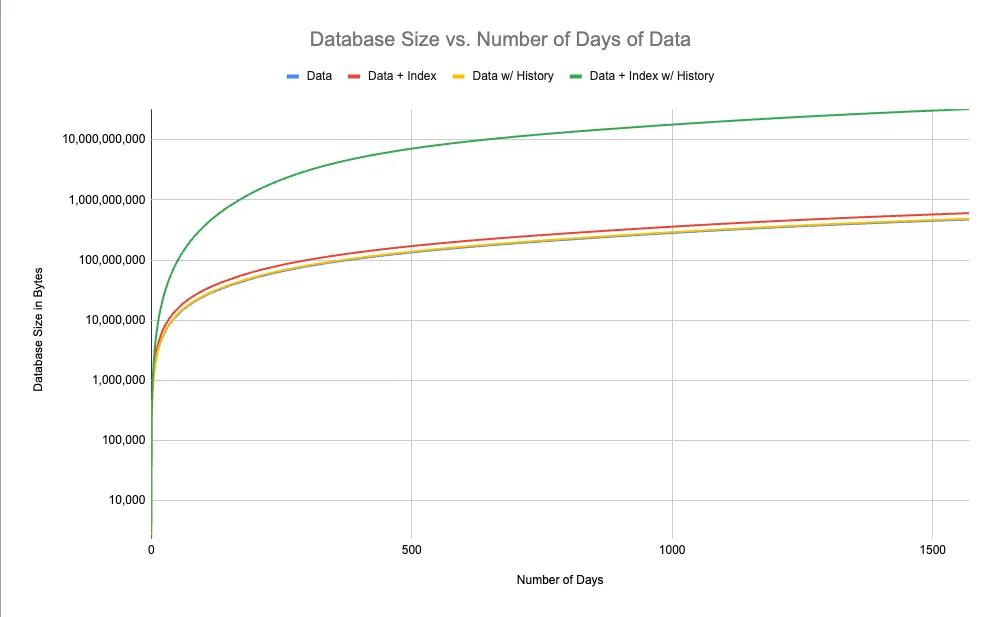
Storing the history of the database takes only slightly more space than storing the database itself. And the size overhead for storing the index is also reasonable. Overall, these three scenarios end with 1,570 days worth data at 487MB, 474MB and 604MB respectively. But as soon as you add history with the index, the size of the complete database explodes. We have to make the Y-axis log-scale to even make the graph look reasonable, and the highest datapoint on the Y-axis scale is at 10GB. Indeed, the full database with 1,570 days of data, all of which have their own materialized index, is over 32GB.
Also instructive is a graph of how fast the database is growing each day:

Here we have a log scale again. In all four scenarios, after the database reaches a certain size, the database grows by approximately a constant factor every day. This is as we would expect, because we are inserting about the same amount of data every day. But, for the data, data + index and data w/ history use cases, the amount by which it grows each day is ~330KB, ~345KB and ~425KB a day. While for the data + index w/ history use case, it grows by a whooping 26MB every day.
Conclusion and future work#
So we can see very starkly the way that schema design and mutation patterns can impact Dolt’s structural sharing and the resulting size overhead associated with history storage. Here at DoltHub, we’re hard at work on lots of features that we hope will be useful for people storing their database history in Dolt in the future.
We’ve recently landed shallow clone functionality, which allows someone who wants to work with something like the stocks database to only pull the tip — if the stocks database did store the full history with the index, pulling the tip would still only require ~600MB. Each day you would be able to keep up by fetching the new 26MB.
But unfortunately, your local copy would still be growing more quickly than maybe necessary, and 26MB is still a lot more than 350KB.
We’re currently working on new ways of Dolt to store archived chunks, so that chunks with high similarity to each other can take up less space on disk and in transit, at the cost of higher CPU utilization when you do need to read those chunks.
We also hope to implement easy-to-use forms of history truncation and tiered storage, so that older history could be easily moved off-host to something like a Dolt remote, and only pulled if it was needed.
For the example presented, the insert patterns on the underlying table schema work really nicely with Dolt’s model of structural sharing, and its a secondary index that causes potentially surprising space utilization overhead. We’re still exploring the design space here, but fundamentally, secondary indexes are always redundant information for the data that’s actually stored in the database. The contents of a secondary index currently go into the content address of the database value in Dolt, but it’s possible that they shouldn’t and that they won’t in the future. In reality, secondary indexes appear in databases as a tradeoff between the write overhead associated with maintaining the index and the speedup given for typical queries that access the index.
For Dolt, which is storing the entire history of the database and allowing all of it to be queried at any given time, the tradeoffs here are potentially different than a traditional OLTP database. For example, as very nascent ideas that may see the light of day one day:
-
It’s possible that maintaining secondary indexes only on branch HEADs could make sense. You might need to materialize them when you create new branch HEADs. They query engine could potentially forego the index access for historical queries, or materialize them on demand, or attempt to accelerate certain types of historical histories by using the index at HEAD + the diff of the primary table.
-
Or, potentially you would materialize the secondary indexes not only at HEAD, but periodically throughout the commit graph, potentially with decreasing frequency as the graph got deeper, with the same kinds of query techniques of overlaying the diff from the primary table being available.
-
Or, potentially you don’t want to materialize the secondary index per se at a commit, but instead you want to materialize a union of the secondary index as it exists for every revision of the primary relation in any version of the table which that index covers. And that version of the secondary index becomes the version that gets queried for all of the covered commits, but every retrieved tuple needs to be further filtered by a lookup against the primary table.
Anyway, those are all very speculative, but it’s an exciting space and we’re excited to explore it in the future.
If you have any further ideas or further questions about Dolt, please don’t hesitate to drop by our Discord and reach out to me. I would love to chat further!