
Introduction#
We’re writing Dolt, the world’s first version controlled SQL database. Dolt is based on the MySQL dialect and wire protocol, and built to be a drop-in replacement for any MySQL application. But many potential customers expressed their preference for a PostgreSQL variant, and we listened. Earlier this month we announced our initial release of DoltgreSQL, which is the PostgreSQL version of Dolt, with the goal of eventually being a drop-in replacement for any PostgreSQL application.

But these are early days, and Doltgres is still under heavy
active development. Today we’re excited to announce a major milestone: getting sqllogictest, a
suite of 5.7 million SQL queries that evaluate the correctness of a query engine, running against
DoltgreSQL. Let’s look at what it took to get there and what the results mean.
What is sqllogictest?#
sqllogictest is an exhaustive set of query engine tests developed by SQLite3 to test that engine. We forked these tests and developed our own test runner that works against Dolt, as well as the in-memory database implementation of our query engine, go-mysql-server.
The genius of sqllogictest is that it leverages other existing database engines (like PostgreSQL
and MySQL) to evaluate the correctness of new ones. The author wrote a framework that generates
millions of randomly generated queries and then ran them all against these (presumably) correct
databases to get a baseline for the test. Because they’re randomly generated, they exercise a much
larger surface area of SQL language functionality than hand-written tests would. Here’s an example
of the kind of query they run:
SELECT pk FROM tab1 WHERE ((((col3 > 0 AND ((col0 >= 7 AND col0 <= 2)
AND (col0 <= 4 OR col4 < 5.82 OR col3 > 7) AND col0 >= 4) AND col0 <
0) AND ((col1 > 7.76))))) OR ((col1 > 7.23 OR (col0 <= 3) OR (col4 >=
2.72 OR col1 >= 8.63) OR (col3 >= 3 AND col3 <= 4)) AND ((col0 < 2 AND
col3 < 0 AND (col1 < 6.30 AND col4 >= 7.2)) AND (((col3 < 5 AND col4
IN (SELECT col1 FROM tab1 WHERE ((col3 >= 7 AND col3 <= 6) OR col0 < 0
OR col1 >= 0.64 OR col3 <= 7 AND (col3 >= 8) AND ((col3 <= 6) AND
((col0 = 1 AND col3 IS NULL)) OR col0 > 7 OR col3 IN (8,1,7,4) OR col3
> 7 AND col3 >= 5 AND (col3 < 0) OR col0 > 3 AND col4 > 1.21 AND col0
< 4 OR ((col4 > 9.30)) AND ((col3 >= 5 AND col3 <= 7))) AND col0 <= 5
OR ((col0 >= 1 AND col4 IS NULL AND col0 > 5 AND (col0 < 3) OR col4 <=
8.86 AND (col3 > 0) AND col3 = 8)) OR col3 >= 1 OR (col3 < 4 OR (col3
= 7 OR (col1 >= 4.84 AND col1 <= 5.61)) OR col3 >= 5 AND ((col3 < 4)
AND ((col3 > 9)) OR (col0 < 3) AND (((col0 IS NULL))) AND (col0 < 4))
AND ((col4 IN (0.79)))) OR (col4 = 6.26 AND col1 >= 5.64) OR col1 IS
NULL AND col0 < 1)))) AND ((((col3 < 9) OR ((col0 IS NULL) OR (((col1
>= 8.40 AND col1 <= 0.30) AND col3 IS NULL OR (col0 <= 7 OR ((col3 >
4))) AND col0 = 6)) OR col3 < 6 AND (((((((col1 > 4.8)) OR col0 < 9 OR
(col3 = 1))) AND col4 >= 4.12))) OR (((col1 > 1.58 AND col0 < 7))) AND
(col1 < 8.60) AND ((col0 > 1 OR col0 > 1 AND ((col3 >= 2 AND col3 <=
0) AND col0 <= 0) OR ((col0 >= 8)) AND (((col3 >= 8 AND col3 <= 8) OR
col0 > 4 OR col3 = 8)) AND col1 > 5.10) AND ((col0 < 7 OR (col0 < 6 OR
(col3 < 0 OR col4 >= 9.51 AND (col3 IS NULL AND col1 < 9.41 AND col1 =
1.9 AND col0 > 1 AND col3 < 9 OR (col4 IS NULL) OR col1 = 0.5 AND
(col0 >= 3) OR col4 = 9.25 OR ((col1 > 0.26)) AND col4 < 8.25 AND
(col0 >= 2) AND col3 IS NULL AND (col1 > 3.52) OR (((col4 < 7.24)) AND
col1 IS NULL) OR col0 > 3) AND col3 >= 4 AND col4 >= 2.5 AND col0 >= 0
OR (col3 > 3 AND col3 >= 3) AND col0 = 1 OR col1 <= 8.9 AND col1 >
9.66 OR (col3 > 9) AND col0 > 0 AND col3 >= 0 AND ((col4 > 8.39))))
AND (col1 IS NULL)))))) AND col1 <= 2.0 OR col4 < 1.8 AND (col4 = 6.59
AND col3 IN (3,9,0))))) OR col4 <= 4.25 OR ((col3 = 5))) OR (((col0 >
0)) AND col0 > 6 AND (col4 >= 6.56)))We’ve been running these against Dolt for years, and slowly climbing in our correctness metric.
- In 2019, we achieved one 9 of correctness
- In 2021, we hit two 9’s
- In September we got to three 9’s.
- Last month, we finally achieved four 9’s
And now we’re excited to share our initial result for DoltgreSQL: one 7 of correctness, or 70% of the tests passing.
That’s not as bad as it sounds. Let’s discuss.
DoltgreSQL’s architecture#
DoltgreSQL is built on top of Dolt, which uses go-mysql-server as its query engine. To get the product up and running quickly, we decided to use an off-the-shelf Postgres query parser, then convert the AST produced by that parser to the one used by go-mysql-server. This diagram explains the flow of query execution in Dolt (top flow) and DoltgreSQL (bottom flow):
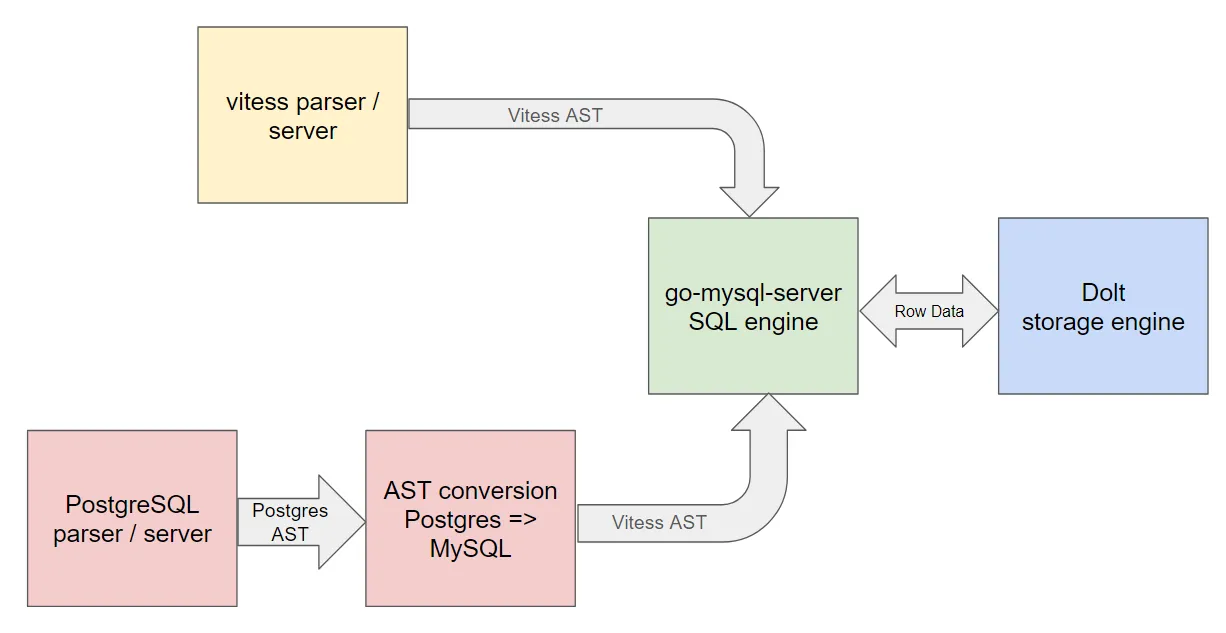
There are three open-source packages involved in implementing the original Dolt query engine, color coded in yellow (vitess), green (go-mysql-server), and blue (Dolt itself). To implement DoltgreSQL, we implemented a translation layer that turns PostgreSQL queries into a form that can be executed by the existing engine. This involves two major parts:
- Decode Postgres wire messages in a server and respond to clients appropriately with encoded PostgreSQL messages
- Translate the AST produced by the the Postgres parser to the one produced by the MySQL parser.
There’s also a third part: the testing harness itself must accurately respond to our server’s messages to feed into the testing framework. If we do all that accurately, everything should just work. Since we know that Dolt classic is 99.99% accurate on this benchmark, the 70% correctness metric effectively measures how accurately the two red boxes do their job, or finds missing features that PostgreSQL has but not MySQL.
What we’re getting wrong right now#
70% isn’t actually too bad: it primarily means that we’ve incompletely implemented parts of the translation layer, either in schema definition (which causes many additional statements to fail), or we messed something up in harness or message decoding. Here’s a typical error:
CREATE TABLE t7n(a TEXT UNIQUE) not ok: Unexpected error* ERROR: blob/text column 'a' used in key specification without a key length (errno 1105) (sqlstate HY000) (SQLSTATE* XX000)This error reveals a missing feature: MySQL requires a prefix length on TEXT or BLOB indexes,
but PostgreSQL and MariaDB do not. A Dolt customer just discovered the same issue and filed a
feature request for it. This wouldn’t impact you
unless your schema makes use of this feature, but it makes a lot of following tests that depend on
that table fail.
Here’s an example of a test where we’re getting something wrong more subtly, probably somewhere in the translation process:
SELECT 'b' IN (SELECT * FROM t8) not ok: Incorrect result at position 0. Expected 1, got 0Finally, the test harness itself needs some more attention. Here’s an example where we’re producing a false negative because the harness isn’t fully implemented for all the Postgres wire types:
SELECT ALL * FROM tab1 WHERE + + 44 IS NULL not ok: Unexpected error Unhandled type FLOAT8We expect to make very rapid progress on these problems, and get to one 9 of accuracy by end of year, and two 9’s a month after that.
PostgreSQL’s extended wire format#
To even get to this point required doing a better job handling PostgreSQL’s wire protocol, which is substantially more involved than MySQL’s. In particular, it’s normal for a Postgres client to send multiple messages in a single packet when making a query. Here’s what the popular pgx Go library does when issuing a query:
func (pgConn *PgConn) ExecPrepared(ctx context.Context, stmtName string, paramValues [][]byte, paramFormats []int16, resultFormats []int16) *ResultReader {
result := pgConn.execExtendedPrefix(ctx, paramValues)
if result.closed {
return result
}
buf := pgConn.wbuf
buf = (&pgproto3.Bind{PreparedStatement: stmtName, ParameterFormatCodes: paramFormats, Parameters: paramValues, ResultFormatCodes: resultFormats}).Encode(buf)
pgConn.execExtendedSuffix(buf, result)
return result
}
func (pgConn *PgConn) execExtendedSuffix(buf []byte, result *ResultReader) {
buf = (&pgproto3.Describe{ObjectType: 'P'}).Encode(buf)
buf = (&pgproto3.Execute{}).Encode(buf)
buf = (&pgproto3.Sync{}).Encode(buf)
n, err := pgConn.conn.Write(buf)
if err != nil {
pgConn.asyncClose()
result.concludeCommand(nil, &writeError{err: err, safeToRetry: n == 0})
pgConn.contextWatcher.Unwatch()
result.closed = true
pgConn.unlock()
return
}
result.readUntilRowDescription()
}So to send a single query, a Postgres client sends three packets with five total messages:
Parse, which readies a query string for executionBind, which binds any input parameters providedDescribe, which returns the result schemaExecute, which executes the bound statement and spools result rowsSync, which is a handshake message telling the server we’re done with this batch of messages.
Our first implementation knew to expect multiple messages in a single wire transmission, but was
limited to writing them into a 2k fixed buffer to parse them. This was good enough for an initial
alpha release, but it turns out that sqllogictest has many queries longer than 2k, which simply
broke all such tests. Handling arbitrary message lengths was simple enough in principle, but tricky
to get all the details right. It looks like this:
func Receive(conn net.Conn) (Message, error) {
header := headerBuffers.Get().([]byte)
defer headerBuffers.Put(header)
n, err := conn.Read(header)
if err != nil {
return nil, err
}
if n < headerSize {
return nil, errors.New("received message header is too short")
}
message, ok := allMessageHeaders[header[0]]
if !ok {
return nil, fmt.Errorf("received message header is not recognized: %v", header[0])
}
messageLen := int(binary.BigEndian.Uint32(header[1:])) - 4
var msgBuffer []byte
if messageLen > 0 {
read := 0
buffer := iobufpool.Get(messageLen + headerSize)
msgBuffer = (*buffer)[:headerSize+messageLen]
defer iobufpool.Put(buffer)
for read < messageLen {
// TODO: this timeout is arbitrary, and should be configurable
err := conn.SetReadDeadline(time.Now().Add(time.Minute))
if err != nil {
return nil, err
}
n, err = conn.Read(msgBuffer[headerSize+read:])
if err != nil {
return nil, err
}
read += n
}
copy(msgBuffer[:headerSize], header)
} else {
msgBuffer = header
}
db := newDecodeBuffer(msgBuffer)
return receiveFromBuffer(db, message)
}Each PostgreSQL message begins with a message byte naming what message is encoded, followed by a
4-byte length. So we have to read from the connection until we receive that many bytes before
attempting to decode a message from it. There may be additional data waiting on the connection, or
this could be the last message the client sent, which means it’s very important to read only the
expected amount of data (because conn.Read() blocks if there’s nothing buffered).
The behavior for error handling is also very precise, documented in the Postgres docs like so:
The purpose of Sync is to provide a resynchronization point for error recovery. When an error is detected while processing any extended-query message, the backend issues ErrorResponse, then reads and discards messages until a Sync is reached, then issues ReadyForQuery and returns to normal message processing.
Our initial draft was skipping this crucial “skip all messages until Sync” behavior when
encountering an error, leading to some very confusing behavior where messages waiting in the
connection buffer were being processed and sent to the client inappropriately, generating seemingly
out-of-sequence results. Given how many errors we encountered in the test run, fixing that buggy
behavior was necessary to get to our 70% correctness milestone.
Conclusion#
We’re early on this journey, and we still have a long way to go to get
DoltgreSQL to production-ready quality. But it’s already
good enough for you to start playing with it and experimenting with how you could use it in your
applications. All the Dolt version-control procedures like CALL DOLT_COMMIT(...) and the
version-control system_tables like SELECT * FROM dolt_diff work just fine. If you’re curious, it’s
not too early to try it out. We’d love to get more feedback from early adopters as we prioritize how
we build out missing features.
Have questions about Dolt or DoltgreSQL? Join us on Discord to talk to our engineering team and meet other Dolt users.