
Dolt is the world’s first version controlled SQL database. Dolt is MySQL-compatible so all the tools you use with MySQL work the same way with Dolt, including Knex.js (which is surprisingly pronounced /k’nex/ instead of /nex/ - Tim would like credit for being right for once).
Knex.js is a “batteries included” SQL query builder for many SQL databases, including MySQL. It features both traditional node style callbacks as well as a promise interface for cleaner async flow control, a stream interface, full-featured query and schema builders, transaction support (with savepoints), connection pooling and standardized responses between different query clients and dialects.
We have a few customers that use Knex.js in their applications and Dolt has received a few Knex-related GitHub issues over the years. This blog is inspired by Tim’s Getting Started with SQLAlchemy and Dolt blog and will also walk through the Getting Started example from the Dolt README, except in Javascript using Knex.js and Node.

TL;DR#
If you don’t want to run through this whole tutorial and just want the Javascript
code, it is available
in this GitHub repository. You can come
with any Dolt SQL server and specify the connection information in a .env file in the
repository root.
You must have Git and
Node installed to run the code. This example uses a
connection to a Hosted Dolt database, but the code will also
work if you run a local dolt sql-server. If you are using
a local dolt sql-server instead of Hosted Dolt you must also install
Dolt.
You can find directions for running the code in the repository README. But essentially all you need to do is:
% npm install
% node index.jsThis script will reset the database to its original state every time the script runs. The code shows off table creation, Dolt commits, reading Dolt system tables, rollback using Dolt reset, branching, and merging all using Knex.js.
Create a Hosted Dolt deployment#
Unlike the SQLAlchemy example, this example will connect to a Dolt database that is cloud-hosted using our Hosted Dolt product.
First, go to the Create Deployment page.
Choose whatever instance you want (we’re using our $50 trial instance) and click Create Deployment. We’re adding one read replica for a later
example that utilizes read
replicas.
Once the deployment has started, you’ll see the connectivity information in the Database tab.
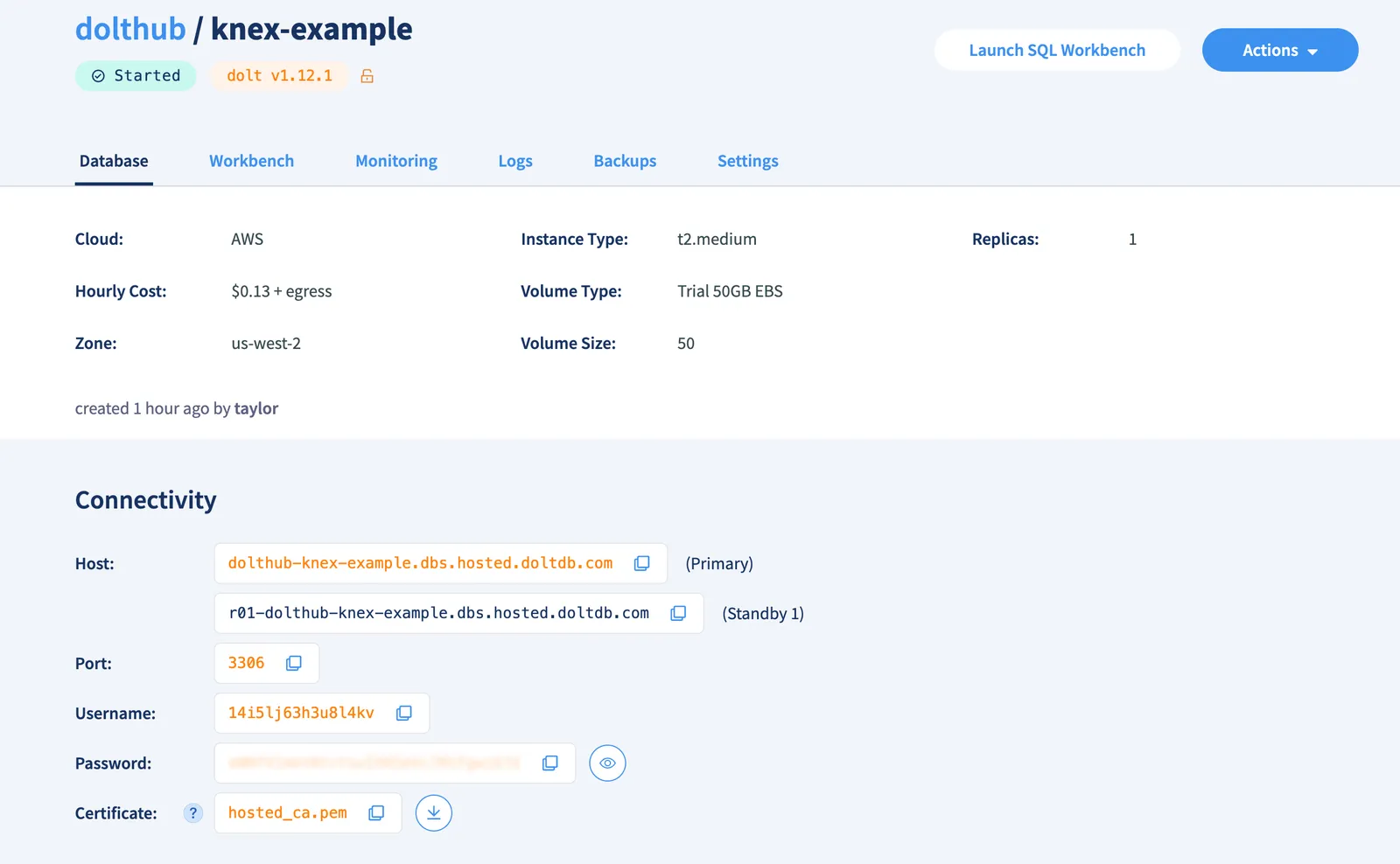
We then add this information to a .env file in the root of the example code repository.
DB_HOST="dolthub-knex-example.dbs.hosted.doltdb.com"
DB_PORT=3306
DB_USER="14i5lj63h3u8l4kv"
DB_PASSWORD="xxxxxxxxxxxxxxxxxxx"
DB_NAME="knextest"
DB_SSL_PATH="/hosted_ca.pem"You will also need to download the Certificate and add it to the root of the repository.
The file name should match the DB_SSL_PATH env.
As you can see, this configuration also includes a database named knextest. We can
create this database from the Hosted Dolt UI by checking Enable workbench writes from
the Workbench tab and clicking Create database.
Connect to the Hosted database#
Now time to get into the Javascript. You can follow along with the code here. In the following sections we’ll walk through the Javascript code and explain what it does and why.
The knex module itself is a function which takes a configuration object for Knex,
accepting a few parameters. The client parameter is required and determines which client
adapter will be used with the library. Dolt is MySQL-compatible so we can use either the
“mysql” or “mysql2” client.
We use dotenv to load the environment variables
we set earlier in the .env file. We will use these to create a connection pool to our
Hosted database:
require("dotenv").config();
const knex = require("knex");
const fs = require("fs");
const poolConfig = { min: 0, max: 7 };
const config = {
host: process.env.DB_HOST,
port: process.env.DB_PORT,
user: process.env.DB_USER,
password: process.env.DB_PASSWORD,
database: process.env.DB_NAME,
ssl: process.env.DB_SSL_PATH
? { ca: fs.readFileSync(__dirname + process.env.DB_SSL_PATH) }
: false,
};
const db = knex({
client: "mysql2",
connection: config,
pool: poolConfig,
});Once we’ve created our Knex instance, we can start running queries. We’ll start with a
function that wraps the Dolt function
active_branch().
printActiveBranch();
async function printActiveBranch() {
const branch = await db.raw(`SELECT ACTIVE_BRANCH()`);
console.log("Active branch:", branch[0][0]["ACTIVE_BRANCH()"]);
}This prints:
Active branch: mainNotice that this function uses async/await.
Promises are the preferred way of
dealing with queries in Knex, as they allow you to return values from a fulfillment
handler, which in turn become the value of the promise. The main benefit of promises are
the ability to catch thrown errors without crashing the Node app, making your code behave
like a .try / .catch / .finally in synchronous code.
Create tables#
Now let’s create some tables. In this example our database will have three tables:
employees, teams, and employees_teams. We can utilize Knex’s schema
builder method createTable,
which creates a new table on the database with a callback function to modify the table’s
structure.
setupDatabase();
async function setupDatabase() {
await db.schema.createTable("employees", table => {
table.integer("id").primary();
table.string("last_name");
table.string("first_name");
});
await db.schema.createTable("teams", table => {
table.integer("id").primary();
table.string("name");
});
await db.schema.createTable("employees_teams", table => {
table.integer("employee_id").references("id").inTable("employees");
table.integer("team_id").references("id").inTable("teams");
table.primary(["employee_id", "team_id"]);
});
}Dolt supports foreign keys, secondary indexes, triggers, check constraints, and stored procedures. It’s a modern, feature-rich SQL database.
Then to examine our changes, we run a SHOW TABLES query and print the results.
printTables();
async function printTables() {
const res = await db.raw("SHOW TABLES");
const tables = res[0].map(table => table[`Tables_in_${database}`]).join(", ");
console.log("Tables in database:", tables);
}This outputs:
Tables in database: employees, employees_teams, teamsThe employees, teams, and employees_teams tables have been created.
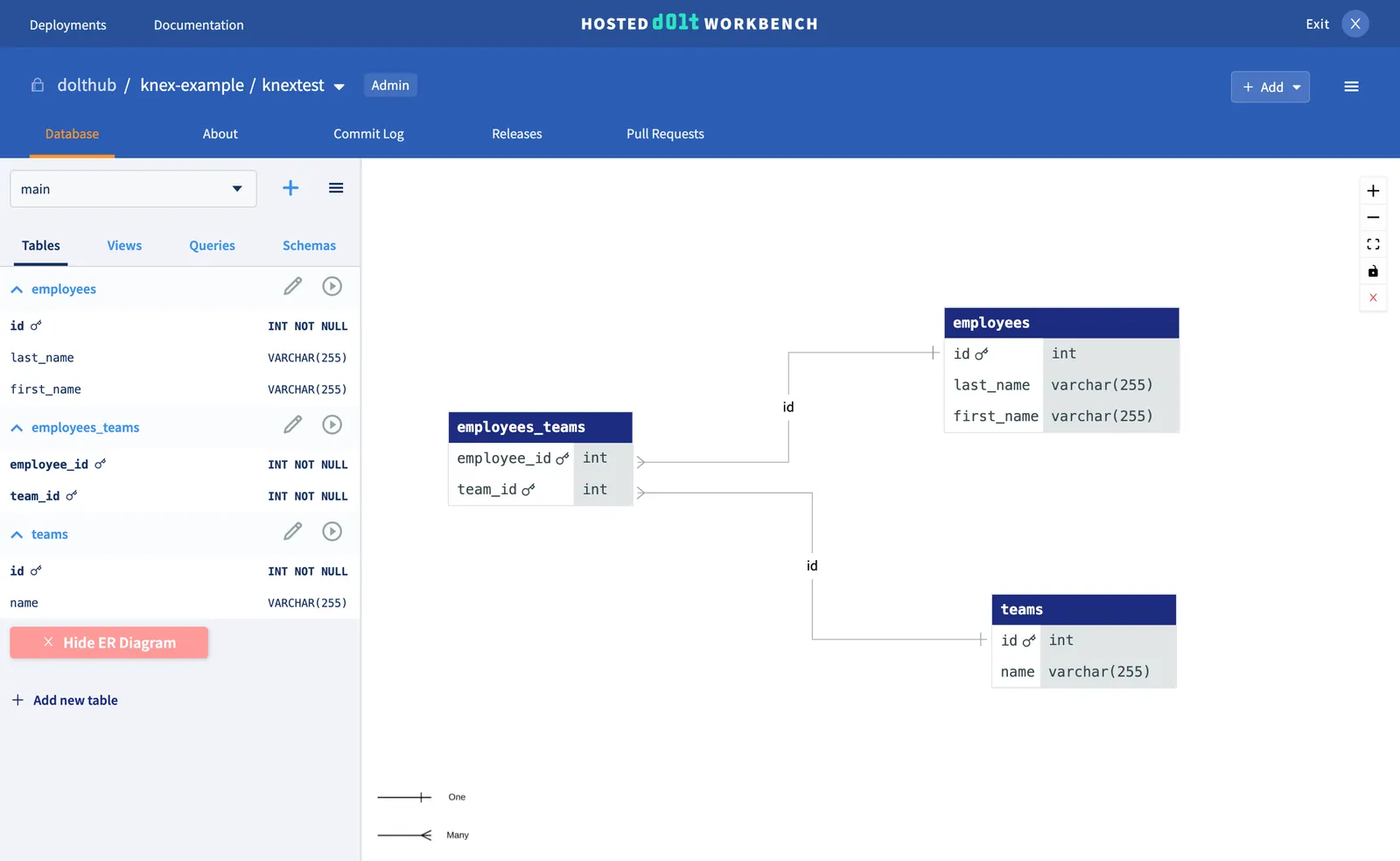
One of the many benefits of using Hosted Dolt is that it comes with a SQL Workbench where
you can view your data and changes across revisions. When you click on Launch SQL Workbench from the top right of your deployment page, you’ll see the tables we just
created, as well as an ER diagram that illustrates table relations.
Make a Dolt commit#
Next, we’ll Dolt commit our new tables. Both Git and SQL have the concept of commits and since Dolt is a combination of Git and SQL it must support both. This can be confusing. A Dolt commit makes an entry in the commit log for versioning purposes. A SQL transaction commit is required to persist your database writes to disk so other connections can see them.
In order to make a Dolt commit, we use the
DOLT_COMMIT()
procedure. Dolt exposes version control write operations as
procedures.
The naming of these procedures follows the Git command line standard. git add on the Git
command line becomes dolt add on the Dolt command line becomes DOLT_ADD() as a Dolt
SQL procedure. Arguments mimic Git as well. If you know Git, you already know how to use
Dolt.
Similar to SQLAlchemy, Knex.js doesn’t have a query builder for procedures. We have to use
a raw SQL statement using Knex’s raw() method. For this method, you can specify a commit
author and message, which are passed as arguments into the Dolt procedure. Like Git, Dolt
has a staging area, so we include a -A option to add all tables before making a commit.
The resulting code looks like this:
doltCommit("Taylor <taylor@dolthub.com>", "Created tables");
async function doltCommit(author, msg) {
const res = await db.raw(`CALL DOLT_COMMIT('--author', ?, '-Am', ?)`, [
author,
msg,
]);
console.log("Created commit:", res[0][0].hash);
}And running it results in the output:
Created commit: 80ks3k1ook712vauvavdnnd6t3q86e3dExamine the commit log#
Let’s examine the Dolt commit log. Dolt version control read operations are exposed in SQL
as custom system
tables or
functions.
The commit log can be read using the
dolt_log
system table, named after the git log and dolt log command line equivalents.
We can use Knex’s query builder select
method to select and order the log
elements we want to print. The resulting code looks like this:
printCommitLog();
async function printCommitLog() {
const res = await db
.select("commit_hash", "committer", "message")
.from("dolt_log")
.orderBy("date", "desc");
console.log("Commit log:");
res.forEach(log =>
console.log(` ${log.commit_hash}: ${log.message} by ${log.committer}`),
);
}And it outputs:
Commit log:
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System AccountYou can also check your commits in the Hosted Workbench:
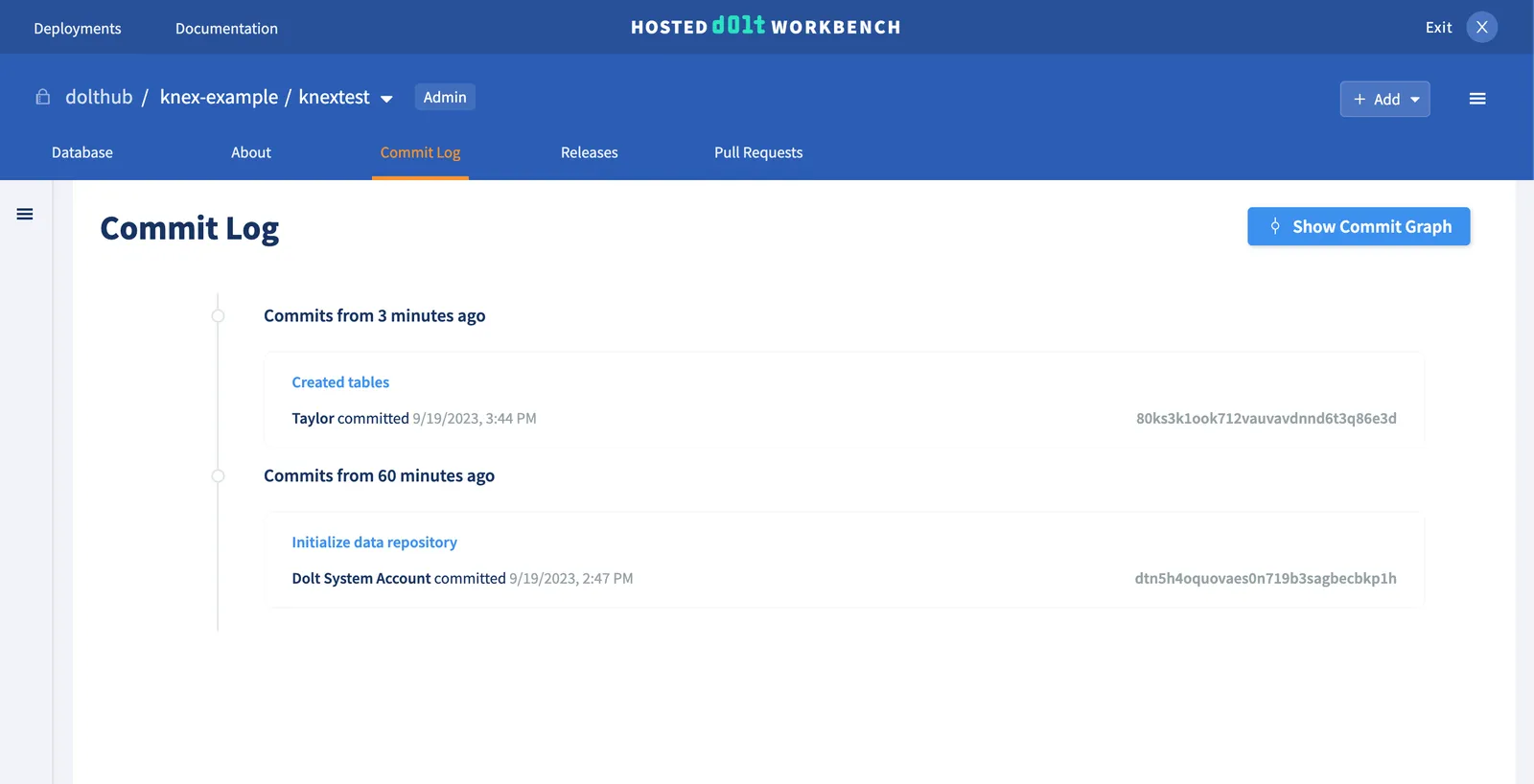
Insert data#
Now we’re going to populate the tables with some data. We can use the insert
method and optionally specify
conflict behavior using
onConflict().merge() or onConflict().ignore().
insertData();
async function insertData() {
await db("employees").insert([
{ id: 0, last_name: "Sehn", first_name: "Tim" },
{ id: 1, last_name: "Hendriks", first_name: "Brian" },
{ id: 2, last_name: "Son", first_name: "Aaron" },
{ id: 3, last_name: "Fitzgerald", first_name: "Brian" },
]);
await db("teams").insert([
{ id: 0, name: "Engineering" },
{ id: 1, name: "Sales" },
]);
await db("employees_teams").insert([
{ employee_id: 0, team_id: 0 },
{ employee_id: 1, team_id: 0 },
{ employee_id: 2, team_id: 0 },
{ employee_id: 0, team_id: 1 },
{ employee_id: 3, team_id: 1 },
]);
}We can make sure our inserts worked by displaying a summary table. Knex.js comes with a query builder that supports many types of complex SQL queries. In this example, we’ll construct a three table join. Later in this example we’ll change the schema, so we’ll account for that in this function.
printSummaryTable();
async function printSummaryTable() {
// Get all employees columns because we change the schema
const colInfo = await db("employees").columnInfo();
const employeeCols = Object.keys(colInfo)
.filter(col => col !== "id")
.map(col => `employees.${col}`);
// Dolt supports up to 12 table joins. Here we do a 3 table join.
const res = await db
.select("teams.name", ...employeeCols)
.from("employees")
.join("employees_teams", "employees.id", "employees_teams.employee_id")
.join("teams", "teams.id", "employees_teams.team_id")
.orderBy("teams.name", "asc");
console.log("Summary:");
res.forEach(row => {
let startDate = "";
if ("start_date" in row) {
if (row.start_date === null) {
startDate = "None";
} else {
const d = new Date(row.start_date);
startDate = d.toDateString();
}
}
console.log(
` ${row.name}: ${row.first_name} ${row.last_name} ${startDate}`,
);
});
}Which results in the following output:
Summary:
Engineering: Tim Sehn
Engineering: Brian Hendriks
Engineering: Aaron Son
Sales: Tim Sehn
Sales: Brian FitzgeraldExamine the status and diff#
You can use the
dolt_status
system table to see what tables changed.
printStatus();
async function printStatus() {
const res = await db.select("*").from("dolt_status");
console.log("Status:");
if (res.length === 0) {
console.log(" No tables modified");
} else {
res.forEach(row => {
console.log(` ${row.table_name}: ${row.status}`);
});
}
}The resulting output looks like:
Status:
employees_teams: modified
employees: modified
teams: modifiedNow that I see which tables changed and how, I want to see what rows changed in a
particular table. Dolt is built from the ground up to provide fast diffs between table
versions even for very large tables. In Dolt, there are a few ways to view diffs: a
dolt_diff_<table> system
table
for each user defined table and a dolt_diff() table
function.
We filter the diff table down to only WORKING changes so we only see changes that aren’t
staged or committed.
printDiff("employees");
async function printDiff(table) {
const res = await db
.select("*")
.from(`dolt_diff_${table}`)
.where("to_commit", "WORKING");
console.log(`Diff for ${table}:`);
console.log(res);
}The resulting output looks like:
Diff for employees:
[
{
to_id: 0,
to_last_name: 'Sehn',
to_first_name: 'Tim',
to_commit: 'WORKING',
to_commit_date: null,
from_id: null,
from_last_name: null,
from_first_name: null,
from_commit: '9iuopee4d7qdkbo8m8vn69j5qq9ee871',
from_commit_date: 2023-09-20T05:59:42.672Z,
diff_type: 'added'
},
{
to_id: 1,
to_last_name: 'Hendriks',
to_first_name: 'Brian',
to_commit: 'WORKING',
to_commit_date: null,
from_id: null,
from_last_name: null,
from_first_name: null,
from_commit: '9iuopee4d7qdkbo8m8vn69j5qq9ee871',
from_commit_date: 2023-09-20T05:59:42.672Z,
diff_type: 'added'
},
{
to_id: 2,
to_last_name: 'Son',
to_first_name: 'Aaron',
to_commit: 'WORKING',
to_commit_date: null,
from_id: null,
from_last_name: null,
from_first_name: null,
from_commit: '9iuopee4d7qdkbo8m8vn69j5qq9ee871',
from_commit_date: 2023-09-20T05:59:42.672Z,
diff_type: 'added'
},
{
to_id: 3,
to_last_name: 'Fitzgerald',
to_first_name: 'Brian',
to_commit: 'WORKING',
to_commit_date: null,
from_id: null,
from_last_name: null,
from_first_name: null,
from_commit: '9iuopee4d7qdkbo8m8vn69j5qq9ee871',
from_commit_date: 2023-09-20T05:59:42.672Z,
diff_type: 'added'
}
]Before we go onto the next section let’s Dolt commit our changes.
await doltCommit("Tim <tim@dolthub.com>", "Inserted data into tables");
await printCommitLog();And you’ll see our new commit in the log:
Created commit: flfiptf13lc7chlvbkikqtss3r02k2se
Commit log:
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System AccountRolling back a mistake#
Dolt has powerful rollback
capabilities. Let’s
imagine I accidentally drop a table. The foreign keys will prevent me from dropping
employees or teams, but employees_teams is not safe from an accident.
dropTable("employees_teams");
async function dropTable(table) {
await db.schema.dropTable(table);
}As we can see from status and SHOW TABLES it is gone.
await printStatus();
await printTables();Status:
employees_teams: deleted
Tables in database: employees, teamsIn a traditional database, this could be disastrous. In Dolt, we can get it back with a
simple call dolt_reset('hard').
This function takes an optional commit. If no commit is specified it resets to the HEAD
commit.
await doltResetHard();
await printStatus();
await printTables();
async function doltResetHard(commit) {
if (commit) {
await db.raw(`CALL DOLT_RESET('--hard', ?)`, [commit]);
console.log("Resetting to commit:", commit);
} else {
await db.raw(`CALL DOLT_RESET('--hard')`);
console.log("Resetting to HEAD");
}
}Resetting to HEAD
Status:
No tables modified
Tables in database: employees, employees_teams, teamsDolt makes operating databases less error-prone. You can always back out changes you have in progress or rewind to a known good state.
Change data on a branch#
Dolt is the only SQL database with branches and merges. We will create and switch branches, and then make some changes and commit them to this new branch. Later, we’ll merge all the changes together. Think of a branch as a really long SQL transaction.
First, you need to create a branch. Creating a branch is a write so you do it with a
procedure,
dolt_branch().
In the Javascript code, we also consult the
dolt_branches
system table to make sure the branch does not already exist. Then we use dolt_checkout()
to switch branches.
await createBranch("modify_data");
await checkoutBranch("modify_data");
async function getBranch(branch) {
return db.select("name").from("dolt_branches").where("name", branch);
}
async function createBranch(branch) {
const res = await getBranch(branch);
if (res.length > 0) {
console.log("Branch exists:", branch);
} else {
await db.raw(`CALL DOLT_BRANCH(?)`, [branch]);
console.log("Created branch:", branch);
}
}
async function checkoutBranch(branch) {
await db.raw(`CALL DOLT_CHECKOUT(?)`, [branch]);
console.log("Using branch:", branch);
}Now that we’re on a new branch, it’s safe to make changes and the main branch will
remain unchanged. We are going to use a
transaction to insert, update, and delete
using the Knex query builder. All queries within a transaction are executed on the same
database connection, and run the entire set of queries as a single unit of work. Any
failure will mean the database will rollback any queries executed on that connection to
the pre-transaction state.
modifyData();
async function modifyData() {
try {
await db.transaction(async trx => {
await trx("employees")
.where("first_name", "Tim")
.update("first_name", "Timothy");
await trx("employees").insert({
id: 4,
last_name: "Bantle",
first_name: "Taylor",
});
await trx("employees_teams").insert({
employee_id: 4,
team_id: 0,
});
await trx("employees_teams")
.where("employee_id", 0)
.where("employee_id", 1)
.del();
});
} catch (err) {
// Rolls back transaction
console.error(err);
}
}Let’s inspect what we’ve done to make sure it looks right.
await printStatus();
await printDiff("employees");
await printDiff("employees_teams");
await printSummaryTable();Status:
employees: modified
employees_teams: modified
Diff for employees:
[
{
to_id: 0,
to_last_name: 'Sehn',
to_first_name: 'Timothy',
to_commit: 'WORKING',
to_commit_date: null,
from_id: 0,
from_last_name: 'Sehn',
from_first_name: 'Tim',
from_commit: 'bu68epe1k4el46l9cfsdishuf5665q7m',
from_commit_date: 2023-09-20T06:20:43.351Z,
diff_type: 'modified'
},
{
to_id: 4,
to_last_name: 'Bantle',
to_first_name: 'Taylor',
to_commit: 'WORKING',
to_commit_date: null,
from_id: null,
from_last_name: null,
from_first_name: null,
from_commit: 'bu68epe1k4el46l9cfsdishuf5665q7m',
from_commit_date: 2023-09-20T06:20:43.351Z,
diff_type: 'added'
}
]
Diff for employees_teams:
[
{
to_employee_id: 4,
to_team_id: 0,
to_commit: 'WORKING',
to_commit_date: null,
from_employee_id: null,
from_team_id: null,
from_commit: 'bu68epe1k4el46l9cfsdishuf5665q7m',
from_commit_date: 2023-09-20T06:20:43.351Z,
diff_type: 'added'
}
]
Summary:
Engineering: Brian Hendriks
Engineering: Aaron Son
Engineering: Taylor Bantle
Sales: Timothy Sehn
Sales: Brian FitzgeraldI am added to the engineering team on the modify_data branch. Tim is no longer on the
Sales team.
Finally, let’s commit these changes so we can make different changes on another branch.
await doltCommit("Brian <brian@dolthub.com>", "Modified data on branch");
await printCommitLog();Created commit: j9taft0oie0kg1rhss4glvvusv0tdao9
Commit log:
j9taft0oie0kg1rhss4glvvusv0tdao9: Modified data on branch by Brian
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System AccountChange schema on another branch#
We’re going to make a schema change on another branch and make some data modifications.
Below, you’ll see we check out the main branch so the new branch has the correct base
branch. Then, we create a new branch called modify_schema and run the modify_schema()
function, which uses a transaction to add a start date column and populate it. We finally
use status and diff to show off what changed.
await checkoutBranch("main");
await createBranch("modify_schema");
await checkoutBranch("modify_schema");
await printActiveBranch();
await modifySchema();
await printStatus();
await printDiff("employees");
await printSummaryTable();
async function modifySchema() {
try {
await db.transaction(async trx => {
await trx.schema.alterTable("employees", table => {
table.date("start_date");
});
await trx("employees").where("id", 0).update("start_date", "2018-08-06");
await trx("employees").where("id", 1).update("start_date", "2018-08-06");
await trx("employees").where("id", 2).update("start_date", "2018-08-06");
await trx("employees").where("id", 3).update("start_date", "2021-04-19");
});
} catch (err) {
// Rolls back transaction
console.error(err);
}
}This outputs the following:
Using branch: main
Created branch: modify_schema
Using branch: modify_schema
Active branch: modify_schema
Status:
employees: modified
Diff for employees:
[
{
to_id: 0,
to_last_name: 'Sehn',
to_first_name: 'Tim',
to_start_date: 2018-08-06T07:00:00.000Z,
to_commit: 'WORKING',
to_commit_date: null,
from_id: 0,
from_last_name: 'Sehn',
from_first_name: 'Tim',
from_start_date: null,
from_commit: '3li6nho3o9891ersocjh4q3l371uj880',
from_commit_date: 2023-09-20T06:28:42.459Z,
diff_type: 'modified'
},
{
to_id: 1,
to_last_name: 'Hendriks',
to_first_name: 'Brian',
to_start_date: 2018-08-06T07:00:00.000Z,
to_commit: 'WORKING',
to_commit_date: null,
from_id: 1,
from_last_name: 'Hendriks',
from_first_name: 'Brian',
from_start_date: null,
from_commit: '3li6nho3o9891ersocjh4q3l371uj880',
from_commit_date: 2023-09-20T06:28:42.459Z,
diff_type: 'modified'
},
{
to_id: 2,
to_last_name: 'Son',
to_first_name: 'Aaron',
to_start_date: 2018-08-06T07:00:00.000Z,
to_commit: 'WORKING',
to_commit_date: null,
from_id: 2,
from_last_name: 'Son',
from_first_name: 'Aaron',
from_start_date: null,
from_commit: '3li6nho3o9891ersocjh4q3l371uj880',
from_commit_date: 2023-09-20T06:28:42.459Z,
diff_type: 'modified'
},
{
to_id: 3,
to_last_name: 'Fitzgerald',
to_first_name: 'Brian',
to_start_date: 2021-04-19T07:00:00.000Z,
to_commit: 'WORKING',
to_commit_date: null,
from_id: 3,
from_last_name: 'Fitzgerald',
from_first_name: 'Brian',
from_start_date: null,
from_commit: '3li6nho3o9891ersocjh4q3l371uj880',
from_commit_date: 2023-09-20T06:28:42.459Z,
diff_type: 'modified'
}
]
Summary:
Engineering: Brian Hendriks Mon Aug 06 2018
Engineering: Aaron Son Mon Aug 06 2018
Sales: Tim Sehn Mon Aug 06 2018
Sales: Brian Fitzgerald Mon Apr 19 2021As you can see our defensive coding in the Insert data section paid off and employee start dates are displayed. This looks good so we’ll commit it.
await doltCommit("Taylor <taylor@dolthub.com>", "Modified schema on branch");
await printCommitLog();Created commit: 4j10oomkf2vp1309eoo01bq4ha4t6iq2
Commit log:
4j10oomkf2vp1309eoo01bq4ha4t6iq2: Modified schema on branch by Taylor
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System AccountMerge it all together#
Now we will merge all the branches together and show the resulting summary table. To
merge, use the procedure
dolt_merge().
await checkoutBranch("main");
await printActiveBranch();
await printCommitLog();
await printSummaryTable();
await doltMerge("modify_data");
await printSummaryTable();
await printCommitLog();
await doltMerge("modify_schema");
await printSummaryTable();
await printCommitLog();
async function doltMerge(branch) {
const res = await db.raw(`CALL DOLT_MERGE(?)`, [branch]);
console.log("Merge complete for ", branch);
console.log(` Commit: ${res[0][0].hash}`);
console.log(` Fast forward: ${res[0][0].fast_forward}`);
console.log(` Conflicts: ${res[0][0].conflicts}`);
}This outputs the following. You can see the data and schema evolving as we merge.
Using branch: main
Active branch: main
Commit log:
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System Account
Summary:
Engineering: Brian Hendriks
Engineering: Aaron Son
Sales: Tim Sehn
Sales: Brian Fitzgerald
Merge complete for modify_data
Commit: 9he3pav122o3qmh7vlm58muv0ie2600j
Fast forward: 1
Conflicts: 0
Summary:
Engineering: Brian Hendriks
Engineering: Aaron Son
Engineering: Taylor Bantle
Sales: Timothy Sehn
Sales: Brian Fitzgerald
Commit log:
j9taft0oie0kg1rhss4glvvusv0tdao9: Modified data on branch by Brian
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System Account
Merge complete for modify_schema
Commit: fjfuj3h9nuap933qtt0aa4fske2h8r6b
Fast forward: 0
Conflicts: 0
Summary:
Engineering: Brian Hendriks Mon Aug 06 2018
Engineering: Aaron Son Mon Aug 06 2018
Engineering: Taylor Bantle None
Sales: Timothy Sehn Mon Aug 06 2018
Sales: Brian Fitzgerald Mon Apr 19 2021
Commit log:
fjfuj3h9nuap933qtt0aa4fske2h8r6b: Merge branch 'modify_schema' into main by 14i5lj63h3u8l4kv
4j10oomkf2vp1309eoo01bq4ha4t6iq2: Modified schema on branch by Taylor
j9taft0oie0kg1rhss4glvvusv0tdao9: Modified data on branch by Brian
flfiptf13lc7chlvbkikqtss3r02k2se: Inserted data into tables by Tim
80ks3k1ook712vauvavdnnd6t3q86e3d: Created tables by Taylor
dtn5h4oquovaes0n719b3sagbecbkp1h: Initialize data repository by Dolt System AccountYou’ll also see the final results in the Hosted Workbench:
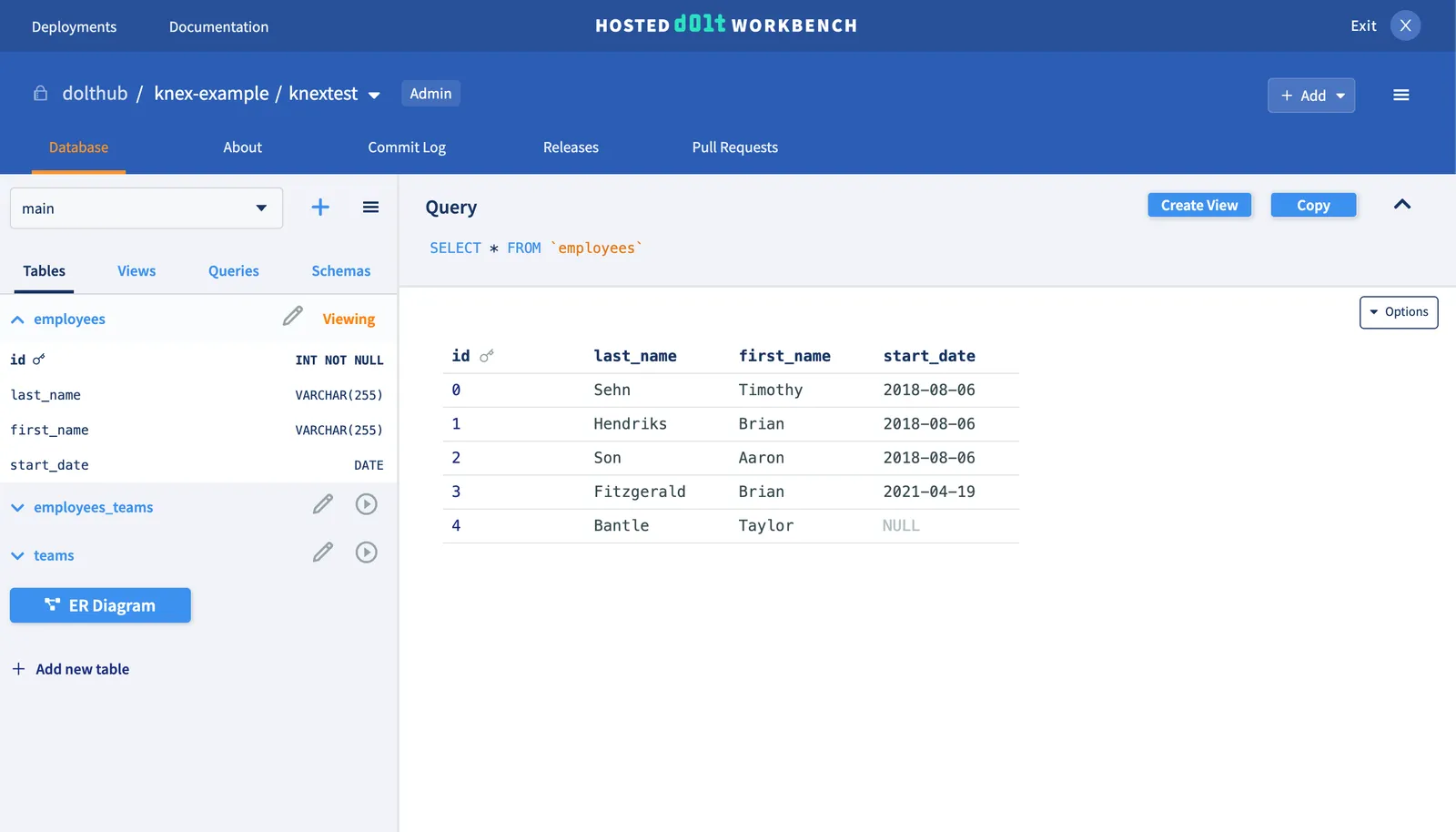
Notice the first merge was a fast-forward merge just like in Git. Dolt will detect schema and data conflicts if you make them.
Bonus Section: Using a read replica#
Hosted Dolt now supports read replicas, a read-only server you can run queries against. Every write to the primary server is replicated to the read replicas. This allows you to scale your read traffic horizontally.
Some SQL query builders and ORMs (such as Sequelize) support specifying one or more read replicas and will automatically route read traffic to the replicas. Knex.js does not have this feature yet. To accomplish something similar, we create two Knex instances - one for the primary and one for the read replica - and explicitly send read queries to the read replica. You can follow along on this branch in our example repository.
First, you’ll need to specify the read replica host in the .env file.
DB_READ_REPLICA_HOST="r01-dolthub-knex-example.dbs.hosted.doltdb.com"And then create an additional Knex instance using that host.
const db = knex({
client: "mysql2",
connection: { ...config, host: process.env.DB_HOST },
pool: poolConfig,
});
const readDb = knex({
client: "mysql2",
connection: { ...config, host: process.env.DB_READ_REPLICA_HOST },
pool: poolConfig,
});Every time we write to the database using the primary instance, we will see it reflected
in the read replica instance. For example, after we create our three tables in the
setupDatabase function, we can use the read replica instance to show the tables.
await setupDatabase(); // Uses `db`
await printTables(); // Uses `readDb`
async function printTables() {
const res = await readDb.raw("SHOW TABLES");
const tables = res[0].map(table => table[`Tables_in_${database}`]).join(", ");
console.log("Tables in database:", tables);
}And it would output the tables we created:
Tables in database: employees, employees_teams, teamsManaging branches in your read replica#
Unlike other SQL databases, Dolt has branches. The main challenge with the code we wrote
without replicas is making sure the primary and read replica instances are pointing at the
same branch when we run read and write queries. For example, if we create a new branch
modify-data and check it out on the primary instance, printActiveBranch using the read
replica will still show the main branch.
The code:
await checkoutBranch("main"); // Uses db
await printActiveBranch(); // Uses readDb
await checkoutBranch("modify-data");
await printActiveBranch();Outputs:
Using branch: main
Active branch: main
Using branch: modify-data
Active branch: mainBut we want it to output:
Using branch: main
Active branch: main
Using branch: modify-data
Active branch: modify-dataThere are a few ways we can keep our read replica active branch in sync with our primary active branch, which are documented here.
The simplest option (which we use in the example code) is to run CALL DOLT_CHECKOUT() on
the read replica every time we run it on the primary.
async function checkoutBranch(branch) {
await db.raw(`CALL DOLT_CHECKOUT(?)`, [branch]);
await readDb.raw(`CALL DOLT_CHECKOUT(?)`, [branch]);
console.log("Using branch:", branch);
}This would also work with a USE statement.
async function checkoutBranch(branch) {
await db.raw(`USE \`${database}/${branch}\``);
await readDb.raw(`USE \`${database}/${branch}\``);
console.log("Using branch:", branch);
}However, in some cases you may not want to change the active branch on the read replica
and instead quickly compare changes between revisions. We can use fully-qualified
references with database revisions or AS OF clauses to do so.
For example, if we accidentally wrote some code that drops a table on branch oops, we
may want to check that the mistake wasn’t committed to that branch and that main wasn’t
also affected.
await checkoutBranch("oops");
await printActiveBranch();
await dropTable("employees_teams");
await printTables("WORKING");
await printTables("oops");
await printTables("main");
await printActiveBranch();
async function printTables(activeBranch) {
const res = await readDb.raw("SHOW TABLES AS OF ?", activeBranch);
const tables = res[0].map(table => table[`Tables_in_${database}`]).join(", ");
console.log("Tables in database:", tables);
}Which will output:
Active branch: oops
Tables in database: employees, teams
Tables in database: employees, employees_teams, teams
Tables in database: employees, employees_teams, teams
Active branch: oopsOnly our working set was affected and we can easily CALL DOLT_CHECKOUT('employees_teams') to reverse the mistake.
Conclusion#
Congratulations on making it this far! You can now start building your own Dolt application using Node and Knex.js. If you have any questions or need more help getting starting, stop by our Discord.