
Git and MySQL had a baby, and it’s called Dolt. That wasn’t always the case though. Let’s talk a little about Dolt’s history, and where we’re going with the Dolt Command Line Interface (CLI).
In The Beginning#
Dolt started out as a command line tool very much like Git. Before we had anything to do with SQL, the idea was that Dolt was Git for data, and our command line was the only way to use the tool. We learned a lot about how to store tabular data efficiently in Prolly Trees, and what operations we could quickly perform with this new novel data structure. It looked very familiar to anyone who knew Git. There was a .dolt directory which was your repository, just like .git, and data was manipulated by a command line tool - dolt. Dolt had subcommands which looked a lot like Git - init, commit, log, diff, etc. It even asked you to introduce yourself, just like Git does! The Dolt commands had direct access to the data files stored on your machine. And it was good.

That was the beginning for Dolt, and being a scrappy startup we listened to our users, experimented, and evolved. We came to realize that tabular data is familiar to many people and tools. If we adopted SQL to work with the data format we had developed we’d open up a lot of new possibilities. We embarked on our second phase of the product, and built a MySQL compatible SQL server which runs on top of the Dolt storage format. In keeping with the MySQL approach, we enabled multiple Dolt repositories (we’ll call them databases now) being managed by one server process. Interactions with that server process were through a sql client - in particular the standard mysql client. We experimented and got all the version control behaviors that were critical into stored procedures, functions and system tables with the goal of enabling users to just use SQL, and nothing else, to manage their Dolt data. And it was good, too.
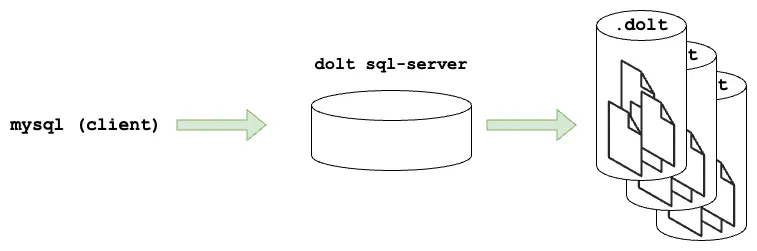
Along the way to getting to a highly capable SQL implementation, the CLI hasn’t been updated for our new paradigm. For example, if you are using Dolt with a running server while also running commands directly, you may notice that dolt status and select * from dolt_status will tell you different results. The core issue being that the CLI is accessing storage files on disk directly while there is a server holding state in memory.
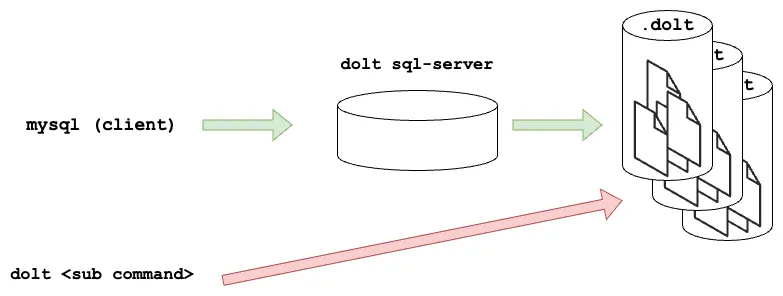
We put guards in place to try and ensure that the CLI wouldn’t make writes when the server was running with the use of a lock file. It was eye opening when I saw a Dolt user get a warning about the server being locked, only to proceed with deleting the lock file and running their command anyway. Clearly, they needed the tool to simply work regardless of whether a server was running or not.
This is the state of the Dolt CLI today, and we have a plan to fix it!
The Future of the CLI#
Stepping back a bit, the ideal experience for the CLI would be that you can either run it locally on data you have a copy of, or you can run commands against a server where the data isn’t even on your computer. Wouldn’t it be nice if dolt log could show you a log of changes to your production database hosted elsewhere? Wouldn’t it be great to be able to do that without pulling all of your data to your local machine? Having local copies of all data makes sense for git because source repositories never get very big. Databases get large though, and it would be ideal to have the Dolt commands you are familiar with work in both the local and remote contexts. That includes three distinct modes 1) Local data manipulation on disk 2) Local data manipulation by a local process. Ideal for testing your SQL server based applications. 3) Remote data stored in a network accessible server. Thankfully, (2) and (3) are effectively the same problem interface: SQL over a network. Which brings us to (1) needing to migrate to a SQL interface to retrieve all information.
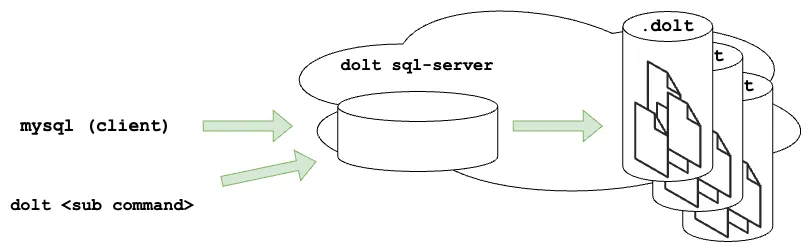
Going over a network is not strictly required though! We have a point in our favor: dolt is a small golang binary which can do All the Things™. The Dolt binary has the SQLEngine within it. This means that we can implement the data collection logic in the Dolt CLI and skip the need to contact a server if we know a server isn’t running. Thus we keep the performance of a local command line tool, while enabling you to go over the network when appropriate without the user ever knowing the difference.
The first step of the project was to build the ability to run CLI commands with awareness of when they can execute their SQL directly in memory against the files on disk, or if they need to transit over the network. This lays the groundwork for us implementing all of the data retrieval and update logic in the CLI using SQL. By leveraging our existing stored procedures, functions, and Dolt system tables, we’ve already migrated the sql, status, add, and blame commands to work in this new approach. We have another 24 commands to go (branch, diff and commit commands are in flight), and when we are done, all Dolt CLI commands will enable you to execute commands consistently against local files, against a local server, and servers running off box.
Making it Concrete#
Let’s compare the dolt sql command’s old and new behavior. Prior to Dolt 1.1, you could create a database and interact with it directly, so long as you didn’t start a server.
$ dolt sql -q 'create database db;use db;create table tbl (id int primary key, text varchar(255))'
$ dolt sql -q 'use db; insert into tbl values (1,"foo")'
Query OK, 1 row affected (0.01 sec)If you start a server by running dolt sql-server, then the dolt sql command will start complaining about the database being locked when you attempt to make updates.
$ dolt sql -q 'use db; insert into tbl values (2,"bar")'
error on line 1 for query insert into tbl values (2,"bar"): database is locked to writesIf you use version 1.1 or later of Dolt though, you will see the new behavior - remember, the server is running!
$ dolt sql -q 'use db; insert into tbl values (2,"bar")'
$ dolt sql -q 'use db; select * from tbl'`
+----+------+
| id | text |
+----+------+
| 1 | foo |
| 2 | bar |
+----+------+This works now because the dolt sql command respects the lock file that the server created, and uses it to cooperate with the server as opposed to just giving up. The lock file contains connection information for the CLI to use to connect to the server.
As stated above, the add, blame, and status commands are server aware now too. Use them with confidence if you have a server running - Other commands coming soon!
Finally, to give a taste of the future, when we have completed the SQL backend rewrites for all commands, our last step will be to enable the CLI to connect to a server off your host, such as Hosted Dolt instances. For such commands you will specify connection arguments before the subcommand name:
$ dolt --connection “{Server…}” logThis will show you a log of all changes on your production host. We’ll talk more about that when we get there!
Drinking Our Own Champagne#
There is a common idiom: “Eating our own Dogfood”. It’s used as a shorthand for a business’s motivation to use whatever it is they are trying to sell. It’s a great way to have compassion for your users. DoltHub has several people who came from Amazon, a notoriously customer obsessed company. For us, using our SQL interfaces is like Eating our own Dogfood, or as I learned instead from Colin Bodell, “Drinking our own Champagne.” By giving the CLI an overhaul, we’ve already found ways to extend and modify existing stored procedures such that they operate better. The quality of the server is going to get better across the board as a result of leveraging SQL for all data access in the CLI. You’ll have more consistent and correct CLI behavior as well!
As stated above, we have a long list of command to update. If you’d like us to prioritize one over any other, hop on our discord channel and make a request!