
This article discusses the technical details of writing integration tests that manage multiple sub-processes in Golang, including attaching debuggers to the new processes. It’s part of our our technical Golang blog series. We publish a new article in the series every 3 weeks.
We’re writing Dolt, a version-controlled SQL
database. Recent customers have turned our attention to the need for different
forms of replication for performance and availability. Dolt’s first form of
replication
uses a remote as an intermediary: the primary pushes new data to the remote on
commit, and replicas pull it on start transaction. It works well and is easy
to configure, but those pulls on the replicas mean you pay a performance penalty
on every new transaction. This wasn’t good enough for our customer, so we built
another form of
replication
for them that’s much closer to traditional RDBMS replication. In this form,
“cluster replication”, servers in the cluster communicate directly and you pay a
small penalty on every write, rather than at read time.
So far, so good. But unlike remote-based replication, which was easy to test with a single process using a file-based remote, cluster replication by its nature requires multiple running processes. This makes it a lot harder to test, and it’s critically important that we have robust tests of this functionality.
This article is about the solution we wrote, as well as how we debug tests that involve running multiple Golang binaries.
The testing framework#
When designing a testing system that runs multiple binaries that talk to each other and makes assertions about their behavior, we wanted it to have the following properties:
- Invokable as a standard Golang test
- Full end-to-end test that reproduces the behavior customers will see in production
- Easy to define new tests
- No containers or kubernetes requirement
Requirement (1) doesn’t rule out much, it just means we need to be able to run
the test with standard tools, e.g. go test -v, “Run Test” from an IDE, etc.
Requirement (2) means we actually do need to spin up separate processes as part of the test: no cheating by mocking things out in the same process, which could miss bugs.
Requirement (3) means that test definitions shouldn’t have excessive boilerplate, e.g. managing the processes explicitly by writing code.
Requirement (4) is a nice to have that makes the tests simpler and reduces the dependencies required to run them. (We aren’t opposed to docker or kubernetes in general, and we use them for all sorts of things, but prefer to keep them out of tests when possible).
In the end we came up with a testing framework that has two principal components:
- A test definition format. We chose YAML to define tests, because it means we don’t have write our own parser and Golang has good support for it. We also use a lot of YAML internally for our infrastructure, so people are already familiar with it.
- A test runner that consumes the definitions and knows how to start new processes, stop them, run queries against them, and test assertions.
We’ll revisit the test runner in a bit. For now let’s examine the test definition.
The test definition#
Let’s look at a relatively simple example of a test defined in this format. It’s kind of long, but it’s pretty simple. We’ll go over each part in detail.
- name: primary comes up and replicates to standby
multi_repos:
- name: server1
repos:
- name: repo1
with_remotes:
- name: standby
url: http://localhost:3852/repo1
- name: repo2
with_remotes:
- name: standby
url: http://localhost:3852/repo2
with_files:
- name: server.yaml
contents: |
log_level: trace
listener:
host: 0.0.0.0
port: 3309
cluster:
standby_remotes:
- name: standby
remote_url_template: http://localhost:3852/{database}
bootstrap_role: primary
bootstrap_epoch: 10
remotesapi:
port: 3851
server:
args: ["--port", "3309"]
port: 3309
- name: server2
repos:
- name: repo1
with_remotes:
- name: standby
url: http://localhost:3851/repo1
- name: repo2
with_remotes:
- name: standby
url: http://localhost:3851/repo2
with_files:
- name: server.yaml
contents: |
log_level: trace
listener:
host: 0.0.0.0
port: 3310
cluster:
standby_remotes:
- name: standby
remote_url_template: http://localhost:3851/{database}
bootstrap_role: standby
bootstrap_epoch: 10
remotesapi:
port: 3852
server:
args: ["--config", "server.yaml"]
port: 3310
connections:
- on: server1
queries:
- exec: "use repo1"
- exec: "create table vals (i int primary key)"
- exec: "insert into vals values (1),(2),(3),(4),(5)"
restart_server:
args: ["--config", "server.yaml"]
- on: server1
queries:
- exec: "use dolt_cluster"
- query: "select `database`, standby_remote, role, epoch, replication_lag_millis, current_error from dolt_cluster_status order by `database` asc"
result:
columns:
[
"database",
"standby_remote",
"role",
"epoch",
"replication_lag_millis",
"current_error",
]
rows:
- ["repo1", "standby", "primary", "10", "0", "NULL"]
- ["repo2", "standby", "primary", "10", "0", "NULL"]
retry_attempts: 100
- on: server2
queries:
- exec: "use repo1"
- query: "select count(*) from vals"
result:
columns: ["count(*)"]
rows: [["5"]]Looking at the big picture, the definition has two main components:
multi_repos, which defines all the servers in the cluster and their propertiesconnections, which defines a series of connections to make to the servers defined inmulti_repos, queries to issue, and their expected results.
Let’s look at the the definition of one of the servers.
- name: server1
repos:
- name: repo1
with_remotes:
- name: standby
url: http://localhost:3852/repo1
- name: repo2
with_remotes:
- name: standby
url: http://localhost:3852/repo2
with_files:
- name: server.yaml
contents: |
log_level: trace
listener:
host: 0.0.0.0
port: 3309
cluster:
standby_remotes:
- name: standby
remote_url_template: http://localhost:3852/{database}
bootstrap_role: primary
bootstrap_epoch: 10
remotesapi:
port: 3851
server:
args: ["--port", "3309"]
port: 3309This defines a server with two databases (repos) in it. Note the embedded
server.yaml file, which we write to disk to give to this server when we run it
as a process. It will run that process, dolt sql-server, with the arguments
--port 3309, and we also record this port separately to make it easier to
communicate to this server later on.
Next let’s look at the connections section, which is where assertions live:
- on: server2
queries:
- exec: "use repo1"
- query: "select count(*) from vals"
result:
columns: ["count(*)"]
rows: [["5"]]This section instructs the test runner to run the queries given on server2,
which is the replica in this cluster. exec means just run the query and make
sure it doesn’t have an error. query means to run the query and then assert
the results match what’s given. The test runner runs all the connections
serially, and you can specify as many different connections to as many servers
as you want.
There are some more subtleties in the test definition language to handle different edge cases, like what happens when a process dies unexpectedly (we simulate this by killing it when part of a test definition), but these are the basics. In general, you can read one of these YAML files like normal lines of code making assertions, which is great.
The test runner#
The test runner reads those YAML descriptions and turns them into
structs. Golang’s YAML libraries make this pretty easy. For example, here’s how
we define a Server:
type Server struct {
Name string `yaml:"name"`
Args []string `yaml:"args"`
Envs []string `yaml:"envs"`
Port int `yaml:"port"`
DebugPort int `yaml:"debug_port"`
LogMatches []string `yaml:"log_matches"`
ErrorMatches []string `yaml:"error_matches"`
}The top level YAML element is similarly defined as a TestDef struct. Parsing a
test file into Golang structs is super easy:
func ParseTestsFile(path string) (TestDef, error) {
contents, err := os.ReadFile(path)
if err != nil {
return TestDef{}, err
}
dec := yaml.NewDecoder(bytes.NewReader(contents))
dec.KnownFields(true)
var res TestDef
err = dec.Decode(&res)
return res, err
}Most of the work the test runner does is pretty boring, but there’s one interesting part that’s tough to get right: process management. Here we have three concerns:
- Invoking our binary with the correct arguments
- Recording its output so we can make assertions on it
- Keeping a handle to the process so we can kill it, either to simulate a failure or to end the test
Luckily, Golang’s os/exec package provides great tools for these concerns. My
colleague Aaron previously wrote about this in
detail if you
want a deep dive. For our purposes, the interesting part is below. We’ve
previously created a *exec.Cmd with the proper binary path and arguments, and
now we want to start it.
func runSqlServerCommand(dc DoltCmdable, opts []SqlServerOpt, cmd *exec.Cmd) (*SqlServer, error) {
stdout, err := cmd.StdoutPipe()
if err != nil {
return nil, err
}
cmd.Stderr = cmd.Stdout
output := new(bytes.Buffer)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
io.Copy(io.MultiWriter(os.Stdout, output), stdout)
}()
done := make(chan struct{})
go func() {
wg.Wait()
close(done)
}()
server := &SqlServer{
Done: done,
Cmd: cmd,
Port: 3306,
Output: output,
}
for _, o := range opts {
o(server)
}
err = server.Cmd.Start()
if err != nil {
return nil, err
}
return server, nil
}Before starting the dolt sql-server process with Cmd.Start(), we rewire its
Stderr to Stdout and direct both into a bytestream that we can evaluate
later. We also set up a chan to signal when all output has been successfully
copied. Then we package all this information up into a SqlServer struct and
return it so the test logic can interact with the server as needed.
After running all the queries specified in the test definition, the test runner
then shuts down the servers it started up. Because the dolt sql-server process
handles interrupt signals and attempts to do graceful shutdown, we want to give
it that chance. So we don’t simply call os.Process.Kill(), which would
immediately terminate the process. Instead, we send it a signal and wait for it
to stop on its own. In addition to waiting for the process to tell us it’s done,
we also wait for its output to finish being copied over by waiting on the Done
channel we established above.
func (s *SqlServer) GracefulStop() error {
err := s.Cmd.Process.Signal(syscall.SIGTERM)
if err != nil {
return err
}
<-s.Done
return s.Cmd.Wait()
}The code to gracefully shutdown a process is actually platform-dependent, so on Windows we have to do something slightly different:
func ApplyCmdAttributes(cmd *exec.Cmd) {
// Creating a new process group for the process will allow GracefulStop to send the break signal to that process
// without also killing the parent process
cmd.SysProcAttr = &syscall.SysProcAttr{
CreationFlags: syscall.CREATE_NEW_PROCESS_GROUP,
}
}
func (s *SqlServer) GracefulStop() error {
err := windows.GenerateConsoleCtrlEvent(windows.CTRL_BREAK_EVENT, uint32(s.Cmd.Process.Pid))
if err != nil {
return err
}
<-s.Done
_, err = s.Cmd.Process.Wait()
return err
}As a ThinkPad peasant yearning for the freedom of Apple silicon1, it was a
nasty surprise to discover this behavior, and the many guides on the internet
about how to achieve this behavior on Windows were basically all wrong. The key
is to apply the syscall.CREATE_NEW_PROCESS_GROUP to the exec.Cmd before
starting it, so that when you eventually send it the BREAK signal it won’t
also kill the parent process.
The compiler will choose the right version of the above functions based on the OS by examining the file names and the build tags, which still works the same now as it did 10 years ago.
Debugging multiple processes with dlv#

While this kind of integration testing is critical for correctness and to catch
regressions, it’s not easy to debug. But it is possible! I’m not smart enough to
debug with printf statements, so I need a bit of help from my IDE. Golang’s
debugger tool dlv supports running a go binary on your behalf, to which you
can then connect the GUI debugger in your IDE. You can even connect the debugger
to a dlv process running on another machine, but for our purposes we’ll do
everything on localhost.
We just need to build support for doing this into the test framework:
func (u DoltUser) DoltCmd(args ...string) *exec.Cmd {
cmd := exec.Command(DoltPath, args...)
cmd.Dir = u.tmpdir
cmd.Env = append(os.Environ(), "DOLT_ROOT_PATH="+u.tmpdir)
ApplyCmdAttributes(cmd)
return cmd
}
func (u DoltUser) DoltDebug(debuggerPort int, args ...string) *exec.Cmd {
if DelvePath != "" {
dlvArgs := []string{
fmt.Sprintf("--listen=:%d", debuggerPort),
"--headless",
"--api-version=2",
"--accept-multiclient",
"exec",
DoltPath,
"--",
}
cmd := exec.Command(DelvePath, append(dlvArgs, args...)...)
cmd.Dir = u.tmpdir
cmd.Env = append(os.Environ(), "DOLT_ROOT_PATH="+u.tmpdir)
ApplyCmdAttributes(cmd)
return cmd
} else {
panic("dlv not found")
}
}Here we have two versions of the code to invoke a new dolt process, depending
on whether we want to debug or not. For debugging, we tell the dlv binary to
execute our binary for us. The arguments provided tell dlv to await execution
until the debugger connects — otherwise, the process would probably complete
before we could connect to it to hit our breakpoints. We call one vs. the other
based on whether the debug_port option is specified for a particular server
in the test definition.
Once we edited the test definition to set a debug_port for each server, we
need to create N+1 different run configurations in the IDE: one for each of the
servers, and another one to run the test itself. For the example above with 2
servers, that means 3 different run configurations.
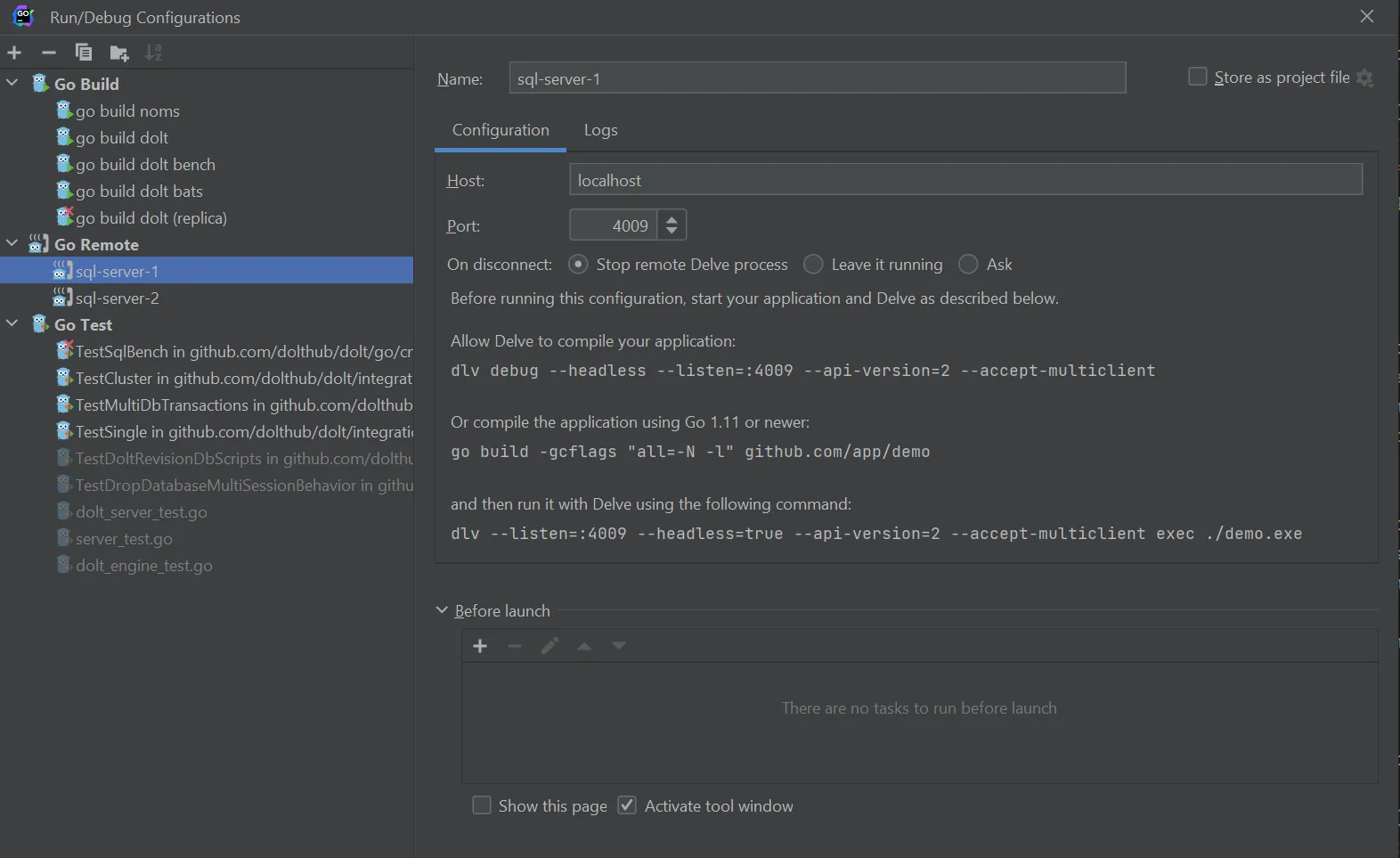
The process to create a remote debugger configuration will vary based on your IDE. I use JetBrains GoLand, so for me this involves defining a new “Go Remote” run configuration like this:
I define one run configuration for each server in the YAML test definition. The only difference between them is the port they connect to. Then, to run the test and connect the debugger:
- Run the primary test configuration
- Wait for the new process to start, waiting for a debugger connection:
API server listening at: [::]:4009 - Run each of the remote debug configurations you set up before. Note that you can’t “Run” these configurations, only “Debug” them.
If you’ve done everything correctly, your debugger should connect to the other process and you should start hitting your breakpoints. Happy debugging!
Limitations and gotchas#
- Our test framework runs a compiled binary found on your
$PATH, rather than compiling and running the code in your workspace, asgo runand friends do. That would be better but it’s harder to get right. - You may need to install
dlvif it isn’t on your system.dlvneeds to be on your$PATHas well. - For the debugging use case, we needed to radically increase timeouts in the test methods to prevent the test from finishing because we took too long poking around with breakpoints. We set up an environment key to alter the test timeouts to make this easy.
Conclusion#
We hope this is a helpful strategy for writing Golang integration tests that manage multiple processes. It has worked well for us so far, and we’ll be making use of this pattern much more extensively as we continue to build out features and beef up our test coverage.
This article is part of our our technical Golang blog series. We publish a new article in the series every 3 weeks, so check back often or subscribe with RSS.
Have questions about Dolt or Golang integration testing? Join us on Discord to talk to our engineering team and meet other Dolt users.
Footnotes#
-
I actually run Windows not because we’re too cheap to buy me a MacBook, but because our product supports Windows and it’s important that some of us run it to find compatibility bugs before our customers do. ↩