Why a database of hospital prices doesn't exist yet

In 2021, a US executive order forced hospitals to publish all their insurance-negotiated rates in machine readable files. We think this data should be public, so we're crowdsourcing a single, fully open, MySQL-compatible database of it. You can track the data we've collected so far here.
Why
5,000 hospitals have put their rates on their own sites, in their own formats. Like this, it's almost impossible to compare apples to apples. Putting all this data in one database means
- you can easily audit hospitals
- you can easily compare rates
- you can compare the rates against other databases easily (like the payer-published rates, which in theory are supposed to match)
All the files are organized differently, which makes this a heroic job for one person. The cost of building it exceeds a hundred thousand dollars, requiring thousands of man-hours to do it.
We're handling this at DoltHub by treating database like an open source codebase. Each person who wants to contribute to our hospital price database can clone their own Dolt copy, make a branch, then submit a PR on DoltHub with their proposed additions. That PR ultimately goes through me. I sample both the source file and transformed file, and if it passes all my checks, I merge it in.
The idea is to be able to build powerful open source databases like Linux, Apache, or GIMP, where design decisions and code contributions came from both leadership and the community.
We've looked at hundreds of files to design a schema which can capture most of them without losing data, and have an active (if chaotic) Discord channel where we're constantly (days, nights, and weekends) discussing this. We've got everyone from students to healthcare professionals. If you've got ideas, come check us out.
Each file is its own unique snowflake
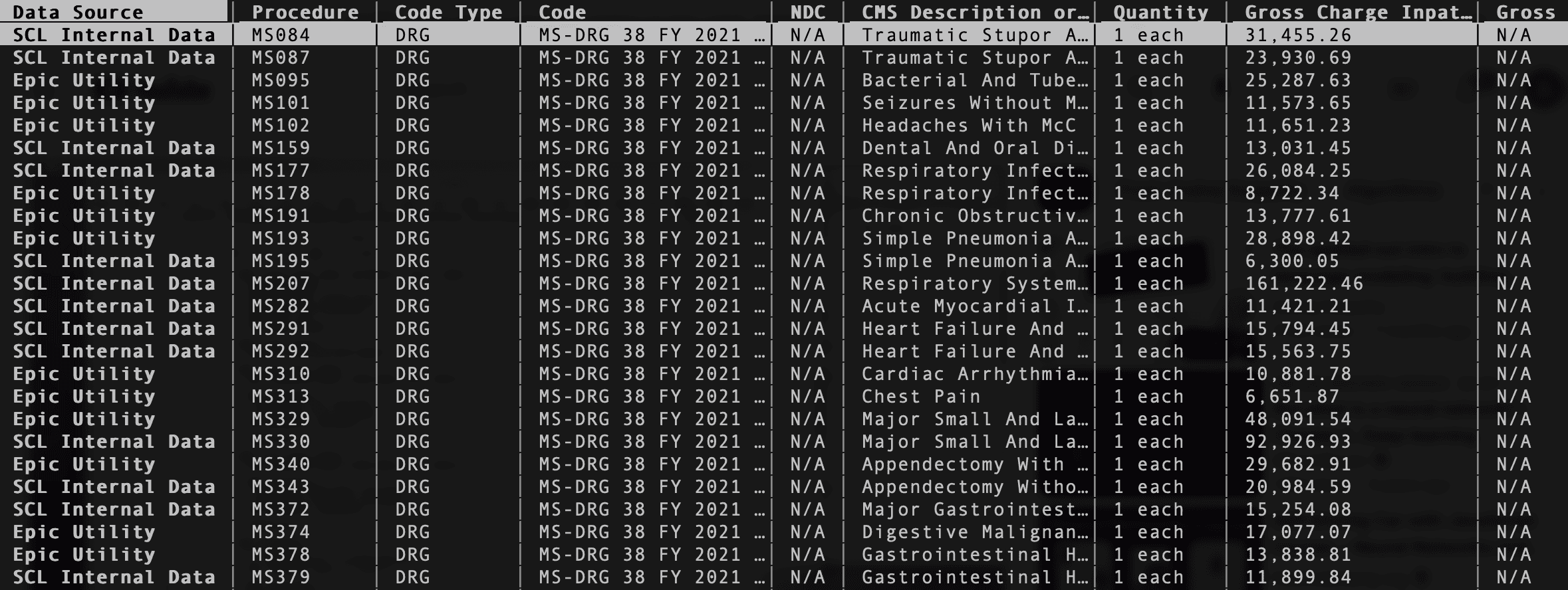 A snapshot of rates from Rosary Healthcare. The codes are buried in strings that need to have their actual codes extracted (viewed in VisiData)
A snapshot of rates from Rosary Healthcare. The codes are buried in strings that need to have their actual codes extracted (viewed in VisiData)
Transforming these files into a uniform format is painstaking, toilsome work that no amount of machine learning or cheap labor can solve, because understanding what the columns mean requires understanding where it fits into the rest of the file.
We've learned that hospitals can have 5 codes in a single row, or just one. Some hospitals use the word "code" to refer to the external billing code, and "procedure code" to refer to the hospital-internal code, while others have the opposite standard.
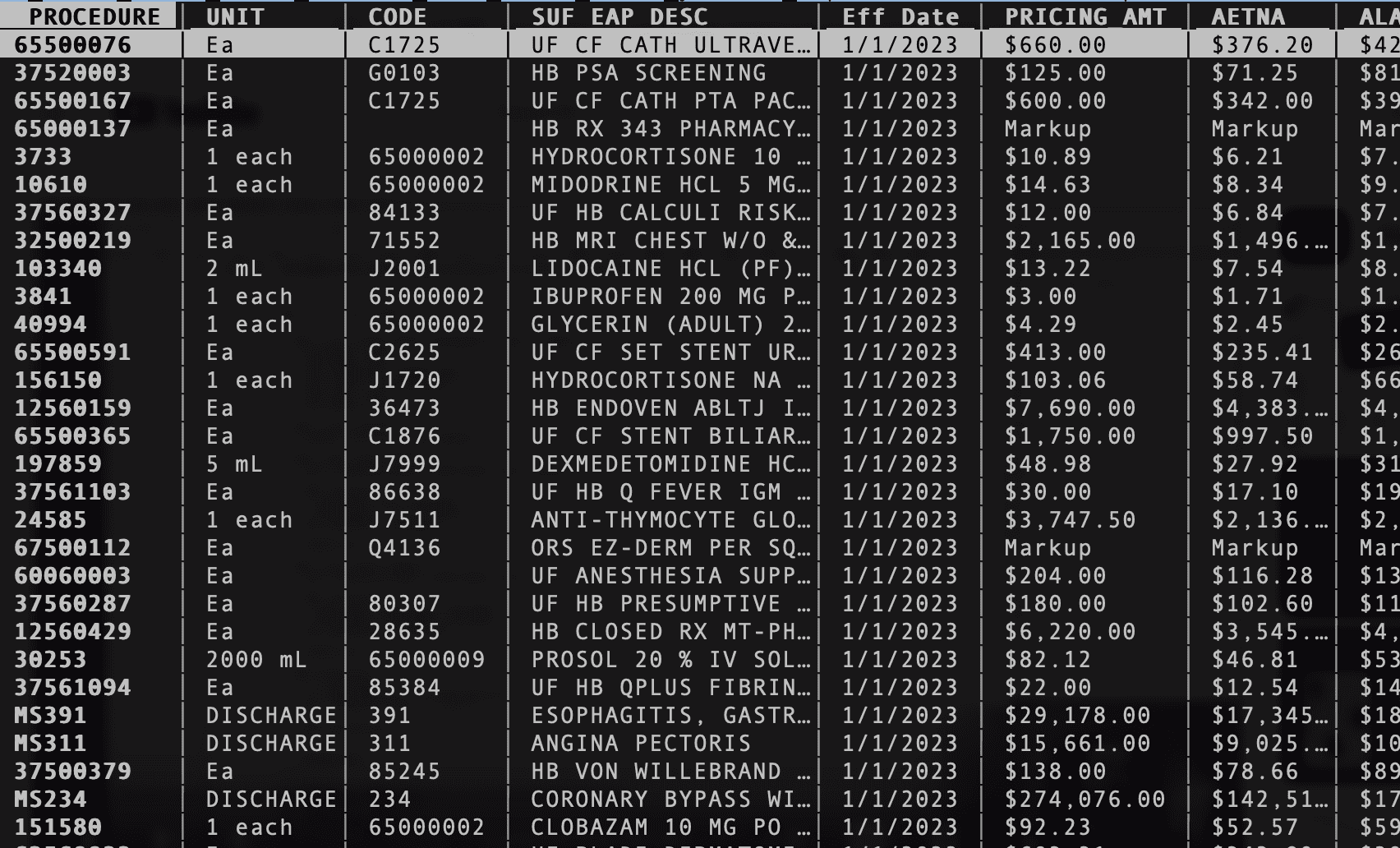 At Shands Teaching Hospital, it's unclear what values are in the "code" column. CPT/DRG and hospital-internal codes appear to be mixed in with each other.
At Shands Teaching Hospital, it's unclear what values are in the "code" column. CPT/DRG and hospital-internal codes appear to be mixed in with each other.
 At University of Pennsylvania hospital, "uninsured" and "cash price" are listed as two separate rates. Is this a mistake?
At University of Pennsylvania hospital, "uninsured" and "cash price" are listed as two separate rates. Is this a mistake?
The most punctilious hospitals will put different kinds of billing codes in separate columns. But some will put them all in a single column. The most casual hospitals will even put different kinds of codes in a single cell.
 All 180 of HCA's hospitals combine multiple different schemas in a single file, often putting multiple codes in the same cell
All 180 of HCA's hospitals combine multiple different schemas in a single file, often putting multiple codes in the same cell
Hospitals don't have to think about primary keys in their files, meaning they can publish multiple rows with all the values the same except the price. From the point of view of us database builders, this doesn't make sense. If the hospital can bill any of these rates, how does it decide?
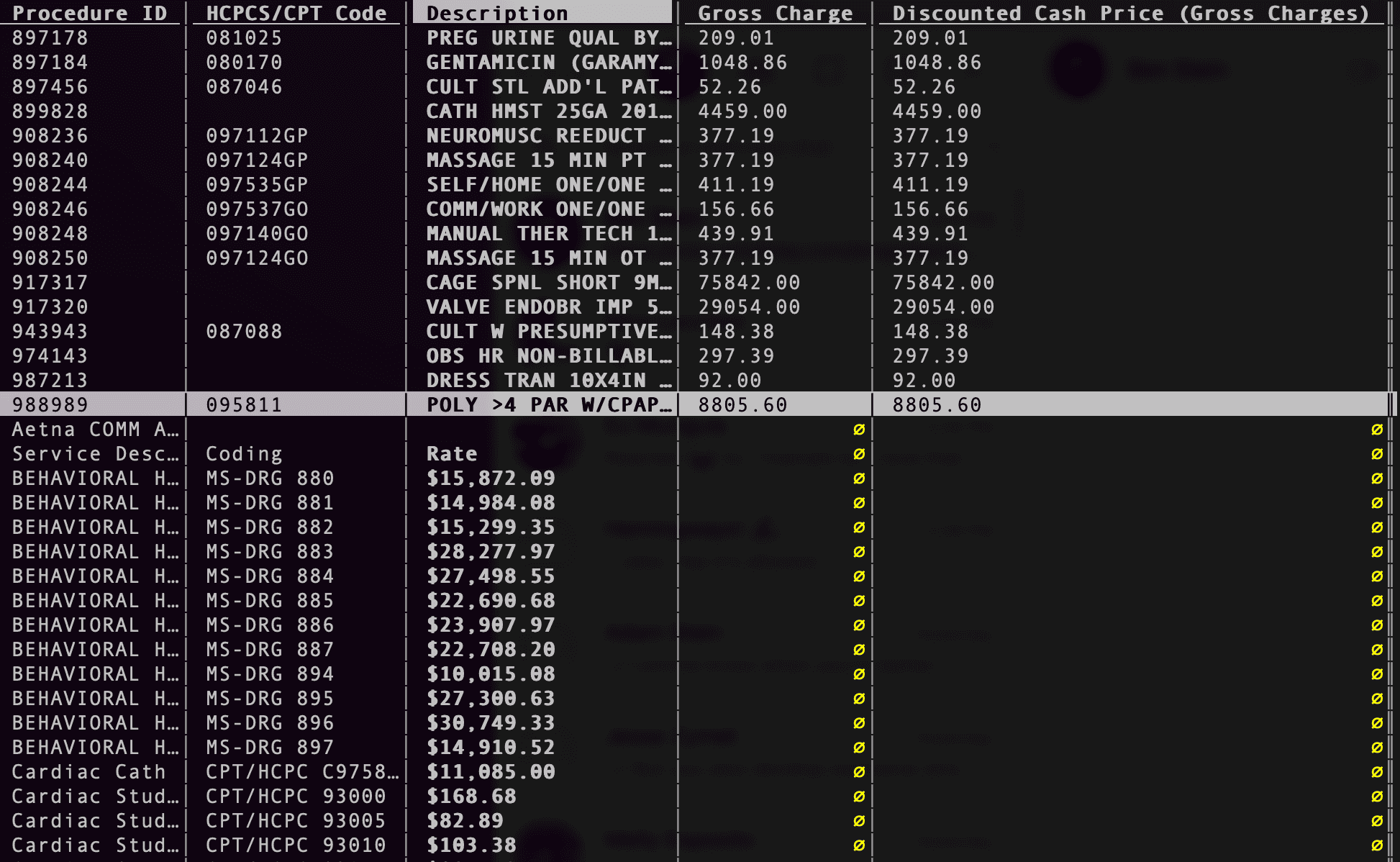
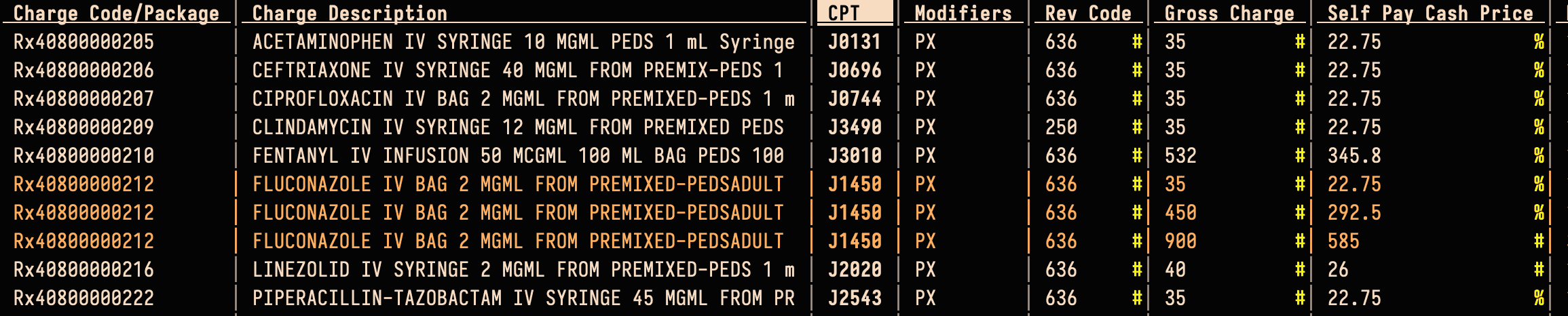 Greenville Memorial lists multiple prices with the exact same metadata, making it unclear what gets charged when.
Greenville Memorial lists multiple prices with the exact same metadata, making it unclear what gets charged when.
Other hospitals have their own unique way of billing that doesn't fit the schema of any others. How do we handle these? Do we add unique PK columns for each hospital with a unique schema?
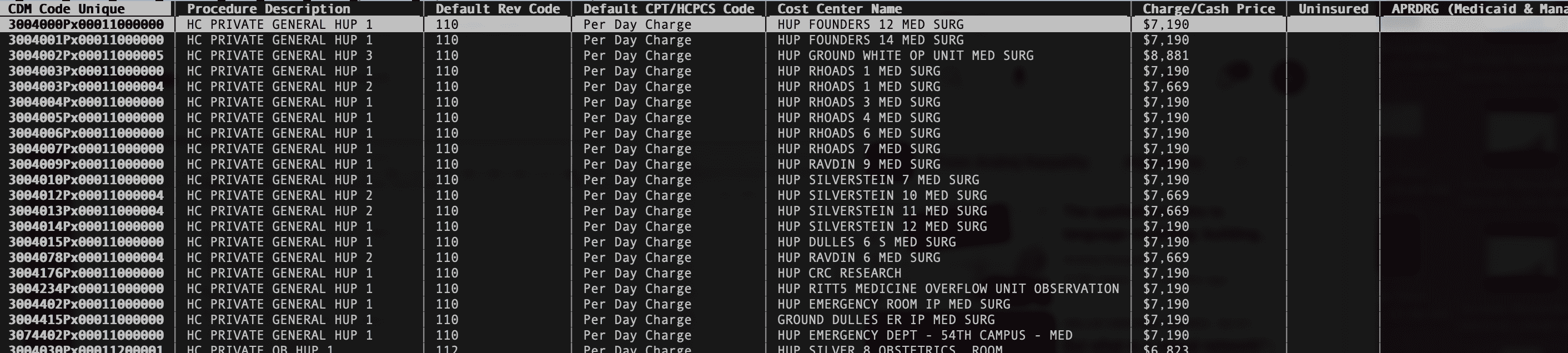
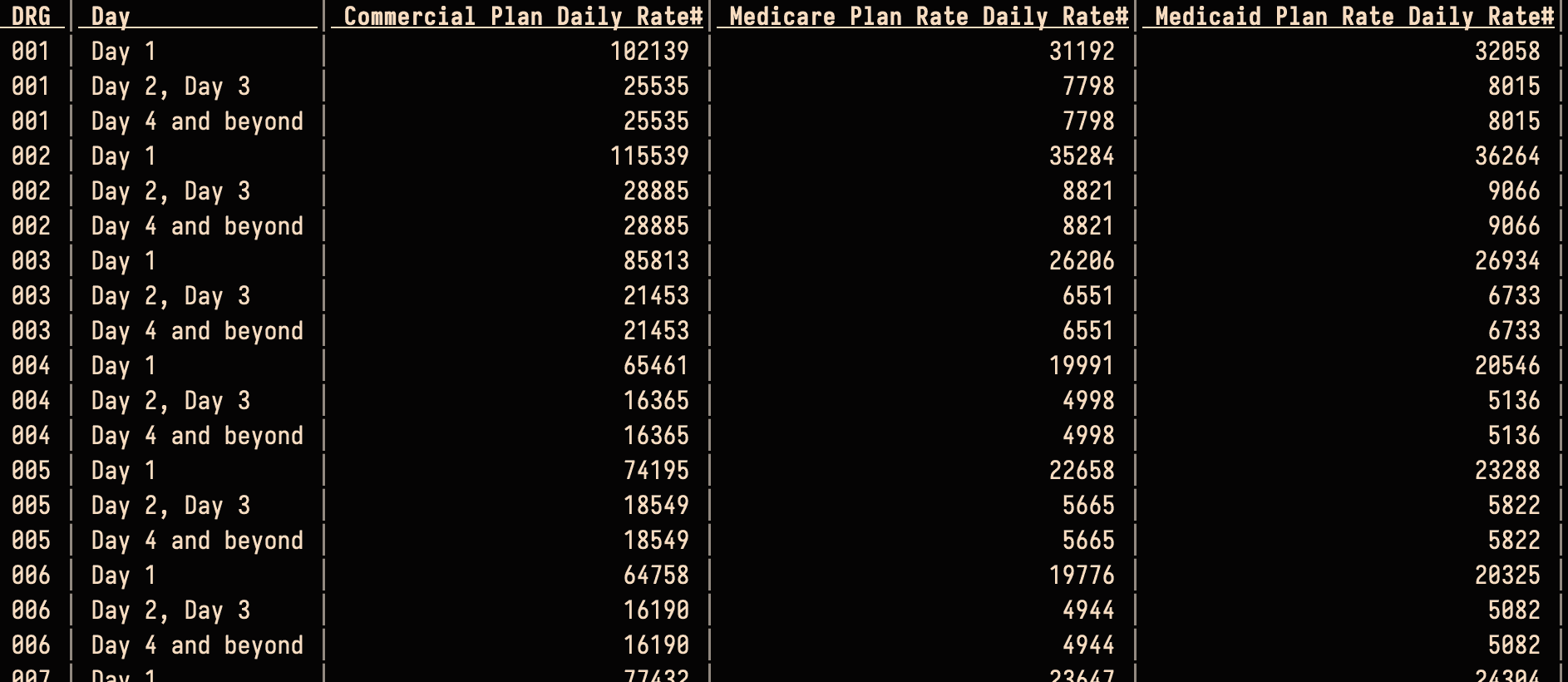 Kaiser Hospitals bill by the number of days spent in a hospital, for inpatient procedures
Kaiser Hospitals bill by the number of days spent in a hospital, for inpatient procedures
As we continue to gather new files, we're still refining our schema. Whatever we choose, it has to have these properties:
- it's understandable to beginners
- it's makes it easy to compare the transformed data to the original file
- it can accurately capture what's in the transparency files
- it can concisely capture what represents a unique "rate"
- it puts "like" with "like" (i.e. normalizes the data)
- it's easy on the disk (< 200GB)
- two people processing the same file must end up with the same row additions
Here's a subset of the fields in our table so you can see how we've narrowed down the information needed to compare rates:
hospital_ccn: there are multiple IDs for a hospital. A hospital has an EIN (which is more related to the hospital system than the hospital itself), an NPI number (though many hospitals have more than one) and even a medicare enrollment ID. We settled on the CMS Certification Number (CCN) which tends to align closest with what people consider an actual hospital.rev_code: Revenue codes tell you what department a service was billed from. The same service can vary in price when billed from different departments.internal_code: Hospitals use an internal code (or charge code, or procedure code) to talk to themselves about what was billed. This isn't the code that they send to the insurance company, but it may affect how much they bill the insurance company, and their reimbursement.code_orig: For verification purposes, the original billing code string in the dataset. For example, "MS-DRG V32 (FY 2021) 003"code_prefix: The kind of code in question (there's only one billing code per row). For "MS-DRG V32 (FY 2021) 003", this would just be "MS-DRG".code: The actual value of the code. In the above example, this would just be "003". Havingcode_orignext tocode_prefixandcodemakes it easy to check that the submitter transformed the row correctly.modifier: Only HCPCS/CPT codes can have modifiers. This is a space-separated list of two-char modifiers that may affect how the code gets billed to the insurer.ndc: The National Drug Code is a dash-separated string in one of three formats. It tells you what kind of drug it is, who made it, and its packaging.apc: Every CPT code is linked to exactly one kind of Ambulatory Patient Classification. Hospitals sometimes list the APC next to the CPT code.billing_class: Whether the portion of the billed code was done by the facility ("hospital") or by a physician ("professional)patient_class: "inpatient" or "outpatient" rates varypayer_orig: The original string that the hospital used to describe the payer or payer + plan. This might be "ANTHEM BCBS GOLD [12345]". Because hospitals refer to payers and plans without global IDs, we have to use these strings as PKs.plan_orig: The same as above, but for just the plan information, if listed separately.rate: Finally, the dollar amount listed by the hospital.
The more hospital information we get, the more we refine this schema to accommodate all the different shapes of data, and refine our pipeline.
Learn more
Building databases collaboratively can be the future of data. We've already built several unique databases that don't exist anywhere else, including a similar database of payer-negotiated rates for hospitals, housing prices, and even museum collections. If you're interested in getting involved in making healthcare pricing free for everyone, come check out our Discord or drop me a line at alec@dolthub.com.