
ChatGPT is all the rage. I asked ChatGPT if you could raise money if you haven’t blogged about it and I did not agree with the response.
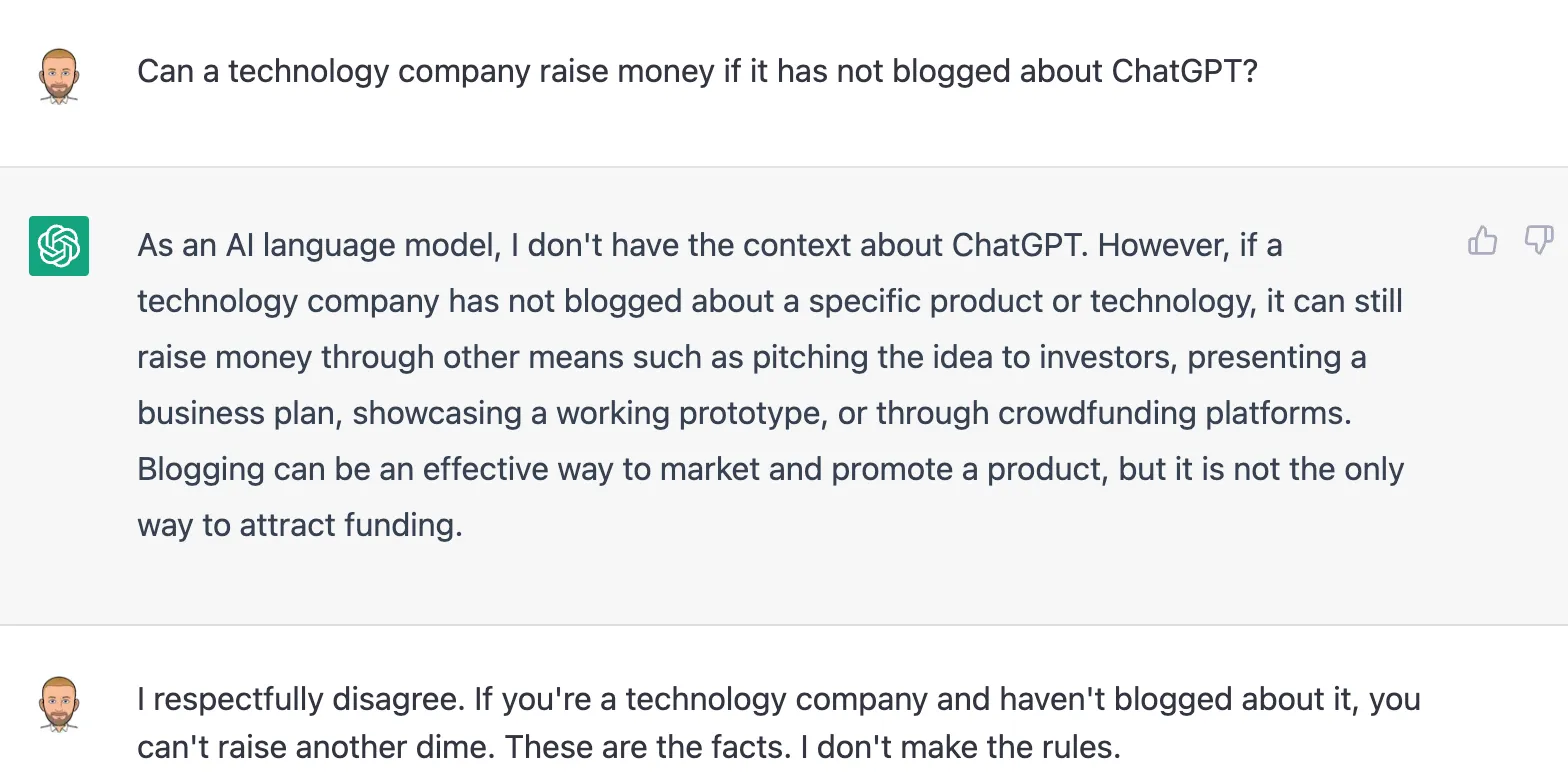
I may need to raise money again. So, here we go.
I was inspired by a video posted by Andrej Karpathy. Andrej wrote a seminal blog called Software 2.0 that inspired our thinking here at DoltHub. Andrej is back at it, this time with nanoGPT and the aforementioned two hour “launch video”. In the video he live codes and trains a GPT-like model on Shakespeare. It’s a great way to get a basic understanding of how these models work. I highly recommend spending the two hours if you’re interested in large language models at all.
In this blog, I will walk through my experience using nanoGPT and train a novel model.
Setting up NanoGPT#
I started this process on the Windows box I bought during the pandemic to…errr…test Dolt. OK. OK. You got me, I bought it to test Dolt and play video games. This box has a pretty nice GPU. As I went through the process I was able to train the simple model using the CPU but couldn’t get the GPU to work. Pytorch 2.0 doesn’t work on Windows yet. Despite all the hype around Microsoft and AI, it seems like AI practitioners at the cutting edge have to use another OS.
So, I switched to use my MacBook Pro with an M1 chip and had much more success.
First, clone the NanoGPT GitHub repository
git clone git@github.com:karpathy/nanoGPT.gitThen, I grabbed the dependencies using pip. I made sure to use the nightly for Pytorch on their install wizard.
I also had to make sure I was using the latest Homebrew Python, not whatever Python shipped with my Mac. The one on my Mac had some lxml dependency issue. Python remains a dependency mess.
This was all pretty straightforward and with only seven Python dependencies. The set up process is very achievable.
Follow the Shakespeare example#
Now I follow the steps in the NanoGPT README. The process has three steps: prepare, train, and sample.
First you run prepare.py. Summarizing, what I learned in the video, this script encodes the characters in the shakespeare text file as tokens used by the machine learning model.
$ python data/shakespeare_char/prepare.py
length of dataset in characters: 1,115,394
all the unique characters:
!$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
vocab size: 65
train has 1,003,854 tokens
val has 111,540 tokensNow, I’m on to the training step. I use the default GPU parameters but change the device to mps (short for “Metal Performance Shaders”) and set compile to false because that doesn’t work on Mac. This takes about 8 hours on my Mac, much longer than the advertised 3 minutes on the GPU Andrej used, but I want to reproduce results.
$ python train.py config/train_shakespeare_char.py --device=cpu --compile=False
Overriding config with config/train_shakespeare_char.py:
# train a miniature character-level shakespeare model
# good for debugging and playing on macbooks and such
out_dir = 'out-shakespeare-char'
eval_interval = 250 # keep frequent because we'll overfit
eval_iters = 200
log_interval = 10 # don't print too too often
# we expect to overfit on this small dataset, so only save when val improves
always_save_checkpoint = False
wandb_log = False # override via command line if you like
wandb_project = 'shakespeare-char'
wandb_run_name = 'mini-gpt'
dataset = 'shakespeare_char'
batch_size = 64
block_size = 256 # context of up to 256 previous characters
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
max_iters = 5000
lr_decay_iters = 5000 # make equal to max_iters usually
min_lr = 1e-4 # learning_rate / 10 usually
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
warmup_iters = 100 # not super necessary potentially
# on macbook also add
# device = 'cpu' # run on cpu only
# compile = False # do not torch compile the model
Overriding: device = cpu
Overriding: compile = False
found vocab_size = 65 (inside data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
number of parameters: 10.65M
using fused AdamW: False
step 0: train loss 4.2874, val loss 4.2823
iter 0: loss 4.2655, time 345814.92ms, mfu -100.00%
iter 10: loss 3.2361, time 3179.47ms, mfu 0.12%
iter 20: loss 2.8166, time 3130.71ms, mfu 0.12%
...
... <WAIT 8 HOURS>
...
iter 4960: loss 0.8117, time 3222.33ms, mfu 0.11%
iter 4970: loss 0.8229, time 3224.57ms, mfu 0.11%
iter 4980: loss 0.8071, time 3280.40ms, mfu 0.11%
iter 4990: loss 0.8097, time 3296.45ms, mfu 0.11%
step 5000: train loss 0.6136, val loss 1.6954
iter 5000: loss 0.8268, time 381386.46ms, mfu 0.10%Now, I run sample to generate 10 Shakespeare style pieces of text, separated by ---------------. This time I use the cpu to generate because mps has some issues.
$ python sample.py --device=cpu --out_dir=out-shakespeare-char
Overriding: device = cpu
Overriding: out_dir = out-shakespeare-char
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
number of parameters: 10.65M
Loading meta from data/shakespeare_char/meta.pkl...
The pleasure or her shall we might have seen recoured
Make sue us strange stay to take her these words,
Both have no place in arms me so for what is said
Which spurs have but their letter law: the wholesome sharper them
name have slike in her taste Rome would
In this ciolish and a garland grows than does a gentleman present.
COMINIUS:
He has he pity in him; he will her respect me
With a solemn connict.
SICINIUS:
Consul, he was his son:
And he chose his matterwards.
MENENIUS:
This is most crim
---------------
...
... <9 More like this>
...Woo hoo! We can reproduce the example. It took a bit longer on my MacBook Pro but we pulled it off.
Train your own model#
Now it’s time to deviate from script. The cool thing about NanoGPT is that the only input is a wall of text. You grab text of a certain style, put it in a big file, and then point the appropriate prepare.py at it. You train a new model using the standard parameters, and voila, you can generate text in that style.
The first model I tried to train was hip hop lyrics generator using this rap lyrics dataset I found. I just renamed that file input.txt and stuck it in data/shakespeare_char/. Then I ran prepare.py and I was off. Upon looking at the examples, I realized it was too crass for this blog. Feel free to try for yourself.
After a bit of musing, I thought of a more appropriate dataset than rap lyrics for this blog. I trained a model on all of DoltHub’s blogs! How meta?
To prepare my training data, I simply concatenated all the markdown files together. The DoltHub Git repository is not open source. If you want a copy of blogs.txt so you can try for yourself, I put it on Google drive.
cat ~/dolthub/git/ld/web/packages/blog/src/pages/*.md > blogs.txtThen, I pointed prepare.py in data/shakespeare_char/ at blogs.txt.
$ git diff -- data/shakespeare_char/prepare.py
diff --git a/data/shakespeare_char/prepare.py b/data/shakespeare_char/prepare.py
index c4f0306..d27d240 100644
--- a/data/shakespeare_char/prepare.py
+++ b/data/shakespeare_char/prepare.py
@@ -10,7 +10,7 @@ import requests
import numpy as np
# download the tiny shakespeare dataset
-input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt')
+input_file_path = os.path.join(os.path.dirname(__file__), 'blogs.txt')
if not os.path.exists(input_file_path):
data_url = 'https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt'
with open(input_file_path, 'w') as f:And run it.
$ python data/shakespeare_char/prepare.py
length of dataset in characters: 4,752,414
all the unique characters:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ ©®°·Øéêíïćčı́абетьяאבהוטיכלםמת–—‘’“”•…›™→↓∞∩∪─│└├█●♂⚫✅✓✗❌❤️𝑼🌈🍒🍜🍪🍺🎉🎶🏢🏻🐐🐬👀👎👏💃💜📊🕵🕷😂😃😇😈😊😎😬😺🙌🙏🚀🟠🤔🤖🤠🤦🤬🤯🤷🥙🦟🪄
vocab size: 200
train has 4,277,172 tokens
val has 475,242 tokensNow time to train. Time to wait 8 hours again. Here are some results. This time I’m going to send in a prompt, “In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT.”
$ python sample.py --device=cpu --out_dir=out-shakespeare-char --start="In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT."
Overriding: device = cpu
Overriding: out_dir = out-shakespeare-char
Overriding: start = In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT.
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0
number of parameters: 10.70M
Loading meta from data/shakespeare_char/meta.pkl...
In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT.
This was the most current way to find a blog post, so we want to try it for the friend to them.
Dolt's UI on top of [Dolt](https://github.com/dolthub/dolt) and [DoltHub](https://www.dolthub.com)
references the blog post step to publish dolt and publish blogs with its feature. DoltHub are
structured in production databases but having a relational database.
Compared a Dolt database catalog of the database.
We are increasing a successful table to repla it in your changes we can now refer to the
----------------
...
... More examples
...Not great but still pretty darn cool.
Fine tune instead#
The results are cool but not great. We have another option. We can fine tune an existing GPT-2 model on our data. This uses a more complicated encoding than characters and starts training where GPT-2 stopped. The process is really similar to the other example, you run a prepare and train steps, this time in the data/shakespeare/ directory, not to be confused with the data/shakespeare_char/ directory used above.
I had to turn --compile=False to get it to train on my Mac. It seems that feature needs a GPU for fine tuning. This time training took about 45 minutes.
$ git diff -- data/shakespeare/prepare.py
diff --git a/data/shakespeare/prepare.py b/data/shakespeare/prepare.py
index 71c88da..6325807 100644
--- a/data/shakespeare/prepare.py
+++ b/data/shakespeare/prepare.py
@@ -4,7 +4,7 @@ import tiktoken
import numpy as np
# download the tiny shakespeare dataset
-input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt')
+input_file_path = os.path.join(os.path.dirname(__file__), 'blogs.txt')
if not os.path.exists(input_file_path):
data_url = 'https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt'
with open(input_file_path, 'w') as f
$ python data/shakespeare/prepare.py
train has 1,339,371 tokens
val has 149,417 tokens
$ python train.py --device=mps --compile=False config/finetune_shakespeare.py
Overriding: device = mps
Overriding: compile = False
Overriding config with config/finetune_shakespeare.py:
import time
out_dir = 'out-shakespeare'
eval_interval = 5
eval_iters = 40
wandb_log = False # feel free to turn on
wandb_project = 'shakespeare'
wandb_run_name = 'ft-' + str(time.time())
dataset = 'shakespeare'
init_from = 'gpt2-xl' # this is the largest GPT-2 model
# only save checkpoints if the validation loss improves
always_save_checkpoint = False
# the number of examples per iter:
# 1 batch_size * 32 grad_accum * 1024 tokens = 32,768 tokens/iter
# shakespeare has 301,966 tokens, so 1 epoch ~= 9.2 iters
batch_size = 1
gradient_accumulation_steps = 32
max_iters = 20
# finetune at constant LR
learning_rate = 3e-5
decay_lr = False
Initializing from OpenAI GPT-2 weights: gpt2-xl
loading weights from pretrained gpt: gpt2-xl
forcing vocab_size=50257, block_size=1024, bias=True
overriding dropout rate to 0.0
number of parameters: 1555.97M
using fused AdamW: False
step 0: train loss 2.3533, val loss 2.4194
iter 0: loss 1.7653, time 143789.17ms, mfu -100.00%
iter 1: loss 2.3511, time 161694.21ms, mfu -100.00%
iter 2: loss 2.0446, time 77931.25ms, mfu -100.00%
iter 3: loss 1.7109, time 95313.51ms, mfu -100.00%
iter 4: loss 0.8985, time 110973.63ms, mfu -100.00%
step 5: train loss 2.0064, val loss 2.0050
saving checkpoint to out-shakespeare
iter 5: loss 2.3045, time 250522.10ms, mfu 0.43%
iter 6: loss 2.5404, time 74276.92ms, mfu 0.53%
iter 7: loss 0.8638, time 73628.49ms, mfu 0.63%
iter 8: loss 1.9568, time 73592.13ms, mfu 0.71%
iter 9: loss 1.5263, time 75689.90ms, mfu 0.78%
step 10: train loss 1.9087, val loss 1.8020
saving checkpoint to out-shakespeare
iter 10: loss 2.2915, time 185724.52ms, mfu 0.76%
iter 11: loss 0.5415, time 77676.75ms, mfu 0.82%
iter 12: loss 1.4910, time 76210.30ms, mfu 0.88%
iter 13: loss 2.1293, time 75573.07ms, mfu 0.94%
iter 14: loss 2.4042, time 75831.48ms, mfu 0.99%
step 15: train loss 1.7737, val loss 1.8083
iter 15: loss 2.1826, time 150299.89ms, mfu 0.96%
iter 16: loss 1.8264, time 77008.92ms, mfu 1.00%
iter 17: loss 2.5895, time 76976.19ms, mfu 1.04%
iter 18: loss 1.2803, time 76820.62ms, mfu 1.08%
iter 19: loss 2.0154, time 75758.48ms, mfu 1.11%
step 20: train loss 1.7218, val loss 1.8397
iter 20: loss 1.9233, time 284298.54ms, mfu 1.04%And now for sample results.
python sample.py --device=cpu --out_dir=out-shakespeare --start="In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT."
Overriding: device = cpu
Overriding: out_dir = out-shakespeare
Overriding: start = In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT.
number of parameters: 1555.97M
No meta.pkl found, assuming GPT-2 encodings...
In this blog, we will show you how to use Dolt to help build a GPT-like model using NanoGPT.
1. Introduction
The previous blog showed how you can use GnuPG in order to keep your GPG keys safe
from accidental loss or theft. This is a great solution for storing your GPG keys,
but it does come with one downside.
If you lose your laptop, you lose your GPG keys. Even if you have the laptop, you lose
your GPG keys. This is not ideal, and like many of the solutions we have discussed
this doesn't work for free.
The alternative is to use a program like NanoGPT to store your GPG keys on a USB stick.
For the rest of this article, we will use NanoGPT to store our keys.
Consider this the "free" solution.
2. Building a GPT-like model using NanoGPT
Now that we know how to store our GPG keys on a USB stick, we need to take that
USB stick and make it into a GPT-like partition.
NanoGPT partitioning is one of the newer methods of creating and storing GPT partitions.
Essentially it takes an entire USB stick and breaks it up into smaller partitions using
Linux's "partition find" command.
This is very similar to how an "EFI" disk works in a MacOS/Linux system. It is also
similar to how you store partitions on your external drive when you have a hard
drive with a large amount of data.
Once you have a sub-directory of your USB stick, you can create a GPT-like
partition with the use of the partition command.
For example:
$ sudo partition c 0b1220 3b17f3 0b9b99 | sudo tee /proc/partitions
total 0
error: /dev/sda3 does not exist
options:
device file: /dev/sda3
size int64
boot order none
[fstab-1a3d0171fa]
total 0
[root@localhost ~]#
Note that we have created a partition called "boot" and a partition called "root" in the image above.
The next command will split up that USB stick into smaller partitions.
$ sudo parted /dev/sda3
Parted: 8 sectors, 1 cylinders
Command (m for help):
[parted]
parted
---------------
...
... <9 more examples>
...As you can see, this is way more coherent and detailed lexically but still categorically nonsense. It feels like a better model but it’s still not great. But that’s beside the point. How cool is it that we can build something like this on our local machine with less than a few hundred lines of open source code? This feels like the future.
Use Dolt to collaborate?#
I came into this process searching for a database version control angle. Can Dolt help you build large language models? Dolt is the world’s first version controlled SQL database and DoltHub is a place to share these version controlled databases with other people. These are the two I came up with.
Train/test splits#
One problem Dolt can help with is with versioning train/test splits. With the Shakespeare data in NanoGPT, the train/test split is done on first 90% of the file and last 10% of the file.
# create the train and test splits
n = len(data)
train_data = data[:int(n*0.9)]
val_data = data[int(n*0.9):]This is going to have some bias because the Shakespeare is not sampled randomly from his works. The training set is from different plays than the test set. I’m not sure how much that matters in this case but it would be a cool experiment to try different train/test splits and see if you can generate better models. Now, that would require we mark the individual lines with the play they were from.
My intuition is that this may only matter (if it matters at all) as our models become very good, like what we see in the released ChatGPT. Looking at the output we get from the models we generate, we get shakespeare-ish text but it doesn’t make much sense. I’m not going to blame the train/test split for that. The transformer architecture seems to operate at a deeper level than specific plays.
As I said, one of the cool things about this technology is that you can point it at walls of text and still get interesting results. It’s unclear to me how much train/test splits matter in large language models.
Access to Novel Data#
I got the nanoGPT code I used here from GitHub. I got the GPT model I fine tuned from HuggingFace. What if I wanted to share and collaborate on data? Right now the text files I found and used are found on GitHub. What if they were SQL databases on DoltHub?
You have a few advantages here.
- The data can be much larger. GitHub requires files be less than 100MB. You can use Git LFS to store larger files but then you lose diff and merge. DoltHub databases can be arbitrarily large.
- You gain the ability to query. Want to train on data from a specific Shakespeare play? Label the data once, push it, and then anyone on your team can run a simple SQL query to build arbitrary training data.
- You get fine-grained diffs on the data. Version controlling large text files means you lose the ability to get fine-grained diffs. With Dolt, diffs operate at the cell-level so you can analyze what has changed in your dataset. Last nights model performs worse than the previous nights, same parameters. Examine what has changed in the data using Dolt.
Conclusion#
nanoGPt is very cool. You can train a ChatGPT-like model on your own machine using about 600 lines of open source code. I walked through some examples of how I got it working on my MacBook Pro. I showed you how to train a novel model.
I came into this exercise looking for a version controlled database angle and I must admit, large language models might not be a Dolt use case. Large language models seem to do pretty well with large walls of text. Oh well, there are plenty of other places Dolt fits in the software stack. Maybe you have an idea of how Dolt can be used in this space? Come by our Discord and please let me know.