
Dolt is the first fully version controlled relational database. Every Git command is exposed as a SQL function, allowing users to efficiently branch, diff, and merge tables.
We recently added anti and semi join support. ANTI_JOIN and SEMI_JOIN are special operators drawn from a larger universe of subquery optimizations that perform set existence checks. We will explain partial joins and their performance characteristics more later.
As an example, this query now “unnests” the IN_SUBQUERY and EXISTS filters into ANTI_JOIN and SEMI_JOIN:
select * from table1
where id NOT IN (select id from table2) and
EXISTS (select id from table3 where id = table1.id)
+---------------------------------+
| plan |
+---------------------------------+
| AntiJoin |
| ├─ (table1.id = applySubq0.id) |
| ├─ SemiJoin |
| │ ├─ (table3.id = table1.id) |
| │ ├─ Table |
| │ │ └─ name: table1 |
| │ └─ Table |
| │ ├─ name: table3 |
| │ └─ columns: [id] |
| └─ TableAlias(applySubq0) |
| └─ Table |
| ├─ name: table2 |
| └─ columns: [id] |
+---------------------------------+Evaluating these operations as joins can lower memory usage and latency of customer queries by more than 10x in many circumstances. To get started, just use IN, EXISTS, or comparison subquery expressions. This blog will be an intro into the internals of subquery unnesting.
Background#
SQL queries are rarely written in the most efficient and compact forms. The same way your source code is written to be read by humans and compiled to an optimal format for computers, SQL queries are compiled and simplified for execution. Whether because of ORMs, or intentionally organizing big queries into logical groups, we think in a different frame of reference than is optimal for SQL engines. As a result one of the important functions of a SQL optimizer is to simplify complex operators into constituent components. A trivial example might look like removing redundant filters:
select * from table1 where id = 1 or id = 1;
=>
select * from table1 where id = 1;You also might (correctly) question whether there is any performance difference after simplification. But SQL is a surprising source of emergent behavior. Subtle interactions and indirections can quickly snowball into NP complete problems.
Joins are the main source of trouble for query simplification. A query on one table will never be as compute intensive as reading multiple tables. We have done a lot of work improving join planning, but “multi-relational” SQL queries can be subdivided and hidden via subqueries. We can hide tables in queries all we want, but the result is still a multi-table indirect join. We have not attempted to optimize between subquery scopes before now, which has caused headaches for some customers.
Consider the query below:
select a.* from table1 a join table2 b on a.id = b.id;This is a two table join. A lack of indexes might prevent it from being fast, but it is standard and close to the optimal execution format. We can enumerate and cost all join orders, index selections, and physical operators (MERGE, HASH, INNER, LOOKUP).
The next query is equivalent, but reads two tables that communicate only via a subquery:
select * from table1 a where id in (select id from table2)Before SEMI_JOIN, this query was forced into one execution strategy: load table2 into a hash map and probe while scanning table1.
Lets look at a performance profile for the explicit vs implicit join:
select count(*) from table1;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
select count(*) from table2;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
select count(a.*) from table1 a join table2 b on a.id = b.id;
+------------+
| count(a.*) |
+------------+
| 10 |
+------------+
________________________________________________________
Executed in 65.65 millis fish external
usr time 51.86 millis 89.00 micros 51.77 millis
sys time 24.26 millis 555.00 micros 23.70 millis
select count(*) from table1 a where id in (select id from table2)
+------------+
| count(a.*) |
+------------+
| 10 |
+------------+
________________________________________________________
Executed in 891.40 millis fish external
usr time 1077.81 millis 96.00 micros 1077.71 millis
sys time 131.76 millis 493.00 micros 131.27 millis
To summarize, table1 has 10 rows and table2 has 1 million rows. The
explicit join takes ~100 milliseconds, and the implicit join takes ~1
second, timed using dolt v0.50.0. The queries are equivalent but the
first is 10x faster than the second.
If we re-run the same comparison but with 50 million rows in table2, the LOOKUP_JOIN still takes ~100 milliseconds, but the IN_SUBQUERY takes 3 minutes! Index joins are fast, we just have to peel back a few layers sometimes to find them.
SemiJoin and AntiJoin#
Dolt now internally converts the second query into the first. In dolt
v0.52.16, the performance is the same between the two queries:
select a.* from table1 a join table2 b on a.id = b.id;
...
________________________________________________________
Executed in 75.84 millis fish external
usr time 64.72 millis 95.00 micros 64.63 millis
sys time 28.01 millis 474.00 micros 27.53 millis
select * from table1 a where id in (select id from table2);
________________________________________________________
Executed in 75.84 millis fish external
usr time 64.72 millis 95.00 micros 64.63 millis
sys time 28.01 millis 474.00 micros 27.53 millisThis is because we convert the IN_SUBQUERY into a SEMI_JOIN. A SEMI_JOIN is a partial join that selects rows from a left table only if a match is found in the right table. Rows from the right table are not returned. Here is the execution plan structured as a SEMI_JOIN:
explain select * from table1 a
where id IN (select id from table2);
+------------------------------------+
| plan |
+------------------------------------+
| SemiLookupJoin |
| ├─ (a.id = applySubq0.id) |
| ├─ TableAlias(a) |
| │ └─ Table |
| │ └─ name: table1 |
| └─ TableAlias(applySubq0) |
| └─ IndexedTableAccess(table2) |
| ├─ index: [table2.id] |
| └─ columns: [id] |
+------------------------------------+The algorithm looks something like:
-
Choose a row from the left side.
-
Index lookup the corresponding row in table2.
-
If we find any match, return the left row.
-
If we do not find a match, continue to the next left row.
The result is the same as the IN_SUBQUERY, except now we are using a join. And because it is a join, we can apply regular join optimizations, like applying a lookup to more quickly find a match.
ANTI_JOIN is the inverse of SEMI_JOIN: we return left rows only if no match is found in the right table. ANTI_JOIN benefits equally from the ability to use a point lookup.
explain select a.* from table1 a
where id NOT IN (select id from table2);
+------------------------------------+
| plan |
+------------------------------------+
| AntiLookupJoin |
| ├─ (a.id = applySubq0.id) |
| ├─ TableAlias(a) |
| │ └─ Table |
| │ └─ name: table1 |
| └─ TableAlias(applySubq0) |
| └─ IndexedTableAccess(table2) |
| ├─ index: [table2.id] |
| └─ columns: [id] |
+------------------------------------+Joins are a strength that we want to lean into. Joins should greedily absorb nested subqueries. We can reorder joins, infer transitive filter closures, choose specialized operators that take advantage of indexes, hash maps, and sorting. Aggregating relations into one join tree finds one global optimum, rather than scattered local maxima. All of these have significant effects on the memory and runtime of subqueries. And funneling operators into joins lets us focus time and energy on optimizing a narrow part of the codebase, rather than several disparate operators.
Memory effects#
IN_SUBQUERY expressions are saved in-memory to avoid re-computing. This can be advantageous, but usually locks us into executing SUBQUERY_INs as HASH_JOINs. Lets consider the query from before:
select * from table1 where id in (select id from table2)But now table2 is 50M rows. Here is what the memory profile looks like:
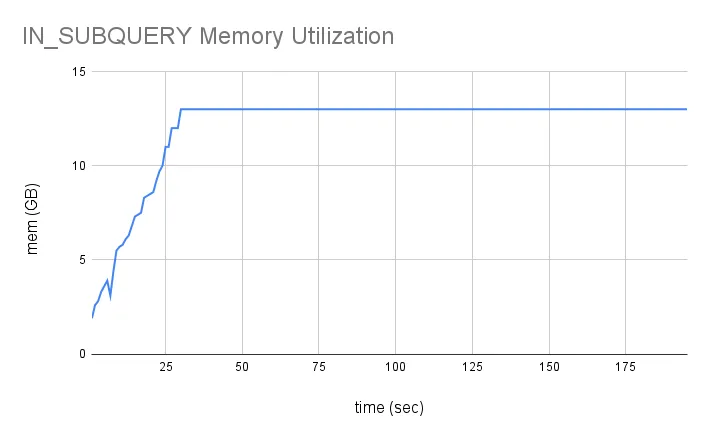
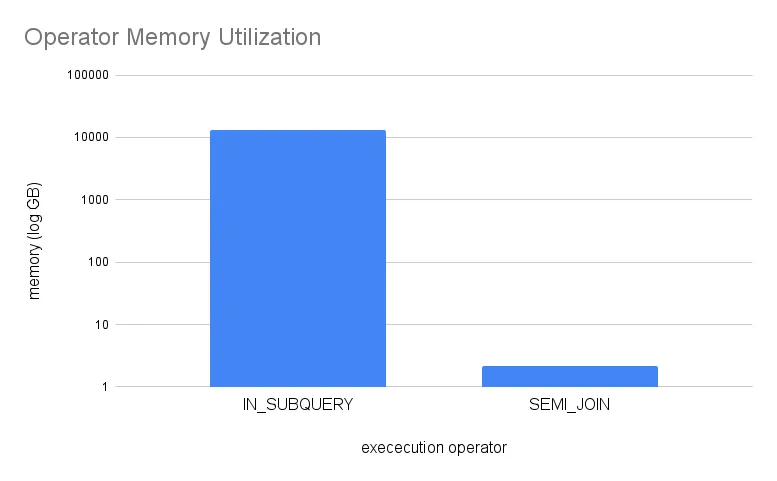
The old Dolt loads table2 into memory as a mandatory default. Sometimes we do want a memory heavy operator, but it should be considered against trade-offs during join costing. We’ve had customers even OOM due to subquery memory inflexibility.
The SEMI_JOIN only uses 2MB of memory. That is 3 orders of magnitude, or 1000x less than reading all of table2 into memory.
This is an extreme example chosen to highlight the difference. The important point is that a join tree will only use as much memory as is necessary to read chunks from disk, maintain the execution stack, and spool values to clients.
Correlated subqueries#
Lastly, we will touch on a thread of future work. The most interesting kinds of subquery expressions depend on the outer scope. Consider a common warehouse query used in the database literature:
select c custkey from customer c
where 1000000 >
(select sum(o.totalprice)
from orders o
where o.custkey = c.custkey)This query finds a list of customers whose total spend exceeds $1
million. This “correlated subquery” is more complicated than our
previous IN/EXISTS queries. We cannot currently optimize this
expression because the orders subquery takes a customer row as a dependency,
blocking a join order rearrangement. The only way to evaluate
the orders subquery is by first reading a fresh c.custkey. The
orders subquery will be evaluated wholly every customer row.
We hope to optimize correlated subqueries in the near future. The process is similar to those used for SEMI_JOIN and ANTI_JOIN. We convert correlated subquery expressions into join equivalents that enforce the dependency ordering. The intermediate representation (IR) of the join facilitates further simplification, unnesting, and rearrangement to find the fastest global join path.
Summary#
We added SEMI_JOIN and ANTI_JOIN support for Dolt. We noted how these operators convert subquery expressions like IN, EXISTS, and comparisons into joins. We dug into some of the ways that SEMI_JOIN and ANTI_JOIN are preferable to subqueries. In the future we wish to convert all subquery expressions into join trees. We have more work to do, but joins are a strength that we want to continue to lean into.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!