
Dolt is a version controlled SQL database that you can branch, merge, and diff. Dolt stores data in a prolly tree to efficiently support these operations, which can come with write overhead and use a lot of storage.
You can reduce the amount of garbage stored on disk using garbage collection (dolt gc). We first released garbage
collection in 2020, and then made it faster using
generational garbage collection over a year ago. Until
recently, we only supported garbage collection using the CLI and did not have online
garbage collection support for a dolt sql-server. This feature
moved to the top of our list when we launched Hosted Dolt, a
cloud-hosted Dolt database similar to AWS RDS or MariaDB
SkySQL.
This week we launched a first version online garbage collection, which can be manually
started using call dolt_gc, the dolt gc
procedure.
This includes full garbage collection, which uses generational garbage collection to
remove all unreferenced chunks from the database, as well as a shallow GC option, which
a faster but less thorough garbage collection that prunes unreferenced table files. This
first version of garbage collection will block all writes to the database while GC is in
process and can only be started using the procedure. Automatic online garbage collection
is coming soon.
How garbage collection works#
For more detailed information about how garbage collection works in Dolt check out these articles:
To summarize, writes to Dolt can result in multiple chunks of the prolly tree being rewritten, which writes a large portion of the tree. When you perform write operations without committing or delete a branch containing novel chunks garbage is created.
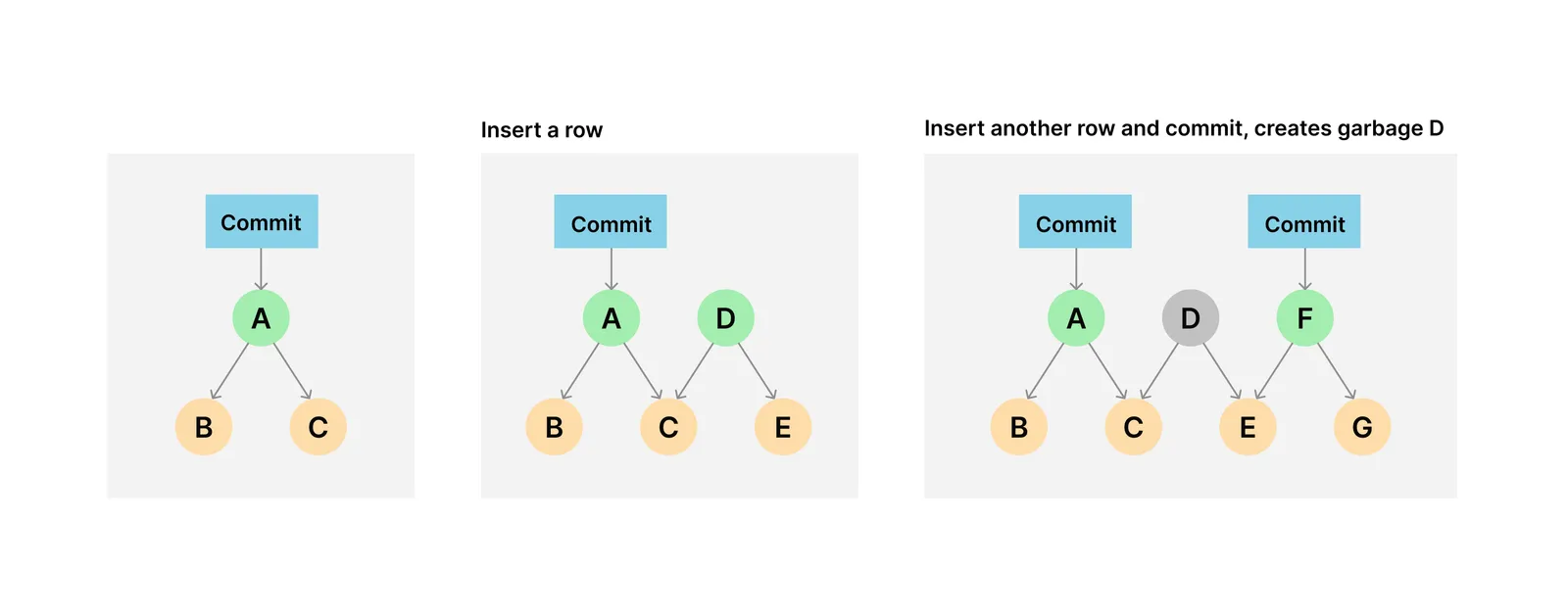
Originally, running dolt gc took every branch and its working set and iterated through
each referenced chunk. All referenced chunks were copied to a new table file, the old
table files were deleted, and replaced with the new table file. This could be very
expensive for large databases.
We implemented generational garbage collection to improve this, which instead splits storage into two categories: old generation (oldgen) and new generation (newgen). All chunks start in newgen. When garbage collection is run, we iterate through every branch and the chunks they reference, ignoring referenced chunks and its children if found in oldgen. All chunks found that are not in oldgen are written to a file, which is added to oldgen.
Once that process is done, we walk the chunks referenced by the working set, again ignoring chunks and its children if found in oldgen. Chunks that are only in newgen are written to a file, which becomes the source of newgen chunks. All other newgen files are deleted.
New edits result in new chunks being added to newgen. Running dolt gc again will be very
fast since it operates on a smaller set of data as most chunks are already in oldgen and
will be ignored.
How online garbage collection works#
Online garbage collection is a way to garbage collect table files while a dolt sql-server is running. Using the previous implementation of garbage collection on a
running sql server couldn’t work due to concurrent writes potentially referencing garbage
collected chunks. We needed to make some changes to Dolt to ensure online garbage
collection leaves the database in a useable state.
Shallow GC#
Online shallow GC was relatively straightforward to
implement. Shallow garbage collection is a
less complete but faster garbage collection that prunes unreferenced table files. Each
Commit call creates a new table file. Once the maximum number of table files is
exceeded, we conjoin them, which can leave behind some table file garbage.
During shallow garbage collection we iterate through all table files and remove any that aren’t referenced in the manifest.
The two issues we needed to solve for online shallow GC were:
- Preventing newly created table files from being garbage collected accidentally, and
- Gracefully failing if a table file doesn’t exist before writing the new contents to the manifest.
We solved #1 by skipping any table file in the pruning process that has been updated more recently than the manifest. The second was solved by adding a check that all tables exist in the chunk source before updating the manifest.
Online shallow GC is available using the stored procedure for GC:
CALL DOLT_GC('--shallow');Full GC#
Background#
The main challenge to implementing full online GC was how to handle concurrent writes while garbage collection was running. In order to implement Git-like functionality in a SQL database, Dolt stores table data in a Merkle DAG, which looks like this:
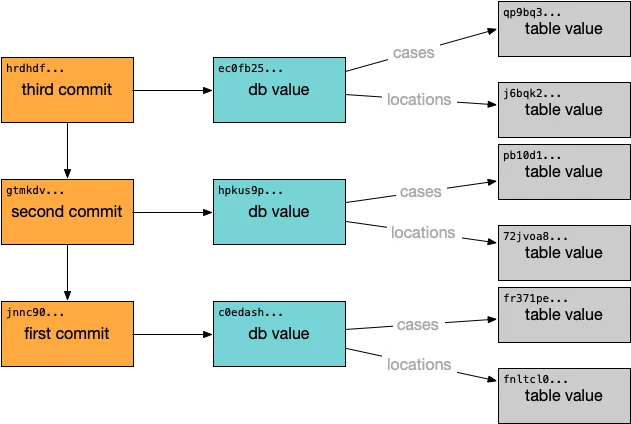
Each table value includes the schema for the table and the table data, encoded in a Prolly-tree. Prolly-trees allow efficient structural sharing of table data across various versions of the data. Performing write operations is equivalent to writing new Prolly-trees. As new trees are constructed, they will write only the new chunks that are needed and structurally share where possible.
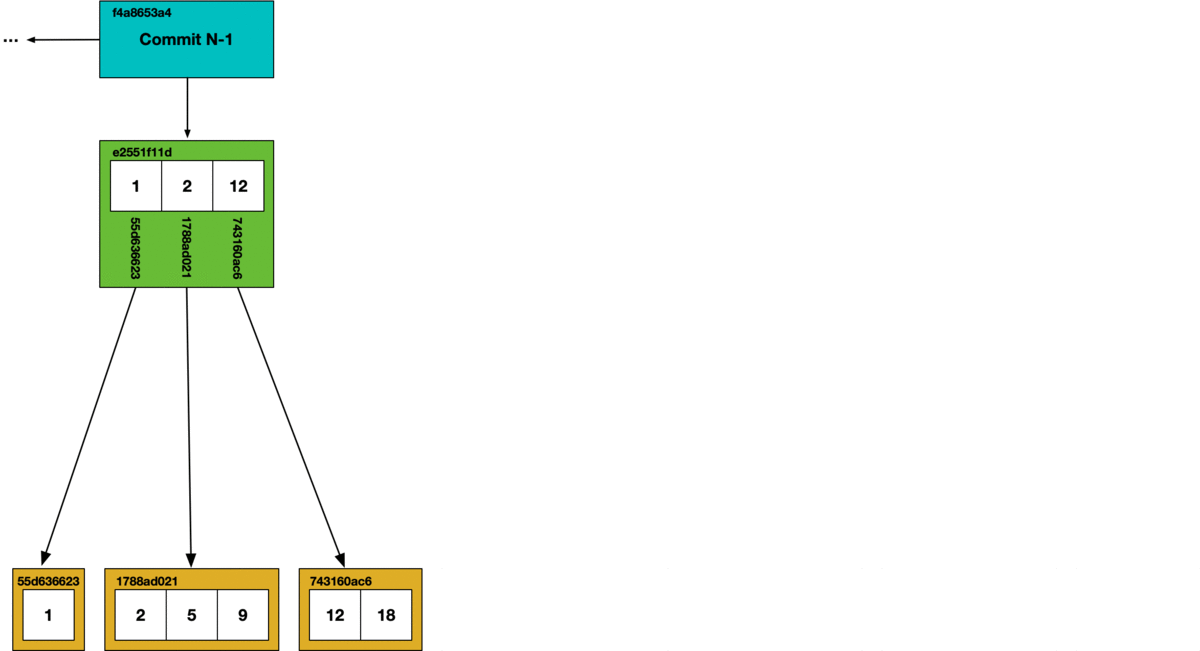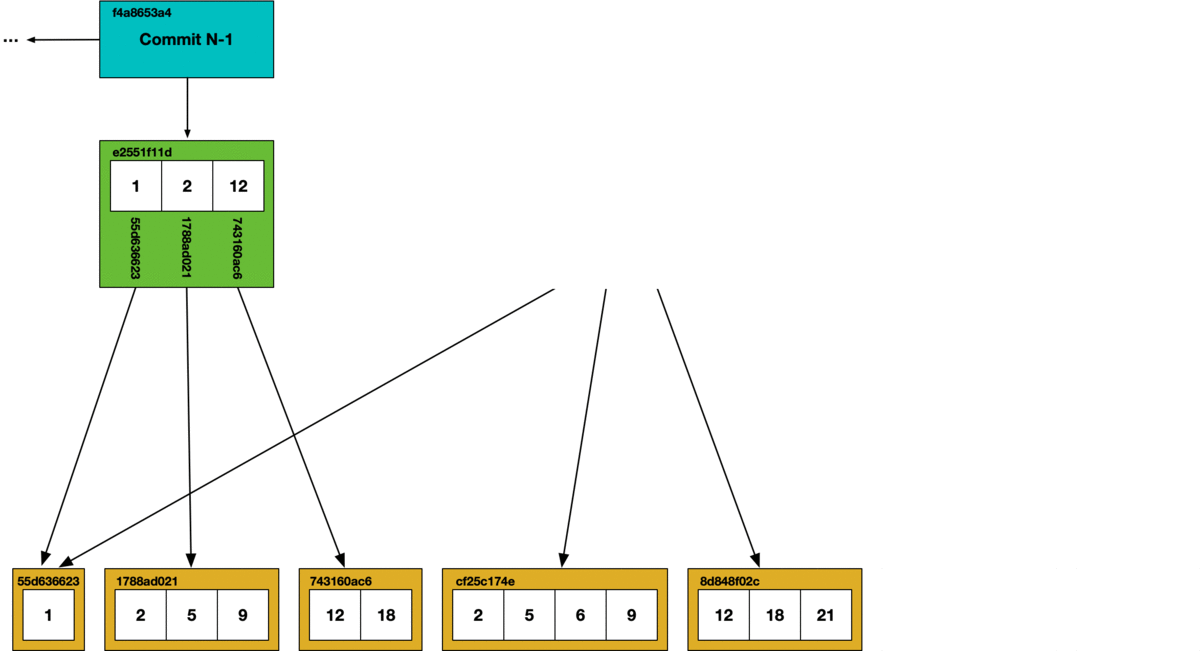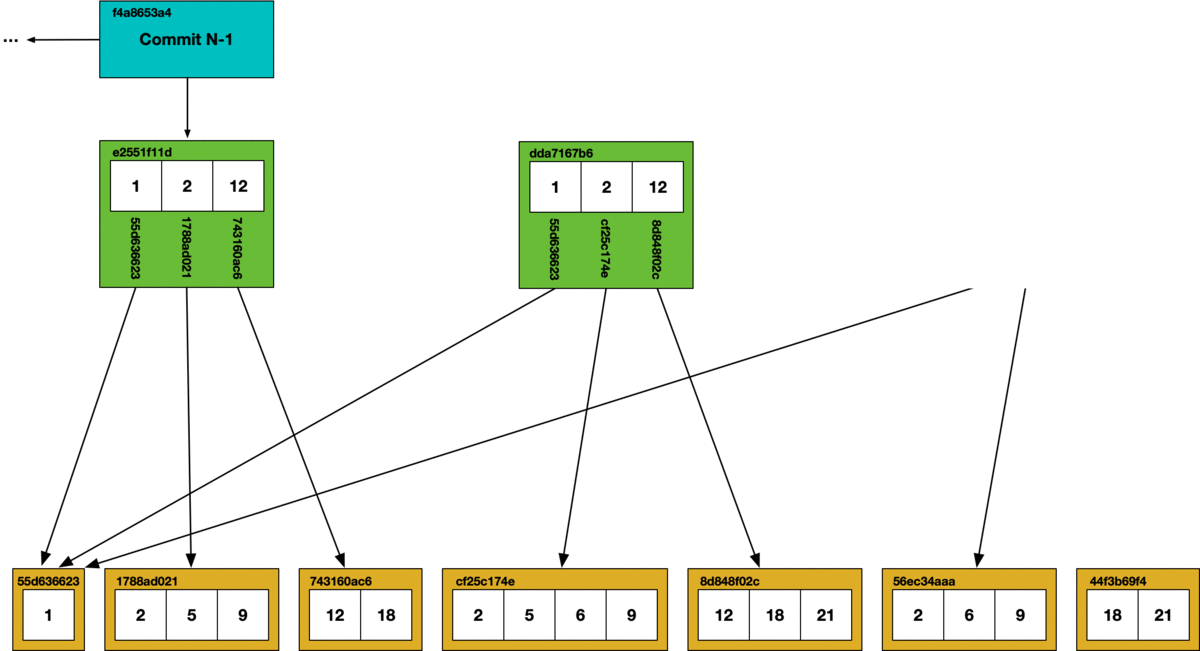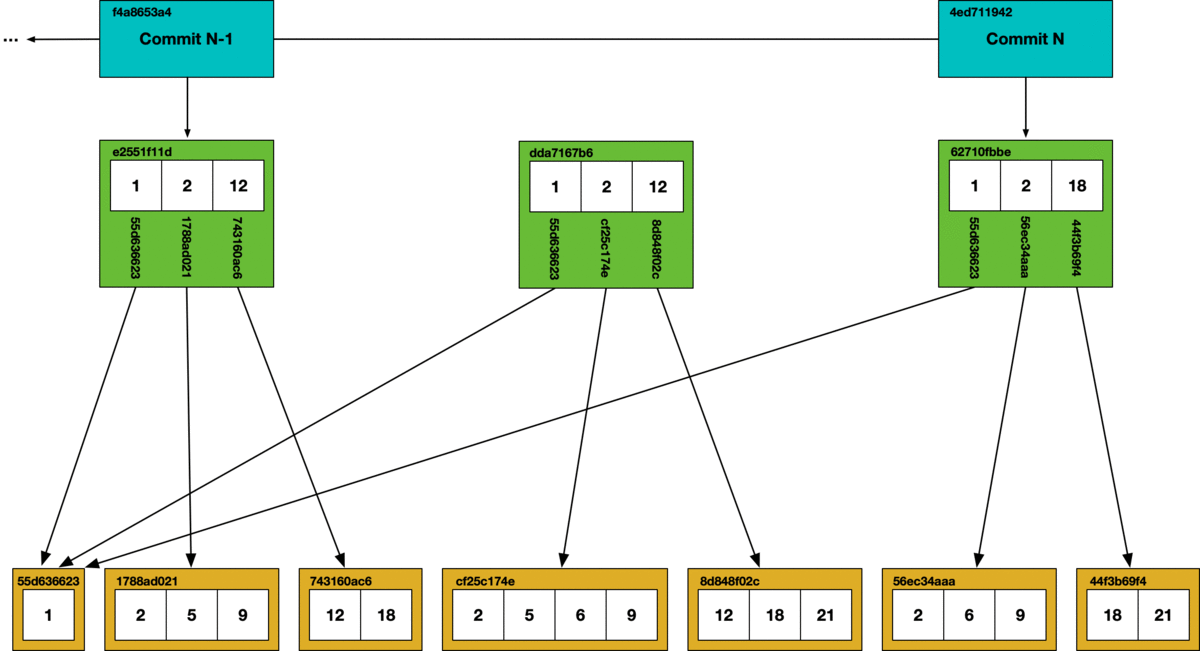
During garbage collection, we use a mark and sweep algorithm. Each chunk that is reached in the commit graph has its hash marked as safe, all other chunks are deleted from the store.
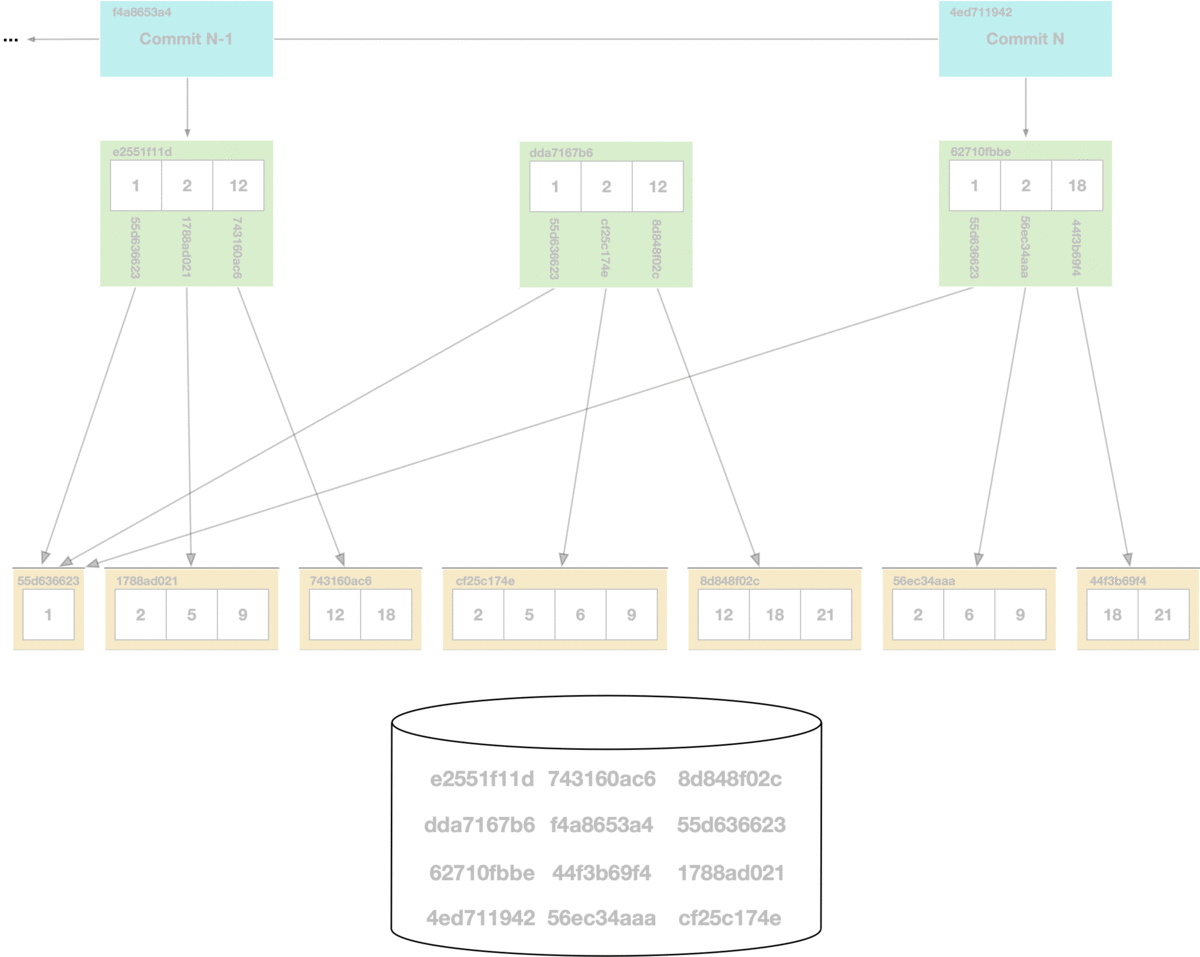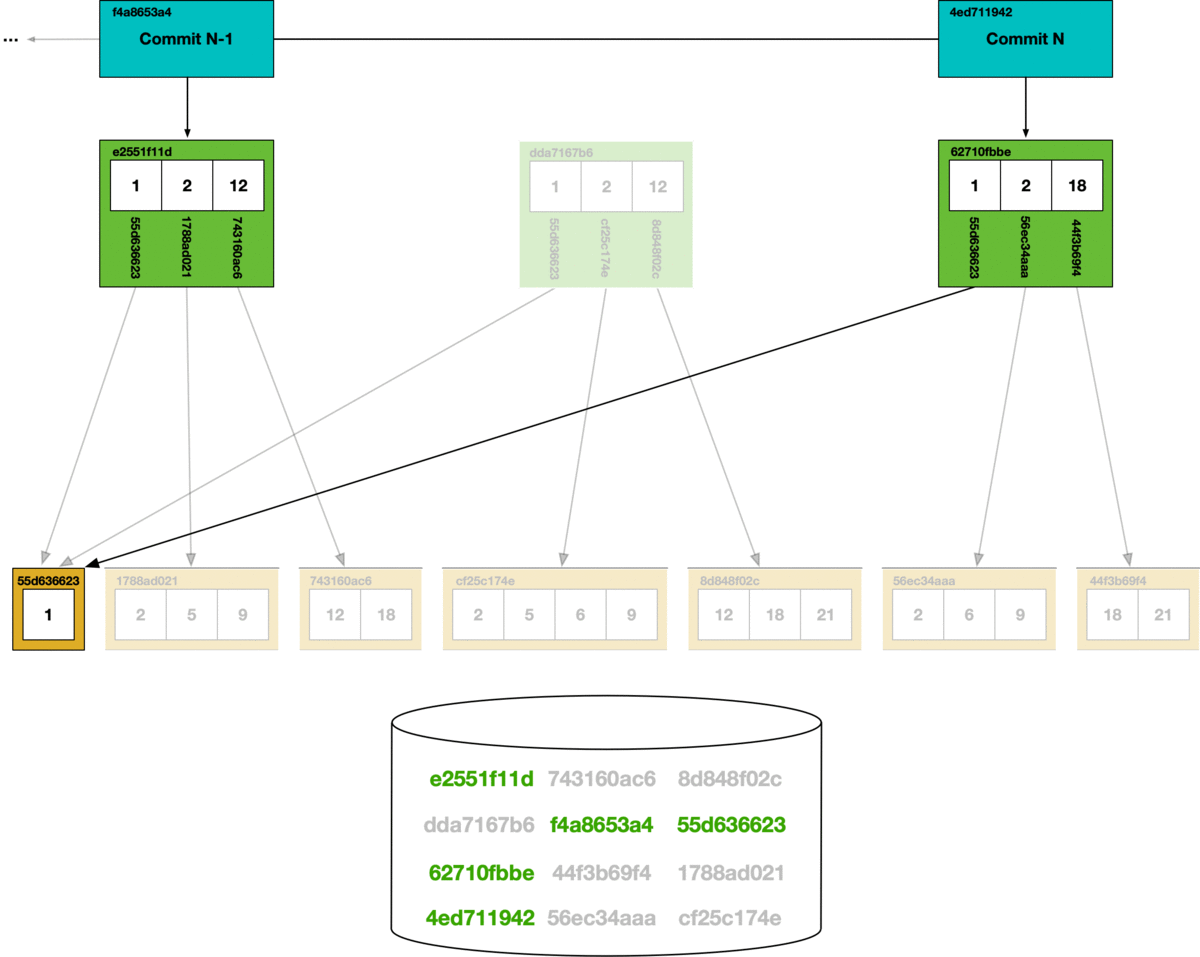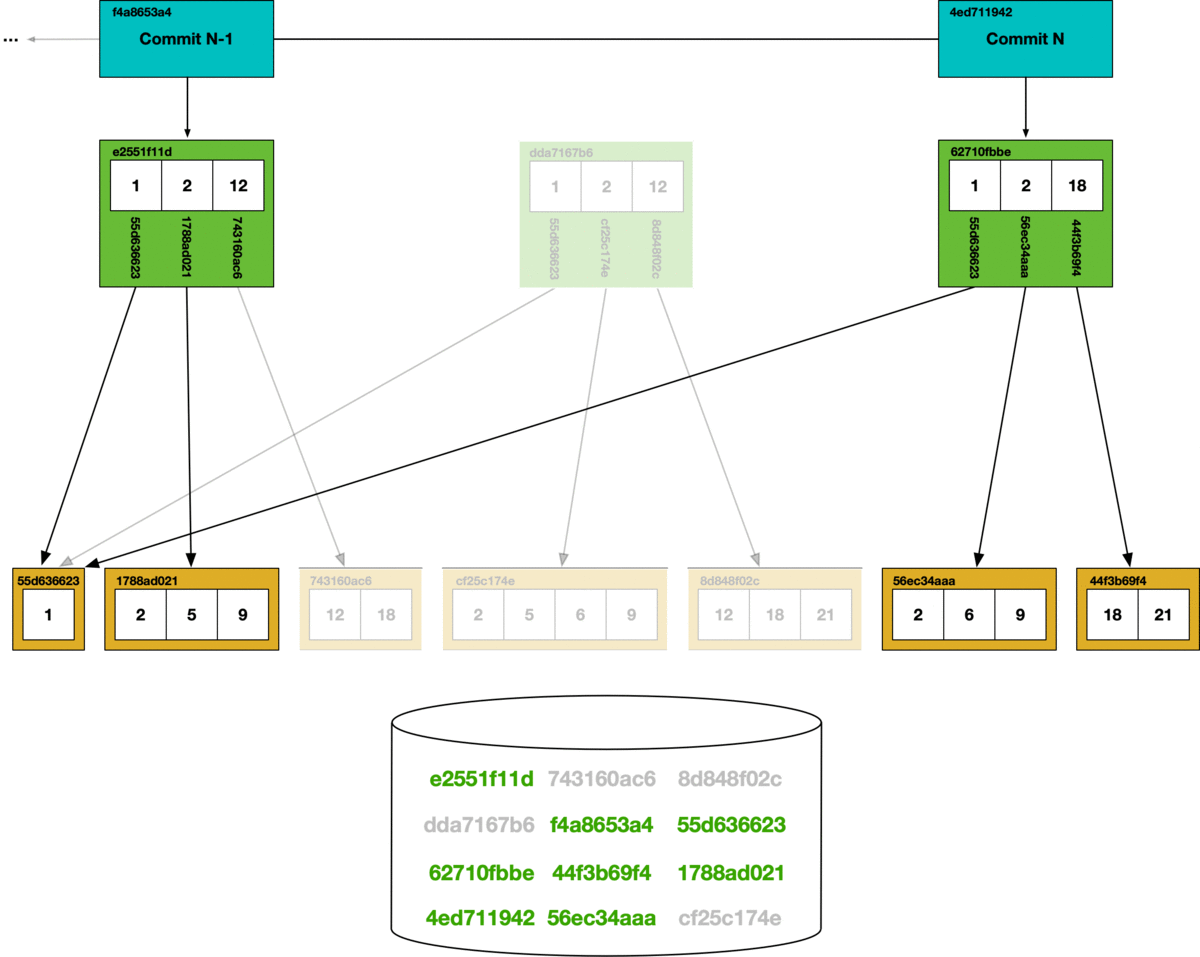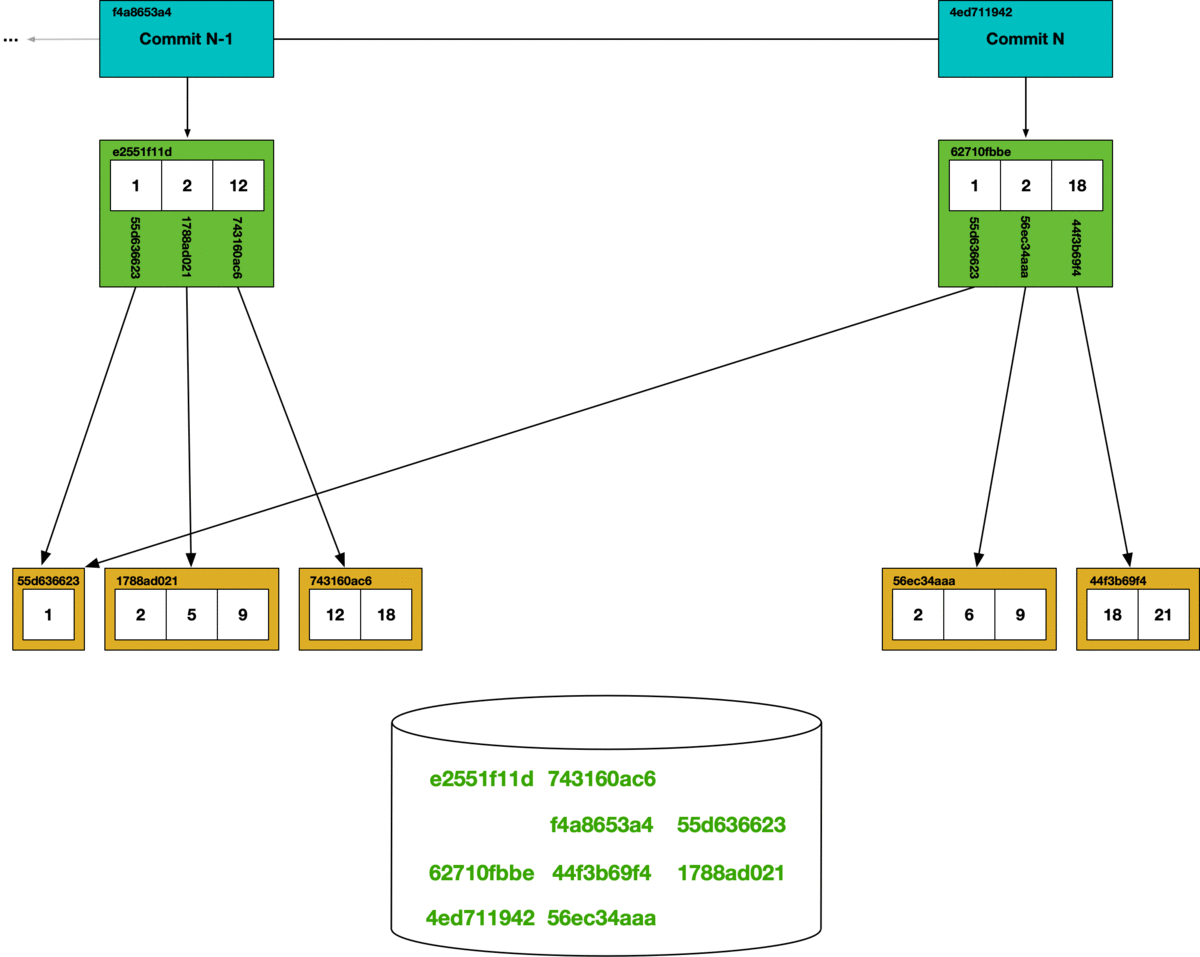
Unlike the CLI, using Dolt as a server allows multiple concurrent clients. If online garbage collection runs concurrently with SQL writes, we can get dangling references. In the garbage collection process illustrated above, if a write occurs that creates a new Prolly-tree referencing a hash that’s been removed during garbage collection, it will create a dangling reference. Dangling references can corrupt the state of the database, so in order to support online garbage collection we had to figure out a way to prevent concurrent writes from creating dangling references.
Implementation#
The original idea was to start garbage collection by adding all referenced chunks to one table file, let writes proceed and add them to the GC process, and at the end block writes to replace the manifest with only the newly created file.
This approach was trickier than we originally thought. We weren’t accounting for new
writes referencing chunks that had already been garbage collected. We reconvened and came
up with a less ideal, but nearer-at-hand solution, which was to block all writes while
garbage collection is active and add a sanity check to all Put chunk calls for any
dangling references. While this would work for online GC using a stored procedure, it is
less ideal for an automatic online GC solution. But it was something to start with.
Implementing the Put chunk sanity check surfaced some existing bugs (see fixes
here and
here). Flaws in our test setup also took some
time to work through. The main cause of the test setup issues was that we were using
MemoryStore
in a lot of our unit tests. MemoryStore doesn’t implement
TableFileStore,
our interface for directly interacting with table files, which means we could not use the
more reliable
puller
for syncing data between Databases. Put chunk calls in chunk stores that don’t support
TableFileStore/puller couldn’t reliably find a chunk in our tests, so they were
failing the sanity checks in a way that was inconsistent with the expected chunk store
state.
After a few failed attempts to make MemoryStore implement TableFileStore, we decided
to replace MemoryStorage in our DBFactory implementation for creating in memory
backed
databases
(which is used in our unit tests) with a blobstore-backed
NBS. This allowed
us to use puller and kill our error-prone
pull
code altogether.
Once we worked through these sanity check related issues, we realized the sanity checks
during Put caused significant performance regressions to writes.
Andy was able to fix these regressions by speeding up
the address walks during the sanity checks and by moving the sanity checks to commit time
instead of Put.
This first version of online GC (which blocks all writes) is also available using the stored procedure for GC:
CALL DOLT_GC();Further work#
This first version of online garbage collection blocks all writes to Dolt while the garbage collection process is in progress. We have further work to do to allow writes to proceed during garbage collection. Once this works we garbage collect automatically during garbage-heavy operations like imports.
If you have any questions or want to know more about Dolt or Hosted Dolt, feel free to reach out on our Discord or file a GitHub issue.