
Dolt is the first version controlled SQL database. Dolt uses Git semantics to branch and commit state checkpoints, and MySQL semantics to define, mutate, and access data.
We’ve optimized a variety of performance benchmarks over the last year: sysbench, TPCC, import performance. Our next target is system tables!
This blog talks about how common system table queries are now on average 10x faster with commit indexes.
Background#
A Dolt database is a commit graph. Each commit in the graph is a point in time snapshot. A database is represented by collections of content addressed chunks on disk. Most chunks are portions of clustered indexes (Prolly trees) containing row data, but commits are also content addressed chunks on disk. The sum of all chunks is a chunkstore. Dolt Prolly trees and commit graphs are different data structures, but they are both chunks in the chunkstore.
System table queries are “views” simulating access to versioning metadata:
> select * from dolt_log;
+----------------------------------+------------+-----------------+-------------------------+----------------------------+
| commit_hash | committer | email | date | message |
+----------------------------------+------------+-----------------+-------------------------+----------------------------+
| ag2ari1tacic1n07s2ndk8upa727nd4s | Bats Tests | bats@email.fake | 2023-01-20 19:52:47.867 | other commit 2 |
| 338aaqhvcsn4114cjkbbqac76cjmrdml | Bats Tests | bats@email.fake | 2023-01-20 19:52:44.527 | other commit 1 |
| v6fji7o05b9qultee9beuj417ka857c6 | Bats Tests | bats@email.fake | 2023-01-20 04:49:13.229 | commit 0 |
| c85kuigqb0rrmi1f44kcjiatb64galuv | Bats Tests | bats@email.fake | 2023-01-20 04:49:09.892 | Initialize data repository |
+----------------------------------+------------+-----------------+-------------------------+----------------------------+System table
queries are
often slow because we materialize the entire commit graph for every
query, essentially a select *, even when users only want one commit.
The right way to do this is to index into the commit graph the same way
we do with regular table indexes; find and read only the
commit we want. But the commit graph is a graph not a B-Tree, so search
isn’t as simple.
Benchmarks#
An alternative performance strategy might materialize system tables with clustered indexes. We avoid this in production because it would add write amplification and hurt commit latency. But materialized tables are useful performance baselines, because they represent a “best case” index lookup of the same data in our native Prolly tree index. The chart below shows the performance of native system tables versus materialized clustered indexes:
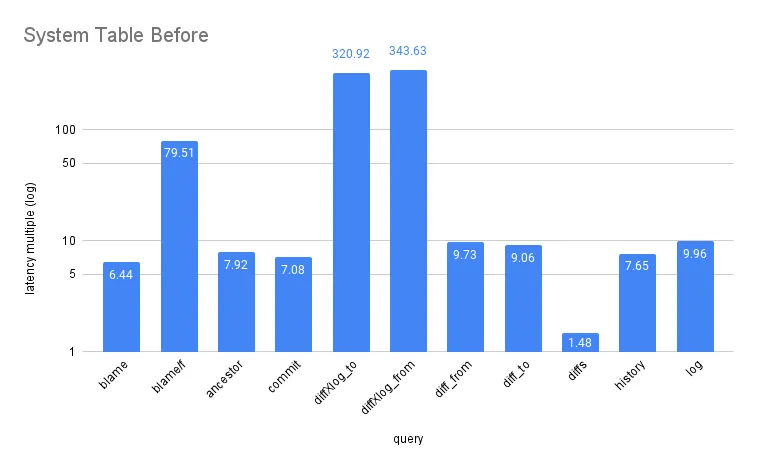
The y-axis is the latency multiple of a query compared to a materialized baseline. So if query A reported a baseline latency of 10ms and a system table latency of 40ms, we would report A’s multiple as 4x. The queries tested can be found here.
Tablescans are slow compared to index lookups! But we can do better.
Commit Indexes#
We can index many useful system table queries, we just have to understand and take advantage of the data structures at our disposal.
We recently added non-traditional indexes for a subset of commit hash filter expressions:
- lookup a commit in O(log n)
- search a commit’s ancestry for a commit in O(log n)
- scan commits by height in graph
We will walk though the data structures that support commit indexes.
Commit Lookup#
The chunkstore lets us lookup data using content addresses. Commits are addressed by their commit hashes, which makes their search straightforward.
So to execute this query:
> select * from dolt_commits where to_commit = 'gugi61g7enk0d3j483l125o667kg07s3';Rather than doing a select * on the entire commit graph, we can
directly search the chunkstore for gugi61. At a lower level, the
chunkstore uses binary search to search a sorted list of address names.
If we find a match, we then use an offset array to load and return the
chunk (commit). The commit includes the commit date, message,
committer, a commit closure address (more on this in next section), and
an address root for the database at this commit. If the chunk does not
exist, the chunkstore will report that too.
This chunkstore lookup ends up being slightly faster than if we searched a equivalent Prolly tree the same key. (benchmarking section includes more details).
Closure search#
Different system tables have different commit graph visibilities. The
dolt_commits table, for example, can see every commit in every branch:
> select * from dolt_commits;
+----------------------------------+------------+-----------------+-------------------------+----------------------------+
| commit_hash | committer | email | date | message |
+----------------------------------+------------+-----------------+-------------------------+----------------------------+
| gbatvm9v29tl1lvq15ns1ctm2hmqf3nj | Bats Tests | bats@email.fake | 2023-01-20 17:36:04.453 | feature commit |
| gugi61g7enk0d3j483l125o667kg07s3 | Bats Tests | bats@email.fake | 2023-01-20 04:49:14.345 | commit 4 |
| 6d68ja67uu5romgg21meog7lhr8b2cc9 | Bats Tests | bats@email.fake | 2023-01-20 04:49:13.308 | commit 3 |
| lfqi7puodj8u5ru15k40ntoie7rb0qgl | Bats Tests | bats@email.fake | 2023-01-20 04:49:13.3 | commit 2 |
| 9aicnc1snas2rss4b97folcvg4mr5ojs | Bats Tests | bats@email.fake | 2023-01-20 04:49:13.251 | commit 1 |
| v6fji7o05b9qultee9beuj417ka857c6 | Bats Tests | bats@email.fake | 2023-01-20 04:49:13.229 | commit 0 |
| c85kuigqb0rrmi1f44kcjiatb64galuv | Bats Tests | bats@email.fake | 2023-01-20 04:49:09.892 | Initialize data repository |
| ag2ari1tacic1n07s2ndk8upa727nd4s | Bats Tests | bats@email.fake | 2023-01-20 19:52:47.867 | other commit 2 |
| 338aaqhvcsn4114cjkbbqac76cjmrdml | Bats Tests | bats@email.fake | 2023-01-20 19:52:44.527 | other commit 1 |
+----------------------------------+------------+-----------------+-------------------------+----------------------------+The log table from main does not include
gbatvm, because it exists on a separate branch with a distinct
ancestry:
> select * from dolt_log where commit_hash = 'gbatvm9v29tl1lvq15ns1ctm2hmqf3nj';
Empty set (0.00 sec)One way to search a commit’s ancestry is through a commit
closure.
The commit closure is a Prolly tree of every commit address in the
current commit’s ancestry, excluding the current commit. The tree is
comprised of (height, address) keys, prefixed on height to order
commits for scanning. After locating a commit in the chunk store, we
use the closure for an O(log n) ancestry verification.
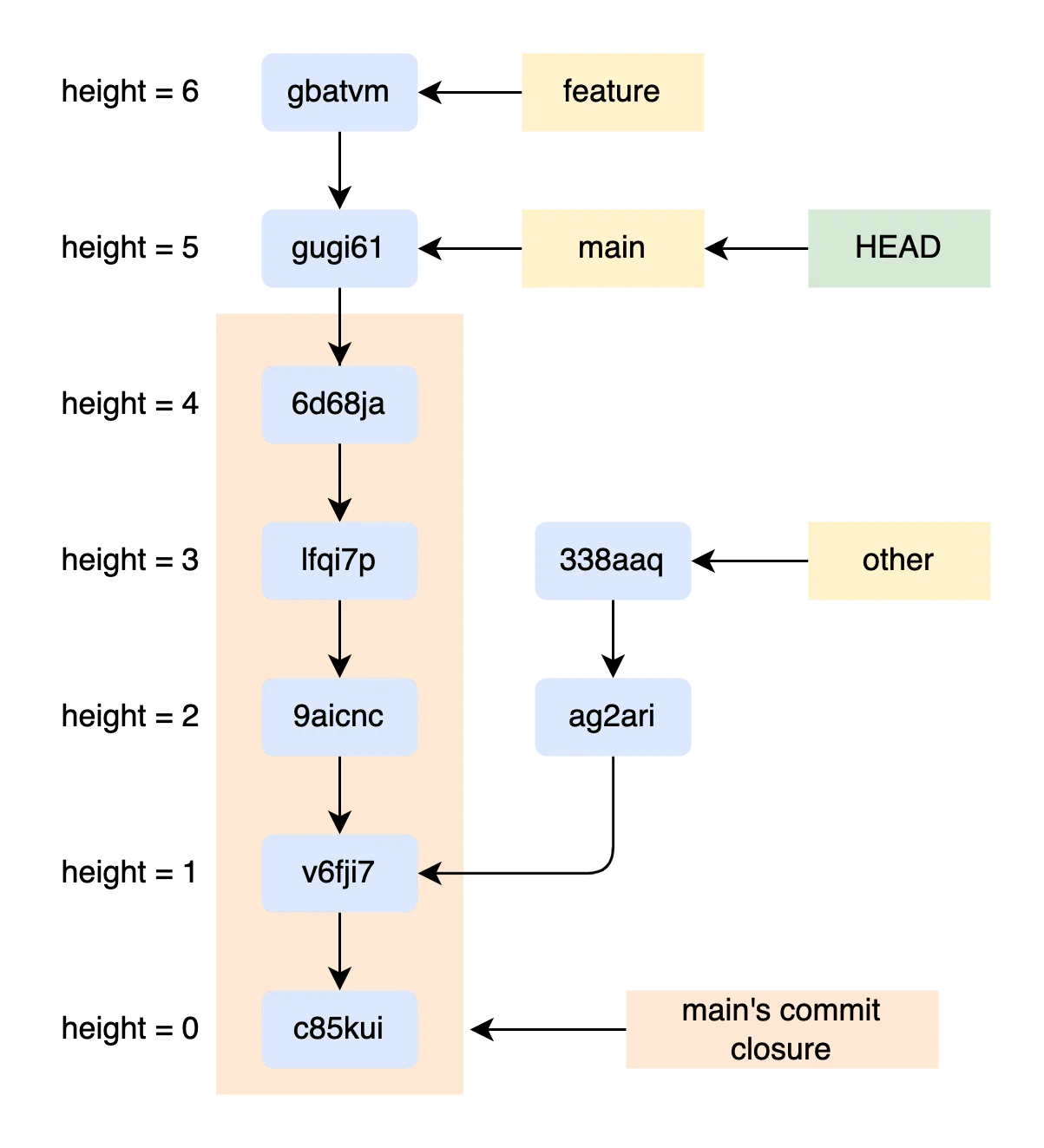
We have to do a bit more work in this case, but two lookups is still faster than reading the whole graph.
Closure scan#
The diff table generates row differences between two commits,
from_commit and to_commit. In this relationship, the from_commit
is a parent of to_commit (i.e. to_commit builds off from_commit).
When we filter on to_commit, from_commit are the parents, search
complete.
Indexing from_commit is more involved:
> select * from dolt_diff_xy where from_commit = 'gugi61g7enk0d3j483l125o667kg07s3';from_commit needs to be compared to the highest commit that references it as
a parent. This is the opposite direction as our commit graph parent pointers.
Most of the time, to_commit is height+1 relative to from_commit (a
linear commit graph). If the commit graph is not branched, there
will be only one height+1 commit in the closure, and we lookup
to_commit in O(log n)time . A branching commit graph will have a
height+1 commit for every branch. Merges combining branches could
reference from_commit above height+1. In that case, a thorough commit
walk from the top is necessary to screen merge commits for a higher
to_commit.
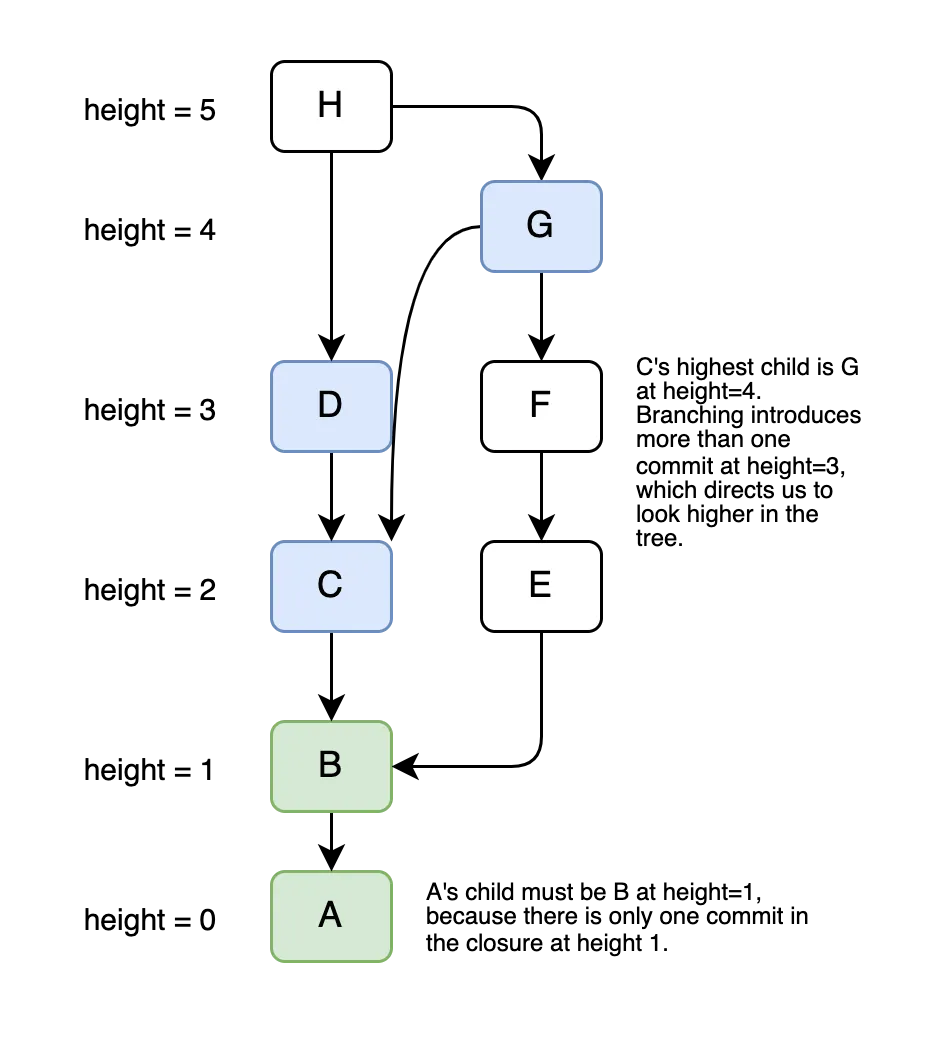
Usually we are lucky and can point lookup to_commit, but a
worst-case range scan is still better than select *.
Benchmarks#
The performance of our new commit indexes is listed below next to the original latencies. Multiples here are still relative to materialized index lookup baselines. The final column reports percent reduction between the two versions:
| query | 0.52.6 | 0.52.10 | % latency improvement |
|---|---|---|---|
| blame | 6.44 | 1.21 | 81% |
| blame/f | 79.51 | 2.36 | 97% |
| ancestor | 7.92 | 1 | 87% |
| commit | 7.08 | 0.96 | 86% |
| diffXlog_to | 320.92 | 1.79 | 99% |
| diffXlog_from | 343.63 | 1.63 | 100% |
| diff_from | 9.73 | 1.29 | 87% |
| diff_to | 9.06 | 1.13 | 88% |
| diffs | 1.48 | 1.03 | 30% |
| history | 7.65 | 1.08 | 86% |
| log | 9.96 | 0.96 | 90% |
And here is a visual comparison in log scale:
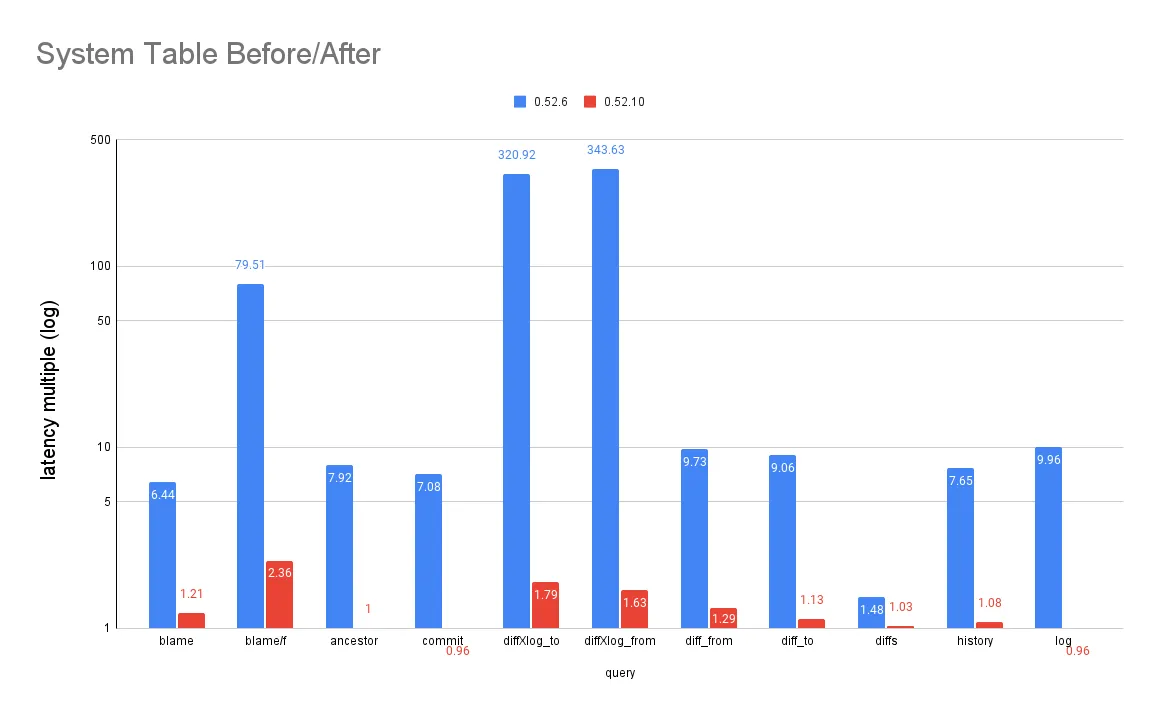
The chunkstore address lookup is comparable to a clustered index lookup in most cases. This makes sense because the clustered index lookup is an abstraction over a chunkstore address search. Directly searching the chunkstore and commit closures even surpasses clustered index lookup performance for the commit and log tables.
System tables experienced a 10x speed migrating from old to new format. Hopefully this additional 10x for indexed queries will make system tables even easier to use!
Summary#
This blog explains some of the recent system table improvements in the
latest Dolt release. In particular, we added custom commit_hash indexes for
system tables. The new indexes deliver an order of magnitude
performance win for common queries, approximating the performance of a
materialized index in many cases. The data structures used support
direct lookups, and are subject to more complicated access and existence
patterns at runtime (i.e. a commit exists, but is not accessible from
HEAD). Among the lookup expressions not supported are commit hash ranges
(commit_hash < 'abcd124'), commit message lookups, and commit date
lookups.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!