
It’s 2022, and the version control wars are conclusively over. Everybody uses git, but hardly anybody really understands it, and even fewer truly love it.

I think these last two points are related. It’s hard to love a tool, no matter how powerful, that you don’t understand. It feels dangerous and scary, no matter what you can achieve with it.
I used to have this problem too. Which was really a big problem considering my day job is to write a version-controlled database that copies git’s versioning model. I was in the “just delete everything and re-clone” camp too, right up until not understanding git’s model meant that I couldn’t understand the product I was building.
But I eventually figured it out. I don’t love git’s interface because I’m not a monster, but I do truly love the product itself now that I understand what it’s doing. But before I share its secrets…
A shameful confession#
Hi, my name is Zach and I’m a software engineer, but I’m… I’m a wordcel. It’s been 3 years, 4 months, and 11 days since the last time I rotated a shape.

Wordcels struggle with git because it’s a tool by shape rotators for shape rotators. But through long study and practice, I have mastered their foreign ways and can now share this forbidden knowledge with my fellow wordcels.
I’m going to assume you understand the idea of version control in the abstract: it lets you save multiple revisions of your files and time travel back to any previous revision if you mess something up. I want to talk about the thing that makes git different, which is its commit graph.
The wordcel’s guide to shape rotation using the Git commit graph#
The first thing you have to understand about git is that it stores all of its history in a graph. Here’s a diagram of a git commit history graph like you’d find on a git tutorial website:
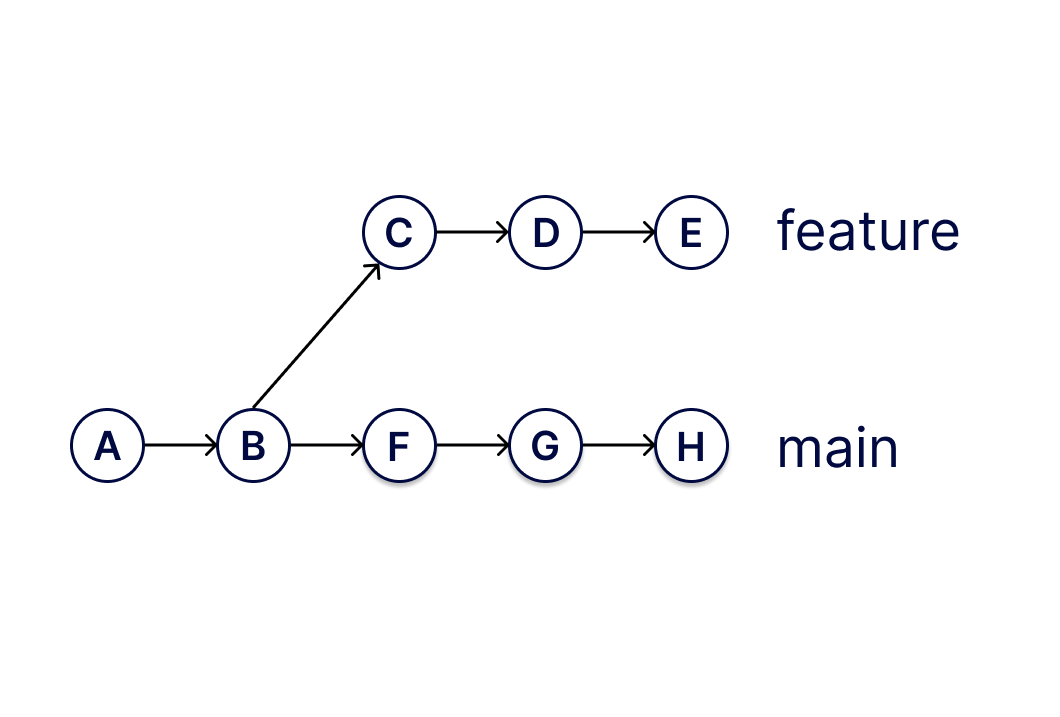
This is some shape rotator BS, you’re saying to yourself. Don’t panic! It’s not actually all that complicated once you understand what’s going on. It’s just that the people who make these diagrams are all such terminal shape rotators that they have forgotten what it is to talk to the humble wordcel, to walk among us and relate to us.
Here’s how this diagram would look if it was helpful.

This is the history of your file. You started with version one, which you committed with the comment “first draft”. Then you wrote a second draft and committed that revision, then finally made copy edits and committed that. So you have three revisions of your file, and this is the order you made them in, just a list of revisions.
Next let’s add in a couple more details.

The things we added are the arrows and the numbered labels for the commits. The arrows show the parent commit of each commit. Each commit points to the previous one in the chain, which illustrates that each revision came from the one before it. The numbers are hexadecimal identifiers that uniquely identify any commit in a repository, so that you can refer to that commit in other commands.
Next, let’s talk about what happens if you want to take the same draft in two different directions.
Branches#
In git, you can have multiple different drafts of the same file in flight at once. Think of it like alternate timelines for the file, parallel versions of reality where things went differently. As you’ve probably guessed, these timelines are what git calls branches.
It’s of course possible that some of these timelines are much darker than others, that’s for you to judge. I’ve seen some pretty dark ones in our repositories.

Back to our example. Let’s say that after you finish your final edits, you decide you’re not sure about the second draft, and want to try something different. So you rewind history to the first draft and start making a totally different set of edits.
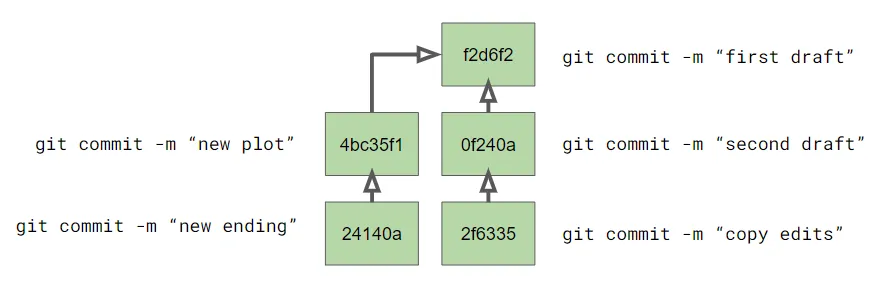
The column of commits on the left are your new edits to the first draft. But it’s a mistake to say that you now have two different copies of your file (you actually have five different copies, one for every commit you made). It’s more accurate to say you have two alternate histories of the file. There are now two alternate timelines for this file that diverged after the first draft. In each timeline you made a different set of edits and so the final file on each timeline is also different.
On the commit graph, here are the alternate timelines labeled:
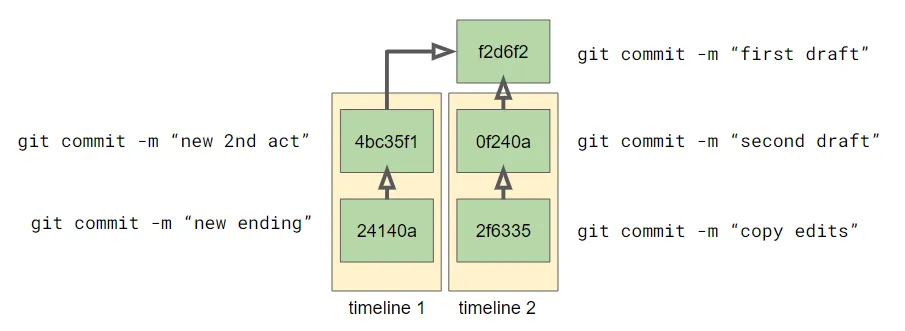
It would be another mistake to keep the colored timeline boxes in this metaphor, because they don’t really exist in git’s view of the world. A branch isn’t a timeline or a history: it’s just a label for a commit which has a history. Every commit has a parent and and therefore a history, but branches just label individual commits in the graph. Not understanding this earlier was the source of much confusion as I was learning git.
For example, there’s nothing stopping you from introducing another
divergence point at the "second draft" commit so you can take the
file in yet another direction. git checkout explicitly allows
this. If I type this command:
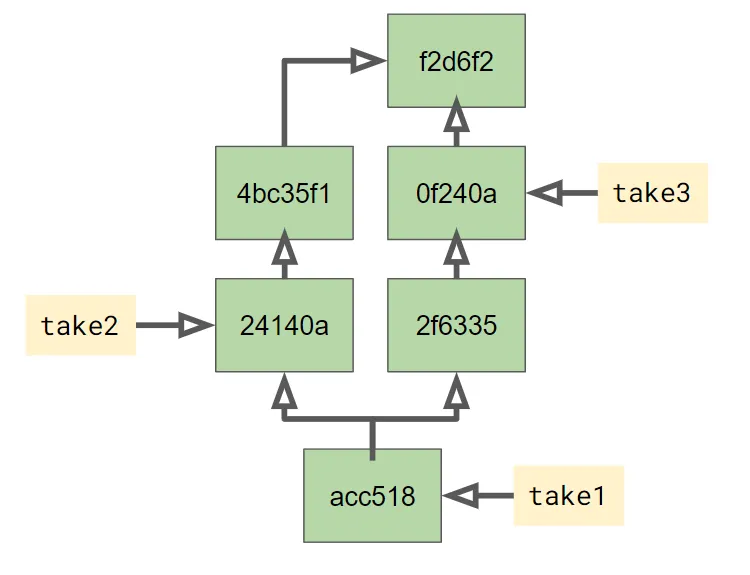
git checkout -b third-draft 0f240aThen I get a third branch at the commit with that label. Removing the timelines and replacing them with branch labels gives us this:
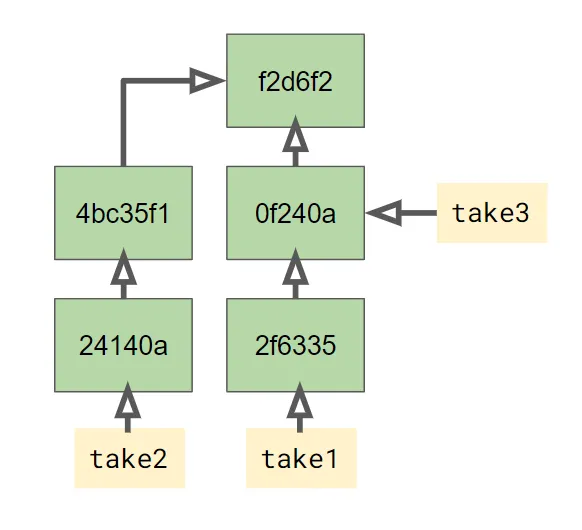
So I have 3 branches, take1, take2, and take3, each of which
refers to a different commit in the graph. They all share some
elements of their history, so it doesn’t make sense to talk about them
like they are independent entities. They’re just labels onto the
underlying graph. This becomes important when we talk about merging.
Merging#

One of the biggest reasons that git came to dominate earlier source control systems is that it can handle merging two branches together pretty well. It can do this because of the commit graph.
Let’s say that you decide you really like the plot changes you
introduced in both take1 and take2 and want to combine them. You
would do this with the merge command:
% git checkout take1
% git merge take2To figure out how to merge those two branches, git looks at the underlying graph and figures out what’s happened to both since they diverged. The place they diverged is called the common ancestor of the two branches.
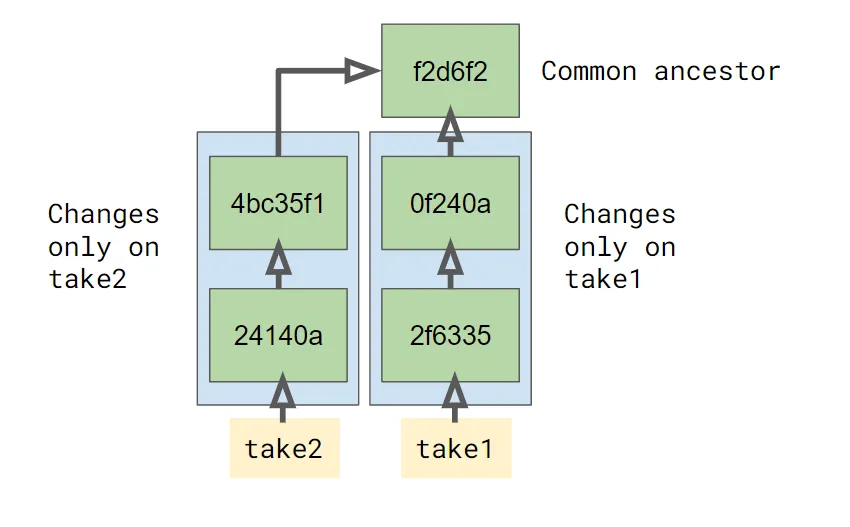
Git merges files one a line-by-line basis, pretty intelligently. So as long as you didn’t change the same line in your file on both branches, the result of your merge is a file with both sets of changes applied to it. This creates a new commit, which looks like this:
This new commit, labeled acc518, has two parents in the graph,
which are the two commits that it came from. Since we merged take2
into take1, the label for the take1 branch now points to the new
commit, while the take2 branch still refers to the same commit as
before.
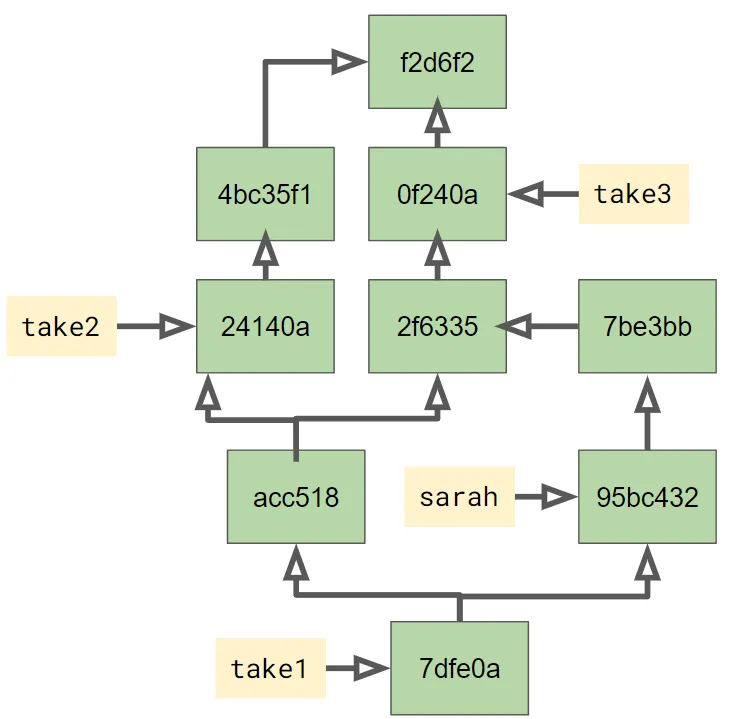
This becomes more important when you’re collaborating with others. Let’s say that back before the merge above, you gave your first take to your friend Sarah to improve. She made a couple of changes on her branch, so now the commit graph looks like this:
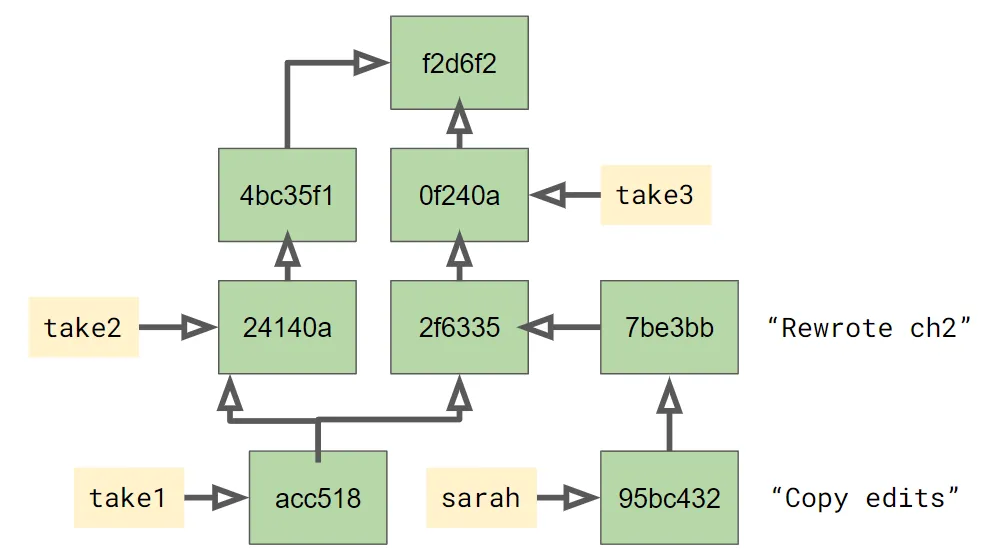
What happens when you want to incorporate her changes? You merge Sarah’s branch into yours:
% git merge sarahThis is where the commit graph really matters. Just like before, git is going to determine where the two branches diverged, and it knows it only needs to consider changes since that divergence, just the two commits Sarah made highlighted in blue below:
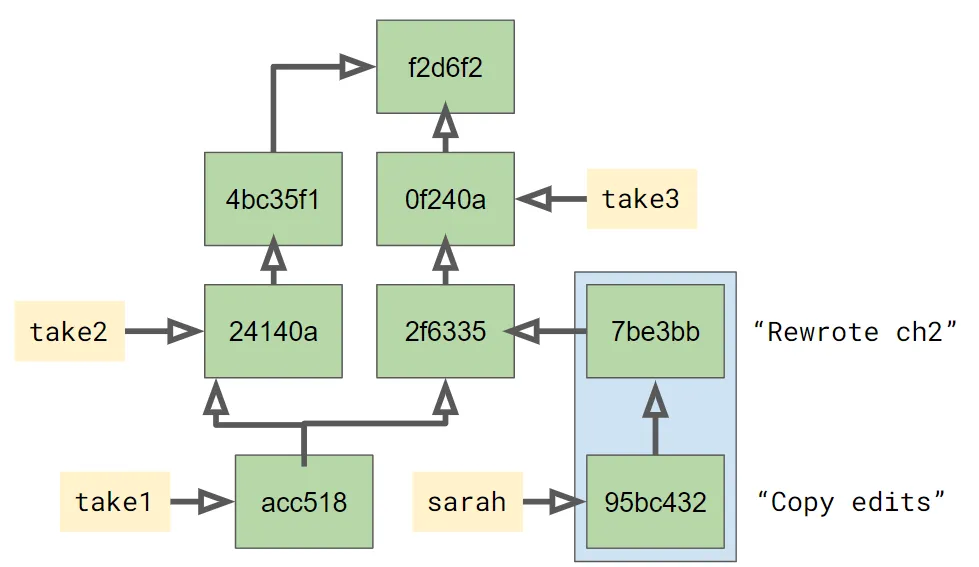
Finally, we end up with the commit graph below. There’s a new commit
7dfe0a that has the two parents of the merge. Our take1 branch
points to that commit, and the sarah branch label hasn’t moved.
If you don’t understand the git commit graph, all of the above merge operations are pretty mysterious. And in fact, lots of people who use git for their daily work never use branches or merge at all, because they don’t understand how it works!
Branch and merge are even more powerful than the simple examples above, but if you understand them you’re already way ahead of the average git user.
Git reset without throwing your changes away#
Like any version control system, git lets you restore your files to
any prior point in history, like going back in time. This is really
useful when you make a mistake you need to undo. The main way to
achieve this is with the git reset --hard command, which takes the
label for the branch you have checked out and moves it to a previous
commit in the branch’s history, any commit you want.

But what happens to the changes you made after the git reset point?
Where does they go? Well, they don’t go anywhere, and once you
understand what the git reset command does it should be easy to
understand why.
In real-world git use, like when you’re working with a team, you
generally have a main branch that nobody commits to
directly. Rather, everyone has their own branches they work on, and
these get merged into main in some centrally controlled location,
like on GitHub.
But anybody who has managed this workflow has, at some point or another, forgotten to make a branch first and made the mistake of committing directly to main. What now? Do I just re-clone the repository and start over? If you understand the git commit graph, you don’t have to! There’s no need to throw any work away or start over, just move the branch labels around.
Here’s where we’re starting: we accidentally made some commits directly to main since our last sync with GitHub.

So we need to undo those changes to main, those are going to make
our life difficult. Before we do that, let’s create a branch to save
our work.
% git branch myWorkThe git branch command makes a new branch label at the current
commit. So the graph is the same as before, it just has an additional
branch label pointing at the most recent commit.

Then we reset the main branch to the right commit.
% git reset --hard f2d6f2git reset --hard moves the current branch label to somewhere else in
the commit graph. It doesn’t actually throw away any work. After the
git reset, our commit graph looks the same, but the branch labels
now point somewhere else:

To continue working on our changes, we switch our workspace over to
the myWork branch again, using git checkout myWork.
What about git rebase?#
No.
Git is an incredibly versatile tool and allows you to do some really complicated things to the commit graph. Some very clever shape rotators decided one thing they really wanted to do was to pick up a set of commits they had made on one branch and move them over to another branch instead. This rewrites the history of the repository to pretend that those commits had a different parent all along.
Shape rotators are always trying to give you reasons this isn’t a wacky terrible idea with very few valid applications, but you should not believe their lies.

Git rebase is a tool of darkness to be mistrusted even in direst need. Walk in the light and use merge instead. I will not be taking questions on this point.
Conclusion#
I wrote this guide to summarize some of the conceptual problems I had when learning how to use git effectively, many of which were based on faulty or incomplete understandings of how git represents its change history. It’s something I wish had been around to read when I was first learning git. I hope it helps you!
My day job is building a database that has version control features modeled after git, which is why I had to really understand all this stuff. It’s Dolt, the world’s first SQL database that you can branch and merge, push and pull, fork and clone just like a git repository. Sound interesting? Have a comment? Come talk to our engineering team on Discord.