So you want Database Forks?

Here at DoltHub, we've had a lot of success with our "So you want..." series of blog posts helping people find Dolt when they are looking for us. Dolt is a lot of things. Dolt is a version controlled database, a Git database, Git for data, data version control, an immutable database, and a decentralized database.
Dolt is also a database you can fork. This blog will explain what a fork is, how to create database forks, and finally go through database products that offer fast, easy forking.
What is a fork?
Conceptually, a "fork" in the software context is a copy that can be modified with the intent of living on as a separate copy. This is distinct from a "branch" which implies the intent to merge the changes on the copy back into the original. A "fork" means you are making a copy and never coming back.

But the whole "never coming back" idea changed because of Git and GitHub. Git enabled decentralized development. In Git, every user was effectively granted a "fork" that acted like a "branch": a fork you could merge if you wanted to. GitHub leveraged this ability to introduce the fork concept for Git repositories. In Git and GitHub, you can merge changes between forks. A fork where you're never coming back became a "hard fork". Confusing? Kind of.
What is a database?

Technically, a file can be a database. Use a file as a database. Put the file in Git. Publish Git repository on GitHub. Fork the repository. Database forks. Nice article, Tim.
For the purpose of this article, we're going to restrict database to mean a SQL database of the online transaction processing (OLTP) variety. I couldn't find much information on forking NoSQL databases or data warehouse-style databases. Forking a SQL database becomes a much trickier problem because databases are generally larger than source code files.
How to create a database fork?
Making a database fork is pretty simple practically. First, you create a backup. Then you restore from the backup in another location, like on another server.
On MySQL, taking a backup using mysqldump would look something like this:
% mysqldump --all-databases --single-transaction --quick --lock-tables=false > full-backup.sql -u root -p
Copying the backup to another using scp host would look like this:
% scp full-backup.sql another-host:/home/timsehn/mysql-backups/Head over to the other host, start a mysql, and then import the backup.
% /usr/local/bin/mysqld
% mysql -u root < /home/timsehn/mysql-backups/full-backup.sqlVoila. The database running on another-host is a fork of the original database.
The issue with this approach is backing up and restoring can be slow. If you abstract the storage from the database, you maybe be able to fork faster. The providers below use clever tricks to make the process faster.
The Options
I started with the cloud database providers who advertise forking in their documentation. All other cloud database providers provide backups. Most even have tools to easily restore a new instance from a backup. So, technically, AWS RDS and every other cloud database provider supports forks.
For this article, I'm writing about the ones that explicitly advertise a fast forking feature. Without further ado, these are the options.

Cloud Hosted Databases Make Forking Easy
Heroku
- Tagline
- Cloud Application Platform
- Initial Release
- November 2011
- GitHub
- https://github.com/wal-e/wal-e
Heroku is a large cloud provider with many services. For database forking, you are looking for Heroku Postgres. Heroku is a large, popular public cloud provider. They are pretty much a known commodity at this point. If you're looking for a big vendor that supports database forks, Heroku is for you.
The database forking feature has been around since at least 2014. It's well documented and fully supported.
The GitHub link above is to the software used to do continuous write ahead log archival for Postgres, the actual feature used to make forking fast. Heroku has a large set of repositories on GitHub as they are a major cloud provider. For the purposes of this article, I thought it was better to link to the open source work that powers forks.
Aiven
- Tagline
- Data Infrastructure Made Simple
- Initial Release
- March 2017
- GitHub
- https://github.com/aiven
Aiven is a fairly new cloud database provider, established in 2016, based out of Helsinki. Before researching for this article I had never hear of them. The company seems pretty open source focused and well funded.
Database forking at Aiven works for both their MySQL and Postgres managed database products. The feature is fully supported and well documented.
Aiven supports a vast array of open source tools but the ones that power fork are pghoard for Postgres and myhoard for MySQL. Great names.
Citus
- Tagline
- The Postgres You Love, At Any Scale
- Initial Release
- April 2014
- GitHub
- https://github.com/citusdata/citus
Citus makes a backend for Postgres that allows you to have a horizontally scalable, eventually consistent backend for Postgres. The company recently sold to Microsoft. Interestingly, I worked with one of the founders, Ozgun Erdogan, at Amazon in the mid 00s. What's up Ozgun? We're database people now.
Citus supports fast database forking. If you're interested in a horizontally scalable Postgres under the Microsoft umbrella that supports database forks, check out Citus.
What if you want GitHub-style Database Forks?
Dolt
- Tagline
- It's Git for Data
- Initial Release
- August 2019
- GitHub
- https://github.com/dolthub/dolt
Dolt and DoltHub add Git and GitHub style forks to the SQL database. Dolt is a version controlled database that supports Git-style version control of both schema and data. Dolt implements branch, merge, push, pull, and all the other popular Git functionality. It's the only SQL database with this functionality.
DoltHub is a place on the internet to share Dolt databases, Dolt's GitHub. DoltLab is a self-hosted version of DoltHub.
DoltHub and DoltLab both support forks in the GitHub sense.
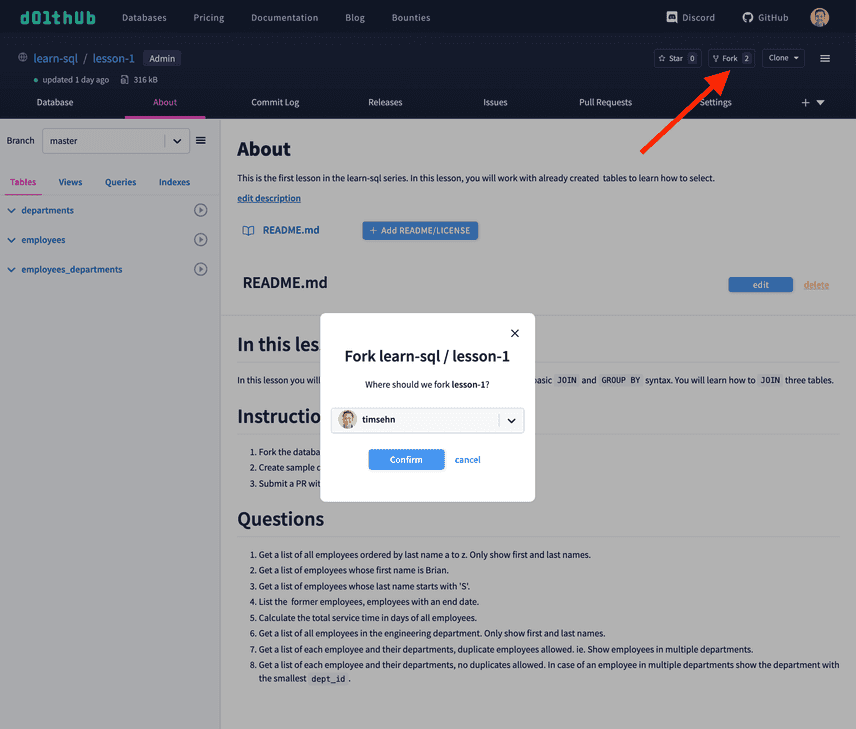
This means that with Dolt and DoltHub you can do distributed collaboration on databases. This feature is exemplified by DoltHub data bounties, where, for instance, we can build the world's biggest database of museum objects using a distributed group of collaborators. Database forks power the bounty workflow, much like GitHub code forks power open source contributions on GitHub.
We're biased but we think Dolt and DoltHub provide the true database fork experience. Sound interesting? Come chat with us about forks on our Discord.